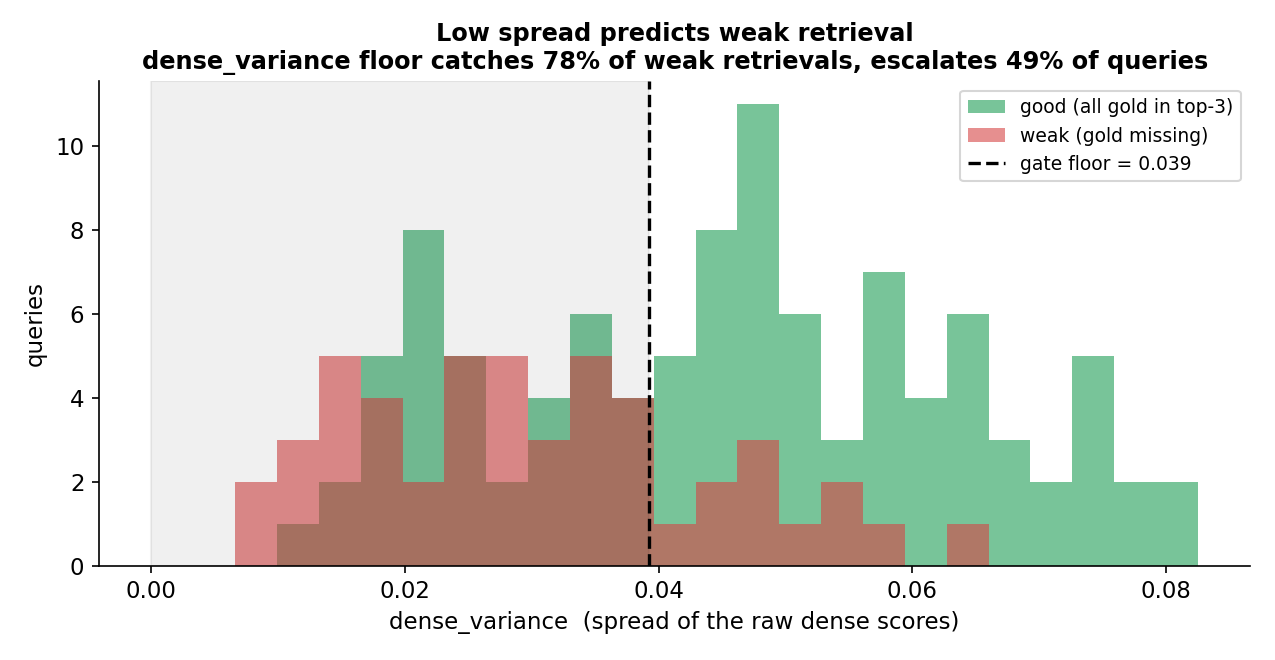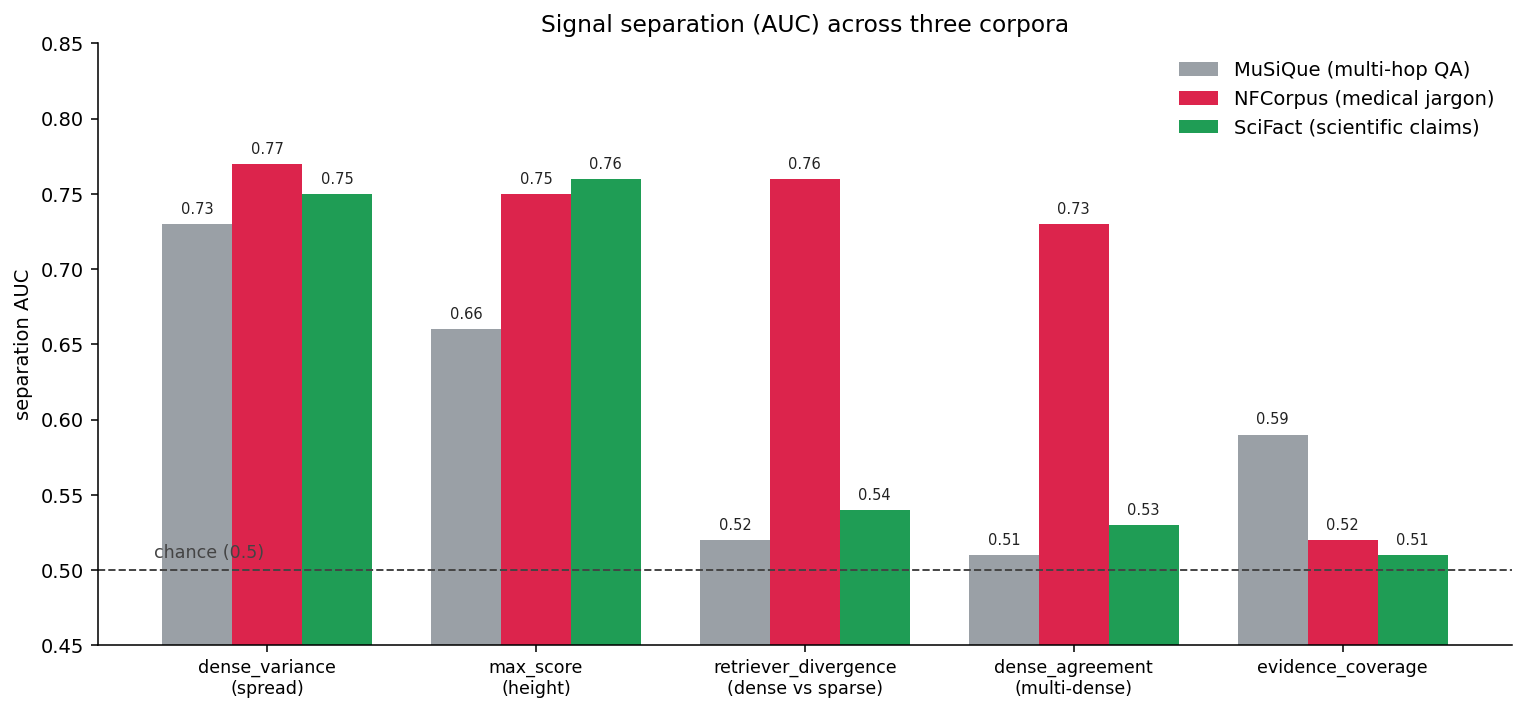
Separation AUC per signal, per corpus. Dense spread transfers across all three; the others help only where the corpus fails their way. Stack: bge-base + miniCOIL fused with RRF, plus mxbai-embed-large and arctic-embed-m for the agreement signals; windows are per corpus, so compare within a column, not across.