






















Qdrant 1.7.0 has just landed!
Kacper Łukawski
·December 10, 2023

Please welcome the long-awaited Qdrant 1.7.0 release. Except for a handful of minor fixes and improvements, this release brings some cool brand-new features that we are excited to share! The latest version of your favorite vector search engine finally supports sparse vectors. That’s the feature many of you requested, so why should we ignore it? We also decided to continue our journey with vector similarity beyond search. The new Discovery API covers some utterly new use cases. We’re more than excited to see what you will build with it! But there is more to it! Check out what’s new in Qdrant 1.7.0!
- Sparse vectors: do you want to use keyword-based search? Support for sparse vectors is finally here!
- Discovery API: an entirely new way of using vectors for restricted search and exploration.
- User-defined sharding: you can now decide which points should be stored on which shard.
- Snapshot-based shard transfer: a new option for moving shards between nodes.
Do you see something missing? Your feedback drives the development of Qdrant, so do not hesitate to join our Discord community and help us build the best vector search engine out there!
New features
Qdrant 1.7.0 brings a bunch of new features. Let’s take a closer look at them!
Sparse vectors
Traditional keyword-based search mechanisms often rely on algorithms like TF-IDF, BM25, or comparable methods. While these techniques internally utilize vectors, they typically involve sparse vector representations. In these methods, the vectors are predominantly filled with zeros, containing a relatively small number of non-zero values. Those sparse vectors are theoretically high dimensional, definitely way higher than the dense vectors used in semantic search. However, since the majority of dimensions are usually zeros, we store them differently and just keep the non-zero dimensions.
Until now, Qdrant has not been able to handle sparse vectors natively. Some were trying to convert them to dense vectors, but that was not the best solution or a suggested way. We even wrote a piece with our thoughts on building a hybrid search, and we encouraged you to use a different tool for keyword lookup.
Things have changed since then, as so many of you wanted a single tool for sparse and dense vectors. And responding to this popular demand, we’ve now introduced sparse vectors!
If you’re coming across the topic of sparse vectors for the first time, our Brief History of Search explains the difference between sparse and dense vectors.
Check out the sparse vectors article and sparse vectors index docs for more details on what this new index means for Qdrant users.
Discovery API
The recently launched Discovery API extends the range of scenarios for leveraging vectors. While its interface mirrors the Recommendation API, it focuses on refining the search parameters for greater precision. The concept of ‘context’ refers to a collection of positive-negative pairs that define zones within a space. Each pair effectively divides the space into positive or negative segments. This concept guides the search operation to prioritize points based on their inclusion within positive zones or their avoidance of negative zones. Essentially, the search algorithm favors points that fall within multiple positive zones or steer clear of negative ones.
The Discovery API can be used in two ways - either with or without the target point. The first case is called a discovery search, while the second is called a context search.
Discovery search
Discovery search is an operation that uses a target point to find the most relevant points in the collection, while performing the search in the preferred areas only. That is basically a search operation with more control over the search space.
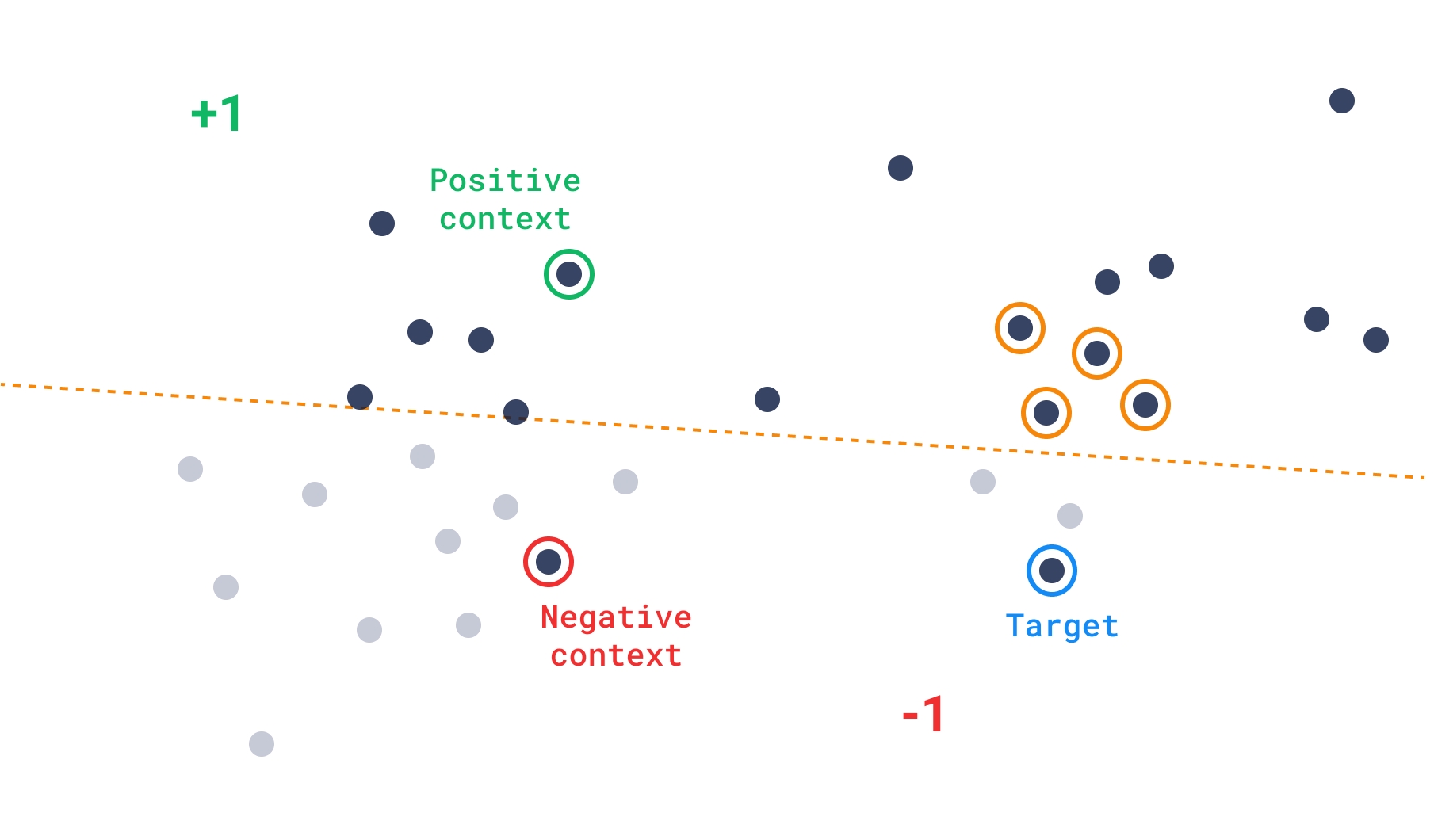
Please refer to the Discovery API documentation on discovery search for more details and the internal mechanics of the operation.
Context search
The mode of context search is similar to the discovery search, but it does not use a target point. Instead, the context is used to navigate the HNSW graph towards preferred zones. It is expected that the results in that mode will be diverse, and not centered around one point.
Context Search could serve as a solution for individuals seeking a more exploratory approach to navigate the vector space.
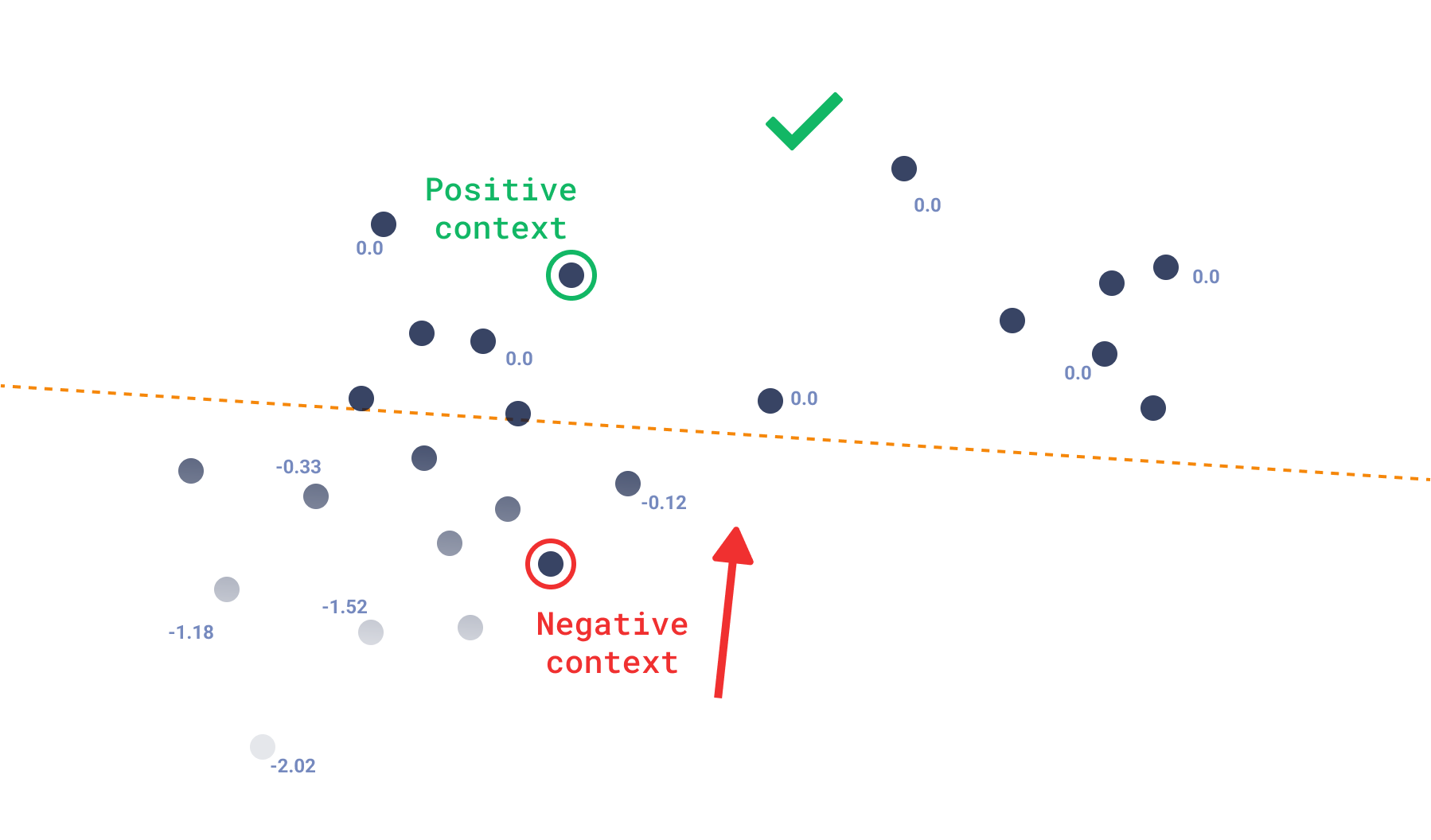
User-defined sharding
Qdrant’s collections are divided into shards. A single shard is a self-contained store of points, which can be moved between nodes. Up till now, the points were distributed among shards by using a consistent hashing algorithm, so that shards were managing non-intersecting subsets of points. The latter one remains true, but now you can define your own sharding and decide which points should be stored on which shard. Sounds cool, right? But why would you need that? Well, there are multiple scenarios in which you may want to use custom sharding. For example, you may want to store some points on a dedicated node, or you may want to store points from the same user on the same shard and
While the existing behavior is still the default one, you can now define the shards when you create a collection. Then, you can assign each point to a shard by providing a shard_key in the upsert operation. What’s more, you can also search over the selected shards only, by providing the shard_key parameter in the search operation.
POST /collections/my_collection/points/search
{
"vector": [0.29, 0.81, 0.75, 0.11],
"shard_key": ["cats", "dogs"],
"limit": 10,
"with_payload": true,
}
If you want to know more about the user-defined sharding, please refer to the sharding documentation.
Snapshot-based shard transfer
That’s a really more in depth technical improvement for the distributed mode users, that we implemented a new options the shard transfer mechanism. The new approach is based on the snapshot of the shard, which is transferred to the target node.
Moving shards is required for dynamical scaling of the cluster. Your data can migrate between nodes, and the way you move it is crucial for the performance of the whole system. The good old stream_records method (still the default one) transmits all the records between the machines and indexes them on the target node.
In the case of moving the shard, it’s necessary to recreate the HNSW index each time. However, with the introduction of the new snapshot approach, the snapshot itself, inclusive of all data and potentially quantized content, is transferred to the target node. This comprehensive snapshot includes the entire index, enabling the target node to seamlessly load it and promptly begin handling requests without the need for index recreation.
There are multiple scenarios in which you may prefer one over the other. Please check out the docs of the shard transfer method for more details and head-to-head comparison. As for now, the old stream_records method is still the default one, but we may decide to change it in the future.
Minor improvements
Beyond introducing new features, Qdrant 1.7.0 enhances performance and addresses various minor issues. Here’s a rundown of the key improvements:
Improvement of HNSW Index Building on High CPU Systems (PR#2869).
Improving Search Tail Latencies: improvement for high CPU systems with many parallel searches, directly impacting the user experience by reducing latency.
Adding Index for Geo Map Payloads: index for geo map payloads can significantly improve search performance, especially for applications involving geographical data.
Stability of Consensus on Big High Load Clusters: enhancing the stability of consensus in large, high-load environments is critical for ensuring the reliability and scalability of the system (PR#3013, PR#3026, PR#2942, PR#3103, PR#3054).
Configurable Timeout for Searches: allowing users to configure the timeout for searches provides greater flexibility and can help optimize system performance under different operational conditions (PR#2748, PR#2771).
Release notes
Our release notes are a place to go if you are interested in more details. Please remember that Qdrant is an open source project, so feel free to contribute!
