
In today’s fast-paced, information-rich world, AI is revolutionizing knowledge management. The systematic process of capturing, distributing, and effectively using knowledge within an organization is one of the fields in which AI provides exceptional value today.
The potential for AI-powered knowledge management increases when leveraging Retrieval Augmented Generation (RAG), a methodology that enables LLMs to access a vast, diverse repository of factual information from knowledge stores, such as vector databases.
This process enhances the accuracy, relevance, and reliability of generated text, thereby mitigating the risk of faulty, incorrect, or nonsensical results sometimes associated with traditional LLMs. This method not only ensures that the answers are contextually relevant but also up-to-date, reflecting the latest insights and data available.
While RAG enhances the accuracy, relevance, and reliability of traditional LLM solutions, an evaluation strategy can further help teams ensure their AI products meet these benchmarks of success.
Relevant tools for this experiment
In this article, we’ll break down a RAG Optimization workflow experiment that demonstrates that evaluation is essential to build a successful RAG strategy. We will use Qdrant and Quotient for this experiment.
Qdrant is a vector database and vector similarity search engine designed for efficient storage and retrieval of high-dimensional vectors. Because Qdrant offers efficient indexing and searching capabilities, it is ideal for implementing RAG solutions, where quickly and accurately retrieving relevant information from extremely large datasets is crucial. Qdrant also offers a wealth of additional features, such as quantization, multivector support and multi-tenancy.
Alongside Qdrant we will use Quotient, which provides a seamless way to evaluate your RAG implementation, accelerating and improving the experimentation process.
Quotient is a platform that provides tooling for AI developers to build evaluation frameworks and conduct experiments on their products. Evaluation is how teams surface the shortcomings of their applications and improve performance in key benchmarks such as faithfulness, and semantic similarity. Iteration is key to building innovative AI products that will deliver value to end users.
💡 The accompanying notebook for this exercise can be found on GitHub for future reference.
Summary of key findings
- Irrelevance and Hallucinations: When the documents retrieved are irrelevant, evidenced by low scores in both Chunk Relevance and Context Relevance, the model is prone to generating inaccurate or fabricated information.
- Optimizing Document Retrieval: By retrieving a greater number of documents and reducing the chunk size, we observed improved outcomes in the model’s performance.
- Adaptive Retrieval Needs: Certain queries may benefit from accessing more documents. Implementing a dynamic retrieval strategy that adjusts based on the query could enhance accuracy.
- Influence of Model and Prompt Variations: Alterations in language models or the prompts used can significantly impact the quality of the generated responses, suggesting that fine-tuning these elements could optimize performance.
Let us walk you through how we arrived at these findings!
Building a RAG pipeline
To evaluate a RAG pipeline, we will have to build a RAG Pipeline first. In the interest of simplicity, we are building a Naive RAG in this article. There are certainly other versions of RAG :
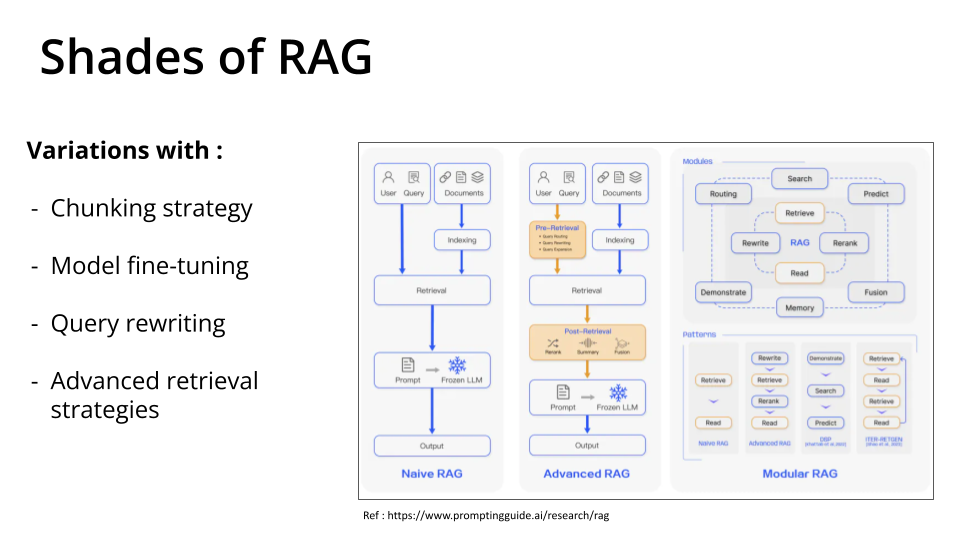
The illustration below depicts how we can leverage a RAG Evaluation framework to assess the quality of RAG Application.
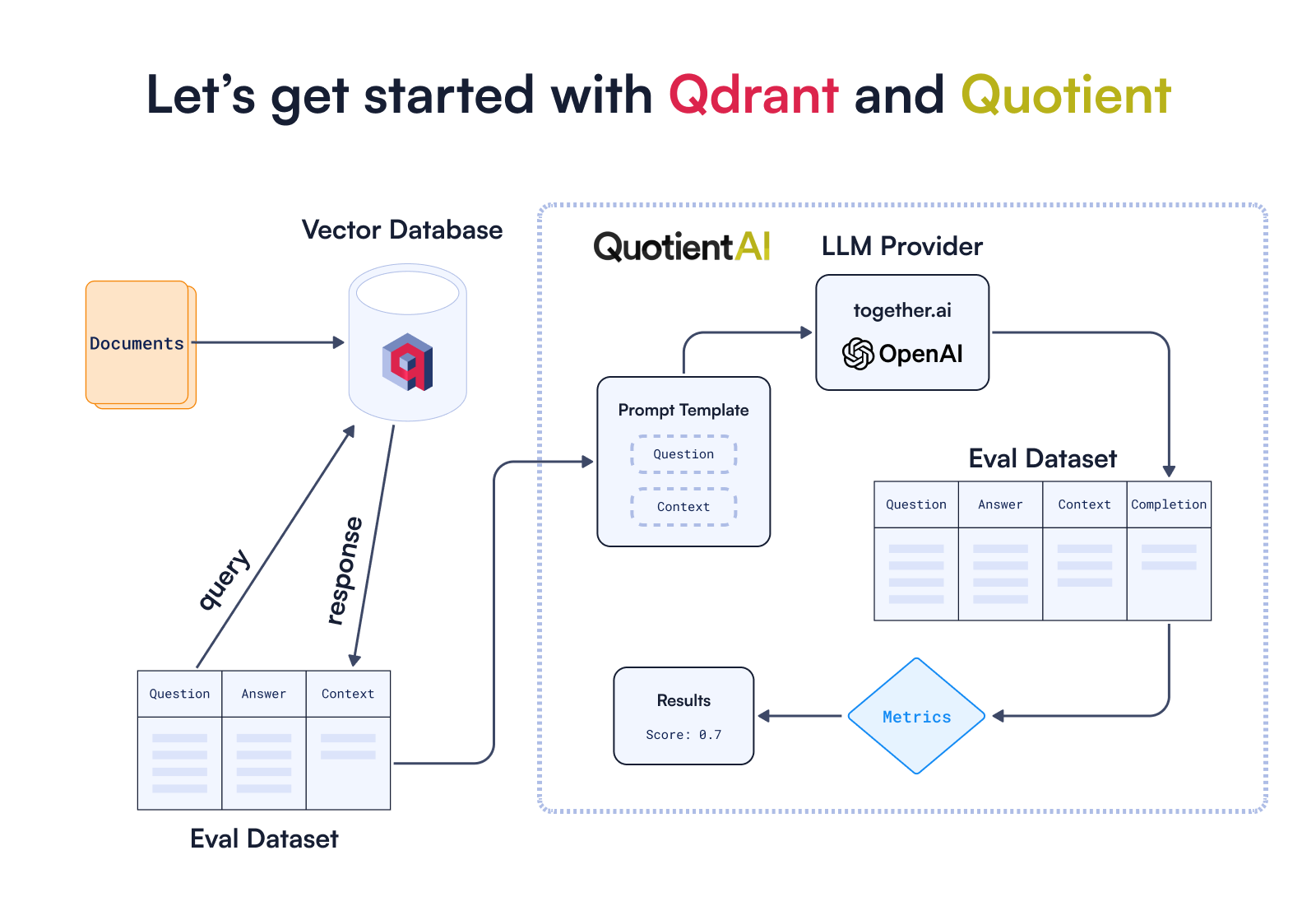
We are going to build a RAG application using Qdrant’s Documentation and the premeditated hugging face dataset. We will then assess our RAG application’s ability to answer questions about Qdrant.
To prepare our knowledge store we will use Qdrant, which can be leveraged in 3 different ways as below :
client = qdrant_client.QdrantClient(
os.environ.get("QDRANT_URL"),
api_key=os.environ.get("QDRANT_API_KEY"),
)
We will be using Qdrant Cloud so it is a good idea to provide the QDRANT_URL and QDRANT_API_KEY as environment variables for easier access.
Moving on, we will need to define the collection name as :
COLLECTION_NAME = "qdrant-docs-quotient"
In this case , we may need to create different collections based on the experiments we conduct.
To help us provide seamless embedding creations throughout the experiment, we will use Qdrant’s own embeddings library Fastembed which supports many different models including dense as well as sparse vector models.
Before implementing RAG, we need to prepare and index our data in Qdrant.
This involves converting textual data into vectors using a suitable encoder (e.g., sentence transformers), and storing these vectors in Qdrant for retrieval.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document as LangchainDocument
## Load the dataset with qdrant documentation
dataset = load_dataset("atitaarora/qdrant_doc", split="train")
## Dataset to langchain document
langchain_docs = [
LangchainDocument(page_content=doc["text"], metadata={"source": doc["source"]})
for doc in dataset
]
len(langchain_docs)
#Outputs
#240
You can preview documents in the dataset as below :
## Here's an example of what a document in our dataset looks like
print(dataset[100]['text'])
Evaluation dataset
To measure the quality of our RAG setup, we will need a representative evaluation dataset. This dataset should contain realistic questions and the expected answers.
Additionally, including the expected contexts for which your RAG pipeline is designed to retrieve information would be beneficial.
We will be using a prebuilt evaluation dataset.
If you are struggling to make an evaluation dataset for your use case , you can use your documents and some techniques described in this notebook
Building the RAG pipeline
We establish the data preprocessing parameters essential for the RAG pipeline and configure the Qdrant vector database according to the specified criteria.
Key parameters under consideration are:
- Chunk size
- Chunk overlap
- Embedding model
- Number of documents retrieved (retrieval window)
Following the ingestion of data in Qdrant, we proceed to retrieve pertinent documents corresponding to each query. These documents are then seamlessly integrated into our evaluation dataset, enriching the contextual information within the designated context column to fulfil the evaluation aspect.
Next we define methods to take care of logistics with respect to adding documents to Qdrant
import uuid
from qdrant_client import models
def add_documents(client, collection_name, chunk_size, chunk_overlap, embedding_model_name):
"""
This function adds documents to the desired Qdrant collection given the specified RAG parameters.
"""
## Processing each document with desired TEXT_SPLITTER_ALGO, CHUNK_SIZE, CHUNK_OVERLAP
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
add_start_index=True,
separators=["\n\n", "\n", ".", " ", ""],
)
docs_processed = []
for doc in langchain_docs:
docs_processed += text_splitter.split_documents([doc])
## Processing documents to be encoded by Fastembed
docs_contents = []
docs_metadatas = []
for doc in docs_processed:
if hasattr(doc, 'page_content') and hasattr(doc, 'metadata'):
docs_contents.append(doc.page_content)
docs_metadatas.append(doc.metadata)
else:
# Handle the case where attributes are missing
print("Warning: Some documents do not have 'page_content' or 'metadata' attributes.")
print("processed: ", len(docs_processed))
print("content: ", len(docs_contents))
print("metadata: ", len(docs_metadatas))
if not client.collection_exists(collection_name):
client.create_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(size=384, distance=models.Distance.COSINE),
)
client.upsert(
collection_name=collection_name,
points=[
models.PointStruct(
id=uuid.uuid4().hex,
vector=models.Document(text=content, model=embedding_model_name),
payload={"metadata": metadata, "document": content},
)
for metadata, content in zip(docs_metadatas, docs_contents)
],
)
and retrieving documents from Qdrant during our RAG Pipeline assessment.
def get_documents(collection_name, query, num_documents=3):
"""
This function retrieves the desired number of documents from the Qdrant collection given a query.
It returns a list of the retrieved documents.
"""
search_results = client.query_points(
collection_name=collection_name,
query=models.Document(text=query, model=embedding_model_name),
limit=num_documents,
).points
results = [r.payload["document"] for r in search_results]
return results
Setting up Quotient
You will need an account log in, which you can get by requesting access on Quotient’s website. Once you have an account, you can create an API key by running the quotient authenticate CLI command.
Once you have your API key, make sure to set it as an environment variable called QUOTIENT_API_KEY
# Import QuotientAI client and connect to QuotientAI
from quotientai.client import QuotientClient
from quotientai.utils import show_job_progress
# IMPORTANT: be sure to set your API key as an environment variable called QUOTIENT_API_KEY
# You will need this set before running the code below. You may also uncomment the following line and insert your API key:
# os.environ['QUOTIENT_API_KEY'] = "YOUR_API_KEY"
quotient = QuotientClient()
QuotientAI provides a seamless way to integrate RAG evaluation into your applications. Here, we’ll see how to use it to evaluate text generated from an LLM, based on retrieved knowledge from the Qdrant vector database.
After retrieving the top similar documents and populating the context column, we can submit the evaluation dataset to Quotient and execute an evaluation job. To run a job, all you need is your evaluation dataset and a recipe.
A recipe is a combination of a prompt template and a specified LLM.
Quotient orchestrates the evaluation run and handles version control and asset management throughout the experimentation process.
Prior to assessing our RAG solution, it’s crucial to outline our optimization goals.
In the context of question-answering on Qdrant documentation, our focus extends beyond merely providing helpful responses. Ensuring the absence of any inaccurate or misleading information is paramount.
In other words, we want to minimize hallucinations in the LLM outputs.
For our evaluation, we will be considering the following metrics, with a focus on Faithfulness:
- Context Relevance
- Chunk Relevance
- Faithfulness
- ROUGE-L
- BERT Sentence Similarity
- BERTScore
Evaluation in action
The function below takes an evaluation dataset as input, which in this case contains questions and their corresponding answers. It retrieves relevant documents based on the questions in the dataset and populates the context field with this information from Qdrant. The prepared dataset is then submitted to QuotientAI for evaluation for the chosen metrics. After the evaluation is complete, the function displays aggregated statistics on the evaluation metrics followed by the summarized evaluation results.
def run_eval(eval_df, collection_name, recipe_id, num_docs=3, path="eval_dataset_qdrant_questions.csv"):
"""
This function evaluates the performance of a complete RAG pipeline on a given evaluation dataset.
Given an evaluation dataset (containing questions and ground truth answers),
this function retrieves relevant documents, populates the context field, and submits the dataset to QuotientAI for evaluation.
Once the evaluation is complete, aggregated statistics on the evaluation metrics are displayed.
The evaluation results are returned as a pandas dataframe.
"""
# Add context to each question by retrieving relevant documents
eval_df['documents'] = eval_df.apply(lambda x: get_documents(collection_name=collection_name,
query=x['input_text'],
num_documents=num_docs), axis=1)
eval_df['context'] = eval_df.apply(lambda x: "\n".join(x['documents']), axis=1)
# Now we'll save the eval_df to a CSV
eval_df.to_csv(path, index=False)
# Upload the eval dataset to QuotientAI
dataset = quotient.create_dataset(
file_path=path,
name="qdrant-questions-eval-v1",
)
# Create a new task for the dataset
task = quotient.create_task(
dataset_id=dataset['id'],
name='qdrant-questions-qa-v1',
task_type='question_answering'
)
# Run a job to evaluate the model
job = quotient.create_job(
task_id=task['id'],
recipe_id=recipe_id,
num_fewshot_examples=0,
limit=500,
metric_ids=[5, 7, 8, 11, 12, 13, 50],
)
# Show the progress of the job
show_job_progress(quotient, job['id'])
# Once the job is complete, we can get our results
data = quotient.get_eval_results(job_id=job['id'])
# Add the results to a pandas dataframe to get statistics on performance
df = pd.json_normalize(data, "results")
df_stats = df[df.columns[df.columns.str.contains("metric|completion_time")]]
df.columns = df.columns.str.replace("metric.", "")
df_stats.columns = df_stats.columns.str.replace("metric.", "")
metrics = {
'completion_time_ms':'Completion Time (ms)',
'chunk_relevance': 'Chunk Relevance',
'selfcheckgpt_nli_relevance':"Context Relevance",
'selfcheckgpt_nli':"Faithfulness",
'rougeL_fmeasure':"ROUGE-L",
'bert_score_f1':"BERTScore",
'bert_sentence_similarity': "BERT Sentence Similarity",
'completion_verbosity':"Completion Verbosity",
'verbosity_ratio':"Verbosity Ratio",}
df = df.rename(columns=metrics)
df_stats = df_stats.rename(columns=metrics)
display(df_stats[metrics.values()].describe())
return df
main_metrics = [
'Context Relevance',
'Chunk Relevance',
'Faithfulness',
'ROUGE-L',
'BERT Sentence Similarity',
'BERTScore',
]
Experimentation
Our approach is rooted in the belief that improvement thrives in an environment of exploration and discovery. By systematically testing and tweaking various components of the RAG pipeline, we aim to incrementally enhance its capabilities and performance.
In the following section, we dive into the details of our experimentation process, outlining the specific experiments conducted and the insights gained.
Experiment 1 - Baseline
Parameters
- Embedding Model:
bge-small-en - Chunk size:
512 - Chunk overlap:
64 - Number of docs retrieved (Retireval Window):
3 - LLM:
Mistral-7B-Instruct
We’ll process our documents based on configuration above and ingest them into Qdrant using add_documents method introduced earlier
#experiment1 - base config
chunk_size = 512
chunk_overlap = 64
embedding_model_name = "BAAI/bge-small-en"
num_docs = 3
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
add_documents(client,
collection_name=COLLECTION_NAME,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
embedding_model_name=embedding_model_name)
#Outputs
#processed: 4504
#content: 4504
#metadata: 4504
Notice the COLLECTION_NAME which helps us segregate and identify our collections based on the experiments conducted.
To proceed with the evaluation, let’s create the evaluation recipe up next
# Create a recipe for the generator model and prompt template
recipe_mistral = quotient.create_recipe(
model_id=10,
prompt_template_id=1,
name='mistral-7b-instruct-qa-with-rag',
description='Mistral-7b-instruct using a prompt template that includes context.'
)
recipe_mistral
#Outputs recipe JSON with the used prompt template
#'prompt_template': {'id': 1,
# 'name': 'Default Question Answering Template',
# 'variables': '["input_text","context"]',
# 'created_at': '2023-12-21T22:01:54.632367',
# 'template_string': 'Question: {input_text}\\n\\nContext: {context}\\n\\nAnswer:',
# 'owner_profile_id': None}
To get a list of your existing recipes, you can simply run:
quotient.list_recipes()
Notice the recipe template is a simplest prompt using Question from evaluation template Context from document chunks retrieved from Qdrant and Answer generated by the pipeline.
To kick off the evaluation
# Kick off an evaluation job
experiment_1 = run_eval(eval_df,
collection_name=COLLECTION_NAME,
recipe_id=recipe_mistral['id'],
num_docs=num_docs,
path=f"{COLLECTION_NAME}_{num_docs}_mistral.csv")
This may take few minutes (depending on the size of evaluation dataset!)
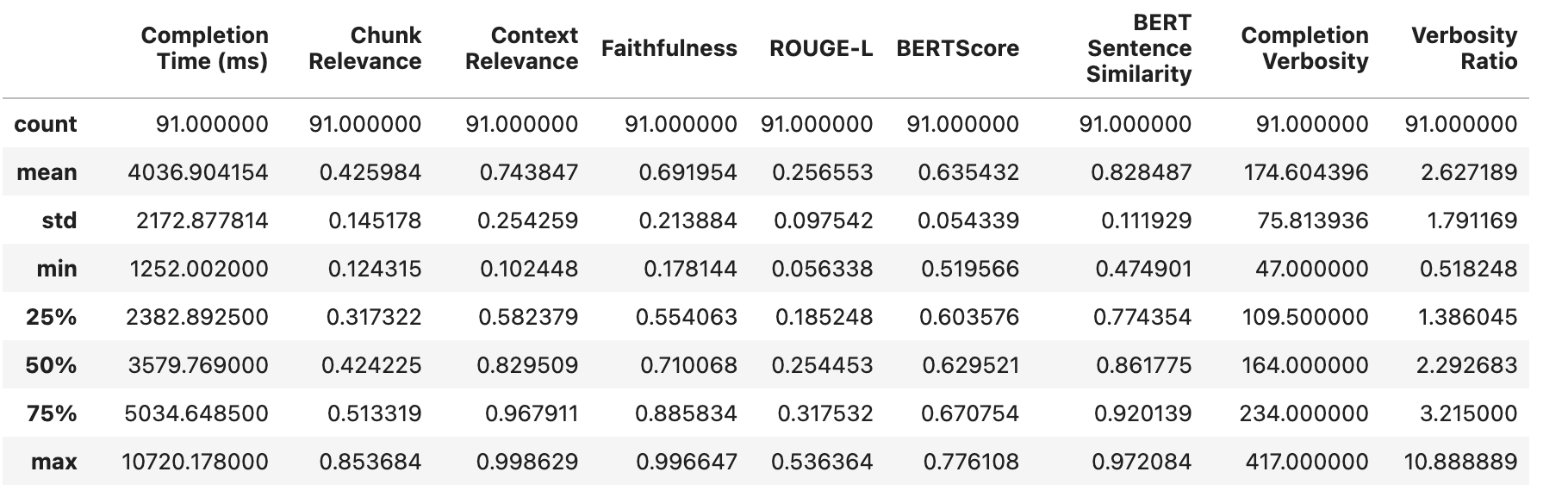
We can look at the results from our first (baseline) experiment as below :
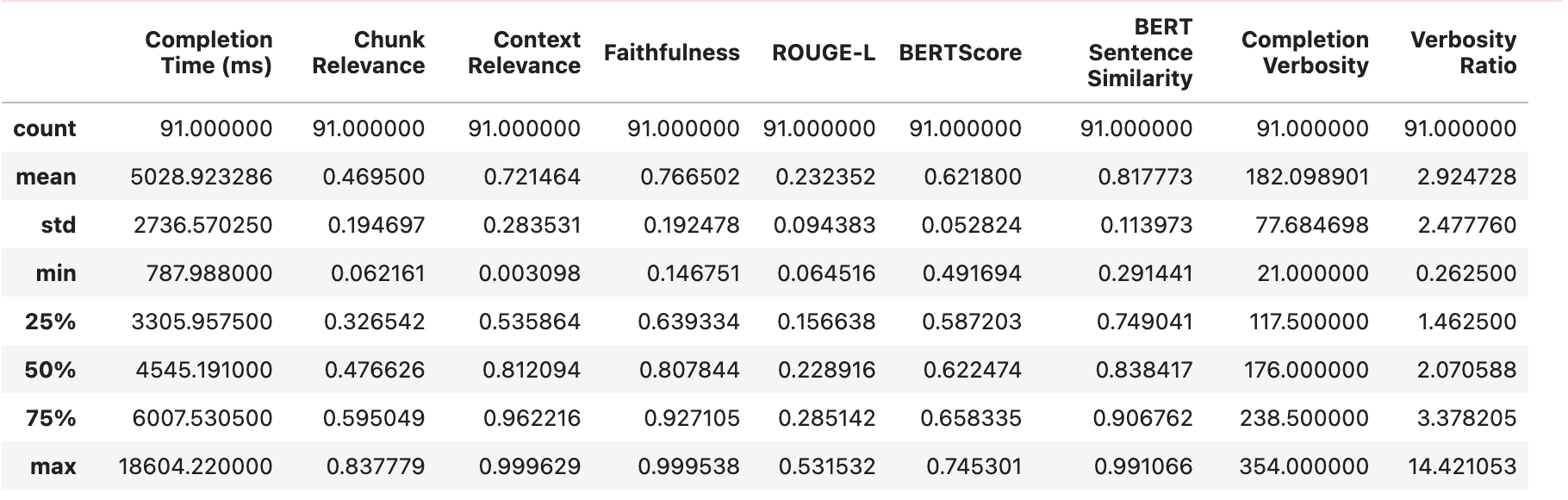
Notice that we have a pretty low average Chunk Relevance and very large standard deviations for both Chunk Relevance and Context Relevance.
Let’s take a look at some of the lower performing datapoints with poor Faithfulness:
with pd.option_context('display.max_colwidth', 0):
display(experiment_1[['content.input_text', 'content.answer','content.documents','Chunk Relevance','Context Relevance','Faithfulness']
].sort_values(by='Faithfulness').head(2))
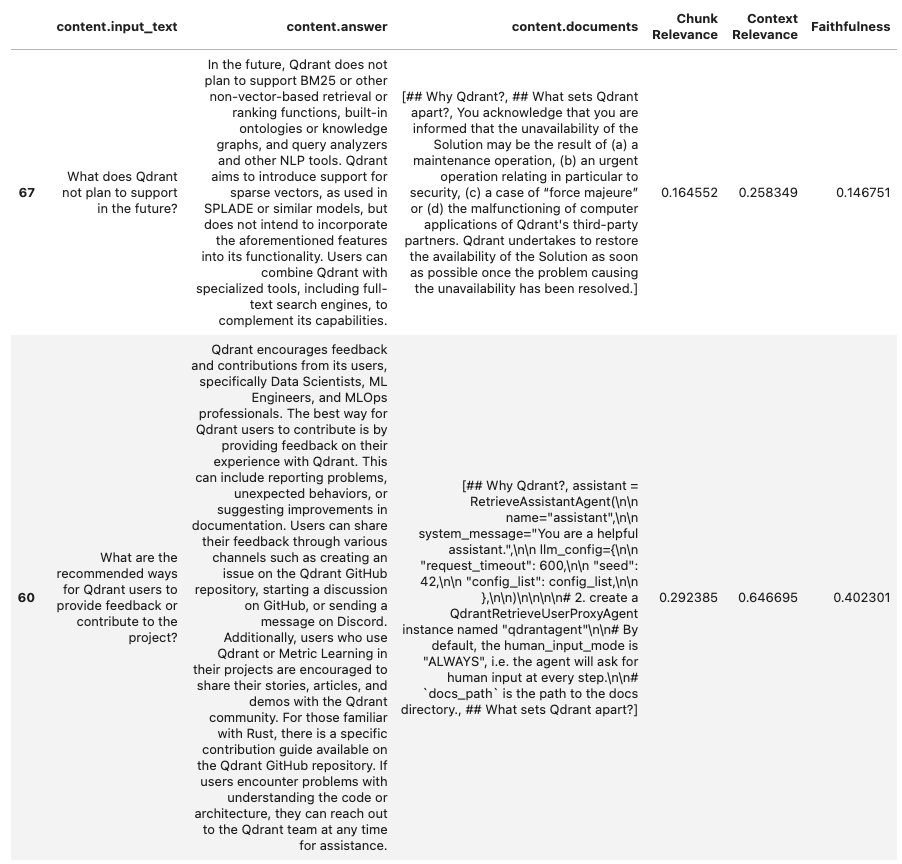
In instances where the retrieved documents are irrelevant (where both Chunk Relevance and Context Relevance are low), the model also shows tendencies to hallucinate and produce poor quality responses.
The quality of the retrieved text directly impacts the quality of the LLM-generated answer. Therefore, our focus will be on enhancing the RAG setup by adjusting the chunking parameters.
Experiment 2 - Adjusting the chunk parameter
Keeping all other parameters constant, we changed the chunk size and chunk overlap to see if we can improve our results.
Parameters :
- Embedding Model :
bge-small-en - Chunk size:
1024 - Chunk overlap:
128 - Number of docs retrieved (Retireval Window):
3 - LLM:
Mistral-7B-Instruct
We will reprocess the data with the updated parameters above:
## for iteration 2 - lets modify chunk configuration
## We will start with creating separate collection to store vectors
chunk_size = 1024
chunk_overlap = 128
embedding_model_name = "BAAI/bge-small-en"
num_docs = 3
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
add_documents(client,
collection_name=COLLECTION_NAME,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
embedding_model_name=embedding_model_name)
#Outputs
#processed: 2152
#content: 2152
#metadata: 2152
Followed by running evaluation :
and comparing it with the results from Experiment 1:
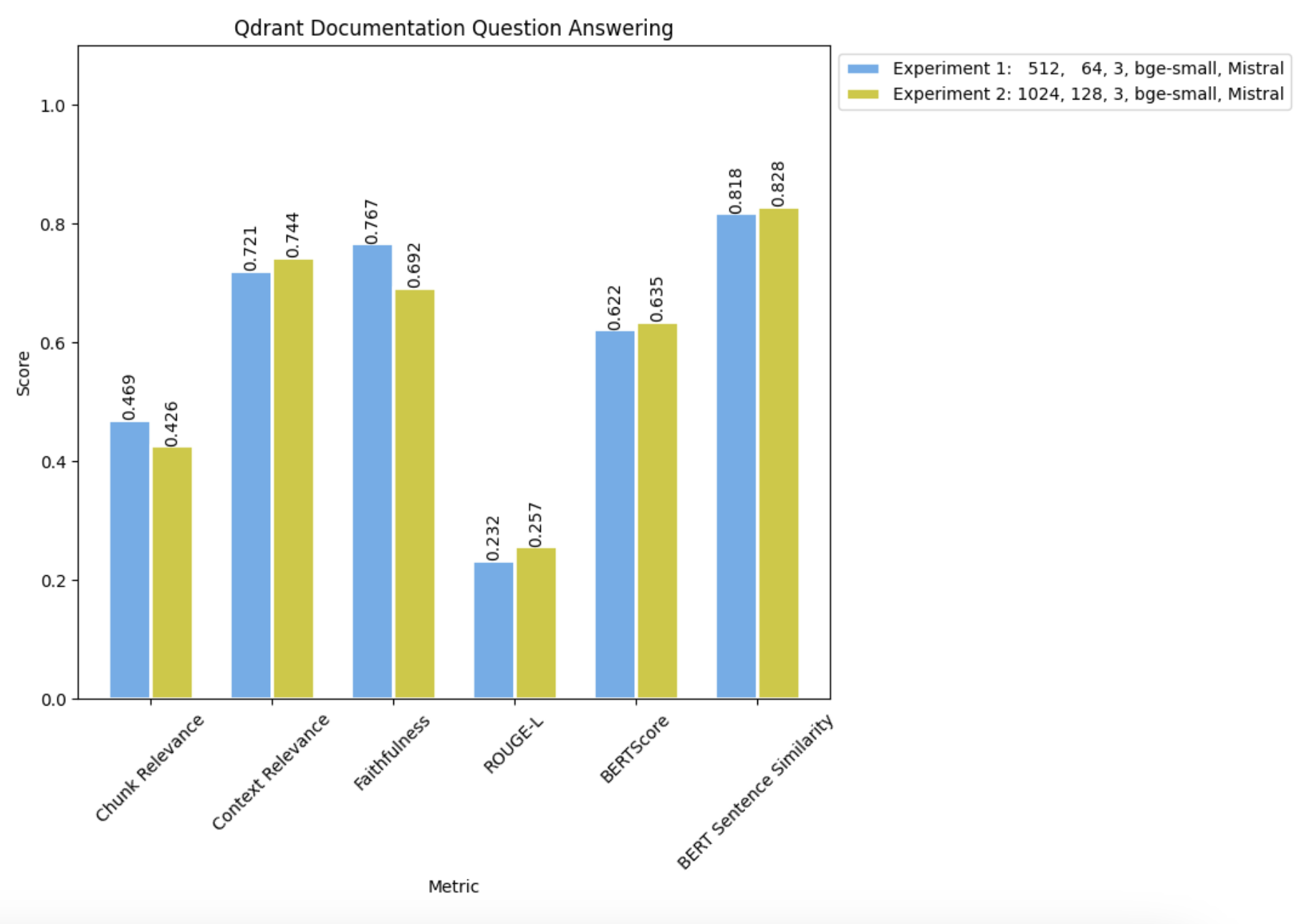
We observed slight enhancements in our LLM completion metrics (including BERT Sentence Similarity, BERTScore, ROUGE-L, and Knowledge F1) with the increase in chunk size. However, it’s noteworthy that there was a significant decrease in Faithfulness, which is the primary metric we are aiming to optimize.
Moreover, Context Relevance demonstrated an increase, indicating that the RAG pipeline retrieved more relevant information required to address the query. Nonetheless, there was a considerable drop in Chunk Relevance, implying that a smaller portion of the retrieved documents contained pertinent information for answering the question.
The correlation between the rise in Context Relevance and the decline in Chunk Relevance suggests that retrieving more documents using the smaller chunk size might yield improved results.
Experiment 3 - Increasing the number of documents retrieved (retrieval window)
This time, we are using the same RAG setup as Experiment 1, but increasing the number of retrieved documents from 3 to 5.
Parameters :
- Embedding Model :
bge-small-en - Chunk size:
512 - Chunk overlap:
64 - Number of docs retrieved (Retrieval Window):
5 - LLM: :
Mistral-7B-Instruct
We can use the collection from Experiment 1 and run evaluation with modified num_docs parameter as :
#collection name from Experiment 1
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
#running eval for experiment 3
experiment_3 = run_eval(eval_df,
collection_name=COLLECTION_NAME,
recipe_id=recipe_mistral['id'],
num_docs=num_docs,
path=f"{COLLECTION_NAME}_{num_docs}_mistral.csv")
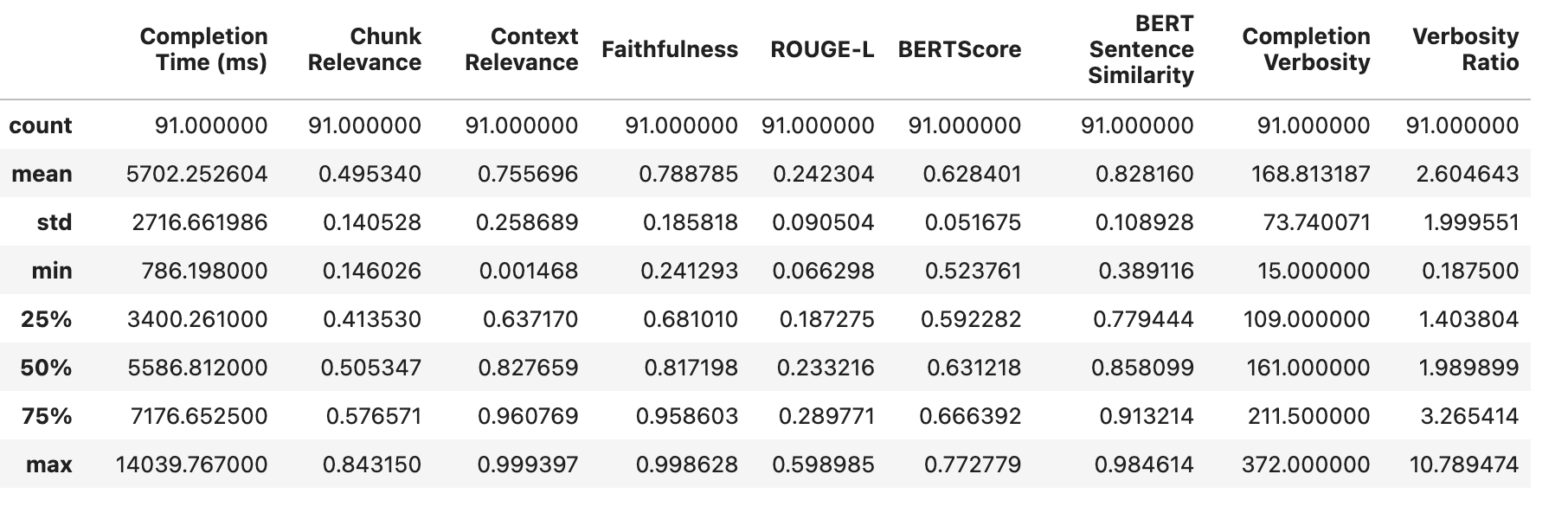
Observe the results as below :
Comparing the results with Experiment 1 and 2 :
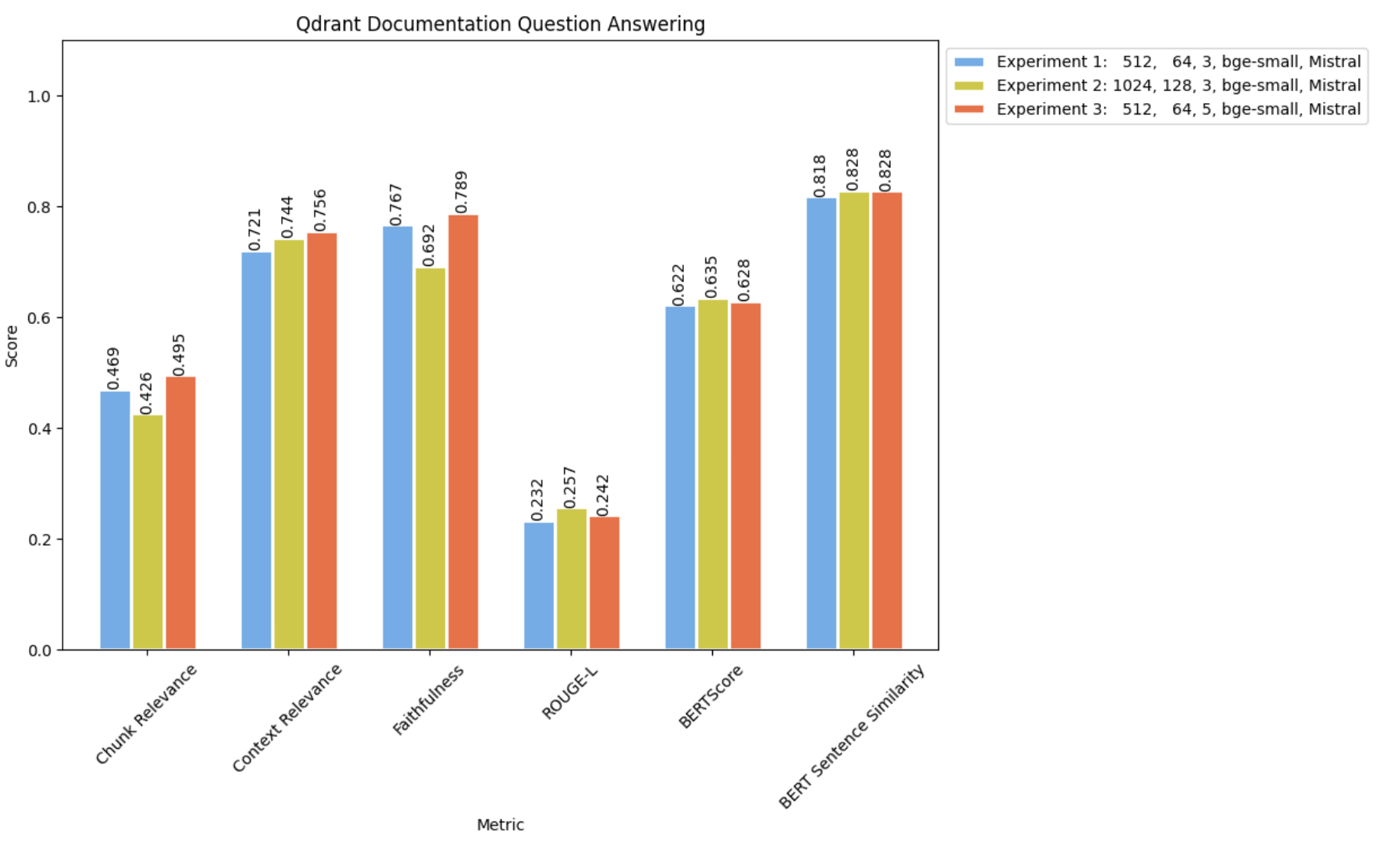
As anticipated, employing the smaller chunk size while retrieving a larger number of documents resulted in achieving the highest levels of both Context Relevance and Chunk Relevance. Additionally, it yielded the best (albeit marginal) Faithfulness score, indicating a reduced occurrence of inaccuracies or hallucinations.
Looks like we have achieved a good hold on our chunking parameters but it is worth testing another embedding model to see if we can get better results.
Experiment 4 - Changing the embedding model
Let us try using MiniLM for this experiment ****Parameters :
- Embedding Model :
MiniLM-L6-v2 - Chunk size:
512 - Chunk overlap:
64 - Number of docs retrieved (Retrieval Window):
5 - LLM: :
Mistral-7B-Instruct
We will have to create another collection for this experiment :
#experiment-4
chunk_size=512
chunk_overlap=64
embedding_model_name="sentence-transformers/all-MiniLM-L6-v2"
num_docs=5
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
add_documents(client,
collection_name=COLLECTION_NAME,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
embedding_model_name=embedding_model_name)
#Outputs
#processed: 4504
#content: 4504
#metadata: 4504
We will observe our evaluations as :
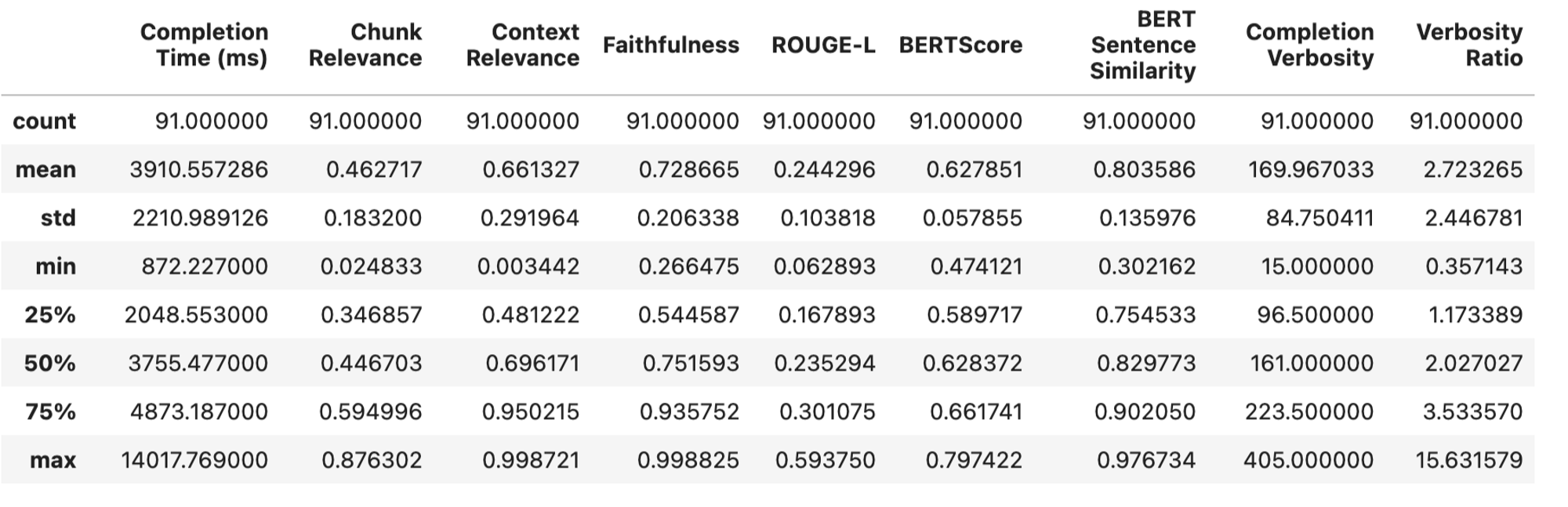
Comparing these with our previous experiments :
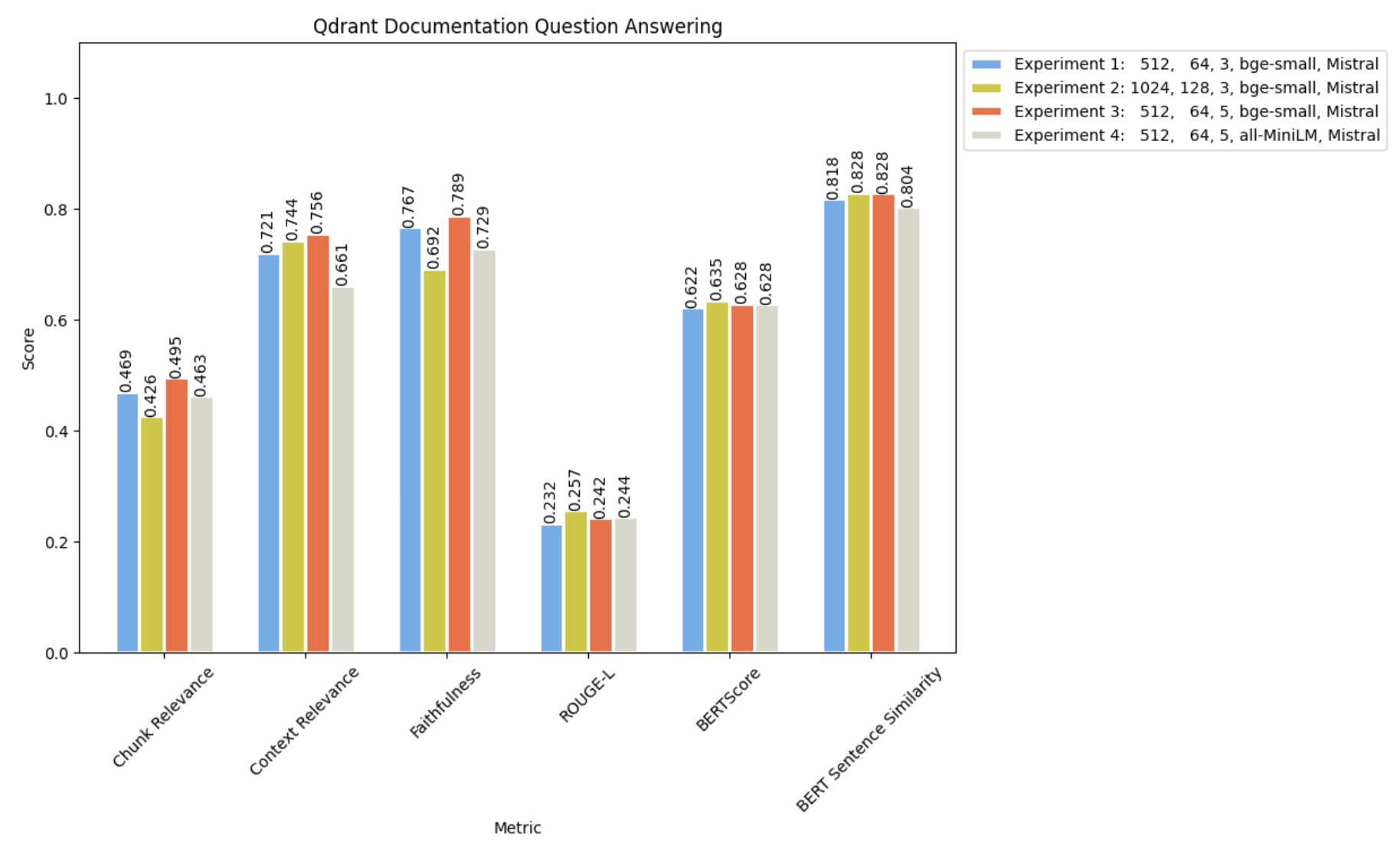
It appears that bge-small was more proficient in capturing the semantic nuances of the Qdrant Documentation.
Up to this point, our experimentation has focused solely on the retrieval aspect of our RAG pipeline. Now, let’s explore altering the generation aspect or LLM while retaining the optimal parameters identified in Experiment 3.
Experiment 5 - Changing the LLM
Parameters :
- Embedding Model :
bge-small-en - Chunk size:
512 - Chunk overlap:
64 - Number of docs retrieved (Retrieval Window):
5 - LLM: :
GPT-3.5-turbo
For this we can repurpose our collection from Experiment 3 while the evaluations to use a new recipe with GPT-3.5-turbo model.
#collection name from Experiment 3
COLLECTION_NAME = f"experiment_{chunk_size}_{chunk_overlap}_{embedding_model_name.split('/')[1]}"
# We have to create a recipe using the same prompt template and GPT-3.5-turbo
recipe_gpt = quotient.create_recipe(
model_id=5,
prompt_template_id=1,
name='gpt3.5-qa-with-rag-recipe-v1',
description='GPT-3.5 using a prompt template that includes context.'
)
recipe_gpt
#Outputs
#{'id': 495,
# 'name': 'gpt3.5-qa-with-rag-recipe-v1',
# 'description': 'GPT-3.5 using a prompt template that includes context.',
# 'model_id': 5,
# 'prompt_template_id': 1,
# 'created_at': '2024-05-03T12:14:58.779585',
# 'owner_profile_id': 34,
# 'system_prompt_id': None,
# 'prompt_template': {'id': 1,
# 'name': 'Default Question Answering Template',
# 'variables': '["input_text","context"]',
# 'created_at': '2023-12-21T22:01:54.632367',
# 'template_string': 'Question: {input_text}\\n\\nContext: {context}\\n\\nAnswer:',
# 'owner_profile_id': None},
# 'model': {'id': 5,
# 'name': 'gpt-3.5-turbo',
# 'endpoint': 'https://api.openai.com/v1/chat/completions',
# 'revision': 'placeholder',
# 'created_at': '2024-02-06T17:01:21.408454',
# 'model_type': 'OpenAI',
# 'description': 'Returns a maximum of 4K output tokens.',
# 'owner_profile_id': None,
# 'external_model_config_id': None,
# 'instruction_template_cls': 'NoneType'}}
Running the evaluations as :
experiment_5 = run_eval(eval_df,
collection_name=COLLECTION_NAME,
recipe_id=recipe_gpt['id'],
num_docs=num_docs,
path=f"{COLLECTION_NAME}_{num_docs}_gpt.csv")
We observe :
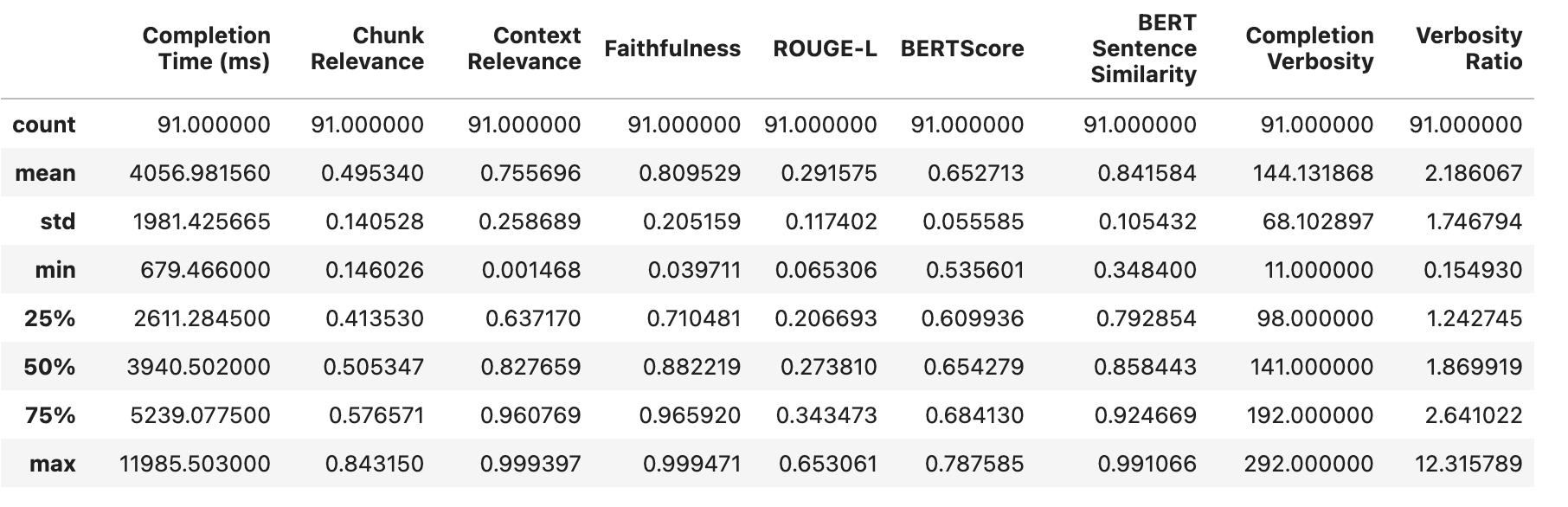
and comparing all the 5 experiments as below :
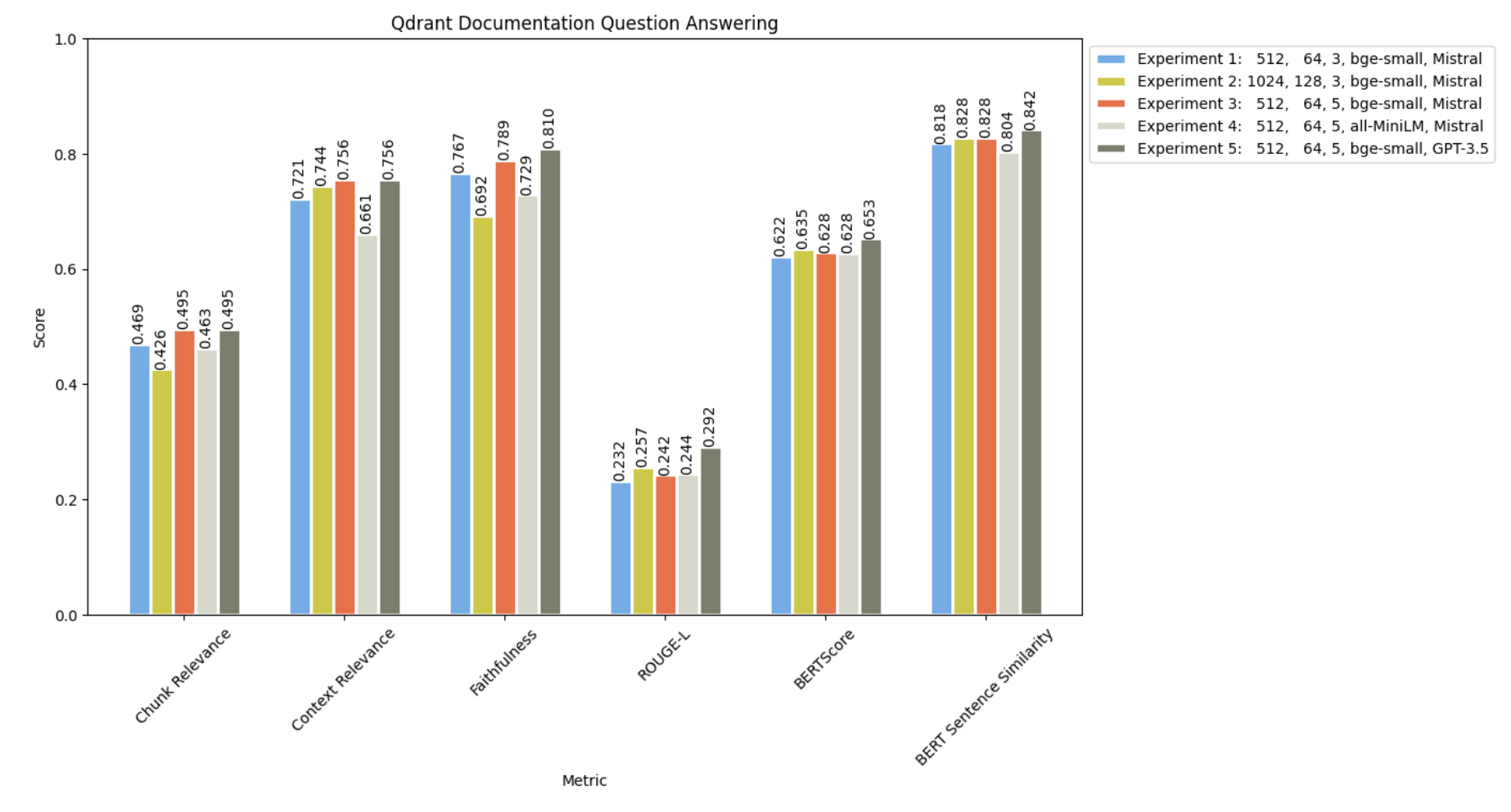
GPT-3.5 surpassed Mistral-7B in all metrics! Notably, Experiment 5 exhibited the lowest occurrence of hallucination.
Conclusions
Let’s take a look at our results from all 5 experiments above
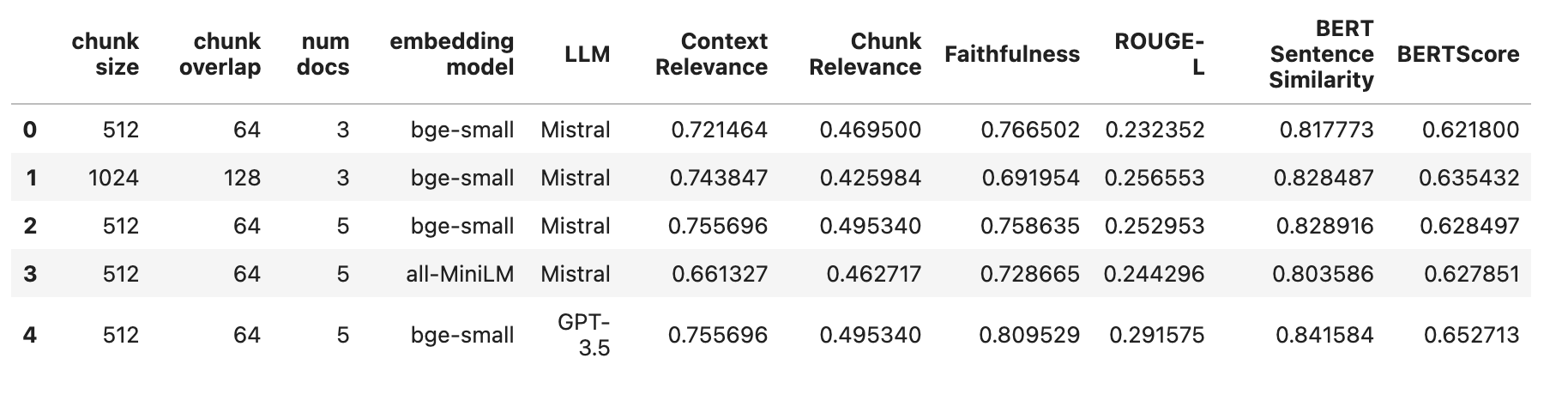
We still have a long way to go in improving the retrieval performance of RAG, as indicated by our generally poor results thus far. It might be beneficial to explore alternative embedding models or different retrieval strategies to address this issue.
The significant variations in Context Relevance suggest that certain questions may necessitate retrieving more documents than others. Therefore, investigating a dynamic retrieval strategy could be worthwhile.
Furthermore, there’s ongoing exploration required on the generative aspect of RAG. Modifying LLMs or prompts can substantially impact the overall quality of responses.
This iterative process demonstrates how, starting from scratch, continual evaluation and adjustments throughout experimentation can lead to the development of an enhanced RAG system.
Watch this workshop on YouTube
A workshop version of this article is available on YouTube. Follow along using our GitHub notebook.