































Qdrant 1.11 - The Vector Stronghold: Optimizing Data Structures for Scale and Efficiency
David Myriel
·August 12, 2024

On this page:
Qdrant 1.11.0 is out! This release largely focuses on features that improve memory usage and optimize segments. However, there are a few cool minor features, so let’s look at the whole list:
Optimized Data Structures:
Defragmentation: Storage for multitenant workloads is more optimized and scales better.
On-Disk Payload Index: Store less frequently used data on disk, rather than in RAM.
UUID for Payload Index: Additional data types for payload can result in big memory savings.
Improved Query API:
GroupBy Endpoint: Use this query method to group results by a certain payload field.
Random Sampling: Select a subset of data points from a larger dataset randomly.
Hybrid Search Fusion: We are adding the Distribution-Based Score Fusion (DBSF) method.
New Web UI Tools:
Search Quality Tool: Test the precision of your semantic search requests in real-time.
Graph Exploration Tool: Visualize vector search in context-based exploratory scenarios.
Quick Recap: Multitenant Workloads
Before we dive into the specifics of our optimizations, let’s first go over Multitenancy. This is one of our most significant features, best used for scaling and data isolation.
If you’re using Qdrant to manage data for multiple users, regions, or workspaces (tenants), we suggest setting up a multitenant environment. This approach keeps all tenant data in a single global collection, with points separated and isolated by their payload.
To avoid slow and unnecessary indexing, it’s better to create an index for each relevant payload rather than indexing the entire collection globally. Since some data is indexed more frequently, you can focus on building indexes for specific regions, workspaces, or users.
For more details on scaling best practices, read How to Implement Multitenancy and Custom Sharding.
Defragmentation of Tenant Storage
With version 1.11, Qdrant changes how vectors from the same tenant are stored on disk, placing them closer together for faster bulk reading and reduced scaling costs. This approach optimizes storage and retrieval operations for different tenants, leading to more efficient system performance and resource utilization.
Figure 1: Re-ordering by payload can significantly speed up access to hot and cold data.
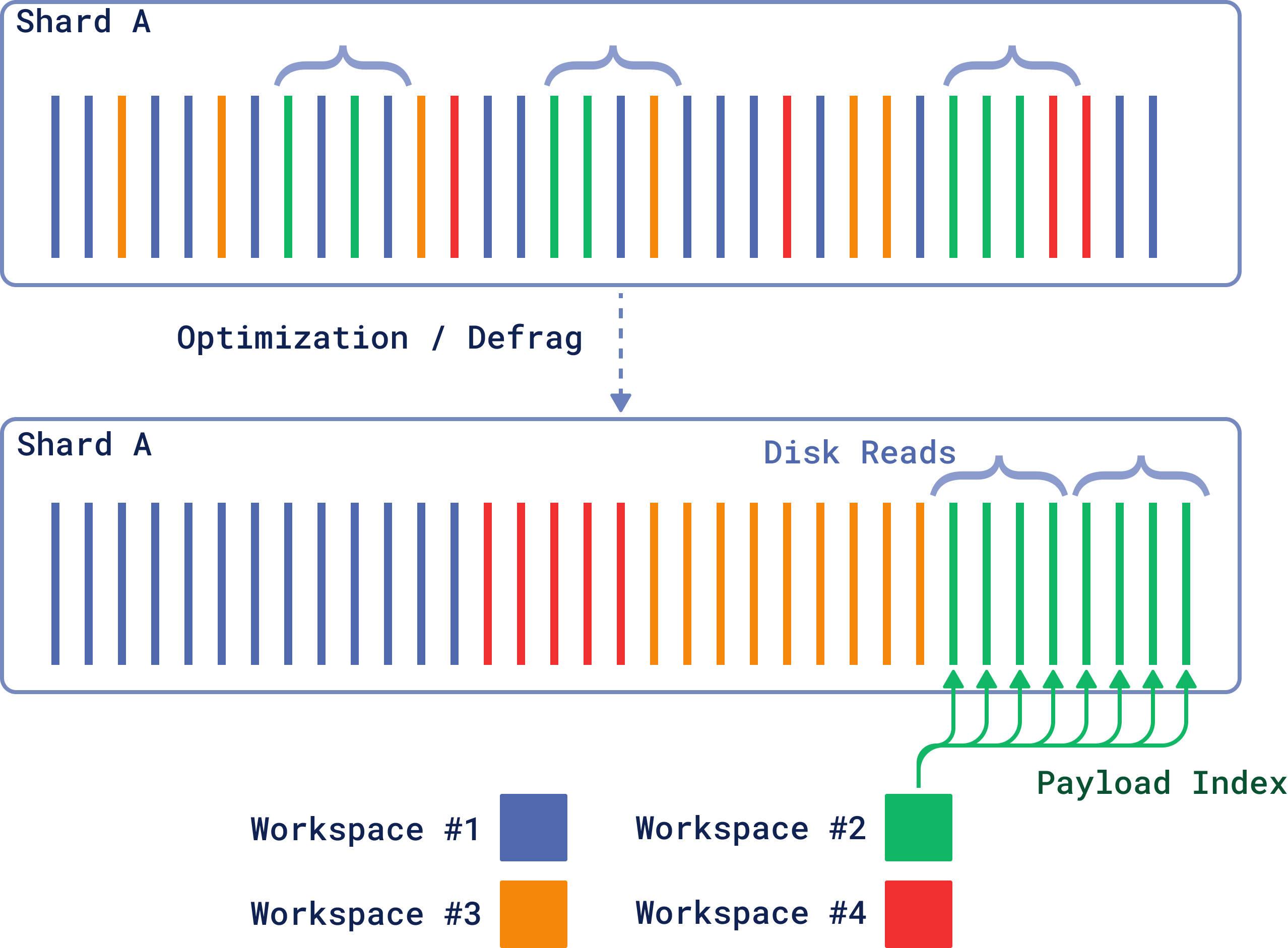
Example: When creating an index, you may set is_tenant=true. This configuration will optimize the storage based on your collection’s usage patterns.
PUT /collections/{collection_name}/index
{
"field_name": "group_id",
"field_schema": {
"type": "keyword",
"is_tenant": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="group_id",
field_schema=models.KeywordIndexParams(
type="keyword",
is_tenant=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "group_id",
field_schema: {
type: "keyword",
is_tenant: true,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
KeywordIndexParamsBuilder,
FieldType
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"group_id",
FieldType::Keyword,
).field_index_params(
KeywordIndexParamsBuilder::default()
.is_tenant(true)
)
).await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"group_id",
PayloadSchemaType.Keyword,
PayloadIndexParams.newBuilder()
.setKeywordIndexParams(
KeywordIndexParams.newBuilder()
.setIsTenant(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "group_id",
schemaType: PayloadSchemaType.Keyword,
indexParams: new PayloadIndexParams
{
KeywordIndexParams = new KeywordIndexParams
{
IsTenant = true
}
}
);
As a result, the storage structure will be organized in a way to co-locate vectors of the same tenant together at the next optimization.
To learn more about defragmentation, read the Multitenancy documentation.
On-Disk Support for the Payload Index
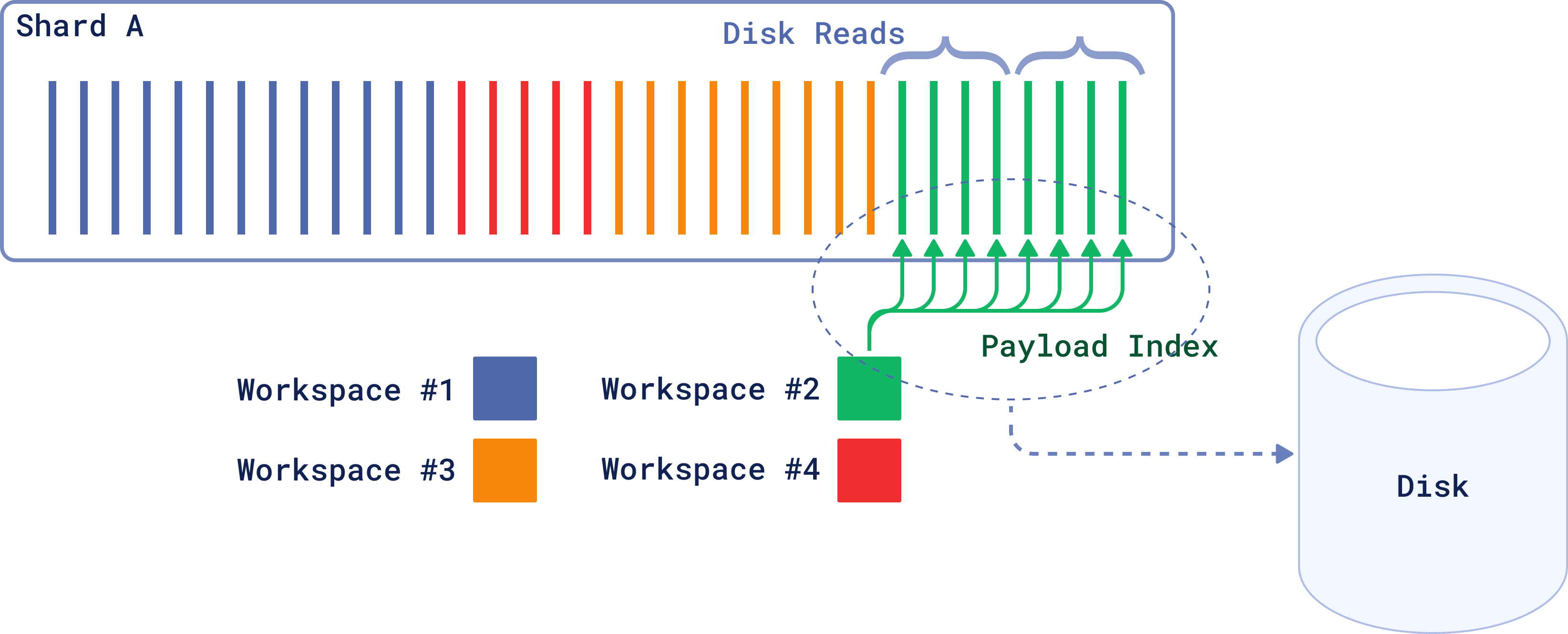
When managing billions of records across millions of tenants, keeping all data in RAM is inefficient. That is especially true when only a small subset is frequently accessed. As of 1.11, you can offload “cold” data to disk and cache the “hot” data in RAM.
This feature can help you manage a high number of different payload indexes, which is beneficial if you are working with large varied datasets.
Figure 2: By moving the data from Workspace 2 to disk, the system can free up valuable memory resources for Workspaces 1, 3 and 4, which are accessed more frequently.
Example: As you create an index for Workspace 2, set the on_disk parameter.
PUT /collections/{collection_name}/index
{
"field_name": "group_id",
"field_schema": {
"type": "keyword",
"is_tenant": true,
"on_disk": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="group_id",
field_schema=models.KeywordIndexParams(
type="keyword",
is_tenant=True,
on_disk=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "group_id",
field_schema: {
type: "keyword",
is_tenant: true,
on_disk: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
KeywordIndexParamsBuilder,
FieldType
};
use qdrant_client::{Qdrant, QdrantError};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"group_id",
FieldType::Keyword,
)
.field_index_params(
KeywordIndexParamsBuilder::default()
.is_tenant(true)
.on_disk(true),
),
);
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"group_id",
PayloadSchemaType.Keyword,
PayloadIndexParams.newBuilder()
.setKeywordIndexParams(
KeywordIndexParams.newBuilder()
.setIsTenant(true)
.setOnDisk(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "group_id",
schemaType: PayloadSchemaType.Keyword,
indexParams: new PayloadIndexParams
{
KeywordIndexParams = new KeywordIndexParams
{
IsTenant = true,
OnDisk = true
}
}
);
By moving the index to disk, Qdrant can handle larger datasets that exceed the capacity of RAM, making the system more scalable and capable of storing more data without being constrained by memory limitations.
To learn more about this, read the Indexing documentation.
UUID Datatype for the Payload Index
Many Qdrant users rely on UUIDs in their payloads, but storing these as strings comes with a substantial memory overhead—approximately 36 bytes per UUID. In reality, UUIDs only require 16 bytes of storage when stored as raw bytes.
To address this inefficiency, we’ve developed a new index type tailored specifically for UUIDs that stores them internally as bytes, reducing memory usage by up to 2.25x.
Example: When adding two separate points, indicate their UUID in the payload. In this example, both data points belong to the same user (with the same UUID).
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"vector": [0.05, 0.61, 0.76, 0.74],
"payload": {"id": 550e8400-e29b-41d4-a716-446655440000}
},
{
"id": 2,
"vector": [0.19, 0.81, 0.75, 0.11],
"payload": {"id": 550e8400-e29b-41d4-a716-446655440000}
},
]
}
For organizations that have numerous users and UUIDs, this simple fix can significantly reduce the cluster size and improve efficiency.
To learn more about this, read the Payload documentation.
Query API: Groups Endpoint
When searching over data, you can group results by specific payload field, which is useful when you have multiple data points for the same item and you want to avoid redundant entries in the results.
Example: If a large document is divided into several chunks, and you need to search or make recommendations on a per-document basis, you can group the results by the document_id.
POST /collections/{collection_name}/points/query/groups
{
"query": [0.01, 0.45, 0.67],
group_by="document_id", # Path of the field to group by
limit=4, # Max amount of groups
group_size=2, # Max amount of points per group
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points_groups(
collection_name="{collection_name}",
query=[0.01, 0.45, 0.67],
group_by="document_id",
limit=4,
group_size=2,
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.queryGroups("{collection_name}", {
query: [0.01, 0.45, 0.67],
group_by: "document_id",
limit: 4,
group_size: 2,
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{Query, QueryPointsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.query_groups(
QueryPointGroupsBuilder::new("{collection_name}", "document_id")
.query(Query::from(vec![0.01, 0.45, 0.67]))
.limit(4u64)
.group_size(2u64)
).await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QueryPointGroups;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.queryGroupsAsync(
QueryPointGroups.newBuilder()
.setCollectionName("{collection_name}")
.setGroupBy("document_id")
.setQuery(nearest(0.01f, 0.45f, 0.67f))
.setLimit(4)
.setGroupSize(2)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryGroupsAsync(
collectionName: "{collection_name}",
groupBy: "document_id",
query: new float[] {
0.01f, 0.45f, 0.67f
},
limit: 4,
groupSize: 2
);
This endpoint will retrieve the best N points for each document, assuming that the payload of the points contains the document ID. Sometimes, the best N points cannot be fulfilled due to lack of points or a big distance with respect to the query. In every case, the group_size is a best-effort parameter, similar to the limit parameter.
For more information on grouping capabilities refer to our Hybrid Queries documentation.
Query API: Random Sampling
Our Food Discovery Demo always shows a random sample of foods from the larger dataset. Now you can do the same and set the randomization from a basic Query API endpoint.
When calling the Query API, you will be able to select a subset of data points from a larger dataset randomly.
This technique is often used to reduce the computational load, improve query response times, or provide a representative sample of the data for various analytical purposes.
Example: When querying the collection, you can configure it to retrieve a random sample of data.
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
# Random sampling (as of 1.11.0)
sampled = client.query_points(
collection_name="{collection_name}",
query=models.SampleQuery(sample=models.Sample.Random)
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
let sampled = client.query("{collection_name}", {
query: { sample: "random" },
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{Query, QueryPointsBuilder, Sample};
let client = Qdrant::from_url("http://localhost:6334").build()?;
let sampled = client
.query(
QueryPointsBuilder::new("{collection_name}").query(Query::new_sample(Sample::Random)),
)
.await?;
import static io.qdrant.client.QueryFactory.sample;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.Sample;
import io.qdrant.client.grpc.Points.QueryPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(sample(Sample.Random))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: Sample.Random
);
To learn more, check out the Query API documentation.
Query API: Distribution-Based Score Fusion
In version 1.10, we added Reciprocal Rank Fusion (RRF) as a way of fusing results from Hybrid Queries. Now we are adding Distribution-Based Score Fusion (DBSF). Michelangiolo Mazzeschi talks more about this fusion method in his latest Medium article.
DBSF normalizes the scores of the points in each query, using the mean +/- the 3rd standard deviation as limits, and then sums the scores of the same point across different queries.
Example: To fuse prefetch results from sparse and dense queries, set "fusion": "dbsf"
POST /collections/{collection_name}/points/query
{
"prefetch": [
{
"query": {
"indices": [1, 42], // <┐
"values": [0.22, 0.8] // <┴─Sparse vector
},
"using": "sparse",
"limit": 20
},
{
"query": [0.01, 0.45, 0.67, ...], // <-- Dense vector
"using": "dense",
"limit": 20
}
],
"query": { "fusion": “dbsf" }, // <--- Distribution Based Score Fusion
"limit": 10
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
prefetch=[
models.Prefetch(
query=models.SparseVector(indices=[1, 42], values=[0.22, 0.8]),
using="sparse",
limit=20,
),
models.Prefetch(
query=[0.01, 0.45, 0.67, ...], # <-- dense vector
using="dense",
limit=20,
),
],
query=models.FusionQuery(fusion=models.Fusion.DBSF),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
prefetch: [
{
query: {
values: [0.22, 0.8],
indices: [1, 42],
},
using: 'sparse',
limit: 20,
},
{
query: [0.01, 0.45, 0.67],
using: 'dense',
limit: 20,
},
],
query: {
fusion: 'dbsf',
},
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{Fusion, PrefetchQueryBuilder, Query, QueryPointsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.query(
QueryPointsBuilder::new("{collection_name}")
.add_prefetch(PrefetchQueryBuilder::default()
.query(Query::new_nearest([(1, 0.22), (42, 0.8)].as_slice()))
.using("sparse")
.limit(20u64)
)
.add_prefetch(PrefetchQueryBuilder::default()
.query(Query::new_nearest(vec![0.01, 0.45, 0.67]))
.using("dense")
.limit(20u64)
)
.query(Query::new_fusion(Fusion::Dbsf))
).await?;
import static io.qdrant.client.QueryFactory.nearest;
import java.util.List;
import static io.qdrant.client.QueryFactory.fusion;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.Fusion;
import io.qdrant.client.grpc.Points.PrefetchQuery;
import io.qdrant.client.grpc.Points.QueryPoints;
QdrantClient client = new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.addPrefetch(PrefetchQuery.newBuilder()
.setQuery(nearest(List.of(0.22f, 0.8f), List.of(1, 42)))
.setUsing("sparse")
.setLimit(20)
.build())
.addPrefetch(PrefetchQuery.newBuilder()
.setQuery(nearest(List.of(0.01f, 0.45f, 0.67f)))
.setUsing("dense")
.setLimit(20)
.build())
.setQuery(fusion(Fusion.DBSF))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
prefetch: new List < PrefetchQuery > {
new() {
Query = new(float, uint)[] {
(0.22f, 1), (0.8f, 42),
},
Using = "sparse",
Limit = 20
},
new() {
Query = new float[] {
0.01f, 0.45f, 0.67f
},
Using = "dense",
Limit = 20
}
},
query: Fusion.Dbsf
);
Note that dbsf is stateless and calculates the normalization limits only based on the results of each query, not on all the scores that it has seen.
To learn more, check out the Hybrid Queries documentation.
Web UI: Search Quality Tool
We have updated the Qdrant Web UI with additional testing functionality. Now you can check the quality of your search requests in real time and measure it against exact search.
Try it: In the Dashboard, go to collection settings and test the Precision from the Search Quality menu tab.
The feature will conduct a semantic search for each point and produce a report below.
Web UI: Graph Exploration Tool
Deeper exploration is highly dependent on expanding context. This is something we previously covered in the Discovery Needs Context article earlier this year. Now, we have developed a UI feature to help you visualize how semantic search can be used for exploratory and recommendation purposes.
Try it: Using the feature is pretty self-explanatory. Each collection’s dataset can be explored from the Graph tab. As you see the images change, you can steer your search in the direction of specific characteristics that interest you.
Search results will become more “distilled” and tailored to your preferences.
Next Steps
If you’re new to Qdrant, now is the perfect time to start. Check out our documentation guides and see why Qdrant is the go-to solution for vector search.
We’re very happy to bring you this latest version of Qdrant, and we can’t wait to see what you build with it. As always, your feedback is invaluable—feel free to reach out with any questions or comments on our community forum.
