Indexing
A key feature of Qdrant is the effective combination of vector and traditional indexes. It is essential to have this because for vector search to work effectively with filters, having a vector index only is not enough. In simpler terms, a vector index speeds up vector search, and payload indexes speed up filtering.
The indexes in the segments exist independently, but the parameters of the indexes themselves are configured for the whole collection.
Not all segments automatically have indexes. Their necessity is determined by the optimizer settings and depends, as a rule, on the number of stored points.
Payload Index
Payload index in Qdrant is similar to the index in conventional document-oriented databases. This index is built for a specific field and type, and is used for quick point requests by the corresponding filtering condition. The index is also used to accurately estimate the filter cardinality, which helps the query planning choose a search strategy.
Creating an index requires additional computational resources and memory, so choosing fields to be indexed is essential. Qdrant does not make this choice but grants it to the user.
The following field types support payload indexing:
keyword- for keyword payload, affects Match filtering conditions.integer- for integer payload, affects Match and Range filtering conditions.float- for float payload, affects Range filtering conditions.bool- for bool payload, affects Match filtering conditions (available as of v1.4.0).geo- for geo payload, affects Geo Bounding Box and Geo Radius filtering conditions.datetime- for datetime payload, affects Range filtering conditions (available as of v1.8.0).text- a special kind of index, available for keyword / string payloads, affects Full Text search filtering conditions. Read more about text index configurationuuid- a special type of index, similar tokeyword, but optimized for UUID values. Affects Match filtering conditions. (available as of v1.11.0)
Payload indexes occupy additional memory and disk space, so it is recommended to only apply payload indexes for those fields that are used in filtering conditions. If you need to filter by many fields and the memory limits do not allow for indexing all of them, it is recommended to choose the field that limits the search result the most. As a rule, the more different values a payload value has, the more efficiently the index will be used.
Create a Payload Index
To create a payload index for a field:
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": "keyword"
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.PayloadSchemaType.KEYWORD,
)
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: "keyword",
});
use qdrant_client::qdrant::{CreateFieldIndexCollectionBuilder, FieldType};
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Keyword,
)
.wait(true),
)
.await?;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
client.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Keyword,
null,
true,
null,
null);
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index"
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
})
You can use dot notation to specify a nested field for indexing. Similar to specifying nested filters.
When the payload keys themselves are open-ended, indexing each key separately does not scale. Reshape the keys into values under a fixed field and index it at collection setup. See Indexing Payloads of Random Shape for the modeling pattern.
Payload indexes should be created before ingesting data. Qdrant’s filterable HNSW index only benefits from additional filter-aware edges when it is generated after the payload indexes have been created. If you create a payload index after data has already been ingested, you need to rebuild the HNSW index to take advantage of the new payload indexes.
Block Queries That Filter on Unindexed Fields
Queries that filter on unindexed fields are not only slower; they can also unnecessarily consume cluster resources, negatively impacting the latency of other search queries. To prevent that, Qdrant provides an option to block queries that filter on unindexed fields. This gives you:
- Fail-fast behavior: Queries that would degrade performance are rejected at the API boundary, surfacing misconfigured indexes as errors rather than latency spikes.
- Performance guarantees: Every query that succeeds is backed by an index, preventing accidental filters on unindexed fields from reaching production.
- Operational visibility: Without strict mode, a missing index might go unnoticed for a long time because queries still return results, albeit slowly.
To block queries that filter on unindexed fields, enable strict mode and set unindexed_filtering_retrieve to false. Qdrant will then return an error if a search query attempts to filter on an unindexed field. On Qdrant Cloud, these settings are applied to all collections by default.
For more information, refer to Disable Retrieving via Non Indexed Payload.
Parameterized Index
Available as of v1.8.0
We’ve added a parameterized variant to the integer index, which allows
you to fine-tune indexing and search performance.
Both the regular and parameterized integer indexes use the following flags:
lookup: enables support for direct lookup using Match filters.range: enables support for Range filters.
The regular integer index assumes both lookup and range are true. In
contrast, to configure a parameterized index, you would set only one of these
filters to true:
lookup | range | Result |
|---|---|---|
true | true | Regular integer index |
true | false | Parameterized integer index |
false | true | Parameterized integer index |
false | false | No integer index |
Setting lookup or range to false may help to tune and reduce memory usage
in large collections. We encourage you to try out if setting either to false
improves memory usage. If you don’t see an improvement or if you’re not sure
what kind of payload filters you’re using, use the regular integer index.
Note: If you set "range": false and still use a range filter, it may lead to
significant performance issues. The same is true for the lookup parameter and
its respective filters.
For example, the following code sets up a parameterized integer index which supports only range filters:
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "integer",
"lookup": false,
"range": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.IntegerIndexParams(
type=models.IntegerIndexType.INTEGER,
lookup=False,
range=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "integer",
lookup: false,
range: true,
},
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder, FieldType, IntegerIndexParamsBuilder,
};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Integer,
)
.field_index_params(IntegerIndexParamsBuilder::new(false, true).build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.IntegerIndexParams;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Integer,
PayloadIndexParams.newBuilder()
.setIntegerIndexParams(
IntegerIndexParams.newBuilder().setLookup(false).setRange(true).build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Integer,
indexParams: new PayloadIndexParams
{
IntegerIndexParams = new()
{
Lookup = false,
Range = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeInteger.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsInt(
&qdrant.IntegerIndexParams{
Lookup: qdrant.PtrOf(false),
Range: qdrant.PtrOf(true),
}),
})
On-Disk Payload Index
Available as of v1.11.0
By default all payload-related structures are stored in memory. In this way, the vector index can quickly access payload values during search. As latency in this case is critical, it is recommended to keep hot payload indexes in memory.
There are, however, cases when payload indexes are too large or rarely used. In those cases, it is possible to store payload indexes on disk.
To configure on-disk payload index, you can use the following index parameters:
PUT /collections/{collection_name}/index
{
"field_name": "payload_field_name",
"field_schema": {
"type": "keyword",
"on_disk": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="payload_field_name",
field_schema=models.KeywordIndexParams(
type=models.KeywordIndexType.KEYWORD,
on_disk=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "payload_field_name",
field_schema: {
type: "keyword",
on_disk: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
KeywordIndexParamsBuilder,
FieldType
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"payload_field_name",
FieldType::Keyword,
)
.field_index_params(
KeywordIndexParamsBuilder::default()
.on_disk(true),
),
).await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"payload_field_name",
PayloadSchemaType.Keyword,
PayloadIndexParams.newBuilder()
.setKeywordIndexParams(
KeywordIndexParams.newBuilder()
.setOnDisk(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "payload_field_name",
schemaType: PayloadSchemaType.Keyword,
indexParams: new PayloadIndexParams
{
KeywordIndexParams = new KeywordIndexParams
{
OnDisk = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsKeyword(
&qdrant.KeywordIndexParams{
OnDisk: qdrant.PtrOf(true),
}),
})
Payload index on-disk is supported for the following types:
keywordintegerfloatdatetimeuuidtextgeo
The list will be extended in future versions.
Tenant Index
Available as of v1.11.0
Many vector search use-cases require multitenancy. In a multi-tenant scenario the collection is expected to contain multiple subsets of data, where each subset belongs to a different tenant.
Qdrant supports efficient multi-tenant search by enabling special configuration vector index, which disables global search and only builds sub-indexes for each tenant.
However, knowing that the collection contains multiple tenants unlocks more opportunities for optimization. To optimize storage in Qdrant further, you can enable tenant indexing for payload fields.
This option will tell Qdrant which fields are used for tenant identification and will allow Qdrant to structure storage for faster search of tenant-specific data. One example of such optimization is localizing tenant-specific data closer on disk, which will reduce the number of disk reads during search.
To enable tenant index for a field, you can use the following index parameters:
PUT /collections/{collection_name}/index
{
"field_name": "payload_field_name",
"field_schema": {
"type": "keyword",
"is_tenant": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="payload_field_name",
field_schema=models.KeywordIndexParams(
type=models.KeywordIndexType.KEYWORD,
is_tenant=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "payload_field_name",
field_schema: {
type: "keyword",
is_tenant: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
KeywordIndexParamsBuilder,
FieldType
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"payload_field_name",
FieldType::Keyword,
)
.field_index_params(
KeywordIndexParamsBuilder::default()
.is_tenant(true),
),
).await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"payload_field_name",
PayloadSchemaType.Keyword,
PayloadIndexParams.newBuilder()
.setKeywordIndexParams(
KeywordIndexParams.newBuilder()
.setIsTenant(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "payload_field_name",
schemaType: PayloadSchemaType.Keyword,
indexParams: new PayloadIndexParams
{
KeywordIndexParams = new KeywordIndexParams
{
IsTenant = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsKeyword(
&qdrant.KeywordIndexParams{
IsTenant: qdrant.PtrOf(true),
}),
})
Tenant optimization is supported for the following datatypes:
keyworduuid
Principal Index
Available as of v1.11.0
Similar to the tenant index, the principal index is used to optimize storage for faster search, assuming that the search request is primarily filtered by the principal field.
A good example of a use case for the principal index is time-related data, where each point is associated with a timestamp. In this case, the principal index can be used to optimize storage for faster search with time-based filters.
PUT /collections/{collection_name}/index
{
"field_name": "timestamp",
"field_schema": {
"type": "integer",
"is_principal": true
}
}
client.create_payload_index(
collection_name="{collection_name}",
field_name="timestamp",
field_schema=models.IntegerIndexParams(
type=models.IntegerIndexType.INTEGER,
is_principal=True,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "timestamp",
field_schema: {
type: "integer",
is_principal: true
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
IntegerIndexParamsBuilder,
FieldType
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"timestamp",
FieldType::Integer,
)
.field_index_params(
IntegerIndexParamsBuilder::default()
.is_principal(true),
),
).await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.IntegerIndexParams;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"timestamp",
PayloadSchemaType.Integer,
PayloadIndexParams.newBuilder()
.setIntegerIndexParams(
IntegerIndexParams.newBuilder()
.setIsPrincipal(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "timestamp",
schemaType: PayloadSchemaType.Integer,
indexParams: new PayloadIndexParams
{
IntegerIndexParams = new IntegerIndexParams
{
IsPrincipal = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeInteger.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsInt(
&qdrant.IntegerIndexParams{
IsPrincipal: qdrant.PtrOf(true),
}),
})
Principal optimization is supported for following types:
integerfloatdatetime
Full-Text Index
Qdrant supports full-text search for string payload. Full-text index allows you to filter points by the presence of a word or a phrase in the payload field.
Full-text index configuration is a bit more complex than other indexes, as you can specify the tokenization parameters. Tokenization is the process of splitting a string into tokens, which are then indexed in the inverted index.
See Full Text match for examples of querying with a full-text index.
To create a full-text index, you can use the following:
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"min_token_len": 2,
"max_token_len": 10,
"lowercase": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type=models.TextIndexType.TEXT,
tokenizer=models.TokenizerType.WORD,
min_token_len=2,
max_token_len=10,
lowercase=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
min_token_len: 2,
max_token_len: 10,
lowercase: true,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.min_token_len(2)
.max_token_len(10)
.lowercase(true);
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setMinTokenLen(2)
.setMaxTokenLen(10)
.setLowercase(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
MinTokenLen = 2,
MaxTokenLen = 10,
Lowercase = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Whitespace,
MinTokenLen: qdrant.PtrOf(uint64(2)),
MaxTokenLen: qdrant.PtrOf(uint64(10)),
Lowercase: qdrant.PtrOf(true),
}),
})
Tokenizers
Tokenizers are algorithms used to split text into smaller units called tokens, which are then indexed and searched in a full-text index. In the context of Qdrant, tokenizers determine how string payloads are broken down for efficient searching and filtering. The choice of tokenizer affects how queries match the indexed text, supporting different languages, word boundaries, and search behaviours such as prefix or phrase matching.
Available tokenizers are:
word(default) - splits the string into words, separated by spaces, punctuation marks, and special characters.whitespace- splits the string into words, separated by spaces.prefix- splits the string into words, separated by spaces, punctuation marks, and special characters, and then creates a prefix index for each word. For example:hellowill be indexed ash,he,hel,hell,hello.multilingual- a special type of tokenizer based on multiple packages like charabia and vaporetto to deliver fast and accurate tokenization for a large variety of languages. It allows proper tokenization and lemmatization for multiple languages, including those with non-Latin alphabets and non-space delimiters. See the charabia documentation for a full list of supported languages and normalization options. Note: For the Japanese language, Qdrant relies on thevaporettoproject, which has much less overhead compared tocharabia, while maintaining comparable performance.
Lowercasing
By default, full-text search in Qdrant is case-insensitive. For example, users can search for the lowercase term tv and find text fields containing the uppercase word TV. Case-insensitivity is achieved by converting both the words in the index and the query terms to lowercase.
Lowercasing is enabled by default. To use case-sensitive full-text search, configure a full-text index with lowercase set to false.
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"lowercase": false
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type=models.TextIndexType.TEXT,
tokenizer=models.TokenizerType.WORD,
lowercase=False,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
lowercase: false,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.lowercase(false);
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setLowercase(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Lowercase = true,
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Word,
Lowercase: qdrant.PtrOf(true),
}),
})
ASCII Folding
Available as of v1.16.0
When enabled, ASCII folding converts Unicode characters into their corresponding ASCII equivalents, for example, by removing diacritics. For instance, the character ã is changed into a, ç becomes c, and é is converted to e.
Because ASCII folding is applied to both the words in the index and the query terms, it increases recall. For example, users can search for cafe and also find text fields containing the word café.
ASCII folding is not enabled by default. To enable it, configure a full-text index with ascii_folding set to true.
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"ascii_folding": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type=models.TextIndexType.TEXT,
tokenizer=models.TokenizerType.WORD,
ascii_folding=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
ascii_folding: true,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.ascii_folding(true);
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setLowercase(true)
.setAsciiFolding(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Lowercase = true,
AsciiFolding = true,
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Word,
Lowercase: qdrant.PtrOf(true),
AsciiFolding: qdrant.PtrOf(true),
}),
})
Stemmer
A stemmer is an algorithm used in text processing to reduce words to their root or base form, known as the “stem.” For example, the words “running”, “runner and “runs” can all be reduced to the stem “run.” When configuring a full-text index in Qdrant, you can specify a stemmer to be used for a particular language. This enables the index to recognize and match different inflections or derivations of a word.
Qdrant provides an implementation of Snowball stemmer, a widely used and performant variant for some of the most popular languages. For the list of supported languages, please visit the rust-stemmers repository.
For full-text indices, stemming is not enabled by default. To enable it, configure the snowball stemmer with the desired language:
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"stemmer": {
"type": "snowball",
"language": "english"
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type=models.TextIndexType.TEXT,
tokenizer=models.TokenizerType.WORD,
stemmer=models.SnowballParams(
type=models.Snowball.SNOWBALL,
language=models.SnowballLanguage.ENGLISH
)
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
stemmer: {
type: "snowball",
language: "english"
}
}
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.snowball_stemmer("english".to_string());
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"{field_name}",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.SnowballParams;
import io.qdrant.client.grpc.Collections.StemmingAlgorithm;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setStemmer(
StemmingAlgorithm.newBuilder()
.setSnowball(
SnowballParams.newBuilder().setLanguage("english").build())
.build())
.build())
.build(),
true,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Stemmer = new StemmingAlgorithm
{
Snowball = new SnowballParams
{
Language = "english"
}
}
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Word,
Stemmer: qdrant.NewStemmingAlgorithmSnowball(&qdrant.SnowballParams{
Language: "english",
}),
}),
})
Stopwords
Stopwords are common words (such as “the”, “is”, “at”, “which”, and “on”) that are often filtered out during text processing because they carry little meaningful information for search and retrieval tasks.
In Qdrant, you can specify a list of stopwords to be ignored during full-text indexing and search. This helps simplify search queries and improves relevance.
You can configure stopwords based on predefined languages, as well as extend existing stopword lists with custom words.
For full-text indices, stopword removal is not enabled by default. To enable it, configure the stopwords parameter with the desired languages and any custom stopwords:
// Simple
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"stopwords": "english"
}
}
// Explicit
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"stopwords": {
"languages": [
"english",
"spanish"
],
"custom": [
"example"
]
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
# Simple
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type=models.TextIndexType.TEXT,
tokenizer=models.TokenizerType.WORD,
stopwords=models.Language.ENGLISH,
),
)
# Explicit
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type=models.TextIndexType.TEXT,
tokenizer=models.TokenizerType.WORD,
stopwords=models.StopwordsSet(
languages=[
models.Language.ENGLISH,
models.Language.SPANISH,
],
custom=[
"example"
]
),
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
// Simple
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
stopwords: "english"
},
});
// Explicit
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
stopwords: {
languages: [
"english",
"spanish"
],
custom: [
"example"
]
}
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
StopwordsSet,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
// Simple
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.stopwords_language("english".to_string());
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
// Explicit
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.stopwords(StopwordsSet {
languages: vec![
"english".to_string(),
"spanish".to_string(),
],
custom: vec!["example".to_string()],
});
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"{field_name}",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.StopwordsSet;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
import java.util.List;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setStopwords(
StopwordsSet.newBuilder()
.addAllLanguages(List.of("english", "spanish"))
.addAllCustom(List.of("example"))
.build())
.build())
.build(),
true,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Stopwords = new StopwordsSet
{
Languages = { "english", "spanish" },
Custom = { "example" }
}
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Word,
Stopwords: &qdrant.StopwordsSet{
Languages: []string{"english", "spanish"},
Custom: []string{"example"},
},
}),
})
Phrase Search
Phrase search in Qdrant allows you to find documents or points where a specific sequence of words appears together, in the same order, within a text payload field. This is useful when you want to match exact phrases rather than individual words scattered throughout the text.
When using a full-text index with phrase search enabled, you can perform phrase search by enclosing the desired phrase in double quotes in your filter query.
For example, searching for "machine learning" will only return results where the words “machine” and “learning” appear together as a phrase, not just anywhere in the text.
For efficient phrase search, Qdrant requires building an additional data structure, so it needs to be configured during the creation of the full-text index:
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "text",
"tokenizer": "word",
"lowercase": true,
"phrase_matching": true
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type=models.TextIndexType.TEXT,
tokenizer=models.TokenizerType.WORD,
lowercase=True,
phrase_matching=True,
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "text",
tokenizer: "word",
lowercase: true,
phrase_matching: true,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder,
TextIndexParamsBuilder,
FieldType,
TokenizerType,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
let text_index_params = TextIndexParamsBuilder::new(TokenizerType::Word)
.phrase_matching(true)
.lowercase(true);
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Text,
).field_index_params(text_index_params.build()),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
import io.qdrant.client.grpc.Collections.TextIndexParams;
import io.qdrant.client.grpc.Collections.TokenizerType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Text,
PayloadIndexParams.newBuilder()
.setTextIndexParams(
TextIndexParams.newBuilder()
.setTokenizer(TokenizerType.Word)
.setLowercase(true)
.setPhraseMatching(true)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Text,
indexParams: new PayloadIndexParams
{
TextIndexParams = new TextIndexParams
{
Tokenizer = TokenizerType.Word,
Lowercase = true,
PhraseMatching = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeText.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsText(
&qdrant.TextIndexParams{
Tokenizer: qdrant.TokenizerType_Whitespace,
Lowercase: qdrant.PtrOf(true),
PhraseMatching: qdrant.PtrOf(true),
}),
})
See Phrase Match for examples of querying phrases with a full-text index.
Vector Index
A vector index is a data structure built on vectors through a specific mathematical model. Through the vector index, we can efficiently query several vectors similar to the target vector.
Qdrant currently only uses HNSW as a dense vector index.
HNSW (Hierarchical Navigable Small World Graph) is a graph-based indexing algorithm. It builds a multi-layer navigation structure for an image according to certain rules. In this structure, the upper layers are more sparse and the distances between nodes are farther. The lower layers are denser and the distances between nodes are closer. The search starts from the uppermost layer, finds the node closest to the target in this layer, and then enters the next layer to begin another search. After multiple iterations, it can quickly approach the target position.
In order to improve performance, HNSW limits the maximum degree of nodes on each layer of the graph to m. In addition, you can use ef_construct (when building an index) or ef (when searching targets) to specify a search range.
The corresponding parameters could be configured in the configuration file:
storage:
# Default parameters of HNSW Index. Could be overridden for each collection or named vector individually
hnsw_index:
# Number of edges per node in the index graph.
# Larger the value - more accurate the search, more space required.
m: 16
# Number of neighbours to consider during the index building.
# Larger the value - more accurate the search, more time required to build index.
ef_construct: 100
# Minimal size threshold (in KiloBytes) below which full-scan is preferred over HNSW search.
# This measures the total size of vectors being queried against.
# When the maximum estimated amount of points that a condition satisfies is smaller than
# `full_scan_threshold_kb`, the query planner will use full-scan search instead of HNSW index
# traversal for better performance.
# Note: 1Kb = 1 vector of size 256
full_scan_threshold: 10000
And so in the process of creating a collection. The ef parameter is configured during the search and by default is equal to ef_construct.
HNSW is chosen for several reasons. First, HNSW is well-compatible with the modification that allows Qdrant to use filters during a search. Second, it is one of the most accurate and fastest algorithms, according to public benchmarks.
Available as of v1.1.1
The HNSW parameters can also be configured on a collection and named vector
level by setting hnsw_config to fine-tune search
performance.
Filterable HNSW Index
Separately, a payload index and a vector index cannot completely address the challenges of filtered search.
In the case of high-selectivity (weak) filters, you can use the HNSW index as it is. In the case of low-selectivity (strict) filters, you can use the payload index and do a complete rescore. However, for cases in the middle, this approach does not work well. On one hand, we cannot apply a full scan on too many vectors. On the other hand, the HNSW graph starts to fall apart when using filters that are too strict.
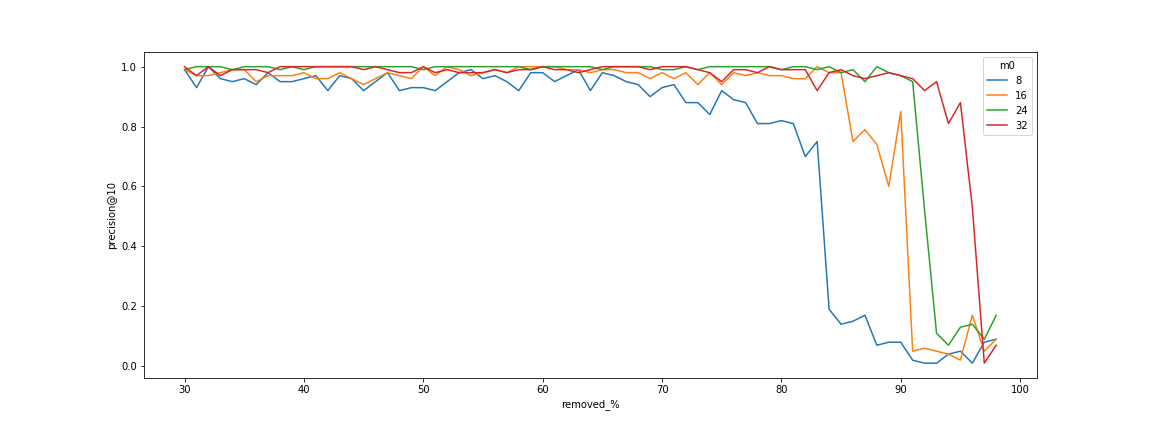
Qdrant solves this problem by extending the HNSW graph with additional edges based on indexed payload values. Extra edges allow you to efficiently search for nearby vectors using the HNSW index and apply filters as you search in the graph. You can find more information on this approach in our article.
The ACORN Search Algorithm
Available as of v1.16.0
In some cases, the additional edges built for Qdrant’s filterable HNSW may not be sufficient. These extra edges are added for each payload index separately, but not for every possible combination of payload indices. As a result, a combination of two or more strict filters might still lead to disconnected graph components. The same can happen when there are a large number of soft-deleted points in the graph. In such cases, use the ACORN Search Algorithm. When using ACORN, during graph traversal, it explores not just direct neighbors (first hop), but also neighbors of neighbors (second hop) when direct neighbors are filtered out. This improves search accuracy at the cost of performance.
Disable the Creation of Extra Edges for Payload Fields
Available as of v1.17.0
Not all payload indices may be intended for use with dense vector search. For example, when a collection contains both dense and sparse vectors, some payload fields may only be used to filter sparse vector searches. Since sparse vector search does not use the HNSW index, it is unnecessary to build extra edges in the HNSW graph for these fields. Creating extra edges adds indexing latency and increases the size of the HNSW graph, which consumes memory as well as disk space, so you may want to disable it for fields that do not require it.
You can disable the creation of extra edges for an indexed payload field by setting enable_hnsw to false when configuring a payload index:
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": {
"type": "keyword",
"enable_hnsw": false
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type=models.TextIndexType.TEXT,
tokenizer=models.TokenizerType.WORD,
enable_hnsw=False,
),
)
client.createPayloadIndex("{collection_name}", {
field_name: "name_of_the_field_to_index",
field_schema: {
type: "keyword",
enable_hnsw: false,
},
});
use qdrant_client::qdrant::{
CreateFieldIndexCollectionBuilder, FieldType, KeywordIndexParamsBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.create_field_index(
CreateFieldIndexCollectionBuilder::new(
"{collection_name}",
"name_of_the_field_to_index",
FieldType::Keyword,
)
.field_index_params(KeywordIndexParamsBuilder::default().enable_hnsw(false)),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.KeywordIndexParams;
import io.qdrant.client.grpc.Collections.PayloadIndexParams;
import io.qdrant.client.grpc.Collections.PayloadSchemaType;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createPayloadIndexAsync(
"{collection_name}",
"name_of_the_field_to_index",
PayloadSchemaType.Keyword,
PayloadIndexParams.newBuilder()
.setKeywordIndexParams(
KeywordIndexParams.newBuilder()
.setEnableHnsw(false)
.build())
.build(),
null,
null,
null)
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreatePayloadIndexAsync(
collectionName: "{collection_name}",
fieldName: "name_of_the_field_to_index",
schemaType: PayloadSchemaType.Keyword,
indexParams: new PayloadIndexParams
{
KeywordIndexParams = new KeywordIndexParams
{
EnableHnsw = false
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateFieldIndex(context.Background(), &qdrant.CreateFieldIndexCollection{
CollectionName: "{collection_name}",
FieldName: "name_of_the_field_to_index",
FieldType: qdrant.FieldType_FieldTypeKeyword.Enum(),
FieldIndexParams: qdrant.NewPayloadIndexParamsKeyword(
&qdrant.KeywordIndexParams{
EnableHnsw: qdrant.PtrOf(false),
}),
})
Rebuild the HNSW Index
There may be cases when you need to rebuild the HNSW index, for example, when you create a new payload index and want to take advantage of filter-aware edges in the HNSW graph. To rebuild an HNSW index, make a small change to its HNSW configuration, for example by bumping ef_construct by 1. This forces the optimizer to re-index all segments.
First, retrieve the current value of ef_construct:
BASE_EF=$(curl -s http://localhost:6333/collections/{collection_name} | \
jq '.result.config.hnsw_config.ef_construct')
base_ef = client.get_collection(
collection_name="{collection_name}"
).config.hnsw_config.ef_construct
const collectionInfo = await client.getCollection("{collection_name}");
const baseEf = collectionInfo.config.hnsw_config.ef_construct;
let base_ef = client
.collection_info("{collection_name}")
.await?
.result
.and_then(|info| info.config)
.and_then(|config| config.hnsw_config)
.and_then(|hnsw| hnsw.ef_construct);
CollectionInfo collectionInfo = client.getCollectionInfoAsync("{collection_name}").get();
long baseEf = collectionInfo.getConfig().getHnswConfig().getEfConstruct();
var collectionInfo = await client.GetCollectionInfoAsync("{collection_name}");
var baseEf = collectionInfo.Config.HnswConfig.EfConstruct;
collectionInfo, err := client.GetCollectionInfo(context.Background(), "{collection_name}")
if err != nil { panic(err) }
baseEf := *collectionInfo.Config.HnswConfig.EfConstruct
Next, update the collection with the value of ef_construct incremented by 1:
curl -X PATCH http://localhost:6333/collections/{collection_name} \
-H 'Content-Type: application/json' \
--data-raw "{
\"hnsw_config\": {
\"ef_construct\": $((BASE_EF + 1))
}
}"
client.update_collection(
collection_name="{collection_name}",
hnsw_config=models.HnswConfigDiff(ef_construct=base_ef + 1),
)
await client.updateCollection("{collection_name}", {
hnsw_config: {
ef_construct: baseEf + 1,
},
});
client
.update_collection(
UpdateCollectionBuilder::new("{collection_name}")
.hnsw_config(HnswConfigDiffBuilder::default().ef_construct(base_ef.unwrap_or(100) + 1)),
)
.await?;
client
.updateCollectionAsync(
UpdateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setHnswConfig(
HnswConfigDiff.newBuilder()
.setEfConstruct(baseEf + 1)
.build())
.build())
.get();
await client.UpdateCollectionAsync(
collectionName: "{collection_name}",
hnswConfig: new HnswConfigDiff { EfConstruct = baseEf + 1 }
);
client.UpdateCollection(context.Background(), &qdrant.UpdateCollection{
CollectionName: "{collection_name}",
HnswConfig: &qdrant.HnswConfigDiff{
EfConstruct: qdrant.PtrOf(baseEf + 1),
},
})
Don’t immediately revert the value of ef_construct to its original value. Keep it set to the new value.
Sparse Vector Index
Available as of v1.7.0
Sparse vectors in Qdrant are indexed with a special data structure, which is optimized for vectors that have a high proportion of zeroes. In some ways, this indexing method is similar to the inverted index, which is used in text search engines.
- A sparse vector index in Qdrant is exact, meaning it does not use any approximation algorithms.
- All sparse vectors added to the collection are immediately indexed in the mutable version of a sparse index.
With Qdrant, you can benefit from a more compact and efficient immutable sparse index, which is constructed during the same optimization process as the dense vector index.
This approach is particularly useful for collections storing both dense and sparse vectors.
To configure a sparse vector index, create a collection with the following parameters:
PUT /collections/{collection_name}
{
"sparse_vectors": {
"text": {
"index": {
"on_disk": false
}
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config={},
sparse_vectors_config={
"text": models.SparseVectorParams(
index=models.SparseIndexParams(on_disk=False),
)
},
)
import { QdrantClient, Schemas } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
sparse_vectors: {
"splade-model-name": {
index: {
on_disk: false
}
}
}
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, SparseIndexConfigBuilder, SparseVectorParamsBuilder,
SparseVectorsConfigBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
let mut sparse_vectors_config = SparseVectorsConfigBuilder::default();
sparse_vectors_config.add_named_vector_params(
"splade-model-name",
SparseVectorParamsBuilder::default()
.index(SparseIndexConfigBuilder::default().on_disk(true)),
);
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.sparse_vectors_config(sparse_vectors_config),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections;
QdrantClient client = new QdrantClient(
QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.createCollectionAsync(
Collections.CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setSparseVectorsConfig(
Collections.SparseVectorConfig.newBuilder().putMap(
"splade-model-name",
Collections.SparseVectorParams.newBuilder()
.setIndex(
Collections.SparseIndexConfig
.newBuilder()
.setOnDisk(false)
.build()
).build()
).build()
).build()
).get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
sparseVectorsConfig: ("splade-model-name", new SparseVectorParams{
Index = new SparseIndexConfig {
OnDisk = false,
}
})
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
SparseVectorsConfig: qdrant.NewSparseVectorsConfig(
map[string]*qdrant.SparseVectorParams{
"splade-model-name": {
Index: &qdrant.SparseIndexConfig{
OnDisk: qdrant.PtrOf(false),
}},
}),
})
The following parameters may affect performance:
on_disk: true- The index is stored on disk, which lets you save memory. This may slow down search performance.on_disk: false- The index is still persisted on disk, but it is also loaded into memory for faster search.
Unlike a dense vector index, a sparse vector index does not require a predefined vector size. It automatically adjusts to the size of the vectors added to the collection.
Note: A sparse vector index only supports dot-product similarity searches. It does not support other distance metrics.
IDF Modifier
Available as of v1.10.0
For many search algorithms, it is important to consider how often an item occurs in a collection. Intuitively speaking, the less frequently an item appears in a collection, the more important it is in a search.
This is also known as the Inverse Document Frequency (IDF). It is used in text search engines to rank search results based on the rarity of a word in a collection.
IDF depends on the currently stored documents and therefore can’t be pre-computed in the sparse vectors in streaming inference mode. In order to support IDF in the sparse vector index, Qdrant provides an option to modify the sparse vector query with the IDF statistics automatically.
The only requirement is to enable the IDF modifier in the collection configuration:
PUT /collections/{collection_name}
{
"sparse_vectors": {
"text": {
"modifier": "idf"
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config={},
sparse_vectors_config={
"text": models.SparseVectorParams(
modifier=models.Modifier.IDF,
),
},
)
import { QdrantClient, Schemas } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
sparse_vectors: {
"text": {
modifier: "idf"
}
}
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, Modifier, SparseVectorParamsBuilder, SparseVectorsConfigBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
let mut sparse_vectors_config = SparseVectorsConfigBuilder::default();
sparse_vectors_config.add_named_vector_params(
"text",
SparseVectorParamsBuilder::default().modifier(Modifier::Idf),
);
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.sparse_vectors_config(sparse_vectors_config),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Modifier;
import io.qdrant.client.grpc.Collections.SparseVectorConfig;
import io.qdrant.client.grpc.Collections.SparseVectorParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setSparseVectorsConfig(
SparseVectorConfig.newBuilder()
.putMap("text", SparseVectorParams.newBuilder().setModifier(Modifier.Idf).build()))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
sparseVectorsConfig: ("text", new SparseVectorParams {
Modifier = Modifier.Idf,
})
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
SparseVectorsConfig: qdrant.NewSparseVectorsConfig(
map[string]*qdrant.SparseVectorParams{
"text": {
Modifier: qdrant.Modifier_Idf.Enum(),
},
}),
})
Qdrant uses the following formula to calculate the IDF modifier:
$$ \text{IDF}(q_i) = \ln \left(\frac{N - n(q_i) + 0.5}{n(q_i) + 0.5}+1\right) $$
Where:
Nis the total number of documents in the collection.nis the number of documents containing non-zero values for the given vector element.