Implement custom connector for Cohere RAG
| Time: 45 min | Level: Intermediate |
|---|
The usual approach to implementing Retrieval Augmented Generation requires users to build their prompts with the relevant context the LLM may rely on, and manually sending them to the model. Cohere is quite unique here, as their models can now speak to the external tools and extract meaningful data on their own. You can virtually connect any data source and let the Cohere LLM know how to access it. Obviously, vector search goes well with LLMs, and enabling semantic search over your data is a typical case.
Cohere RAG has lots of interesting features, such as inline citations, which help you to refer to the specific parts of the documents used to generate the response.
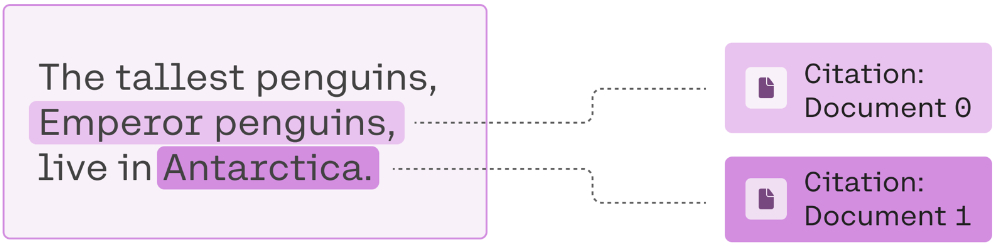
Source: https://docs.cohere.com/docs/retrieval-augmented-generation-rag
The connectors have to implement a specific interface and expose the data source as HTTP REST API. Cohere documentation describes a general process of creating a connector. This tutorial guides you step by step on building such a service around Qdrant.
Qdrant connector
You probably already have some collections you would like to bring to the LLM. Maybe your pipeline was set up using some of the popular libraries such as LangChain, LlamaIndex, or Haystack. Cohere connectors may implement even more complex logic, e.g. hybrid search. In our case, we are going to start with a fresh Qdrant collection, index data using Cohere Embed v3, build the connector, and finally connect it with the Command-R model.
Building the collection
First things first, let’s build a collection and configure it for the Cohere embed-multilingual-v3.0 model. It
produces 1024-dimensional embeddings, and we can choose any of the distance metrics available in Qdrant. Our connector
will act as a personal assistant of a software engineer, and it will expose our notes to suggest the priorities or
actions to perform.
from qdrant_client import QdrantClient, models
client = QdrantClient(
"https://my-cluster.cloud.qdrant.io:6333",
api_key="my-api-key",
)
client.create_collection(
collection_name="personal-notes",
vectors_config=models.VectorParams(
size=1024,
distance=models.Distance.DOT,
),
)
Our notes will be represented as simple JSON objects with a title and text of the specific note. The embeddings will
be created from the text field only.
notes = [
{
"title": "Project Alpha Review",
"text": "Review the current progress of Project Alpha, focusing on the integration of the new API. Check for any compatibility issues with the existing system and document the steps needed to resolve them. Schedule a meeting with the development team to discuss the timeline and any potential roadblocks."
},
{
"title": "Learning Path Update",
"text": "Update the learning path document with the latest courses on React and Node.js from Pluralsight. Schedule at least 2 hours weekly to dedicate to these courses. Aim to complete the React course by the end of the month and the Node.js course by mid-next month."
},
{
"title": "Weekly Team Meeting Agenda",
"text": "Prepare the agenda for the weekly team meeting. Include the following topics: project updates, review of the sprint backlog, discussion on the new feature requests, and a brainstorming session for improving remote work practices. Send out the agenda and the Zoom link by Thursday afternoon."
},
{
"title": "Code Review Process Improvement",
"text": "Analyze the current code review process to identify inefficiencies. Consider adopting a new tool that integrates with our version control system. Explore options such as GitHub Actions for automating parts of the process. Draft a proposal with recommendations and share it with the team for feedback."
},
{
"title": "Cloud Migration Strategy",
"text": "Draft a plan for migrating our current on-premise infrastructure to the cloud. The plan should cover the selection of a cloud provider, cost analysis, and a phased migration approach. Identify critical applications for the first phase and any potential risks or challenges. Schedule a meeting with the IT department to discuss the plan."
},
{
"title": "Quarterly Goals Review",
"text": "Review the progress towards the quarterly goals. Update the documentation to reflect any completed objectives and outline steps for any remaining goals. Schedule individual meetings with team members to discuss their contributions and any support they might need to achieve their targets."
},
{
"title": "Personal Development Plan",
"text": "Reflect on the past quarter's achievements and areas for improvement. Update the personal development plan to include new technical skills to learn, certifications to pursue, and networking events to attend. Set realistic timelines and check-in points to monitor progress."
},
{
"title": "End-of-Year Performance Reviews",
"text": "Start preparing for the end-of-year performance reviews. Collect feedback from peers and managers, review project contributions, and document achievements. Consider areas for improvement and set goals for the next year. Schedule preliminary discussions with each team member to gather their self-assessments."
},
{
"title": "Technology Stack Evaluation",
"text": "Conduct an evaluation of our current technology stack to identify any outdated technologies or tools that could be replaced for better performance and productivity. Research emerging technologies that might benefit our projects. Prepare a report with findings and recommendations to present to the management team."
},
{
"title": "Team Building Event Planning",
"text": "Plan a team-building event for the next quarter. Consider activities that can be done remotely, such as virtual escape rooms or online game nights. Survey the team for their preferences and availability. Draft a budget proposal for the event and submit it for approval."
}
]
Storing the embeddings along with the metadata is fairly simple.
import cohere
import uuid
cohere_client = cohere.Client(api_key="my-cohere-api-key")
response = cohere_client.embed(
texts=[
note.get("text")
for note in notes
],
model="embed-multilingual-v3.0",
input_type="search_document",
)
client.upload_points(
collection_name="personal-notes",
points=[
models.PointStruct(
id=uuid.uuid4().hex,
vector=embedding,
payload=note,
)
for note, embedding in zip(notes, response.embeddings)
]
)
Our collection is now ready to be searched over. In the real world, the set of notes would be changing over time, so the ingestion process won’t be as straightforward. This data is not yet exposed to the LLM, but we will build the connector in the next step.
Connector web service
FastAPI is a modern web framework and perfect a choice for a simple HTTP API. We are
going to use it for the purposes of our connector. There will be just one endpoint, as required by the model. It will
accept POST requests at the /search path. There is a single query parameter required. Let’s define a corresponding
model.
from pydantic import BaseModel
class SearchQuery(BaseModel):
query: str
RAG connector does not have to return the documents in any specific format. There are some good practices to follow,
but Cohere models are quite flexible here. Results just have to be returned as JSON, with a list of objects in a
results property of the output. We will use the same document structure as we did for the Qdrant payloads, so there
is no conversion required. That requires two additional models to be created.
from typing import List
class Document(BaseModel):
title: str
text: str
class SearchResults(BaseModel):
results: List[Document]
Once our model classes are ready, we can implement the logic that will get the query and provide the notes that are relevant to it. Please note the LLM is not going to define the number of documents to be returned. That’s completely up to you how many of them you want to bring to the context.
There are two services we need to interact with - Qdrant server and Cohere API. FastAPI has a concept of a dependency injection, and we will use it to provide both clients into the implementation.
In case of queries, we need to set the input_type to search_query in the calls to Cohere API.
from fastapi import FastAPI, Depends
from typing import Annotated
app = FastAPI()
def client() -> QdrantClient:
return QdrantClient(config.QDRANT_URL, api_key=config.QDRANT_API_KEY)
def cohere_client() -> cohere.Client:
return cohere.Client(api_key=config.COHERE_API_KEY)
@app.post("/search")
def search(
query: SearchQuery,
client: Annotated[QdrantClient, Depends(client)],
cohere_client: Annotated[cohere.Client, Depends(cohere_client)],
) -> SearchResults:
response = cohere_client.embed(
texts=[query.query],
model="embed-multilingual-v3.0",
input_type="search_query",
)
results = client.query_points(
collection_name="personal-notes",
query=response.embeddings[0],
limit=2,
).points
return SearchResults(
results=[
Document(**point.payload)
for point in results
]
)
Our app might be launched locally for the development purposes, given we have the uvicorn server installed:
uvicorn main:app
FastAPI exposes an interactive documentation at http://localhost:8000/docs, where we can test our endpoint. The
/search endpoint is available there.
We can interact with it and check the documents that will be returned for a specific query. For example, we want to know recall what we are supposed to do regarding the infrastructure for your projects.
curl -X "POST" \
-H "Content-type: application/json" \
-d '{"query": "Is there anything I have to do regarding the project infrastructure?"}' \
"http://localhost:8000/search"
The output should look like following:
{
"results": [
{
"title": "Cloud Migration Strategy",
"text": "Draft a plan for migrating our current on-premise infrastructure to the cloud. The plan should cover the selection of a cloud provider, cost analysis, and a phased migration approach. Identify critical applications for the first phase and any potential risks or challenges. Schedule a meeting with the IT department to discuss the plan."
},
{
"title": "Project Alpha Review",
"text": "Review the current progress of Project Alpha, focusing on the integration of the new API. Check for any compatibility issues with the existing system and document the steps needed to resolve them. Schedule a meeting with the development team to discuss the timeline and any potential roadblocks."
}
]
}
Connecting to Command-R
Our web service is implemented, yet running only on our local machine. It has to be exposed to the public before Command-R can interact with it. For a quick experiment, it might be enough to set up tunneling using services such as ngrok. We won’t cover all the details in the tutorial, but their Quickstart is a great resource describing the process step-by-step. Alternatively, you can also deploy the service with a public URL.
Once it’s done, we can create the connector first, and then tell the model to use it, while interacting through the chat API. Creating a connector is a single call to Cohere client:
connector_response = cohere_client.connectors.create(
name="personal-notes",
url="https:/this-is-my-domain.app/search",
)
The connector_response.connector will be a descriptor, with id being one of the attributes. We’ll use this
identifier for our interactions like this:
response = cohere_client.chat(
message=(
"Is there anything I have to do regarding the project infrastructure? "
"Please mention the tasks briefly."
),
connectors=[
cohere.ChatConnector(id=connector_response.connector.id)
],
model="command-r",
)
We changed the model to command-r, as this is currently the best Cohere model available to public. The
response.text is the output of the model:
Here are some of the tasks related to project infrastructure that you might have to perform:
- You need to draft a plan for migrating your on-premise infrastructure to the cloud and come up with a plan for the selection of a cloud provider, cost analysis, and a gradual migration approach.
- It's important to evaluate your current technology stack to identify any outdated technologies. You should also research emerging technologies and the benefits they could bring to your projects.
You only need to create a specific connector once! Please do not call cohere_client.connectors.create for every single
message you send to the chat method.
Wrapping up
We have built a Cohere RAG connector that integrates with your existing knowledge base stored in Qdrant. We covered just the basic flow, but in real world scenarios, you should also consider e.g. building the authentication system to prevent unauthorized access.