Qdrant Semantic Querying with Airflow and Astronomer
| Time: 45 min | Level: Intermediate |
|---|
In this tutorial, you will use Qdrant as a provider in Apache Airflow, an open-source tool that lets you setup data-engineering workflows.
You will write the pipeline as a DAG (Directed Acyclic Graph) in Python. With this, you can leverage the powerful suite of Python’s capabilities and libraries to achieve almost anything your data pipeline needs.
Astronomer is a managed platform that simplifies the process of developing and deploying Airflow projects via its easy-to-use CLI and extensive automation capabilities.
Airflow is useful when running operations in Qdrant based on data events or building parallel tasks for generating vector embeddings. By using Airflow, you can set up monitoring and alerts for your pipelines for full observability.
Prerequisites
Please make sure you have the following ready:
- A running Qdrant instance. We’ll be using a free instance from https://cloud.qdrant.io
- The Astronomer CLI. Find the installation instructions here.
- A HuggingFace token to generate embeddings.
Implementation
We’ll be building a DAG that generates embeddings in parallel for our data corpus and performs semantic retrieval based on user input.
Set up the project
The Astronomer CLI makes it very straightforward to set up the Airflow project:
mkdir qdrant-airflow-tutorial && cd qdrant-airflow-tutorial
astro dev init
This command generates all of the project files you need to run Airflow locally. You can find a directory called dags, which is where we can place our Python DAG files.
To use Qdrant within Airflow, install the Qdrant Airflow provider by adding the following to the requirements.txt file
apache-airflow-providers-qdrant
Configure credentials
We can set up provider connections using the Airflow UI, environment variables or the airflow_settings.yml file.
Add the following to the .env file in the project. Replace the values as per your credentials.
HUGGINGFACE_TOKEN="<YOUR_HUGGINGFACE_ACCESS_TOKEN>"
AIRFLOW_CONN_QDRANT_DEFAULT='{
"conn_type": "qdrant",
"host": "xyz-example.eu-central.aws.cloud.qdrant.io:6333",
"password": "<YOUR_QDRANT_API_KEY>"
}'
Add the data corpus
Let’s add some sample data to work with. Paste the following content into a file called books.txt file within the include directory.
1 | To Kill a Mockingbird (1960) | fiction | Harper Lee's Pulitzer Prize-winning novel explores racial injustice and moral growth through the eyes of young Scout Finch in the Deep South.
2 | Harry Potter and the Sorcerer's Stone (1997) | fantasy | J.K. Rowling's magical tale follows Harry Potter as he discovers his wizarding heritage and attends Hogwarts School of Witchcraft and Wizardry.
3 | The Great Gatsby (1925) | fiction | F. Scott Fitzgerald's classic novel delves into the glitz, glamour, and moral decay of the Jazz Age through the eyes of narrator Nick Carraway and his enigmatic neighbour, Jay Gatsby.
4 | 1984 (1949) | dystopian | George Orwell's dystopian masterpiece paints a chilling picture of a totalitarian society where individuality is suppressed and the truth is manipulated by a powerful regime.
5 | The Catcher in the Rye (1951) | fiction | J.D. Salinger's iconic novel follows disillusioned teenager Holden Caulfield as he navigates the complexities of adulthood and society's expectations in post-World War II America.
6 | Pride and Prejudice (1813) | romance | Jane Austen's beloved novel revolves around the lively and independent Elizabeth Bennet as she navigates love, class, and societal expectations in Regency-era England.
7 | The Hobbit (1937) | fantasy | J.R.R. Tolkien's adventure follows Bilbo Baggins, a hobbit who embarks on a quest with a group of dwarves to reclaim their homeland from the dragon Smaug.
8 | The Lord of the Rings (1954-1955) | fantasy | J.R.R. Tolkien's epic fantasy trilogy follows the journey of Frodo Baggins to destroy the One Ring and defeat the Dark Lord Sauron in the land of Middle-earth.
9 | The Alchemist (1988) | fiction | Paulo Coelho's philosophical novel follows Santiago, an Andalusian shepherd boy, on a journey of self-discovery and spiritual awakening as he searches for a hidden treasure.
10 | The Da Vinci Code (2003) | mystery/thriller | Dan Brown's gripping thriller follows symbologist Robert Langdon as he unravels clues hidden in art and history while trying to solve a murder mystery with far-reaching implications.
Now, the hacking part - writing our Airflow DAG!
Write the dag
We’ll add the following content to a books_recommend.py file within the dags directory. Let’s go over what it does for each task.
import os
import requests
from airflow.decorators import dag, task
from airflow.models.baseoperator import chain
from airflow.models.param import Param
from airflow.providers.qdrant.hooks.qdrant import QdrantHook
from airflow.providers.qdrant.operators.qdrant import QdrantIngestOperator
from pendulum import datetime
from qdrant_client import models
QDRANT_CONNECTION_ID = "qdrant_default"
DATA_FILE_PATH = "include/books.txt"
COLLECTION_NAME = "airflow_tutorial_collection"
EMBEDDING_MODEL_ID = "sentence-transformers/all-MiniLM-L6-v2"
EMBEDDING_DIMENSION = 384
SIMILARITY_METRIC = models.Distance.COSINE
def embed(text: str) -> list:
HUGGINFACE_URL = f"https://api-inference.huggingface.co/pipeline/feature-extraction/{EMBEDDING_MODEL_ID}"
response = requests.post(
HUGGINFACE_URL,
headers={"Authorization": f"Bearer {os.getenv('HUGGINGFACE_TOKEN')}"},
json={"inputs": [text], "options": {"wait_for_model": True}},
)
return response.json()[0]
@dag(
dag_id="books_recommend",
start_date=datetime(2023, 10, 18),
schedule=None,
catchup=False,
params={"preference": Param("Something suspenseful and thrilling.", type="string")},
)
def recommend_book():
@task
def import_books(text_file_path: str) -> list:
data = []
with open(text_file_path, "r") as f:
for line in f:
_, title, genre, description = line.split("|")
data.append(
{
"title": title.strip(),
"genre": genre.strip(),
"description": description.strip(),
}
)
return data
@task
def init_collection():
hook = QdrantHook(conn_id=QDRANT_CONNECTION_ID)
if not hook.conn..collection_exists(COLLECTION_NAME):
hook.conn.create_collection(
COLLECTION_NAME,
vectors_config=models.VectorParams(
size=EMBEDDING_DIMENSION, distance=SIMILARITY_METRIC
),
)
@task
def embed_description(data: dict) -> list:
return embed(data["description"])
books = import_books(text_file_path=DATA_FILE_PATH)
embeddings = embed_description.expand(data=books)
qdrant_vector_ingest = QdrantIngestOperator(
conn_id=QDRANT_CONNECTION_ID,
task_id="qdrant_vector_ingest",
collection_name=COLLECTION_NAME,
payload=books,
vectors=embeddings,
)
@task
def embed_preference(**context) -> list:
user_mood = context["params"]["preference"]
response = embed(text=user_mood)
return response
@task
def search_qdrant(
preference_embedding: list,
) -> None:
hook = QdrantHook(conn_id=QDRANT_CONNECTION_ID)
result = hook.conn.query_points(
collection_name=COLLECTION_NAME,
query=preference_embedding,
limit=1,
with_payload=True,
).points
print("Book recommendation: " + result[0].payload["title"])
print("Description: " + result[0].payload["description"])
chain(
init_collection(),
qdrant_vector_ingest,
search_qdrant(embed_preference()),
)
recommend_book()
import_books: This task reads a text file containing information about the books (like title, genre, and description), and then returns the data as a list of dictionaries.
init_collection: This task initializes a collection in the Qdrant database, where we will store the vector representations of the book descriptions.
embed_description: This is a dynamic task that creates one mapped task instance for each book in the list. The task uses the embed function to generate vector embeddings for each description. To use a different embedding model, you can adjust the EMBEDDING_MODEL_ID, EMBEDDING_DIMENSION values.
embed_user_preference: Here, we take a user’s input and convert it into a vector using the same pre-trained model used for the book descriptions.
qdrant_vector_ingest: This task ingests the book data into the Qdrant collection using the QdrantIngestOperator, associating each book description with its corresponding vector embeddings.
search_qdrant: Finally, this task performs a search in the Qdrant database using the vectorized user preference. It finds the most relevant book in the collection based on vector similarity.
Run the DAG
Head over to your terminal and run
astro dev start
A local Airflow container should spawn. You can now access the Airflow UI at http://localhost:8080. Visit our DAG by clicking on books_recommend.
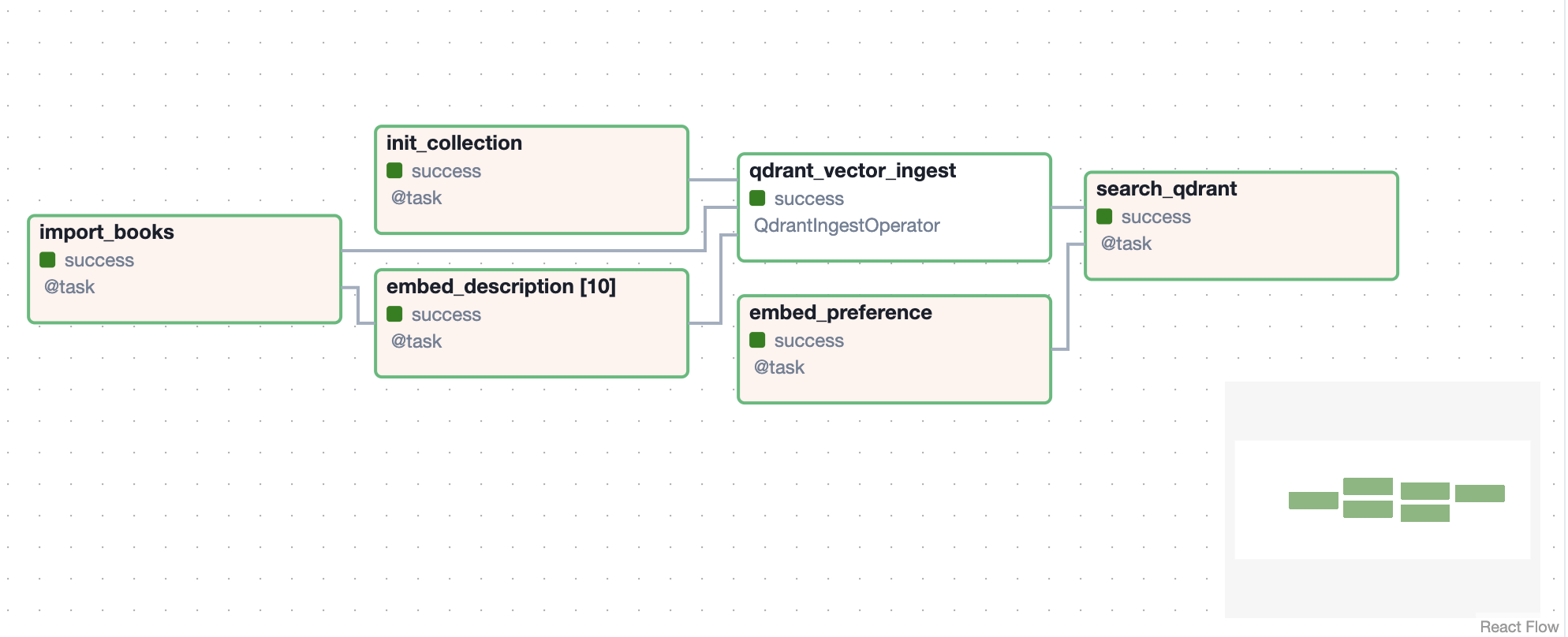
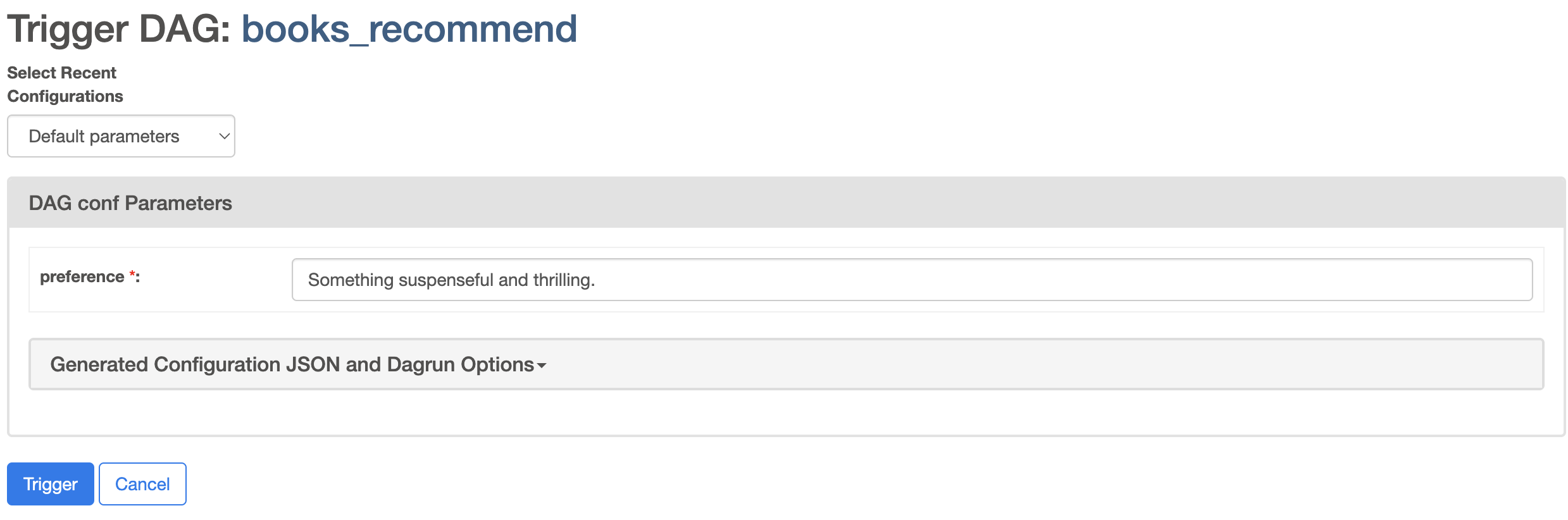
Hit the PLAY button on the right to run the DAG. You’ll be asked for input about your preference, with the default value already filled in.
After your DAG run completes, you should be able to see the output of your search in the logs of the search_qdrant task.

There you have it, an Airflow pipeline that interfaces with Qdrant! Feel free to fiddle around and explore Airflow. There are references below that might come in handy.