Extending ChatGPT with a Qdrant-based knowledge base
Kacper Łukawski
·March 23, 2023

In recent months, ChatGPT has revolutionised the way we communicate, learn, and interact with technology. Our social platforms got flooded with prompts, responses to them, whole articles and countless other examples of using Large Language Models to generate content unrecognisable from the one written by a human.
Despite their numerous benefits, these models have flaws, as evidenced by the phenomenon of hallucination - the generation of incorrect or nonsensical information in response to user input. This issue, which can compromise the reliability and credibility of AI-generated content, has become a growing concern among researchers and users alike. Those concerns started another wave of entirely new libraries, such as Langchain, trying to overcome those issues, for example, by combining tools like vector databases to bring the required context into the prompts. And that is, so far, the best way to incorporate new and rapidly changing knowledge into the neural model. So good that OpenAI decided to introduce a way to extend the model capabilities with external plugins at the model level. These plugins, designed to enhance the model’s performance, serve as modular extensions that seamlessly interface with the core system. By adding a knowledge base plugin to ChatGPT, we can effectively provide the AI with a curated, trustworthy source of information, ensuring that the generated content is more accurate and relevant. Qdrant may act as a vector database where all the facts will be stored and served to the model upon request.
If you’d like to ask ChatGPT questions about your data sources, such as files, notes, or emails, starting with the official ChatGPT retrieval plugin repository is the easiest way. Qdrant is already integrated, so that you can use it right away. In the following sections, we will guide you through setting up the knowledge base using Qdrant and demonstrate how this powerful combination can significantly improve ChatGPT’s performance and output quality.
Implementing a knowledge base with Qdrant
The official ChatGPT retrieval plugin uses a vector database to build your knowledge base. Your documents are chunked and vectorized with the OpenAI’s text-embedding-ada-002 model to be stored in Qdrant. That enables semantic search capabilities. So, whenever ChatGPT thinks it might be relevant to check the knowledge base, it forms a query and sends it to the plugin to incorporate the results into its response. You can now modify the knowledge base, and ChatGPT will always know the most recent facts. No model fine-tuning is required. Let’s implement that for your documents. In our case, this will be Qdrant’s documentation, so you can ask even technical questions about Qdrant directly in ChatGPT.
Everything starts with cloning the plugin’s repository.
git clone git@github.com:openai/chatgpt-retrieval-plugin.git
Please use your favourite IDE to open the project once cloned.
Prerequisites
You’ll need to ensure three things before we start:
- Create an OpenAI API key, so you can use their embeddings model programmatically. If you already have an account, you can generate one at https://platform.openai.com/account/api-keys. Otherwise, registering an account might be required.
- Run a Qdrant instance. The instance has to be reachable from the outside, so you either need to launch it on-premise or use the Qdrant Cloud offering. A free 1GB cluster is available, which might be enough in many cases. We’ll use the cloud.
- Since ChatGPT will interact with your service through the network, you must deploy it, making it possible to connect from the Internet. Unfortunately, localhost is not an option, but any provider, such as Heroku or fly.io, will work perfectly. We will use fly.io, so please register an account. You may also need to install the flyctl tool for the deployment. The process is described on the homepage of fly.io.
Configuration
The retrieval plugin is a FastAPI-based application, and its default functionality might be enough in most cases. However, some configuration is required so ChatGPT knows how and when to use it. However, we can start setting up Fly.io, as we need to know the service’s hostname to configure it fully.
First, let’s login into the Fly CLI:
flyctl auth login
That will open the browser, so you can simply provide the credentials, and all the further commands will be executed with your account. If you have never used fly.io, you may need to give the credit card details before running any instance, but there is a Hobby Plan you won’t be charged for.
Let’s try to launch the instance already, but do not deploy it. We’ll get the hostname assigned and have all the details to fill in the configuration. The retrieval plugin uses TCP port 8080, so we need to configure fly.io, so it redirects all the traffic to it as well.
flyctl launch --no-deploy --internal-port 8080
We’ll be prompted about the application name and the region it should be deployed to. Please choose whatever works best for you. After that, we should see the hostname of the newly created application:
...
Hostname: your-application-name.fly.dev
...
Let’s note it down. We’ll need it for the configuration of the service. But we’re going to start with setting all the applications secrets:
flyctl secrets set DATASTORE=qdrant \
OPENAI_API_KEY=<your-openai-api-key> \
QDRANT_URL=https://<your-qdrant-instance>.aws.cloud.qdrant.io \
QDRANT_API_KEY=<your-qdrant-api-key> \
BEARER_TOKEN=eyJhbGciOiJIUzI1NiJ9.e30.ZRrHA1JJJW8opsbCGfG_HACGpVUMN_a9IV7pAx_Zmeo
The secrets will be staged for the first deployment. There is an example of a minimal Bearer token generated by https://jwt.io/. Please adjust the token and do not expose it publicly, but you can keep the same value for the demo.
Right now, let’s dive into the application config files. You can optionally provide your
icon and keep it as .well-known/logo.png file, but there are two additional files we’re
going to modify.
The .well-known/openapi.yaml file describes the exposed API in the OpenAPI format.
Lines 3 to 5 might be filled with the application title and description, but the essential
part is setting the server URL the application will run. Eventually, the top part of the
file should look like the following:
openapi: 3.0.0
info:
title: Qdrant Plugin API
version: 1.0.0
description: Plugin for searching through the Qdrant doc…
servers:
- url: https://your-application-name.fly.dev
...
There is another file in the same directory, and that’s the most crucial piece to
configure. It contains the description of the plugin we’re implementing, and ChatGPT
uses this description to determine if it should communicate with our knowledge base.
The file is called .well-known/ai-plugin.json, and let’s edit it before we finally
deploy the app. There are various properties we need to fill in:
| Property | Meaning | Example |
|---|---|---|
name_for_model | Name of the plugin for the ChatGPT model | qdrant |
name_for_human | Human-friendly model name, to be displayed in ChatGPT UI | Qdrant Documentation Plugin |
description_for_model | Description of the purpose of the plugin, so ChatGPT knows in what cases it should be using it to answer a question. | Plugin for searching through the Qdrant documentation to find answers to questions and retrieve relevant information. Use it whenever a user asks something that might be related to Qdrant vector database or semantic vector search |
description_for_human | Short description of the plugin, also to be displayed in the ChatGPT UI. | Search through Qdrant docs |
auth | Authorization scheme used by the application. By default, the bearer token has to be configured. | {"type": "user_http", "authorization_type": "bearer"} |
api.url | Link to the OpenAPI schema definition. Please adjust based on your application URL. | https://your-application-name.fly.dev/.well-known/openapi.yaml |
logo_url | Link to the application logo. Please adjust based on your application URL. | https://your-application-name.fly.dev/.well-known/logo.png |
A complete file may look as follows:
{
"schema_version": "v1",
"name_for_model": "qdrant",
"name_for_human": "Qdrant Documentation Plugin",
"description_for_model": "Plugin for searching through the Qdrant documentation to find answers to questions and retrieve relevant information. Use it whenever a user asks something that might be related to Qdrant vector database or semantic vector search",
"description_for_human": "Search through Qdrant docs",
"auth": {
"type": "user_http",
"authorization_type": "bearer"
},
"api": {
"type": "openapi",
"url": "https://your-application-name.fly.dev/.well-known/openapi.yaml",
"has_user_authentication": false
},
"logo_url": "https://your-application-name.fly.dev/.well-known/logo.png",
"contact_email": "email@domain.com",
"legal_info_url": "email@domain.com"
}
That was the last step before running the final command. The command that will deploy the application on the server:
flyctl deploy
The command will build the image using the Dockerfile and deploy the service at a given URL. Once the command is finished, the service should be running on the hostname we got previously:
https://your-application-name.fly.dev
Integration with ChatGPT
Once we have deployed the service, we can point ChatGPT to it, so the model knows how to connect. When you open the ChatGPT UI, you should see a dropdown with a Plugins tab included:
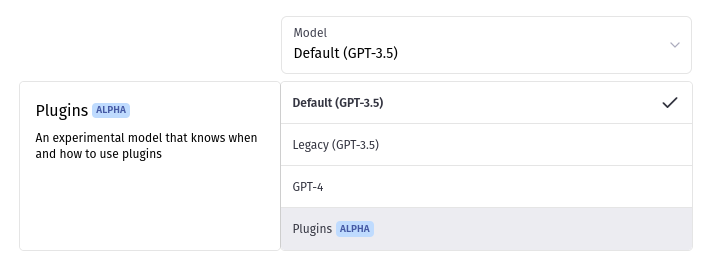
Once selected, you should be able to choose one of check the plugin store:

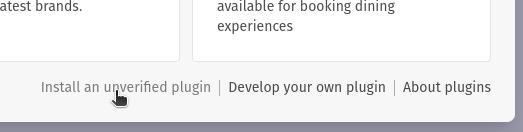
There are some premade plugins available, but there’s also a possibility to install your own plugin by clicking on the “Develop your own plugin” option in the bottom right corner:
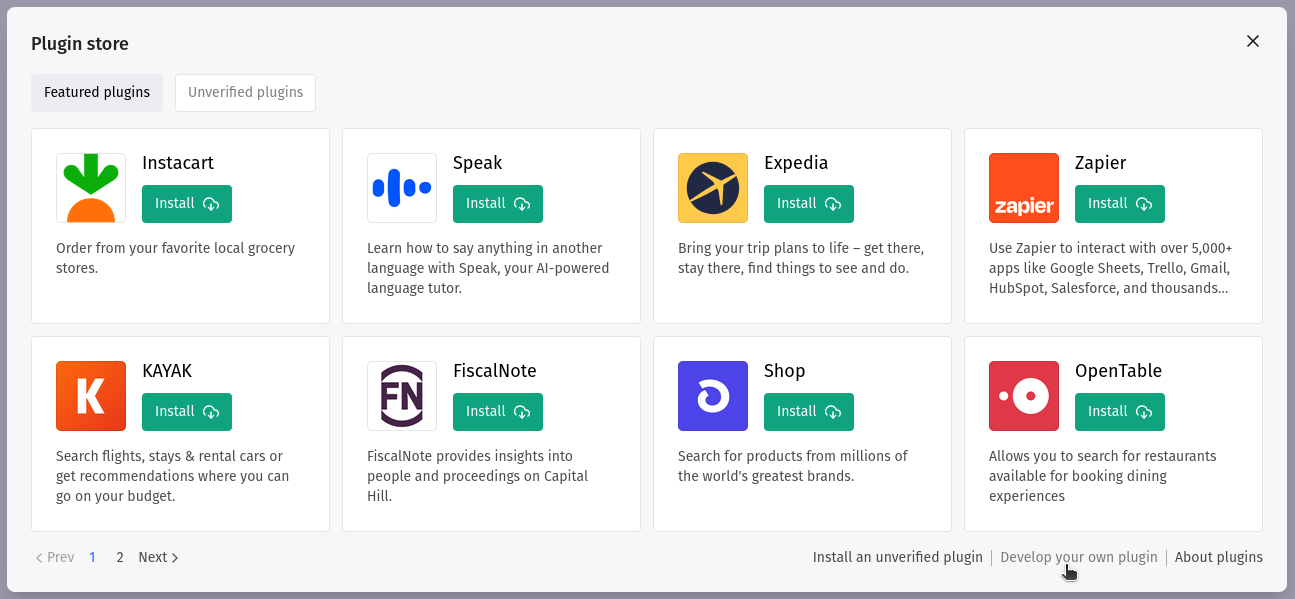
We need to confirm our plugin is ready, but since we relied on the official retrieval plugin from OpenAI, this should be all fine:
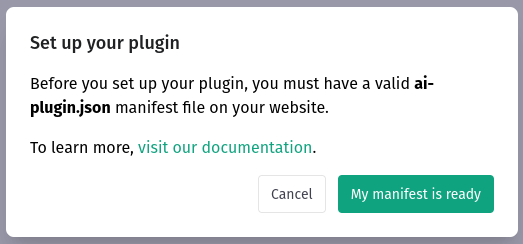
After clicking on “My manifest is ready”, we can already point ChatGPT to our newly created service:
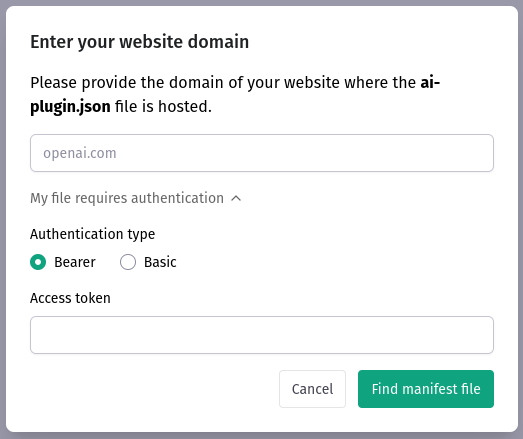
A successful plugin installation should end up with the following information:
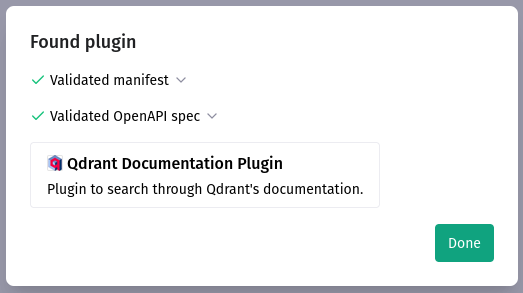
There is a name and a description of the plugin we provided. Let’s click on “Done” and return to the “Plugin store” window again. There is another option we need to choose in the bottom right corner:
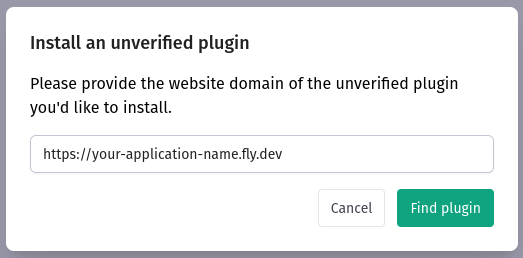
Our plugin is not officially verified, but we can, of course, use it freely. The installation requires just the service URL:
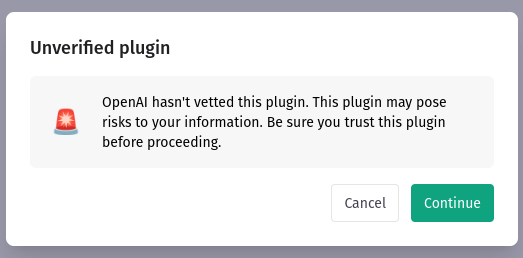
OpenAI cannot guarantee the plugin provides factual information, so there is a warning we need to accept:
Finally, we need to provide the Bearer token again:
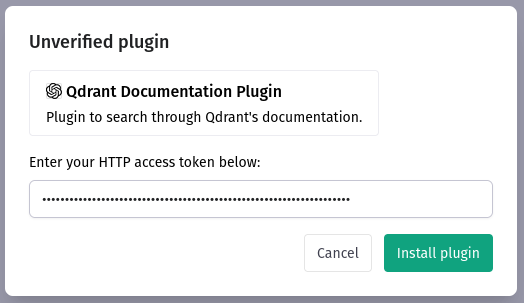
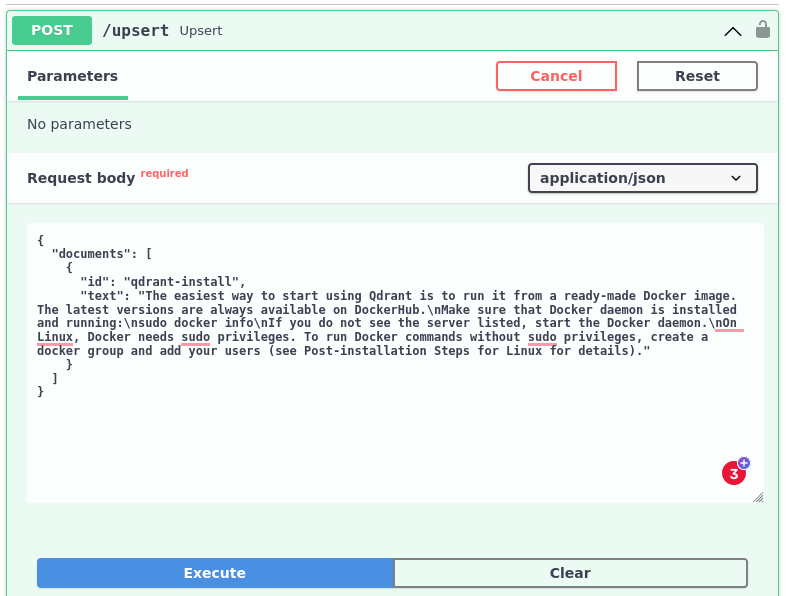
Our plugin is now ready to be tested. Since there is no data inside the knowledge base, extracting any facts is impossible, but we’re going to put some data using the Swagger UI exposed by our service at https://your-application-name.fly.dev/docs. We need to authorize first, and then call the upsert method with some docs. For the demo purposes, we can just put a single document extracted from the Qdrant documentation to see whether integration works properly:
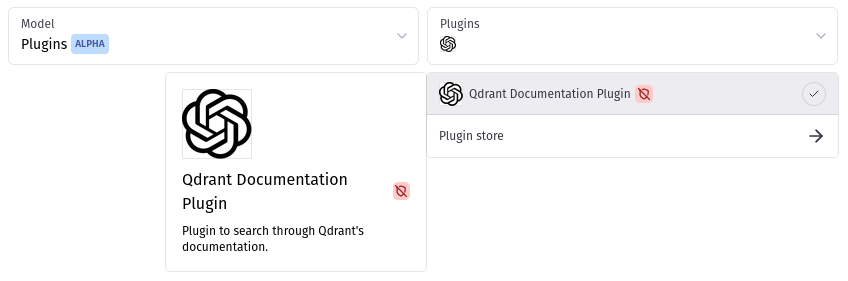
We can come back to ChatGPT UI, and send a prompt, but we need to make sure the plugin is selected:
Now if our prompt seems somehow related to the plugin description provided, the model will automatically form a query and send it to the HTTP API. The query will get vectorized by our app, and then used to find some relevant documents that will be used as a context to generate the response.
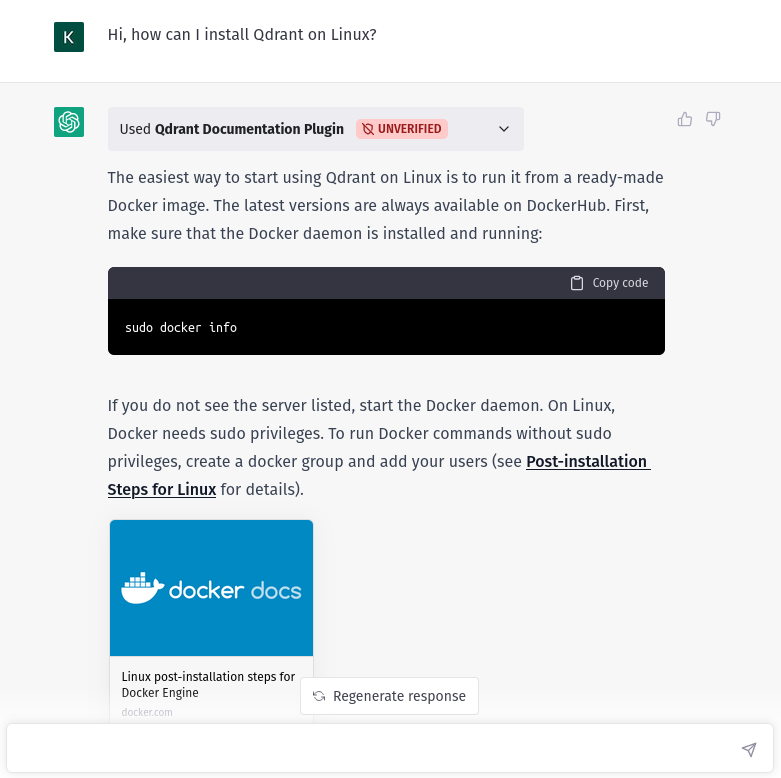
We have a powerful language model, that can interact with our knowledge base, to return not only grammatically correct but also factual information. And this is how your interactions with the model may start to look like:
However, a single document is not enough to enable the full power of the plugin. If you
want to put more documents that you have collected, there are already some scripts
available in the scripts/ directory that allows converting JSON, JSON lines or even
zip archives.