Qdrant Summer of Code 2024 - ONNX Cross Encoders in Python
Huong (Celine) Hoang
·October 14, 2024

Introduction
Hi everyone! I’m Huong (Celine) Hoang, and I’m thrilled to share my experience working at Qdrant this summer as part of their Summer of Code 2024 program. During my internship, I worked on integrating cross-encoders into the FastEmbed library for re-ranking tasks. This enhancement widened the capabilities of the Qdrant ecosystem, enabling developers to build more context-aware search applications, such as question-answering systems, using Qdrant’s suite of libraries.
This project was both technically challenging and rewarding, pushing me to grow my skills in handling large-scale ONNX (Open Neural Network Exchange) model integrations, tokenization, and more. Let me take you through the journey, the lessons learned, and where things are headed next.
Project Overview
Qdrant is well known for its vector search capabilities, but my task was to go one step further — introducing cross-encoders for re-ranking. Traditionally, the FastEmbed library would generate embeddings, but cross-encoders don’t do that. Instead, they provide a list of scores based on how well a query matches a list of documents. This kind of re-ranking is critical when you want to refine search results and bring the most relevant answers to the top.
The project revolved around creating a new input-output scheme: text data to scores. For this, I designed a family of classes to support ONNX models. Some of the key models I worked with included Xenova/ms-marco-MiniLM-L-6-v2, Xenova/ms-marco-MiniLM-L-12-v2, and BAAI/bge-reranker, all designed for re-ranking tasks.
An important point to mention is that FastEmbed is a minimalistic library: it doesn’t have heavy dependencies like PyTorch or TensorFlow, and as a result, it is lightweight, occupying far less storage space.
Below is a diagram that represents the overall workflow for this project, detailing the key steps from user interaction to the final output validation:
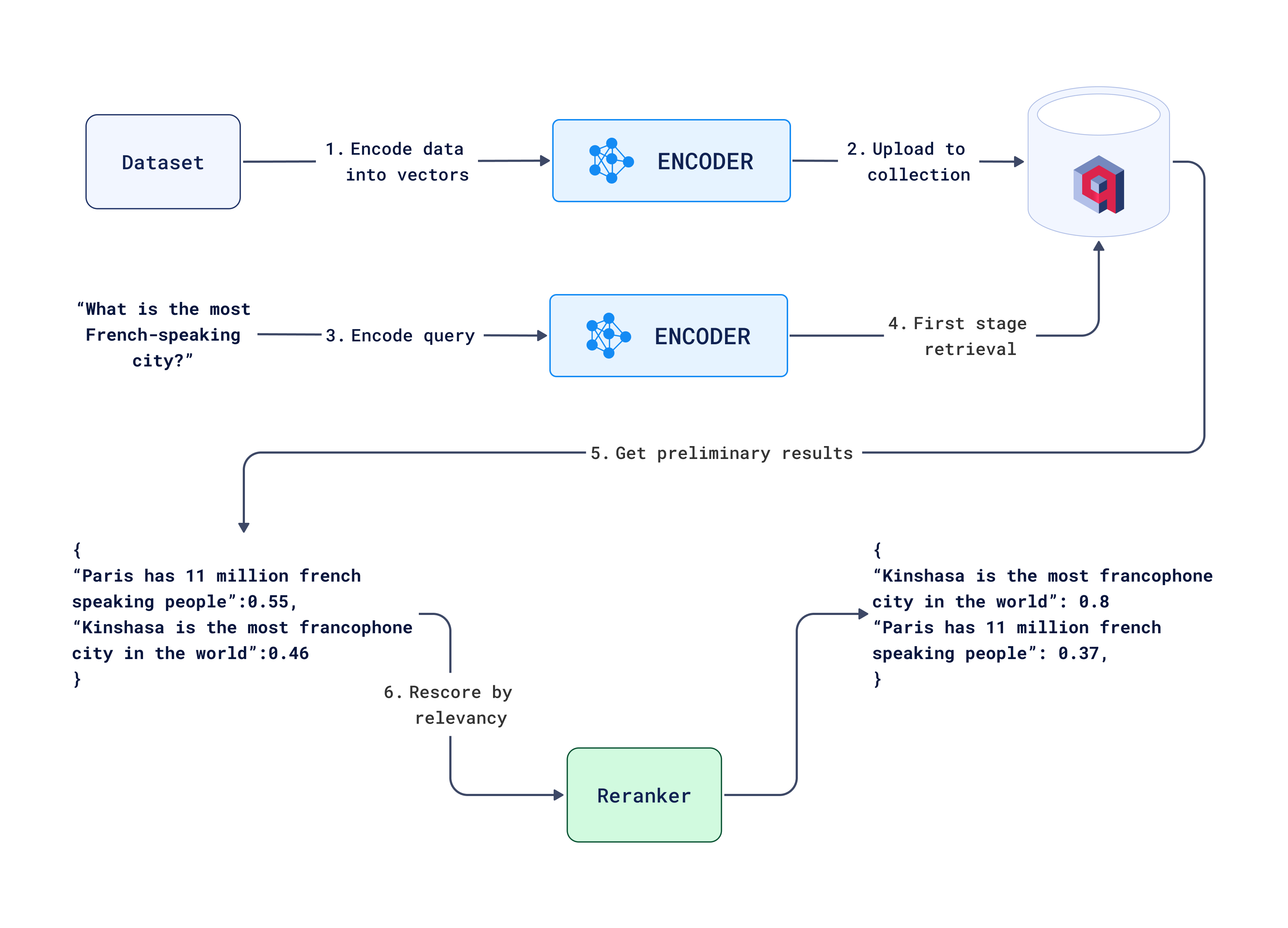
Search workflow with reranking
Technical Challenges
1. Building a New Input-Output Scheme
FastEmbed already had support for embeddings, but re-ranking with cross-encoders meant building a completely new family of classes. These models accept a query and a set of documents, then return a list of relevance scores. For that, I created the base classes like TextCrossEncoderBase and OnnxCrossEncoder, taking inspiration from existing text embedding models.
One thing I had to ensure was that the new class hierarchy was user-friendly. Users should be able to work with cross-encoders without needing to know the complexities of the underlying models. For instance, they should be able to just write:
from fastembed.rerank.cross_encoder import TextCrossEncoder
encoder = TextCrossEncoder(model_name="Xenova/ms-marco-MiniLM-L-6-v2")
scores = encoder.rerank(query, documents)
Meanwhile, behind the scenes, we manage all the model loading, tokenization, and scoring.
2. Handling Tokenization for Cross-Encoders
Cross-encoders require careful tokenization because they need to distinguish between the query and the documents. This is done using token type IDs, which help the model differentiate between the two. To implement this, I configured the tokenizer to handle pairs of inputs—concatenating the query with each document and assigning token types accordingly.
Efficient tokenization is critical to ensure the performance of the models, and I optimized it specifically for ONNX models.
3. Model Loading and Integration
One of the most rewarding parts of the project was integrating the ONNX models into the FastEmbed library. ONNX models need to be loaded into a runtime environment that efficiently manages the computations.
While PyTorch is a common framework for these types of tasks, FastEmbed exclusively supports ONNX models, making it both lightweight and efficient. I focused on extensive testing to ensure that the ONNX models performed equivalently to their PyTorch counterparts, ensuring users could trust the results.
I added support for batching as well, allowing users to re-rank large sets of documents without compromising speed.
4. Debugging and Code Reviews
During the project, I encountered a number of challenges, including issues with model configurations, tokenizers, and test cases. With the help of my mentor, George Panchuk, I was able to resolve these issues and improve my understanding of best practices, particularly around code readability, maintainability, and style.
One notable lesson was the importance of keeping the code organized and maintainable, with a strong focus on readability. This included properly structuring modules and ensuring the entire codebase followed a clear, consistent style.
5. Testing and Validation
To ensure the accuracy and performance of the models, I conducted extensive testing. I compared the output of ONNX models with their PyTorch counterparts, ensuring the conversion to ONNX was correct. A key part of this process was rigorous testing to verify the outputs and identify potential issues, such as incorrect conversions or bugs in our implementation.
For instance, a test to validate the model’s output was structured as follows:
def test_rerank():
is_ci = os.getenv("CI")
for model_desc in TextCrossEncoder.list_supported_models():
if not is_ci and model_desc["size_in_GB"] > 1:
continue
model_name = model_desc["model"]
model = TextCrossEncoder(model_name=model_name)
query = "What is the capital of France?"
documents = ["Paris is the capital of France.", "Berlin is the capital of Germany."]
scores = np.array(model.rerank(query, documents))
canonical_scores = CANONICAL_SCORE_VALUES[model_name]
assert np.allclose(
scores, canonical_scores, atol=1e-3
), f"Model: {model_name}, Scores: {scores}, Expected: {canonical_scores}"
The CANONICAL_SCORE_VALUES were retrieved directly from the result of applying the original PyTorch models to the same input
Outcomes and Future Improvements
By the end of my project, I successfully added cross-encoders to the FastEmbed library, allowing users to re-rank search results based on relevance scores. This enhancement opens up new possibilities for applications that rely on contextual ranking, such as search engines and recommendation systems.
This functionality will be available as of FastEmbed 0.4.0.
Some areas for future improvements include:
- Expanding Model Support: We could add more cross-encoder models, especially from the sentence transformers library, to give users more options.
- Parallelization: Optimizing batch processing to handle even larger datasets could further improve performance.
- Custom Tokenization: For models with non-standard tokenization, like BAAI/bge-reranker, more specific tokenizer configurations could be added.
Overall Experience and Wrapping Up
Looking back, this internship has been an incredibly valuable experience. I’ve grown not only as a developer but also as someone who can take on complex projects and see them through from start to finish. The Qdrant team has been so supportive, especially during the debugging and review stages. I’ve learned so much about model integration, ONNX, and how to build tools that are user-friendly and scalable.
One key takeaway for me is the importance of understanding the user experience. It’s not just about getting the models to work but making sure they are easy to use and integrate into real-world applications. This experience has solidified my passion for building solutions that truly make an impact, and I’m excited to continue working on projects like this in the future.
Thank you for taking the time to read about my journey with Qdrant and the FastEmbed library. I’m excited to see how this work will continue to improve search experiences for users!