
Qdrant is one of the fastest vector search engines out there, so while looking for a demo to show off, we came upon the idea to do a search-as-you-type box with a fully semantic search backend. Now we already have a semantic/keyword hybrid search on our website. But that one is written in Python, which incurs some overhead for the interpreter. Naturally, I wanted to see how fast I could go using Rust.
Since Qdrant doesn’t embed by itself, I had to decide on an embedding model. The prior version used the SentenceTransformers package, which in turn employs Bert-based All-MiniLM-L6-V2 model. This model is battle-tested and delivers fair results at speed, so not experimenting on this front I took an ONNX version and ran that within the service.
The workflow looks like this:
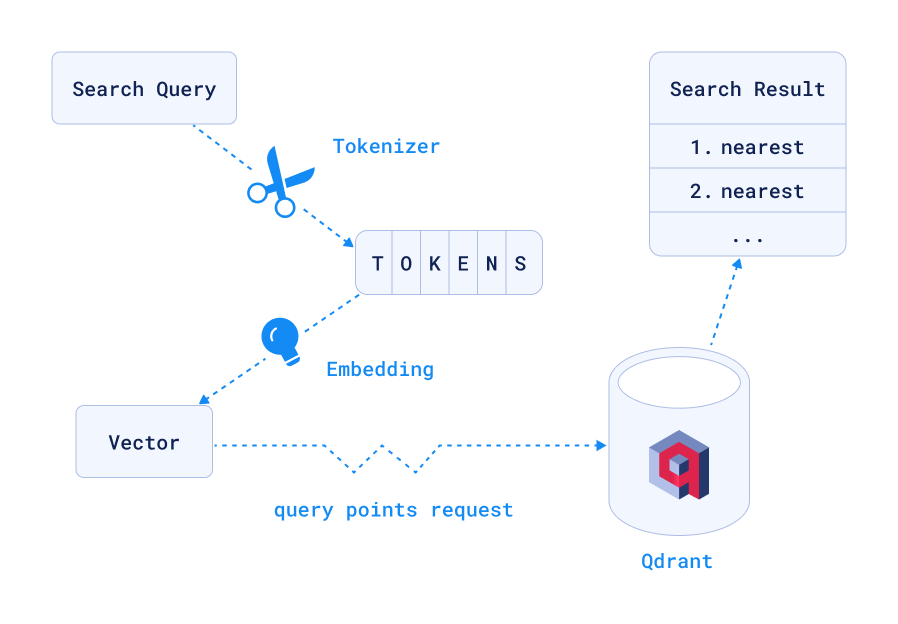
This will, after tokenizing and embedding send a /collections/site/points/search POST request to Qdrant, sending the following JSON:
POST collections/site/points/search
{
"vector": [-0.06716014,-0.056464013, ...(382 values omitted)],
"limit": 5,
"with_payload": true,
}
Even with avoiding a network round-trip, the embedding still takes some time. As always in optimization, if you cannot do the work faster, a good solution is to avoid work altogether (please don’t tell my employer). This can be done by pre-computing common prefixes and calculating embeddings for them, then storing them in a prefix_cache collection. Now the recommend API method can find the best matches without doing any embedding. For now, I use short (up to and including 5 letters) prefixes, but I can also parse the logs to get the most common search terms and add them to the cache later.
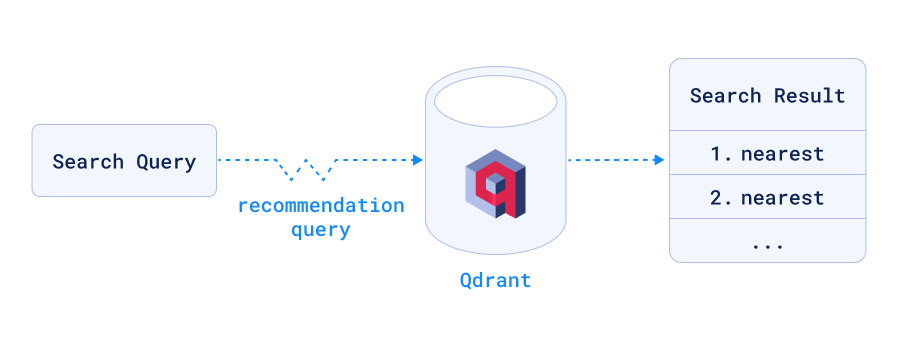
Making that work requires setting up the prefix_cache collection with points that have the prefix as their point_id and the embedding as their vector, which lets us do the lookup with no search or index. The prefix_to_id function currently uses the u64 variant of PointId, which can hold eight bytes, enough for this use. If the need arises, one could instead encode the names as UUID, hashing the input. Since I know all our prefixes are within 8 bytes, I decided against this for now.
The recommend endpoint works roughly the same as search_points, but instead of searching for a vector, Qdrant searches for one or more points (you can also give negative example points the search engine will try to avoid in the results). It was built to help drive recommendation engines, saving the round-trip of sending the current point’s vector back to Qdrant to find more similar ones. However Qdrant goes a bit further by allowing us to select a different collection to lookup the points, which allows us to keep our prefix_cache collection separate from the site data. So in our case, Qdrant first looks up the point from the prefix_cache, takes its vector and searches for that in the site collection, using the precomputed embeddings from the cache. The API endpoint expects a POST of the following JSON to /collections/site/points/recommend:
POST collections/site/points/recommend
{
"positive": [1936024932],
"limit": 5,
"with_payload": true,
"lookup_from": {
"collection": "prefix_cache"
}
}
Now I have, in the best Rust tradition, a blazingly fast semantic search.
To demo it, I used our Qdrant documentation website’s page search, replacing our previous Python implementation. So in order to not just spew empty words, here is a benchmark, showing different queries that exercise different code paths.
Since the operations themselves are far faster than the network whose fickle nature would have swamped most measurable differences, I benchmarked both the Python and Rust services locally. I’m measuring both versions on the same AMD Ryzen 9 5900HX with 16GB RAM running Linux. The table shows the average time and error bound in milliseconds. I only measured up to a thousand concurrent requests. None of the services showed any slowdown with more requests in that range. I do not expect our service to become DDOS’d, so I didn’t benchmark with more load.
Without further ado, here are the results:
| query length | Short | Long |
|---|---|---|
| Python 🐍 | 16 ± 4 ms | 16 ± 4 ms |
| Rust 🦀 | 1½ ± ½ ms | 5 ± 1 ms |
The Rust version consistently outperforms the Python version and offers a semantic search even on few-character queries. If the prefix cache is hit (as in the short query length), the semantic search can even get more than ten times faster than the Python version. The general speed-up is due to both the relatively lower overhead of Rust + Actix Web compared to Python + FastAPI (even if that already performs admirably), as well as using ONNX Runtime instead of SentenceTransformers for the embedding. The prefix cache gives the Rust version a real boost by doing a semantic search without doing any embedding work.
As an aside, while the millisecond differences shown here may mean relatively little for our users, whose latency will be dominated by the network in between, when typing, every millisecond more or less can make a difference in user perception. Also search-as-you-type generates between three and five times as much load as a plain search, so the service will experience more traffic. Less time per request means being able to handle more of them.
Mission accomplished! But wait, there’s more!
Prioritizing Exact Matches and Headings
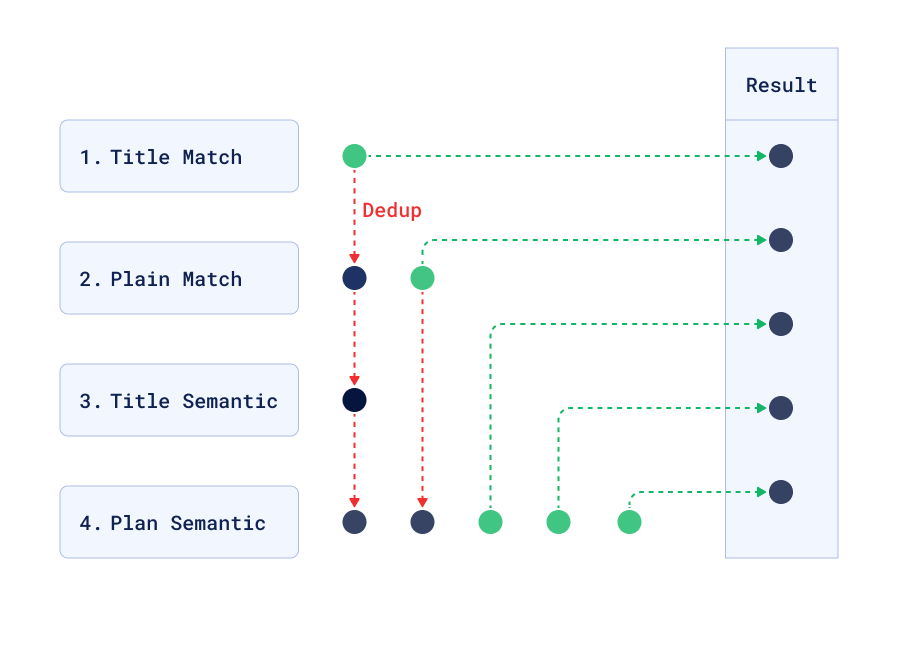
To improve on the quality of the results, Qdrant can do multiple searches in parallel, and then the service puts the results in sequence, taking the first best matches. The extended code searches:
- Text matches in titles
- Text matches in body (paragraphs or lists)
- Semantic matches in titles
- Any Semantic matches
Those are put together by taking them in the above order, deduplicating as necessary.
Instead of sending a search or recommend request, one can also send a search/batch or recommend/batch request, respectively. Each of those contain a "searches" property with any number of search/recommend JSON requests:
POST collections/site/points/search/batch
{
"searches": [
{
"vector": [-0.06716014,-0.056464013, ...],
"filter": {
"must": [
{ "key": "text", "match": { "text": <query> }},
{ "key": "tag", "match": { "any": ["h1", "h2", "h3"] }},
]
}
...,
},
{
"vector": [-0.06716014,-0.056464013, ...],
"filter": {
"must": [ { "key": "body", "match": { "text": <query> }} ]
}
...,
},
{
"vector": [-0.06716014,-0.056464013, ...],
"filter": {
"must": [ { "key": "tag", "match": { "any": ["h1", "h2", "h3"] }} ]
}
...,
},
{
"vector": [-0.06716014,-0.056464013, ...],
...,
},
]
}
As the queries are done in a batch request, there isn’t any additional network overhead and only very modest computation overhead, yet the results will be better in many cases.
The only additional complexity is to flatten the result lists and take the first 5 results, deduplicating by point ID. Now there is one final problem: The query may be short enough to take the recommend code path, but still not be in the prefix cache. In that case, doing the search sequentially would mean two round-trips between the service and the Qdrant instance. The solution is to concurrently start both requests and take the first successful non-empty result.
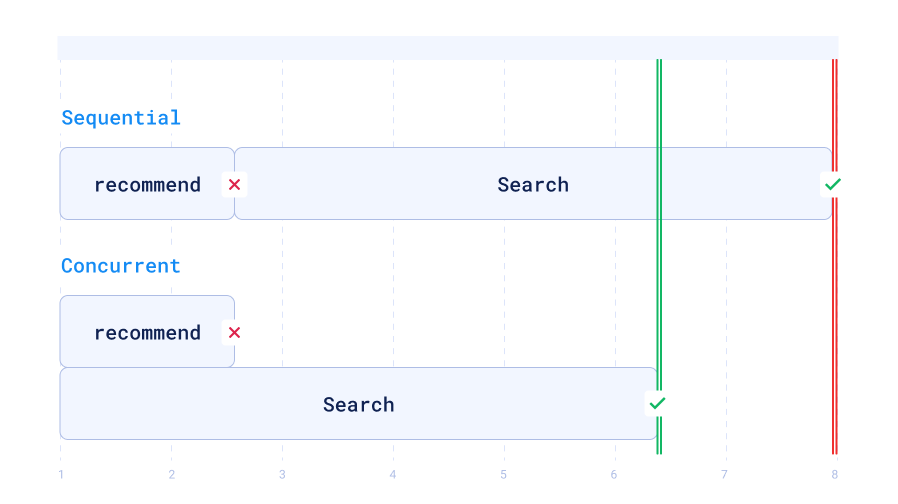
While this means more load for the Qdrant vector search engine, this is not the limiting factor. The relevant data is already in cache in many cases, so the overhead stays within acceptable bounds, and the maximum latency in case of prefix cache misses is measurably reduced.
The code is available on the Qdrant github
To sum up: Rust is fast, recommend lets us use precomputed embeddings, batch requests are awesome and one can do a semantic search in mere milliseconds.