
Vector Similarity: Unleashing Data Insights Beyond Traditional Search
When making use of unstructured data, there are traditional go-to solutions that are well-known for developers:
- Full-text search when you need to find documents that contain a particular word or phrase.
- Vector search when you need to find documents that are semantically similar to a given query.
Sometimes people mix those two approaches, so it might look like the vector similarity is just an extension of full-text search. However, in this article, we will explore some promising new techniques that can be used to expand the use-case of unstructured data and demonstrate that vector similarity creates its own stack of data exploration tools.
What is vector similarity search?
Vector similarity offers a range of powerful functions that go far beyond those available in traditional full-text search engines. From dissimilarity search to diversity and recommendation, these methods can expand the cases in which vectors are useful.
Vector Databases, which are designed to store and process immense amounts of vectors, are the first candidates to implement these new techniques and allow users to exploit their data to its fullest.
Vector similarity search vs. full-text search
While there is an intersection in the functionality of these two approaches, there is also a vast area of functions that is unique to each of them. For example, the exact phrase matching and counting of results are native to full-text search, while vector similarity support for this type of operation is limited. On the other hand, vector similarity easily allows cross-modal retrieval of images by text or vice-versa, which is impossible with full-text search.
This mismatch in expectations might sometimes lead to confusion. Attempting to use a vector similarity as a full-text search can result in a range of frustrations, from slow response times to poor search results, to limited functionality. As an outcome, they are getting only a fraction of the benefits of vector similarity.
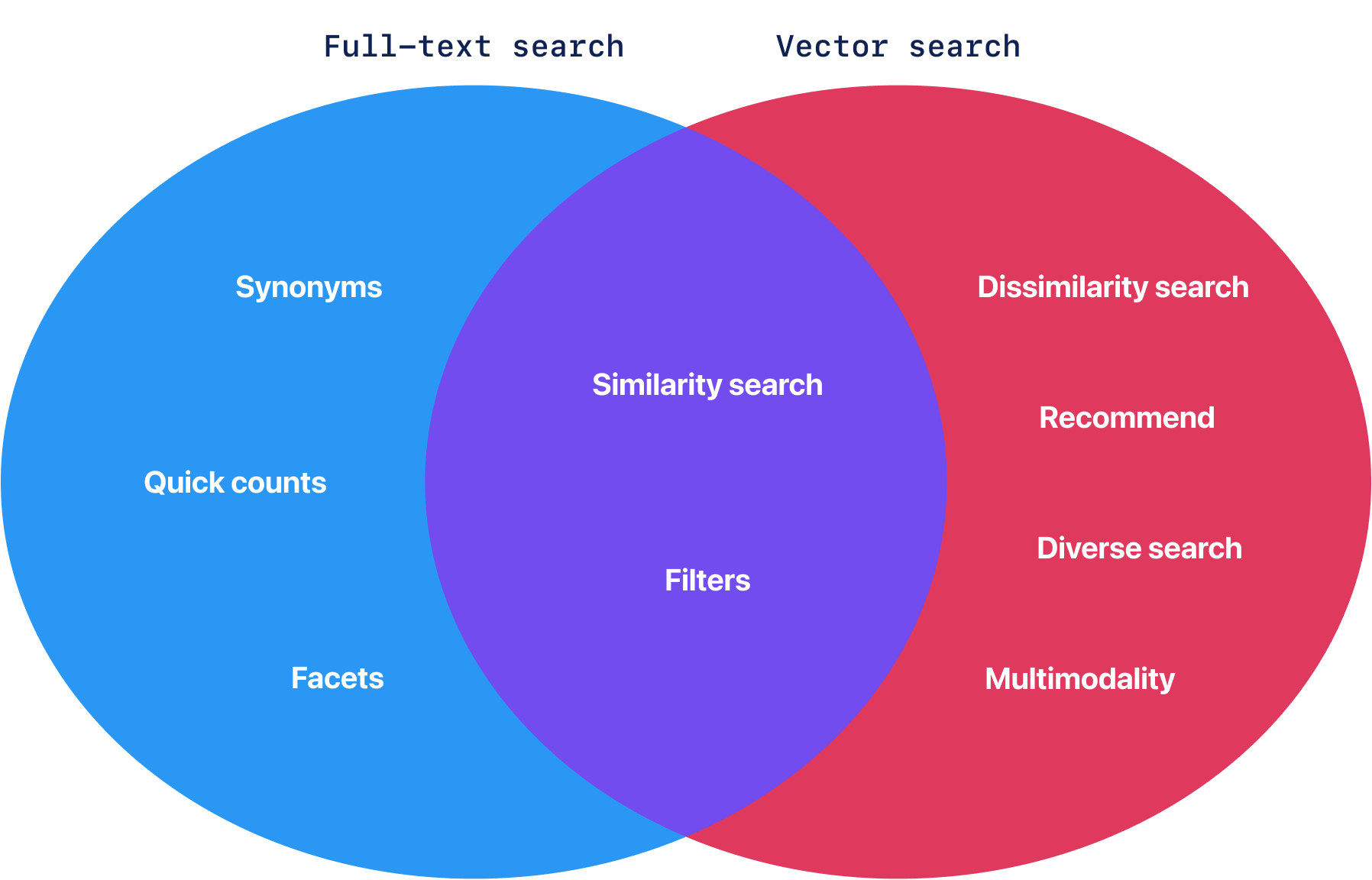
Full-text search and Vector Similarity Functionality overlap
Below we will explore why the vector similarity stack deserves new interfaces and design patterns that will unlock the full potential of this technology, which can still be used in conjunction with full-text search.
New ways to interact with similarities
Having a vector representation of unstructured data unlocks new ways of interacting with it. For example, it can be used to measure semantic similarity between words, to cluster words or documents based on their meaning, to find related images, or even to generate new text. However, these interactions can go beyond finding their nearest neighbors (kNN).
There are several other techniques that can be leveraged by vector representations beyond the traditional kNN search. These include dissimilarity search, diversity search, recommendations, and discovery functions.
Dissimilarity ssearch
The Dissimilarity —or farthest— search is the most straightforward concept after the nearest search, which can’t be reproduced in a traditional full-text search. It aims to find the most un-similar or distant documents across the collection.
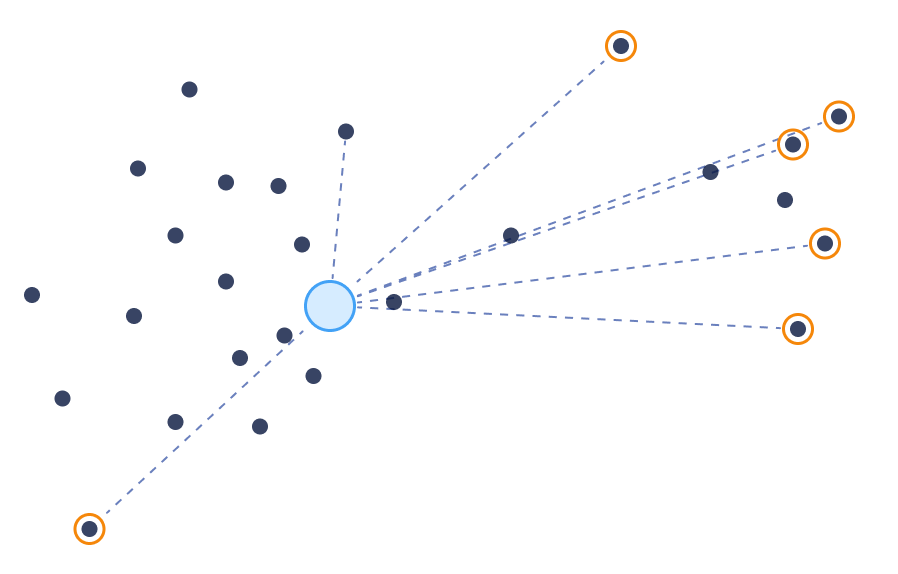
Dissimilarity Search
Unlike full-text match, Vector similarity can compare any pair of documents (or points) and assign a similarity score. It doesn’t rely on keywords or other metadata. With vector similarity, we can easily achieve a dissimilarity search by inverting the search objective from maximizing similarity to minimizing it.
The dissimilarity search can find items in areas where previously no other search could be used. Let’s look at a few examples.
Case: mislabeling detection
For example, we have a dataset of furniture in which we have classified our items into what kind of furniture they are: tables, chairs, lamps, etc. To ensure our catalog is accurate, we can use a dissimilarity search to highlight items that are most likely mislabeled.
To do this, we only need to search for the most dissimilar items using the embedding of the category title itself as a query. This can be too broad, so, by combining it with filters —a Qdrant superpower—, we can narrow down the search to a specific category.

Mislabeling Detection
The output of this search can be further processed with heavier models or human supervision to detect actual mislabeling.
Case: outlier detection
In some cases, we might not even have labels, but it is still possible to try to detect anomalies in our dataset. Dissimilarity search can be used for this purpose as well.
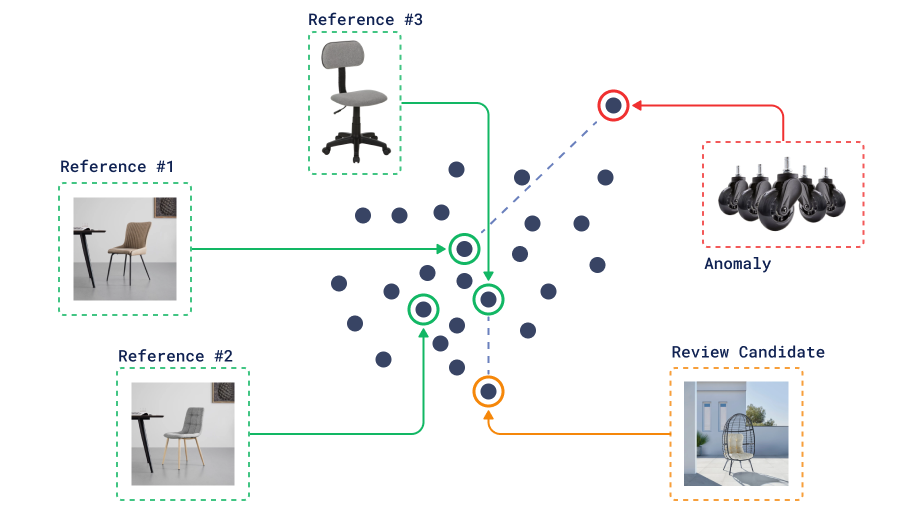
Anomaly Detection
The only thing we need is a bunch of reference points that we consider “normal”. Then we can search for the most dissimilar points to this reference set and use them as candidates for further analysis.
Diversity search
Even with no input provided vector, (dis-)similarity can improve an overall selection of items from the dataset.
The naive approach is to do random sampling. However, unless our dataset has a uniform distribution, the results of such sampling might be biased toward more frequent types of items.

Example of random sampling
The similarity information can increase the diversity of those results and make the first overview more interesting. That is especially useful when users do not yet know what they are looking for and want to explore the dataset.

Example of similarity-based sampling
The power of vector similarity, in the context of being able to compare any two points, allows making a diverse selection of the collection possible without any labeling efforts. By maximizing the distance between all points in the response, we can have an algorithm that will sequentially output dissimilar results.
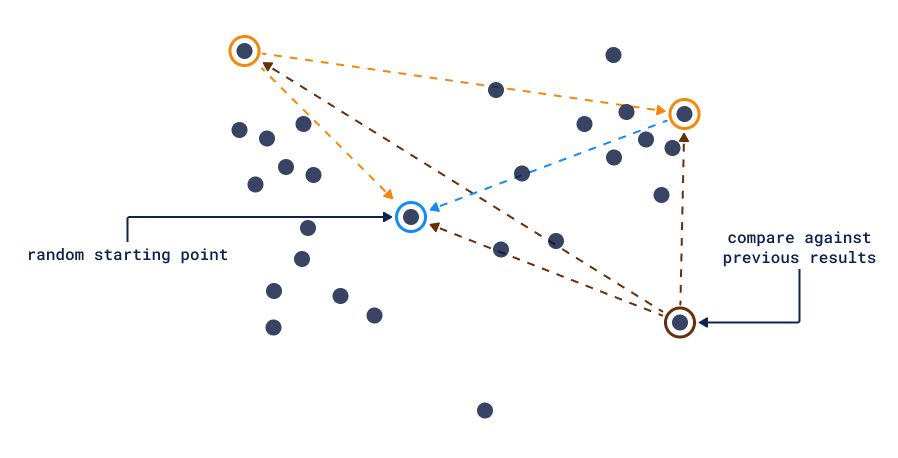
Diversity Search
Some forms of diversity sampling are already used in the industry and are known as Maximum Margin Relevance (MMR). Techniques like this were developed to enhance similarity on a universal search API. However, there is still room for new ideas, particularly regarding diversity retrieval. By utilizing more advanced vector-native engines, it could be possible to take use cases to the next level and achieve even better results.
Vector similarity recommendations
Vector similarity can go above a single query vector. It can combine multiple positive and negative examples for a more accurate retrieval. Building a recommendation API in a vector database can take advantage of using already stored vectors as part of the queries, by specifying the point id. Doing this, we can skip query-time neural network inference, and make the recommendation search faster.
There are multiple ways to implement recommendations with vectors.
Vector-features recommendations
The first approach is to take all positive and negative examples and average them to create a single query vector. In this technique, the more significant components of positive vectors are canceled out by the negative ones, and the resulting vector is a combination of all the features present in the positive examples, but not in the negative ones.
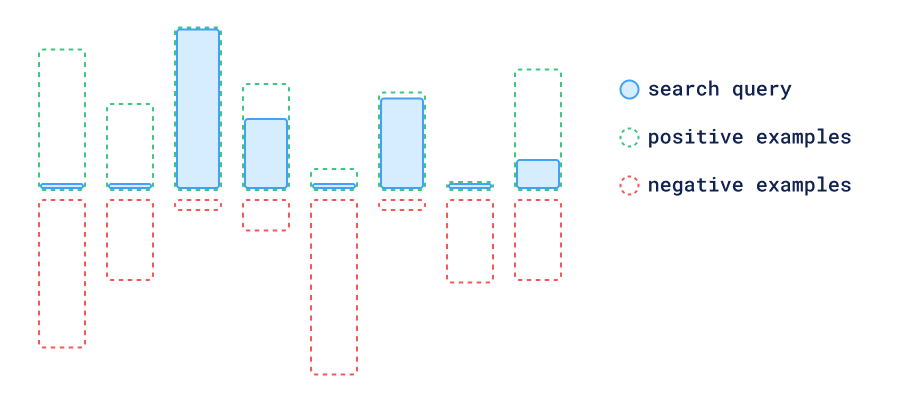
Vector-Features Based Recommendations
This approach is already implemented in Qdrant, and while it works great when the vectors are assumed to have each of their dimensions represent some kind of feature of the data, sometimes distances are a better tool to judge negative and positive examples.
Relative distance recommendations
Another approach is to use the distance between negative examples to the candidates to help them create exclusion areas. In this technique, we perform searches near the positive examples while excluding the points that are closer to a negative example than to a positive one.
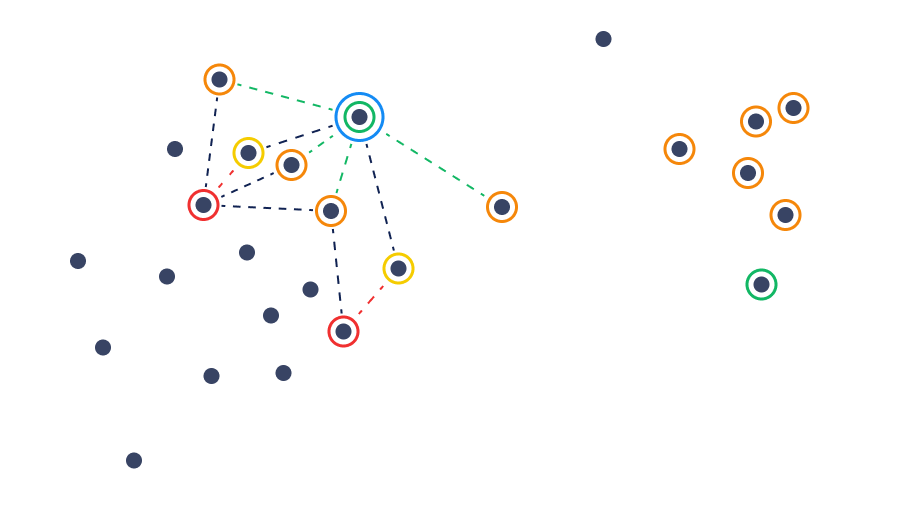
Relative Distance Recommendations
The main use-case of both approaches —of course— is to take some history of user interactions and recommend new items based on it.
Discovery
In many exploration scenarios, the desired destination is not known in advance. The search process in this case can consist of multiple steps, where each step would provide a little more information to guide the search in the right direction.
To get more intuition about the possible ways to implement this approach, let’s take a look at how similarity modes are trained in the first place:
The most well-known loss function used to train similarity models is a triplet-loss. In this loss, the model is trained by fitting the information of relative similarity of 3 objects: the Anchor, Positive, and Negative examples.
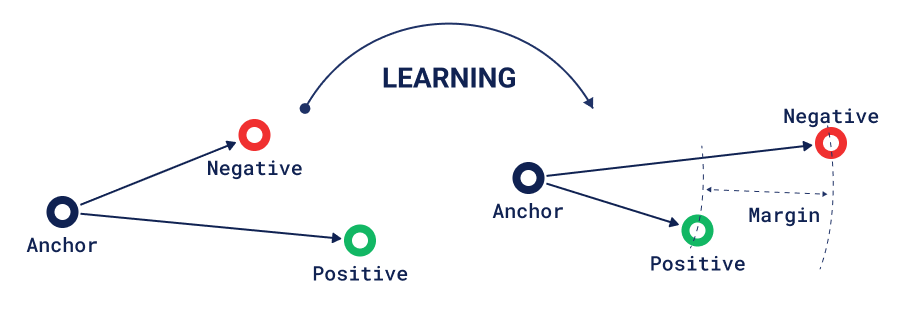
Triplet Loss
Using the same mechanics, we can look at the training process from the other side. Given a trained model, the user can provide positive and negative examples, and the goal of the discovery process is then to find suitable anchors across the stored collection of vectors.
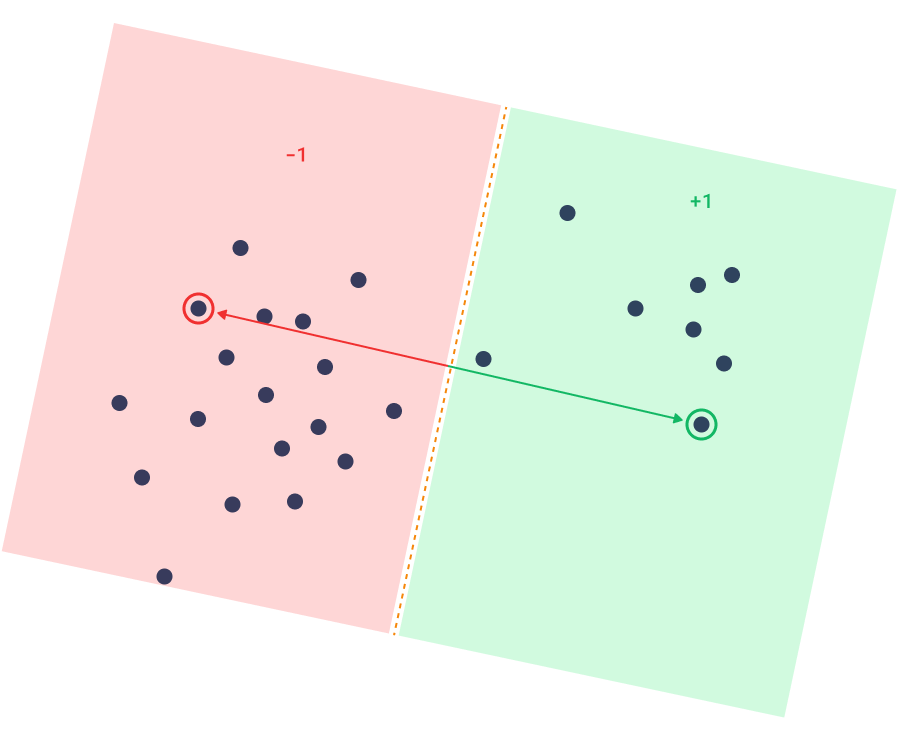
Reversed triplet loss
Multiple positive-negative pairs can be provided to make the discovery process more accurate. Worth mentioning, that as well as in NN training, the dataset may contain noise and some portion of contradictory information, so a discovery process should be tolerant of this kind of data imperfections.
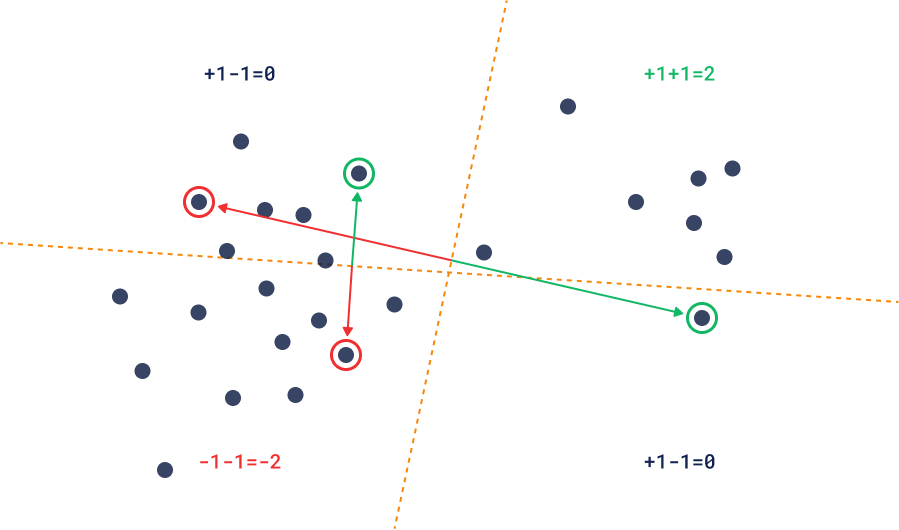
Sample pairs
The important difference between this and the recommendation method is that the positive-negative pairs in the discovery method don’t assume that the final result should be close to positive, it only assumes that it should be closer than the negative one.
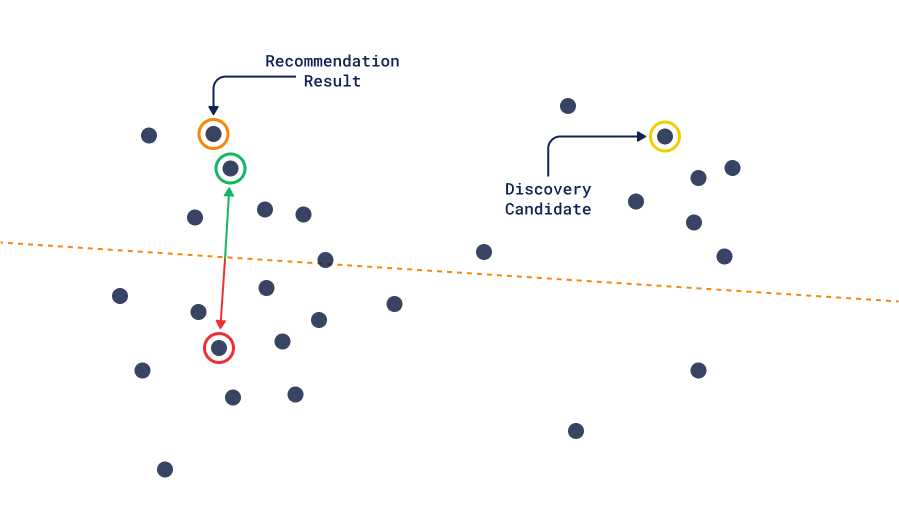
Discovery vs Recommendation
In combination with filtering or similarity search, the additional context information provided by the discovery pairs can be used as a re-ranking factor.
A new API stack for vector databases
When you introduce vector similarity capabilities into your text search engine, you extend its functionality. However, it doesn’t work the other way around, as the vector similarity as a concept is much broader than some task-specific implementations of full-text search.
Vector databases, which introduce built-in full-text functionality, must make several compromises:
- Choose a specific full-text search variant.
- Either sacrifice API consistency or limit vector similarity functionality to only basic kNN search.
- Introduce additional complexity to the system.
Qdrant, on the contrary, puts vector similarity in the center of its API and architecture, such that it allows us to move towards a new stack of vector-native operations. We believe that this is the future of vector databases, and we are excited to see what new use-cases will be unlocked by these techniques.
Key takeaways:
- Vector similarity offers advanced data exploration tools beyond traditional full-text search, including dissimilarity search, diversity sampling, and recommendation systems.
- Practical applications of vector similarity include improving data quality through mislabeling detection and anomaly identification.
- Enhanced user experiences are achieved by leveraging advanced search techniques, providing users with intuitive data exploration, and improving decision-making processes.
Ready to unlock the full potential of your data? Try a free demo to explore how vector similarity can revolutionize your data insights and drive smarter decision-making.