Finding errors in datasets with Similarity Search
George Panchuk
·July 18, 2022

Nowadays, people create a huge number of applications of various types and solve problems in different areas. Despite such diversity, they have something in common - they need to process data. Real-world data is a living structure, it grows day by day, changes a lot and becomes harder to work with.
In some cases, you need to categorize or label your data, which can be a tough problem given its scale. The process of splitting or labelling is error-prone and these errors can be very costly. Imagine that you failed to achieve the desired quality of the model due to inaccurate labels. Worse, your users are faced with a lot of irrelevant items, unable to find what they need and getting annoyed by it. Thus, you get poor retention, and it directly impacts company revenue. It is really important to avoid such errors in your data.
Furniture web-marketplace
Let’s say you work on an online furniture marketplace.
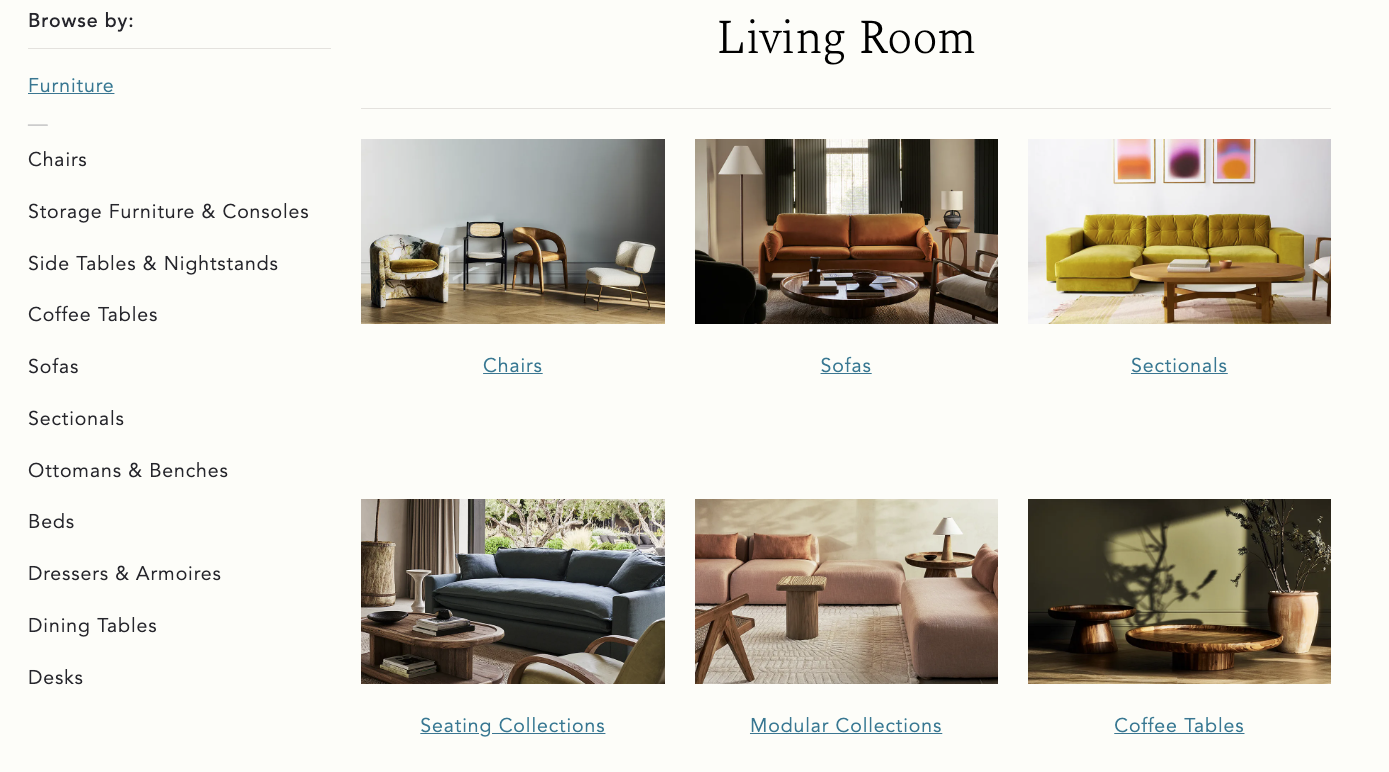
Furniture marketplace
In this case, to ensure a good user experience, you need to split items into different categories: tables, chairs, beds, etc. One can arrange all the items manually and spend a lot of money and time on this. There is also another way: train a classification or similarity model and rely on it. With both approaches it is difficult to avoid mistakes. Manual labelling is a tedious task, but it requires concentration. Once you got distracted or your eyes became blurred mistakes won’t keep you waiting. The model also can be wrong. You can analyse the most uncertain predictions and fix them, but the other errors will still leak to the site. There is no silver bullet. You should validate your dataset thoroughly, and you need tools for this.
When you are sure that there are not many objects placed in the wrong category, they can be considered outliers or anomalies. Thus, you can train a model or a bunch of models capable of looking for anomalies, e.g. autoencoder and a classifier on it. However, this is again a resource-intensive task, both in terms of time and manual labour, since labels have to be provided for classification. On the contrary, if the proportion of out-of-place elements is high enough, outlier search methods are likely to be useless.
Similarity search
The idea behind similarity search is to measure semantic similarity between related parts of the data. E.g. between category title and item images. The hypothesis is, that unsuitable items will be less similar.
We can’t directly compare text and image data. For this we need an intermediate representation - embeddings. Embeddings are just numeric vectors containing semantic information. We can apply a pre-trained model to our data to produce these vectors. After embeddings are created, we can measure the distances between them.
Assume we want to search for something other than a single bed in «Single beds» category.
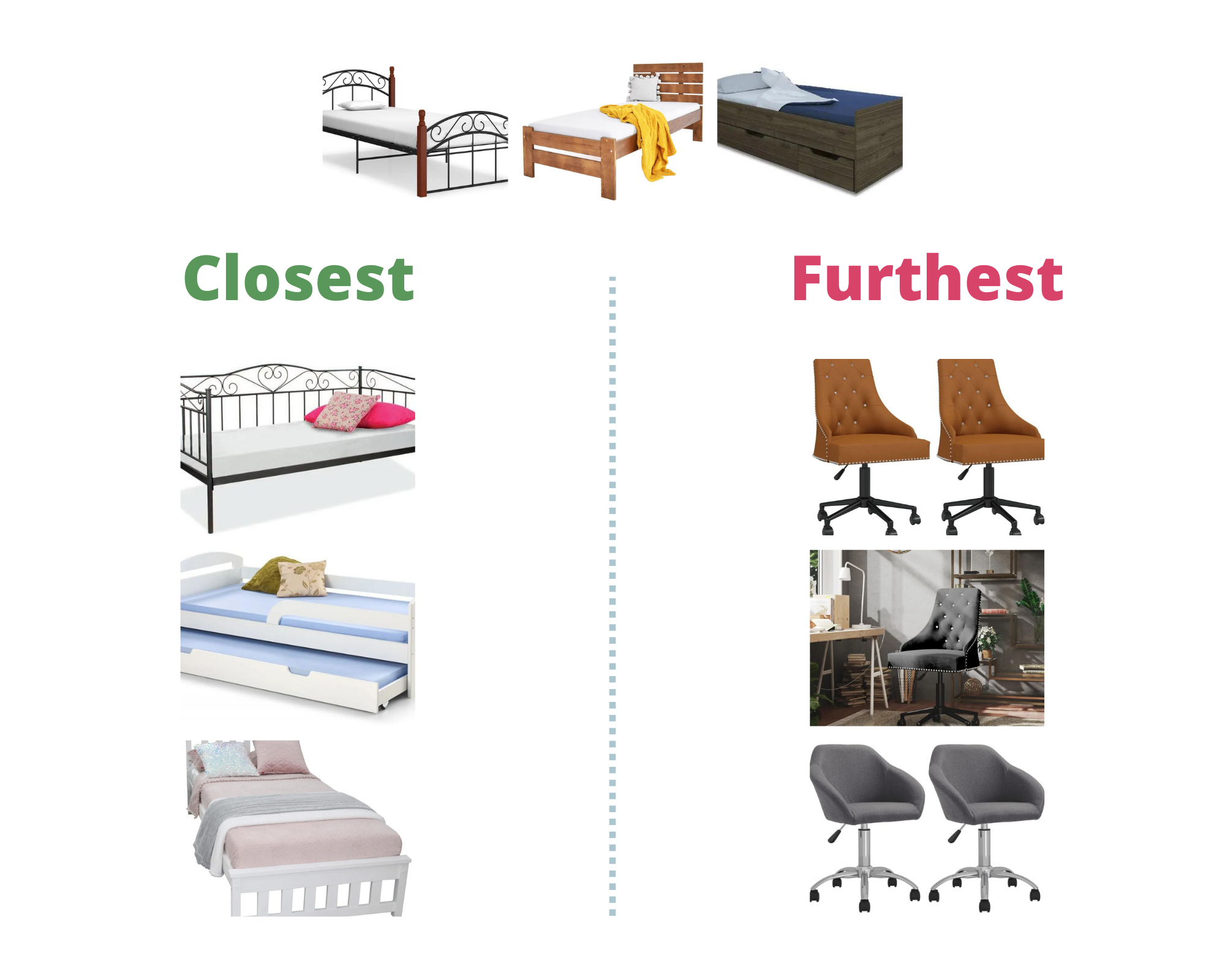
Similarity search
One of the possible pipelines would look like this:
- Take the name of the category as an anchor and calculate the anchor embedding.
- Calculate embeddings for images of each object placed into this category.
- Compare obtained anchor and object embeddings.
- Find the furthest.
For instance, we can do it with the CLIP model.
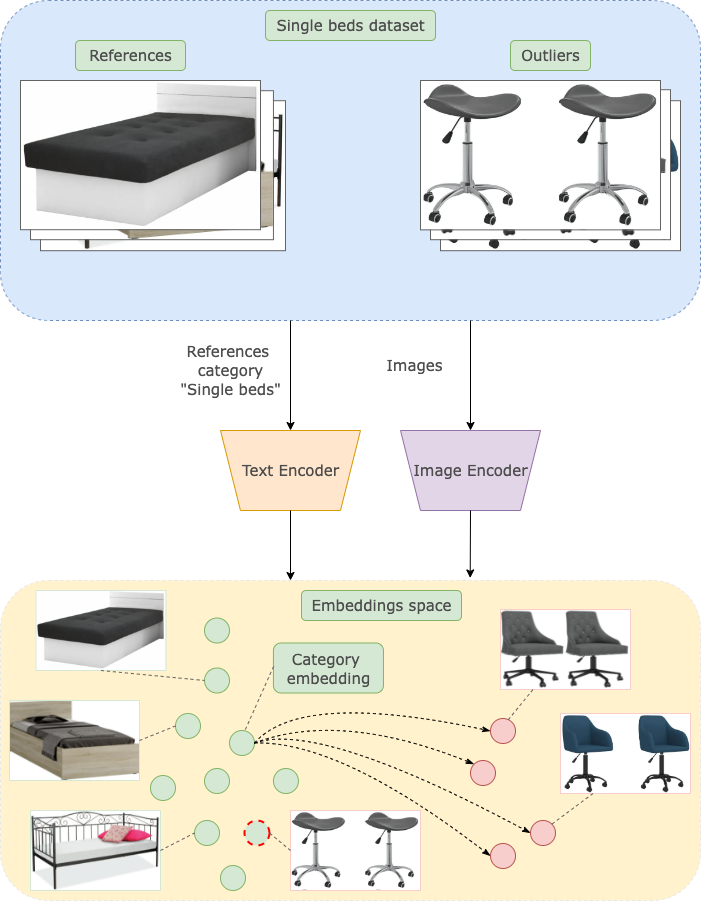
Category vs. Image
We can also calculate embeddings for titles instead of images, or even for both of them to find more errors.
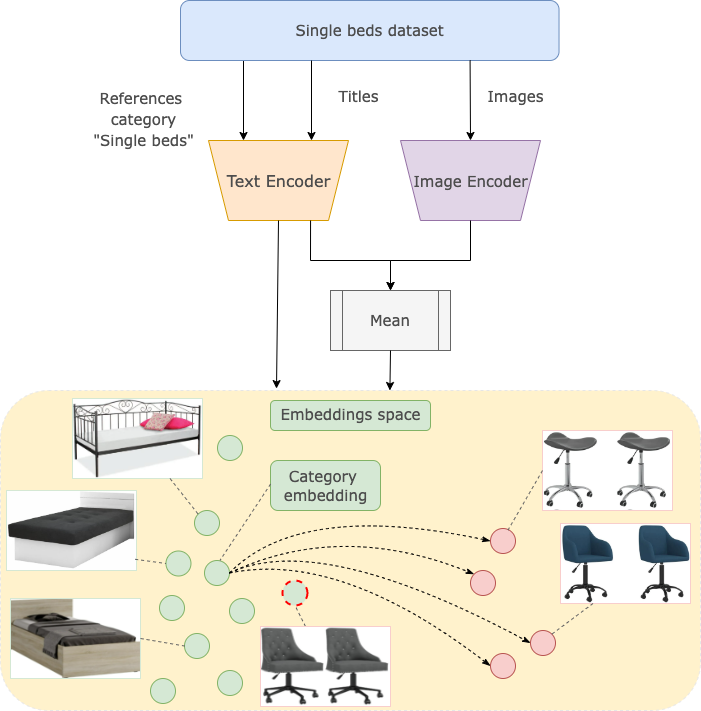
Category vs. Title and Image
As you can see, different approaches can find new errors or the same ones. Stacking several techniques or even the same techniques with different models may provide better coverage. Hint: Caching embeddings for the same models and reusing them among different methods can significantly speed up your lookup.
Diversity search
Since pre-trained models have only general knowledge about the data, they can still leave some misplaced items undetected. You might find yourself in a situation when the model focuses on non-important features, selects a lot of irrelevant elements, and fails to find genuine errors. To mitigate this issue, you can perform a diversity search.
Diversity search is a method for finding the most distinctive examples in the data. As similarity search, it also operates on embeddings and measures the distances between them. The difference lies in deciding which point should be extracted next.
Let’s imagine how to get 3 points with similarity search and then with diversity search.
Similarity:
- Calculate distance matrix
- Choose your anchor
- Get a vector corresponding to the distances from the selected anchor from the distance matrix
- Sort fetched vector
- Get top-3 embeddings
Diversity:
- Calculate distance matrix
- Initialize starting point (randomly or according to the certain conditions)
- Get a distance vector for the selected starting point from the distance matrix
- Find the furthest point
- Get a distance vector for the new point
- Find the furthest point from all of already fetched points
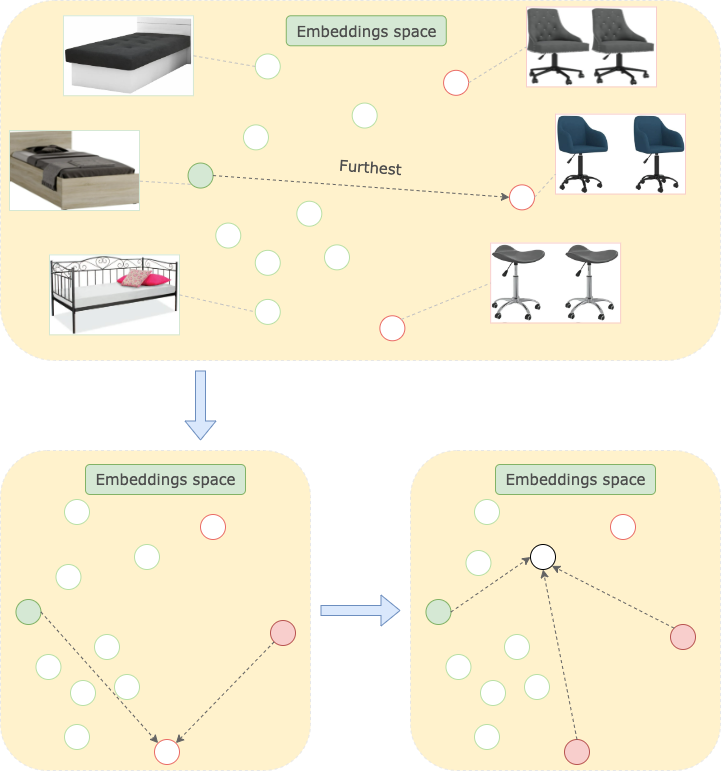
Diversity search
Diversity search utilizes the very same embeddings, and you can reuse them. If your data is huge and does not fit into memory, vector search engines like Qdrant might be helpful.
Although the described methods can be used independently. But they are simple to combine and improve detection capabilities. If the quality remains insufficient, you can fine-tune the models using a similarity learning approach (e.g. with Quaterion both to provide a better representation of your data and pull apart dissimilar objects in space.
Conclusion
In this article, we enlightened distance-based methods to find errors in categorized datasets. Showed how to find incorrectly placed items in the furniture web store. I hope these methods will help you catch sneaky samples leaked into the wrong categories in your data, and make your users` experience more enjoyable.
Poke the demo.
Stay tuned :)