
Discovery needs context
When Christopher Columbus and his crew sailed to cross the Atlantic Ocean, they were not looking for the Americas. They were looking for a new route to India because they were convinced that the Earth was round. They didn’t know anything about a new continent, but since they were going west, they stumbled upon it.
They couldn’t reach their target, because the geography didn’t let them, but once they realized it wasn’t India, they claimed it a new “discovery” for their crown. If we consider that sailors need water to sail, then we can establish a context which is positive in the water, and negative on land. Once the sailor’s search was stopped by the land, they could not go any further, and a new route was found. Let’s keep these concepts of target and context in mind as we explore the new functionality of Qdrant: Discovery search.
What is discovery search?
In version 1.7, Qdrant released this novel API that lets you constrain the space in which a search is performed, relying only on pure vectors. This is a powerful tool that lets you explore the vector space in a more controlled way. It can be used to find points that are not necessarily closest to the target, but are still relevant to the search.
You can already select which points are available to the search by using payload filters. This by itself is very versatile because it allows us to craft complex filters that show only the points that satisfy their criteria deterministically. However, the payload associated with each point is arbitrary and cannot tell us anything about their position in the vector space. In other words, filtering out irrelevant points can be seen as creating a mask rather than a hyperplane –cutting in between the positive and negative vectors– in the space.
Understanding context
This is where a vector context can help. We define context as a list of pairs. Each pair is made up of a positive and a negative vector. With a context, we can define hyperplanes within the vector space, which always prefer the positive over the negative vectors. This effectively partitions the space where the search is performed. After the space is partitioned, we then need a target to return the points that are more similar to it.
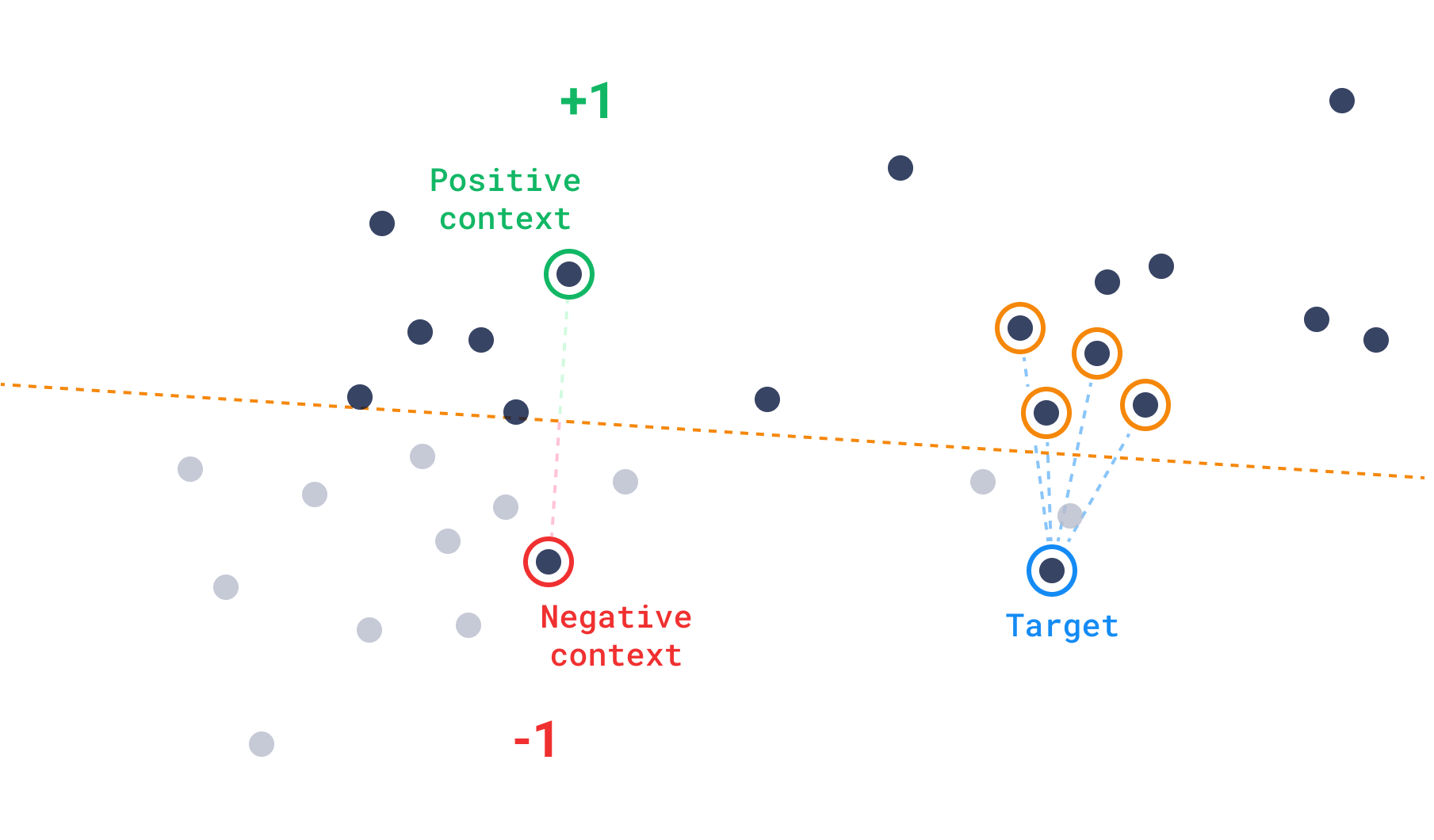
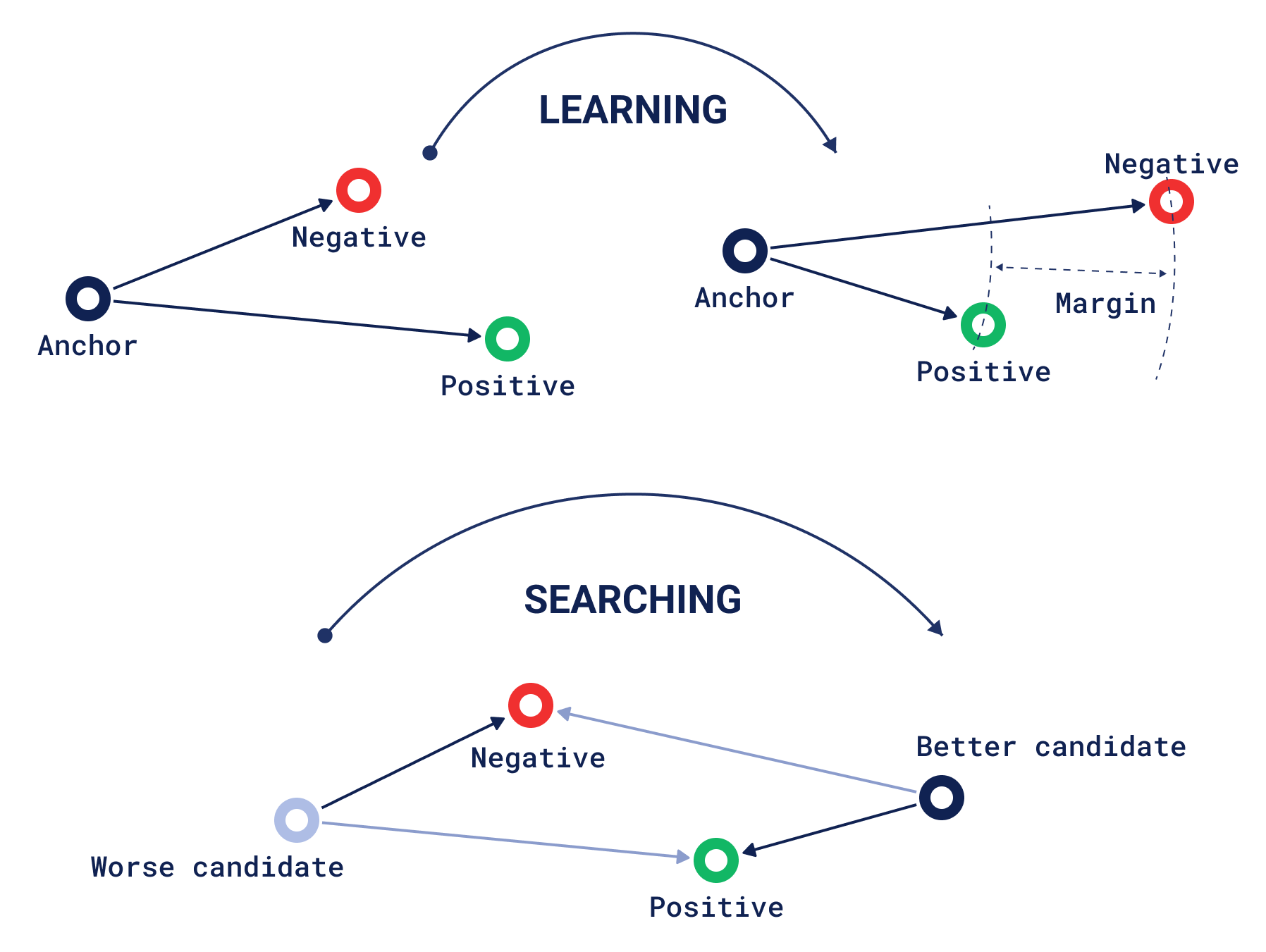
While positive and negative vectors might suggest the use of the recommendation interface, in the case of context they require to be paired up in a positive-negative fashion. This is inspired from the machine-learning concept of triplet loss, where you have three vectors: an anchor, a positive, and a negative. Triplet loss is an evaluation of how much the anchor is closer to the positive than to the negative vector, so that learning happens by “moving” the positive and negative points to try to get a better evaluation. However, during discovery, we consider the positive and negative vectors as static points, and we search through the whole dataset for the “anchors”, or result candidates, which fit this characteristic better.
Discovery search, then, is made up of two main inputs:
- target: the main point of interest
- context: the pairs of positive and negative points we just defined.
However, it is not the only way to use it. Alternatively, you can only provide a context, which invokes a Context Search. This is useful when you want to explore the space defined by the context, but don’t have a specific target in mind. But hold your horses, we’ll get to that later ↪.
Real-world discovery search applications
Let’s talk about the first case: context with a target.
To understand why this is useful, let’s take a look at a real-world example: using a multimodal encoder like CLIP to search for images, from text and images. CLIP is a neural network that can embed both images and text into the same vector space. This means that you can search for images using either a text query or an image query. For this example, we’ll reuse our food recommendations demo by typing “burger” in the text input:
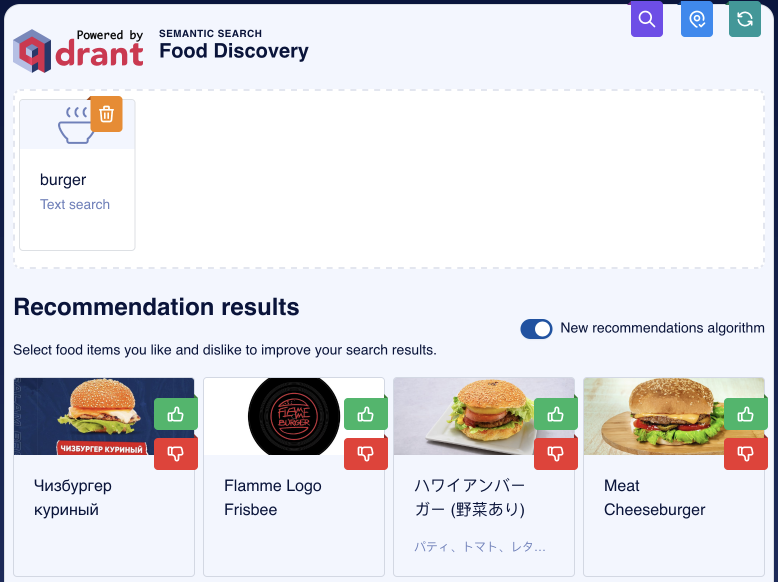
This is basically nearest neighbor search, and while technically we have only images of burgers, one of them is a logo representation of a burger. We’re looking for actual burgers, though. Let’s try to exclude images like that by adding it as a negative example:
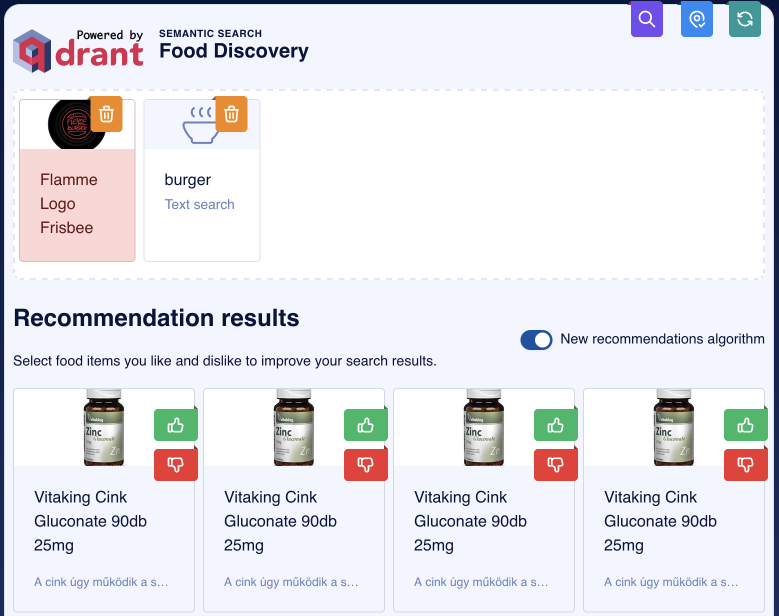
Wait a second, what has just happened? These pictures have nothing to do with burgers, and still, they appear on the first results. Is the demo broken?
Turns out, multimodal encoders might not work how you expect them to. Images and text are embedded in the same space, but they are not necessarily close to each other. This means that we can create a mental model of the distribution as two separate planes, one for images and one for text.
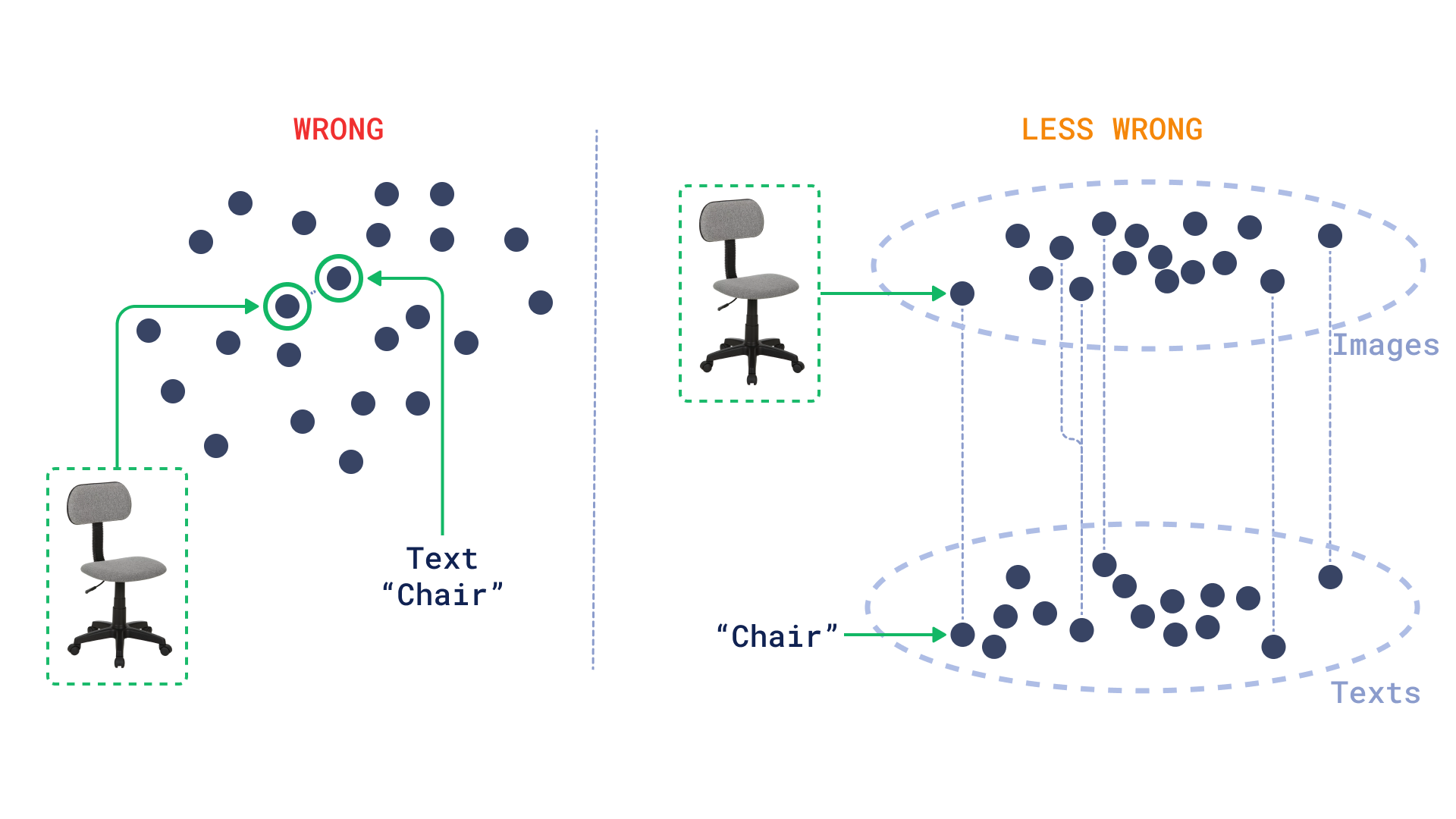
This is where discovery excels because it allows us to constrain the space considering the same mode (images) while using a target from the other mode (text).
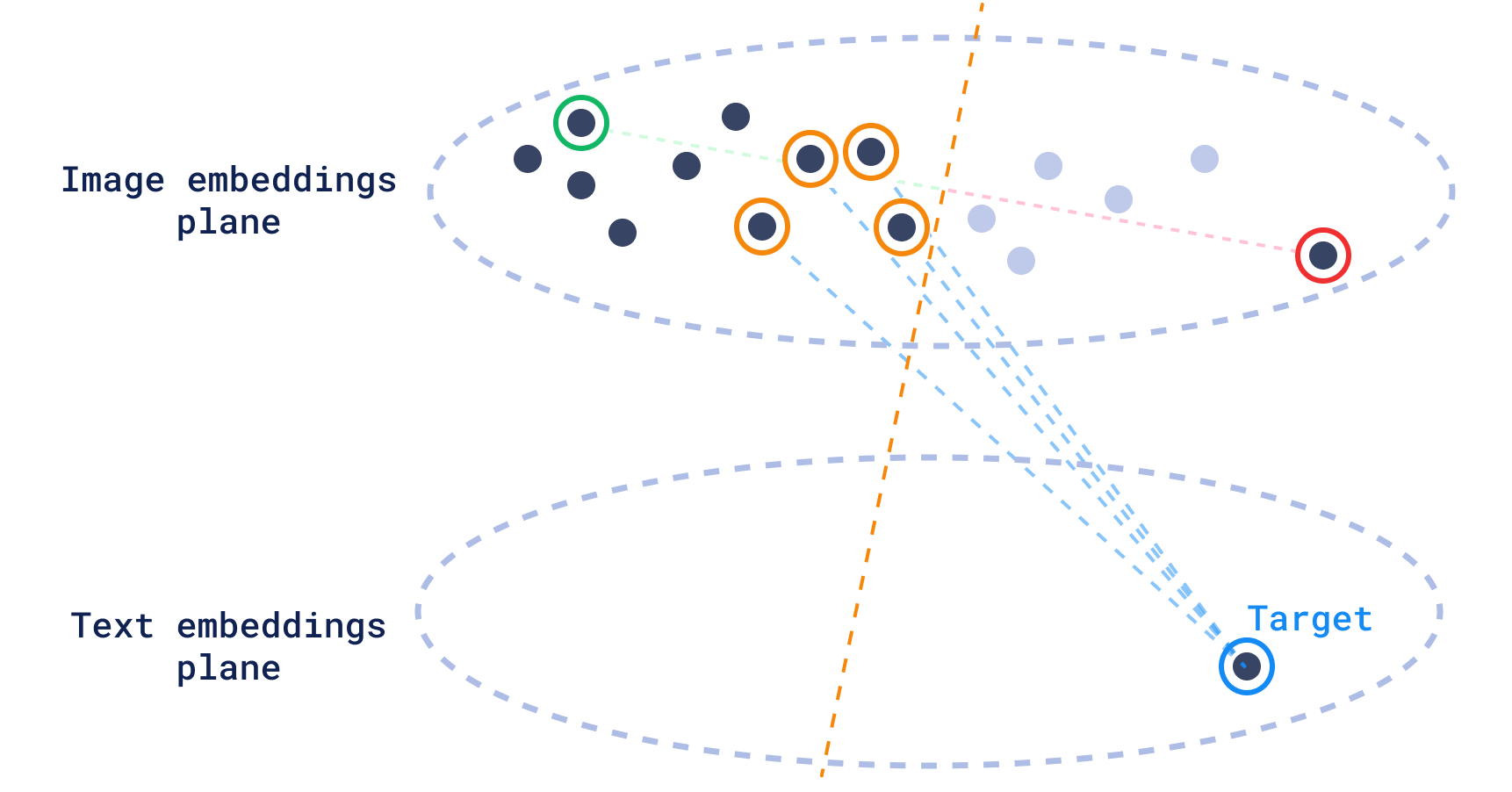
Discovery search also lets us keep giving feedback to the search engine in the shape of more context pairs, so we can keep refining our search until we find what we are looking for.
Another intuitive example: imagine you’re looking for a fish pizza, but pizza names can be confusing, so you can just type “pizza”, and prefer a fish over meat. Discovery search will let you use these inputs to suggest a fish pizza… even if it’s not called fish pizza!
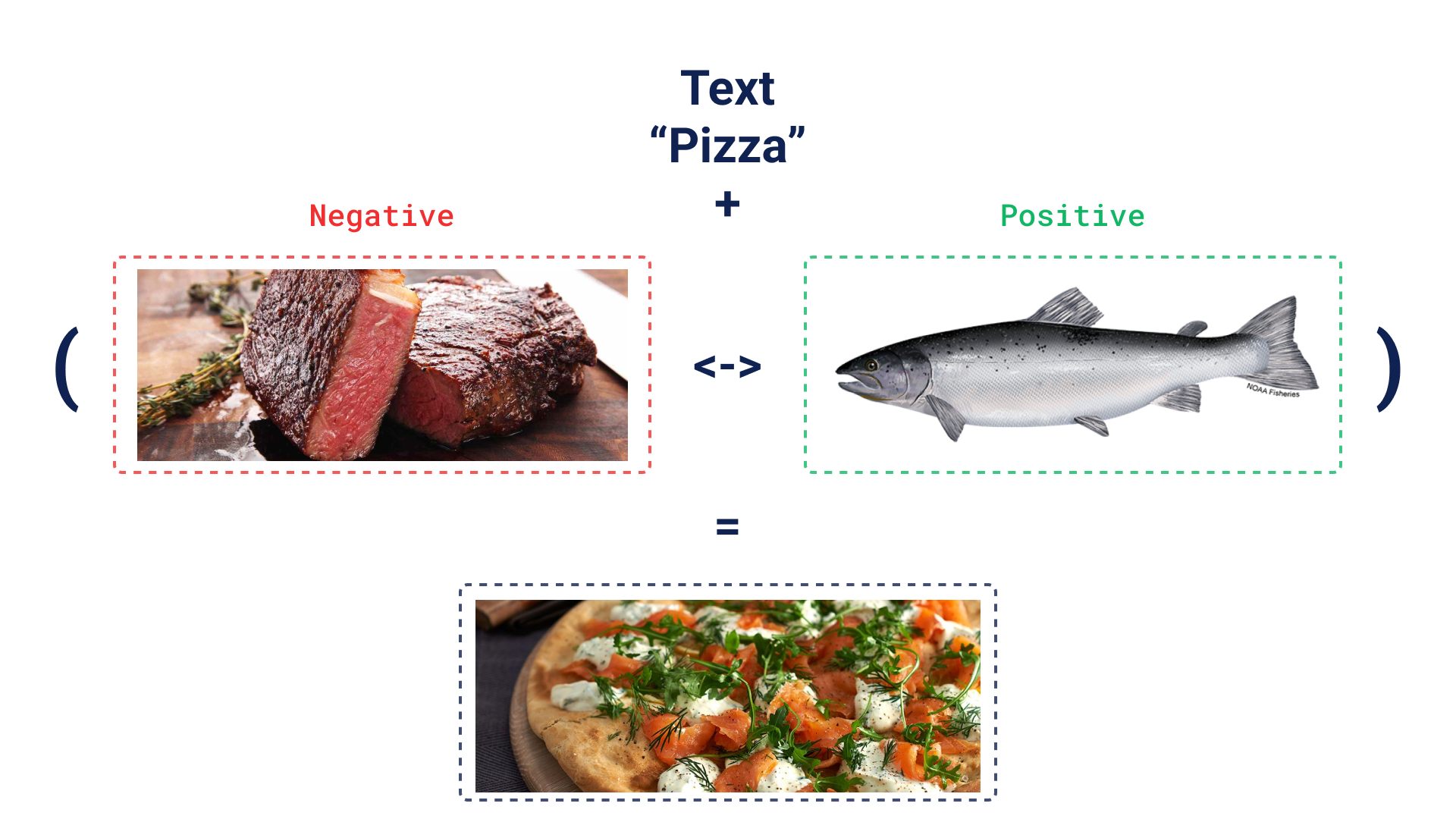
Context search
Now, the second case: only providing context.
Ever been caught in the same recommendations on your favorite music streaming service? This may be caused by getting stuck in a similarity bubble. As user input gets more complex, diversity becomes scarce, and it becomes harder to force the system to recommend something different.
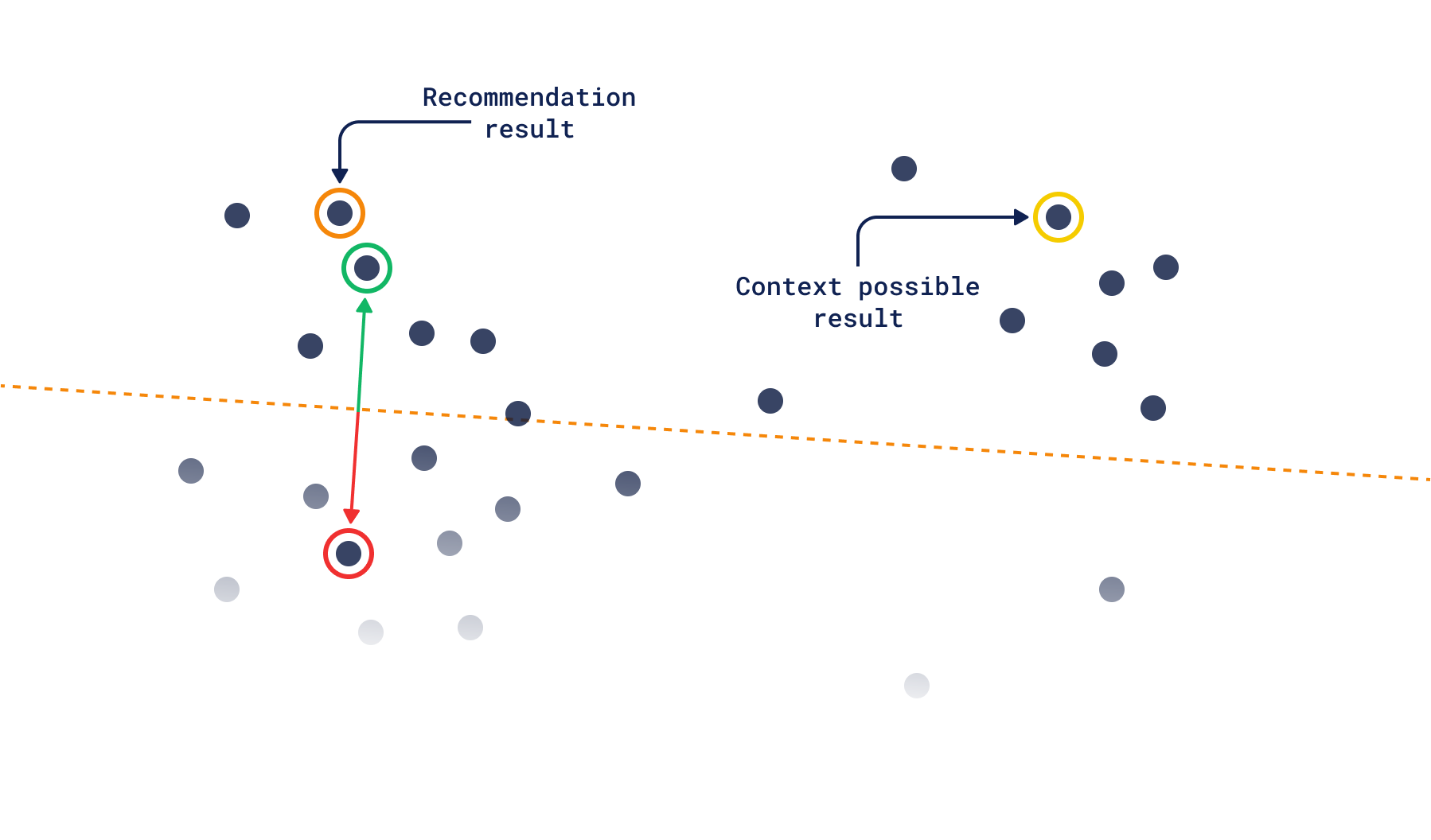
Context search solves this by de-focusing the search around a single point. Instead, it selects points randomly from within a zone in the vector space. This search is the most influenced by triplet loss, as the score can be thought of as “how much a point is closer to a negative than a positive vector?”. If it is closer to the positive one, then its score will be zero, same as any other point within the same zone. But if it is on the negative side, it will be assigned a more and more negative score the further it gets.
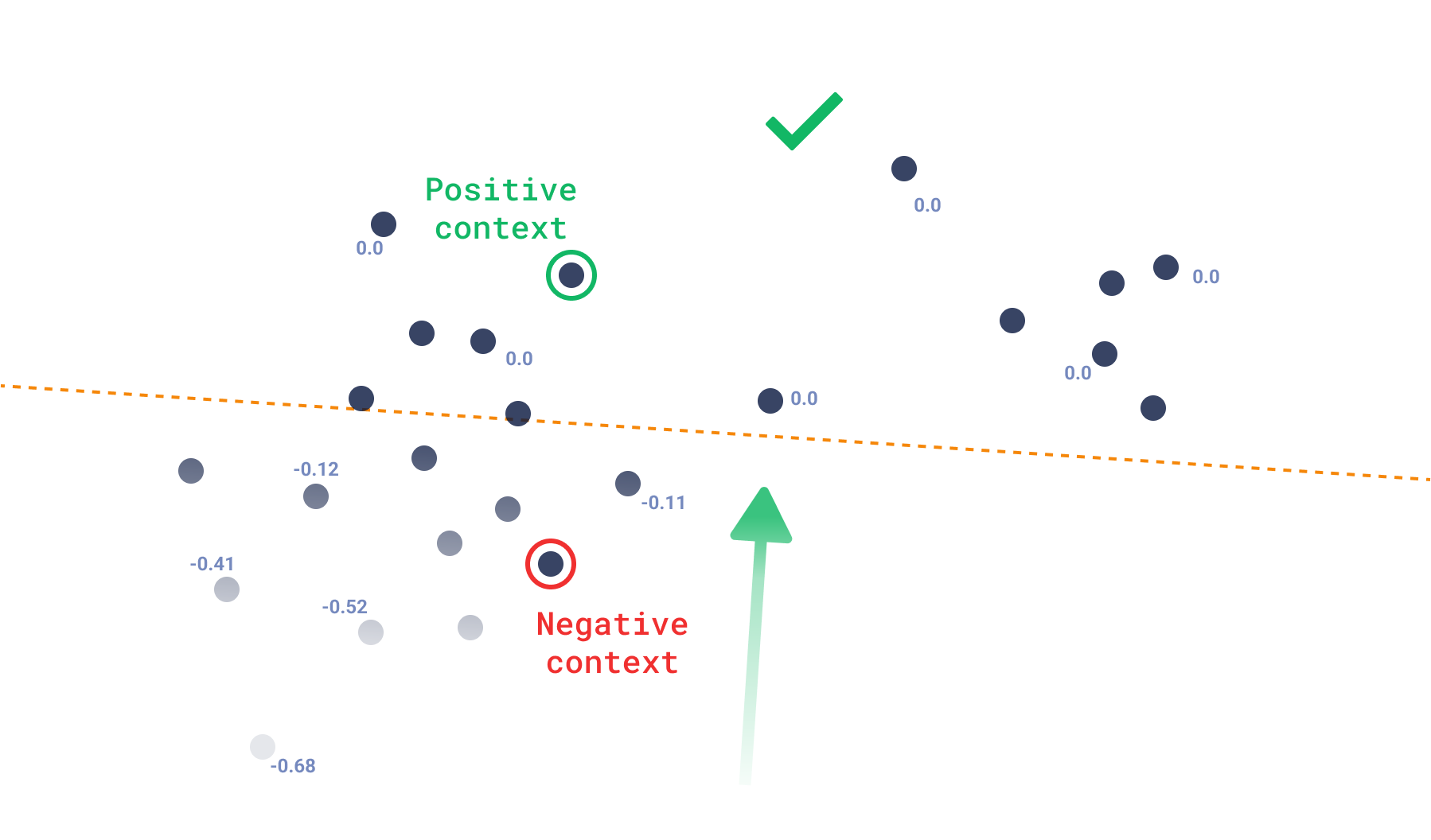
Creating complex tastes in a high-dimensional space becomes easier since you can just add more context pairs to the search. This way, you should be able to constrain the space enough so you select points from a per-search “category” created just from the context in the input.
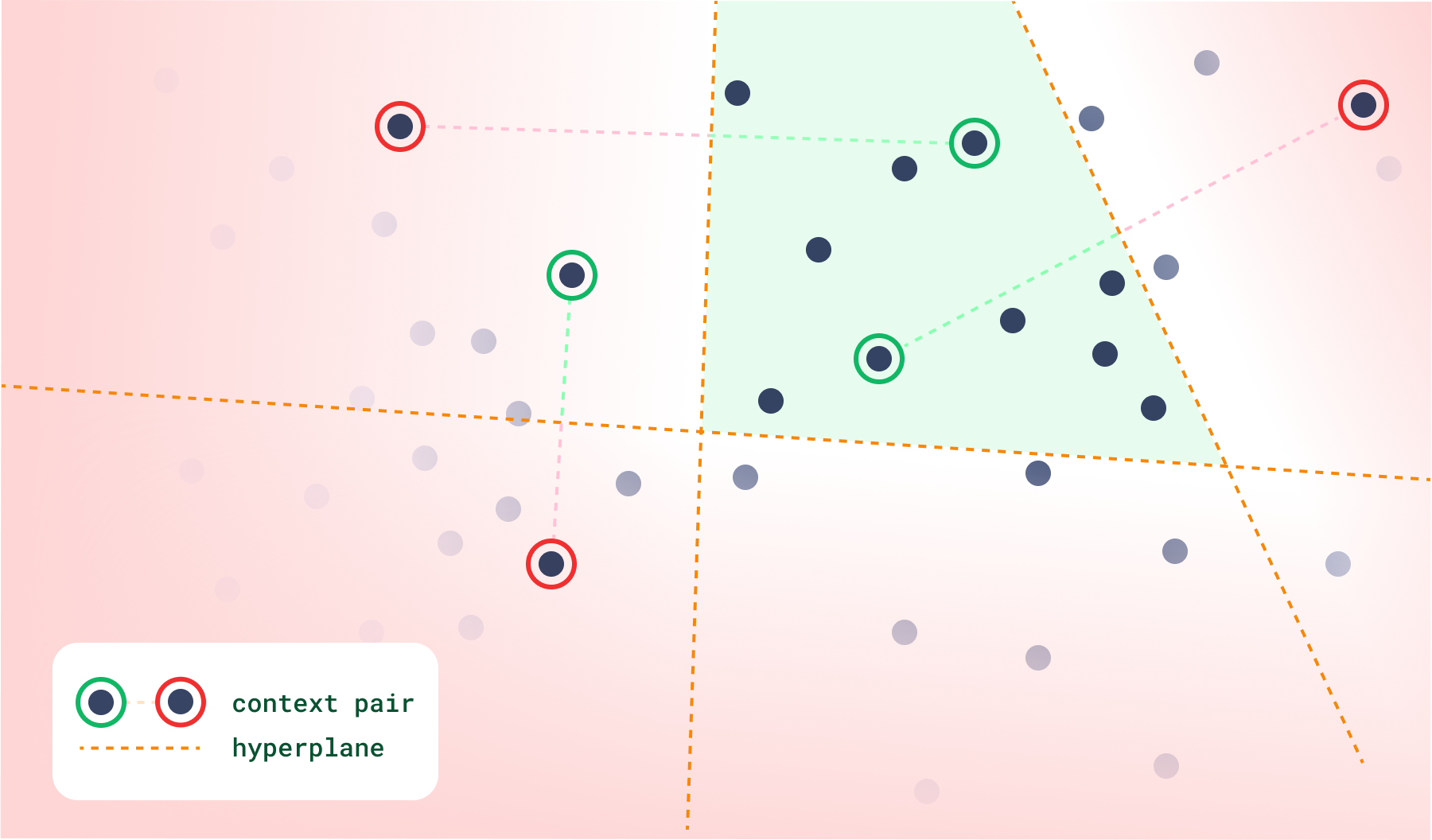
This way you can give refreshing recommendations, while still being in control by providing positive and negative feedback, or even by trying out different permutations of pairs.
Key takeaways:
- Discovery search is a powerful tool for controlled exploration in vector spaces. Context, consisting of positive and negative vectors constrain the search space, while a target guides the search.
- Real-world applications include multimodal search, diverse recommendations, and context-driven exploration.
- Ready to learn more about the math behind it and how to use it? Check out the documentation