
With Qdrant version 1.3.0 we introduce the alternative io_uring based async uring storage backend on Linux-based systems. Since its introduction, io_uring has been known to improve async throughput wherever the OS syscall overhead gets too high, which tends to occur in situations where software becomes IO bound (that is, mostly waiting on disk).
Input+Output
Around the mid-90s, the internet took off. The first servers used a process- per-request setup, which was good for serving hundreds if not thousands of concurrent request. The POSIX Input + Output (IO) was modeled in a strictly synchronous way. The overhead of starting a new process for each request made this model unsustainable. So servers started forgoing process separation, opting for the thread-per-request model. But even that ran into limitations.
I distinctly remember when someone asked the question whether a server could
serve 10k concurrent connections, which at the time exhausted the memory of
most systems (because every thread had to have its own stack and some other
metadata, which quickly filled up available memory). As a result, the
synchronous IO was replaced by asynchronous IO during the 2.5 kernel update,
either via select or epoll (the latter being Linux-only, but a small bit
more efficient, so most servers of the time used it).
However, even this crude form of asynchronous IO carries the overhead of at least one system call per operation. Each system call incurs a context switch, and while this operation is itself not that slow, the switch disturbs the caches. Today’s CPUs are much faster than memory, but if their caches start to miss data, the memory accesses required led to longer and longer wait times for the CPU.
Memory-mapped IO
Another way of dealing with file IO (which unlike network IO doesn’t have a hard time requirement) is to map parts of files into memory - the system fakes having that chunk of the file in memory, so when you read from a location there, the kernel interrupts your process to load the needed data from disk, and resumes your process once done, whereas writing to the memory will also notify the kernel. Also the kernel can prefetch data while the program is running, thus reducing the likelyhood of interrupts.
Thus there is still some overhead, but (especially in asynchronous
applications) it’s far less than with epoll. The reason this API is rarely
used in web servers is that these usually have a large variety of files to
access, unlike a database, which can map its own backing store into memory
once.
Combating the Poll-ution
There were multiple experiments to improve matters, some even going so far as moving a HTTP server into the kernel, which of course brought its own share of problems. Others like Intel added their own APIs that ignored the kernel and worked directly on the hardware.
Finally, Jens Axboe took matters into his own hands and proposed a ring buffer based interface called io_uring. The buffers are not directly for data, but for operations. User processes can setup a Submission Queue (SQ) and a Completion Queue (CQ), both of which are shared between the process and the kernel, so there’s no copying overhead.
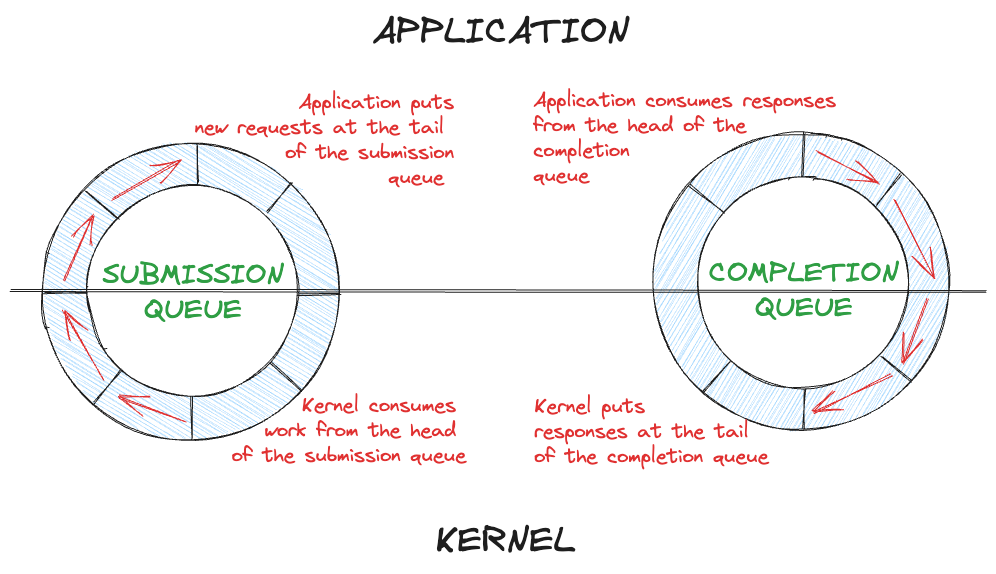
Apart from avoiding copying overhead, the queue-based architecture lends itself to multithreading as item insertion/extraction can be made lockless, and once the queues are set up, there is no further syscall that would stop any user thread.
Servers that use this can easily get to over 100k concurrent requests. Today Linux allows asynchronous IO via io_uring for network, disk and accessing other ports, e.g. for printing or recording video.
And what about Qdrant?
Qdrant can store everything in memory, but not all data sets may fit, which can require storing on disk. Before io_uring, Qdrant used mmap to do its IO. This led to some modest overhead in case of disk latency. The kernel may stop a user thread trying to access a mapped region, which incurs some context switching overhead plus the wait time until the disk IO is finished. Ultimately, this works very well with the asynchronous nature of Qdrant’s core.
One of the great optimizations Qdrant offers is quantization (either scalar or product-based). However unless the collection resides fully in memory, this optimization method generates significant disk IO, so it is a prime candidate for possible improvements.
If you run Qdrant on Linux, you can enable io_uring with the following in your configuration:
# within the storage config
storage:
performance:
# enable the async scorer which uses io_uring
async_scorer: true
or QDRANT__STORAGE__PERFORMANCE__ASYNC_SCORER=true.
You can return to the mmap based backend by either deleting the async_scorer
entry or setting the value to false.
Benchmarks
To run the benchmark, use a test instance of Qdrant. If necessary spin up a
docker container and load a snapshot of the collection you want to benchmark
with. You can copy and edit our benchmark script
to run the benchmark. Run the script with and without enabling
storage.async_scorer and once. You can measure IO usage with iostat from
another console.
For our benchmark, we chose the laion dataset picking 5 million 768d entries. We enabled scalar quantization + HNSW with m=16 and ef_construct=512. We do the quantization in RAM, HNSW in RAM but keep the original vectors on disk (which was a network drive rented from Hetzner for the benchmark).
If you want to reproduce the benchmarks, you can get snapshots containing the datasets:
Running the benchmark, we get the following IOPS, CPU loads and wall clock times:
| oversampling | parallel | ~max IOPS | CPU% (of 4 cores) | time (s) (avg of 3) | |
|---|---|---|---|---|---|
| io_uring | 1 | 4 | 4000 | 200 | 12 |
| mmap | 1 | 4 | 2000 | 93 | 43 |
| io_uring | 1 | 8 | 4000 | 200 | 12 |
| mmap | 1 | 8 | 2000 | 90 | 43 |
| io_uring | 4 | 8 | 7000 | 100 | 30 |
| mmap | 4 | 8 | 2300 | 50 | 145 |
Note that in this case, the IO operations have relatively high latency due to using a network disk. Thus, the kernel takes more time to fulfil the mmap requests, and application threads need to wait, which is reflected in the CPU percentage. On the other hand, with the io_uring backend, the application threads can better use available cores for the rescore operation without any IO-induced delays.
Oversampling is a new feature to improve accuracy at the cost of some
performance. It allows setting a factor, which is multiplied with the limit
while doing the search. The results are then re-scored using the original vector
and only then the top results up to the limit are selected.
Discussion
Looking back, disk IO used to be very serialized; re-positioning read-write heads on moving platter was a slow and messy business. So the system overhead didn’t matter as much, but nowadays with SSDs that can often even parallelize operations while offering near-perfect random access, the overhead starts to become quite visible. While memory-mapped IO gives us a fair deal in terms of ease of use and performance, we can improve on the latter in exchange for some modest complexity increase.
io_uring is still quite young, having only been introduced in 2019 with kernel 5.1, so some administrators will be wary of introducing it. Of course, as with performance, the right answer is usually “it depends”, so please review your personal risk profile and act accordingly.
Best Practices
If your on-disk collection’s query performance is of sufficiently high priority to you, enable the io_uring-based async_scorer to greatly reduce operating system overhead from disk IO. On the other hand, if your collections are in memory only, activating it will be ineffective. Also note that many queries are not IO bound, so the overhead may or may not become measurable in your workload. Finally, on-device disks typically carry lower latency than network drives, which may also affect mmap overhead.
Therefore before you roll out io_uring, perform the above or a similar benchmark with both mmap and io_uring and measure both wall time and IOps). Benchmarks are always highly use-case dependent, so your mileage may vary. Still, doing that benchmark once is a small price for the possible performance wins. Also please tell us about your benchmark results!