Using LangChain for Question Answering with Qdrant
Kacper Łukawski
·January 31, 2023

Streamlining Question Answering: Simplifying Integration with LangChain and Qdrant
Building applications with Large Language Models doesn’t have to be complicated. A lot has been going on recently to simplify the development, so you can utilize already pre-trained models and support even complex pipelines with a few lines of code. LangChain provides unified interfaces to different libraries, so you can avoid writing boilerplate code and focus on the value you want to bring.
Why Use Qdrant for Question Answering with LangChain?
It has been reported millions of times recently, but let’s say that again. ChatGPT-like models struggle with generating factual statements if no context
is provided. They have some general knowledge but cannot guarantee to produce a valid answer consistently. Thus, it is better to provide some facts we
know are actual, so it can just choose the valid parts and extract them from all the provided contextual data to give a comprehensive answer. Vector database,
such as Qdrant, is of great help here, as their ability to perform a semantic search over a huge knowledge base is crucial to preselect some possibly valid
documents, so they can be provided into the LLM. That’s also one of the chains implemented in LangChain, which is called VectorDBQA. And Qdrant got
integrated with the library, so it might be used to build it effortlessly.
The Two-Model Approach
Surprisingly enough, there will be two models required to set things up. First of all, we need an embedding model that will convert the set of facts into
vectors, and store those into Qdrant. That’s an identical process to any other semantic search application. We’re going to use one of the
SentenceTransformers models, so it can be hosted locally. The embeddings created by that model will be put into Qdrant and used to retrieve the most
similar documents, given the query.
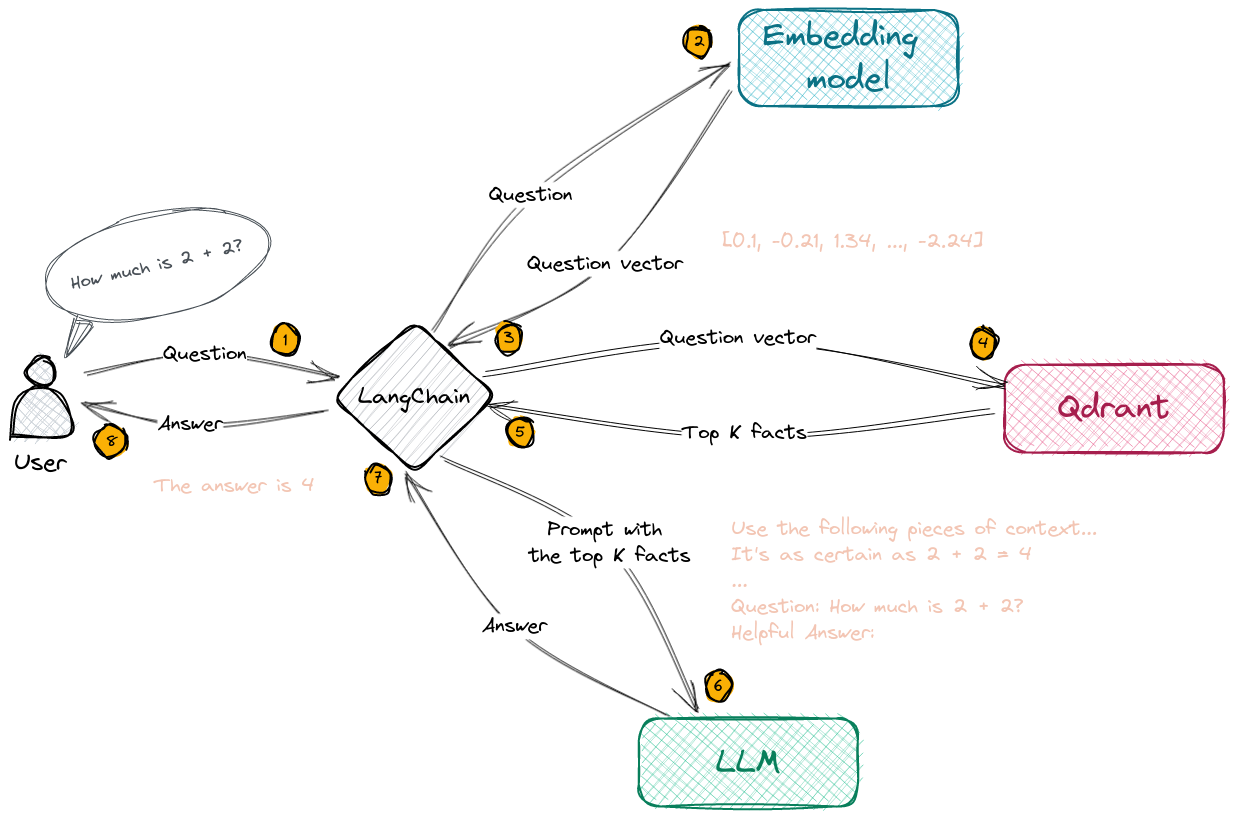
However, when we receive a query, there are two steps involved. First of all, we ask Qdrant to provide the most relevant documents and simply combine all of them into a single text. Then, we build a prompt to the LLM (in our case OpenAI), including those documents as a context, of course together with the question asked. So the input to the LLM looks like the following:
Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
It's as certain as 2 + 2 = 4
...
Question: How much is 2 + 2?
Helpful Answer:
There might be several context documents combined, and it is solely up to LLM to choose the right piece of content. But our expectation is, the model should
respond with just 4.
Why do we need two different models?
Both solve some different tasks. The first model performs feature extraction, by converting the text into vectors, while
the second one helps in text generation or summarization. Disclaimer: This is not the only way to solve that task with LangChain. Such a chain is called stuff
in the library nomenclature.
Enough theory! This sounds like a pretty complex application, as it involves several systems. But with LangChain, it might be implemented in just a few lines
of code, thanks to the recent integration with Qdrant. We’re not even going to work directly with QdrantClient, as everything is already done in the background
by LangChain. If you want to get into the source code right away, all the processing is available as a
Google Colab notebook.
How to Implement Question Answering with LangChain and Qdrant
Step 1: Configuration
A journey of a thousand miles begins with a single step, in our case with the configuration of all the services. We’ll be using Qdrant Cloud, so we need an API key. The same is for OpenAI - the API key has to be obtained from their website.

Step 2: Building the knowledge base
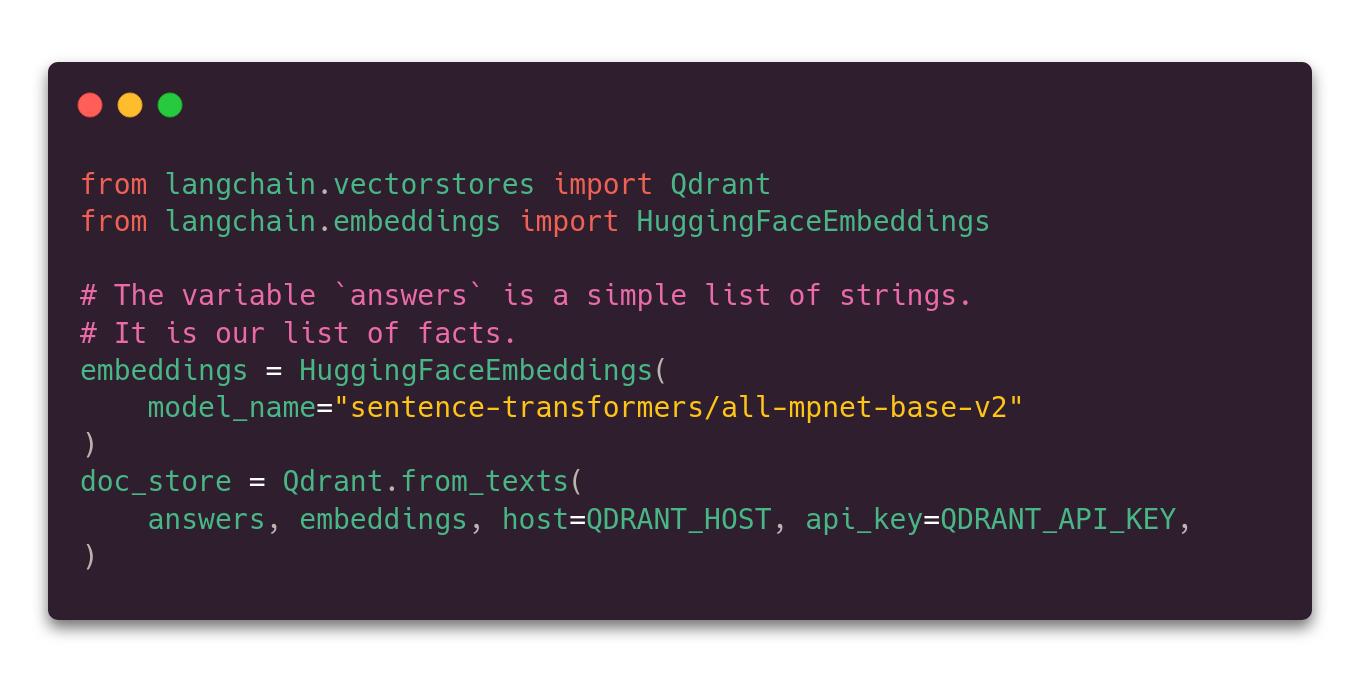
We also need some facts from which the answers will be generated. There is plenty of public datasets available, and Natural Questions is one of them. It consists of the whole HTML content of the websites they were scraped from. That means we need some preprocessing to extract plain text content. As a result, we’re going to have two lists of strings - one for questions and the other one for the answers.
The answers have to be vectorized with the first of our models. The sentence-transformers/all-mpnet-base-v2 is one of the possibilities, but there are some
other options available. LangChain will handle that part of the process in a single function call.
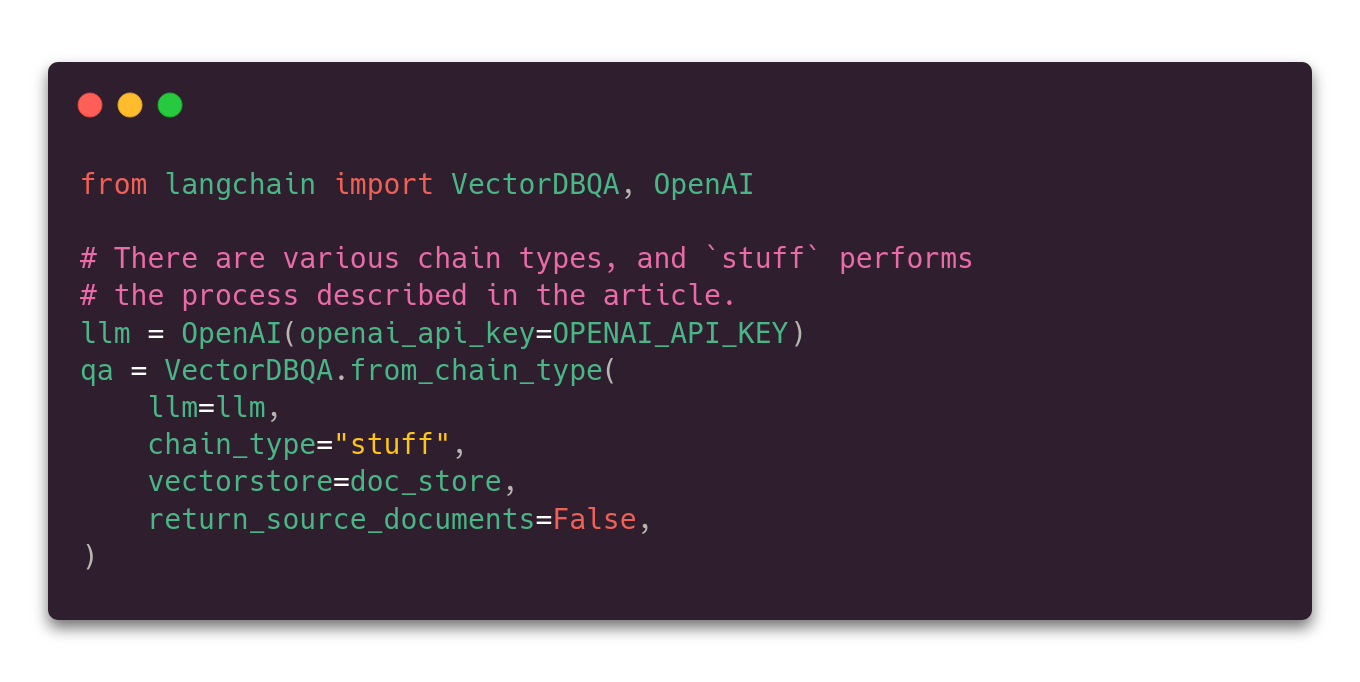
Step 3: Setting up QA with Qdrant in a loop
VectorDBQA is a chain that performs the process described above. So it, first of all, loads some facts from Qdrant and then feeds them into OpenAI LLM which
should analyze them to find the answer to a given question. The only last thing to do before using it is to put things together, also with a single function call.
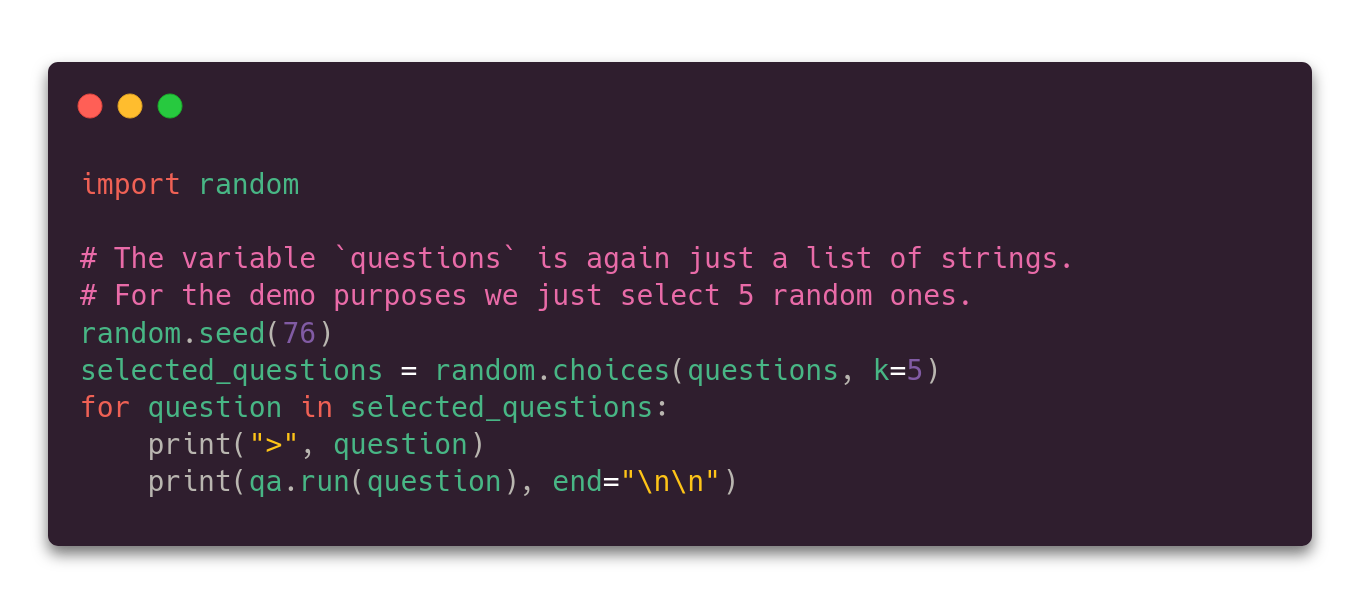
Step 4: Testing out the chain
And that’s it! We can put some queries, and LangChain will perform all the required processing to find the answer in the provided context.
> what kind of music is scott joplin most famous for
Scott Joplin is most famous for composing ragtime music.
> who died from the band faith no more
Chuck Mosley
> when does maggie come on grey's anatomy
Maggie first appears in season 10, episode 1, which aired on September 26, 2013.
> can't take my eyes off you lyrics meaning
I don't know.
> who lasted the longest on alone season 2
David McIntyre lasted the longest on Alone season 2, with a total of 66 days.
The great thing about such a setup is that the knowledge base might be easily extended with some new facts and those will be included in the prompts sent to LLM later on. Of course, assuming their similarity to the given question will be in the top results returned by Qdrant.
If you want to run the chain on your own, the simplest way to reproduce it is to open the Google Colab notebook.