
A brand-new Qdrant 1.2 release comes packed with a plethora of new features, some of which were highly requested by our users. If you want to shape the development of the Qdrant vector database, please join our Discord community and let us know how you use it!
New features
As usual, a minor version update of Qdrant brings some interesting new features. We love to see your feedback, and we tried to include the features most requested by our community.
Product Quantization
The primary focus of Qdrant was always performance. That’s why we built it in Rust, but we were always concerned about making vector search affordable. From the very beginning, Qdrant offered support for disk-stored collections, as storage space is way cheaper than memory. That’s also why we have introduced the Scalar Quantization mechanism recently, which makes it possible to reduce the memory requirements by up to four times.
Today, we are bringing a new quantization mechanism to life. A separate article on Product Quantization will describe that feature in more detail. In a nutshell, you can reduce the memory requirements by up to 64 times!
Optional named vectors
Qdrant has been supporting multiple named vectors per point for quite a long time. Those may have utterly different dimensionality and distance functions used to calculate similarity. Having multiple embeddings per item is an essential real-world scenario. For example, you might be encoding textual and visual data using different models. Or you might be experimenting with different models but don’t want to make your payloads redundant by keeping them in separate collections.
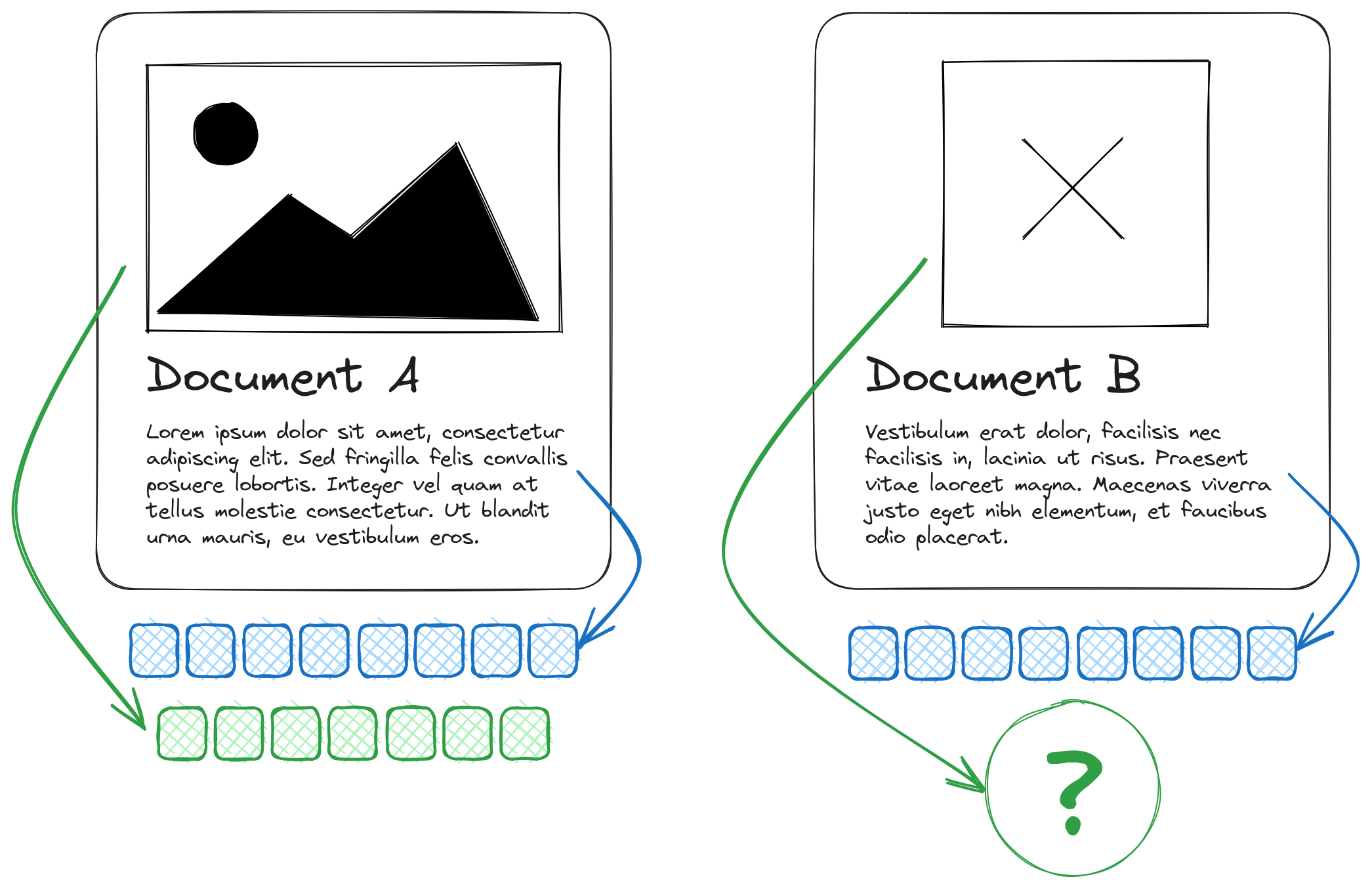
However, up to the previous version, we requested that you provide all the vectors for each point. There have been many requests to allow nullable vectors, as sometimes you cannot generate an embedding or simply don’t want to for reasons we don’t need to know.
Grouping requests
Embeddings are great for capturing the semantics of the documents, but we rarely encode larger pieces of data into a single vector. Having a summary of a book may sound attractive, but in reality, we divide it into paragraphs or some different parts to have higher granularity. That pays off when we perform the semantic search, as we can return the relevant pieces only. That’s also how modern tools like Langchain process the data. The typical way is to encode some smaller parts of the document and keep the document id as a payload attribute.
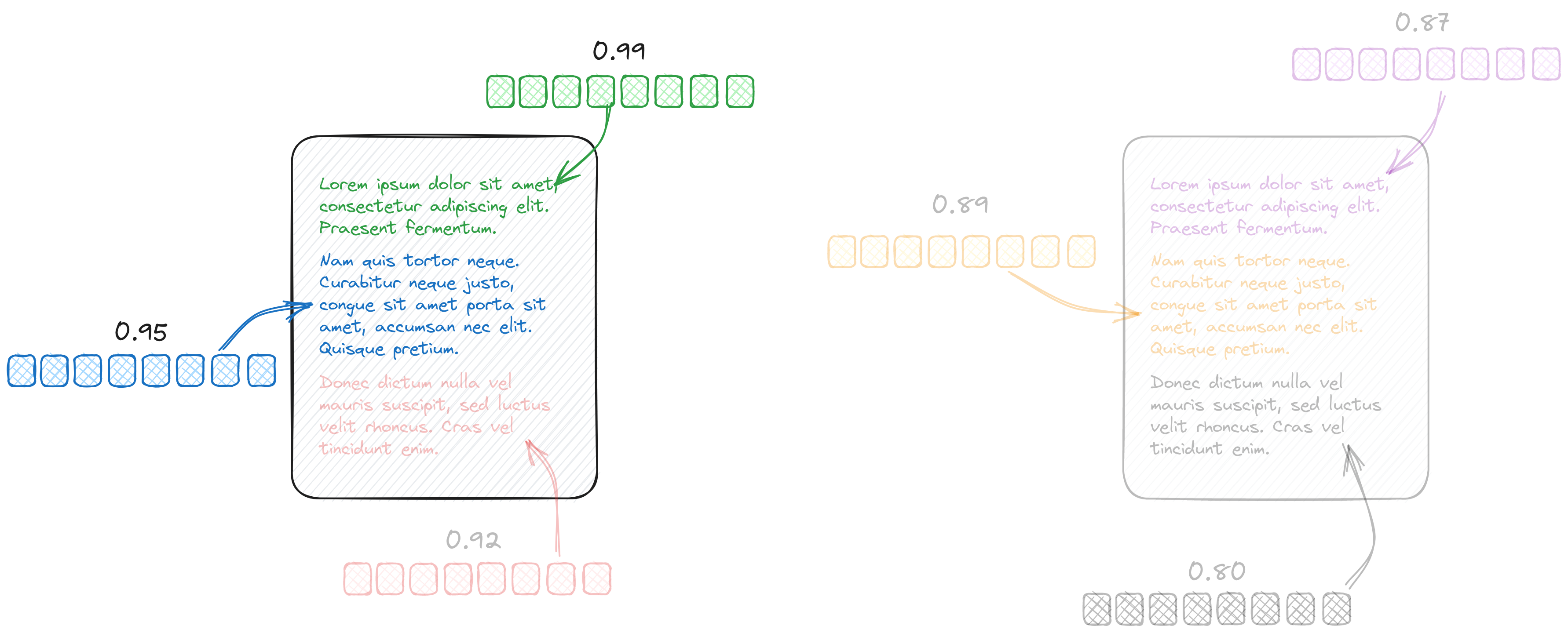
There are cases where we want to find relevant parts, but only up to a specific number of results
per document (for example, only a single one). Up till now, we had to implement such a mechanism
on the client side and send several calls to the Qdrant engine. But that’s no longer the case.
Qdrant 1.2 provides a mechanism for grouping requests, which
can handle that server-side, within a single call to the database. This mechanism is similar to the
SQL GROUP BY clause.
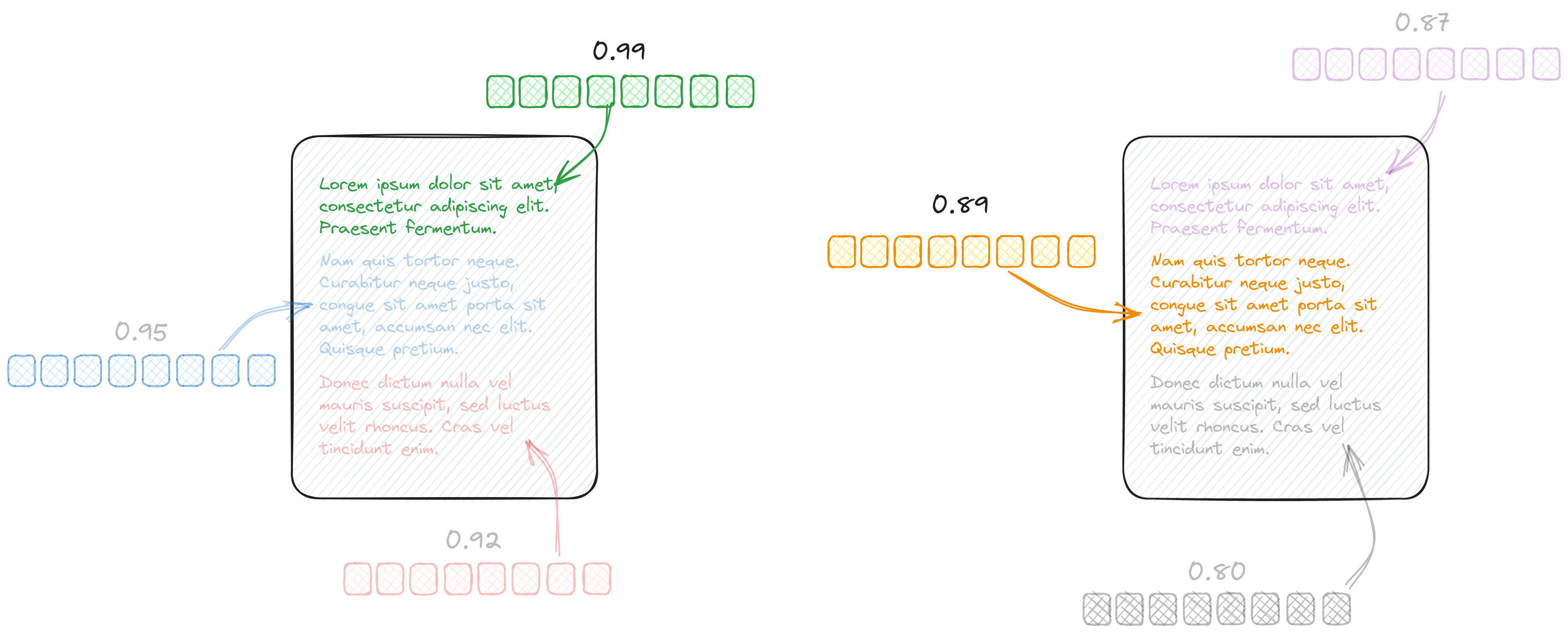
You are not limited to a single result per document, and you can select how many entries will be returned.
Nested filters
Unlike some other vector databases, Qdrant accepts any arbitrary JSON payload, including
arrays, objects, and arrays of objects. You can also filter the search results using nested
keys, even though arrays (using the [] syntax).
Before Qdrant 1.2 it was impossible to express some more complex conditions for the nested structures. For example, let’s assume we have the following payload:
{
"country": "Japan",
"cities": [
{
"name": "Tokyo",
"population": 9.3,
"area": 2194
},
{
"name": "Osaka",
"population": 2.7,
"area": 223
},
{
"name": "Kyoto",
"population": 1.5,
"area": 827.8
}
]
}
We want to filter out the results to include the countries with a city with over 2 million citizens and an area bigger than 500 square kilometers but no more than 1000. There is no such a city in Japan, looking at our data, but if we wrote the following filter, it would be returned:
{
"filter": {
"must": [
{
"key": "country.cities[].population",
"range": {
"gte": 2
}
},
{
"key": "country.cities[].area",
"range": {
"gt": 500,
"lte": 1000
}
}
]
},
"limit": 3
}
Japan would be returned because Tokyo and Osaka match the first criteria, while Kyoto fulfills the second. But that’s not what we wanted to achieve. That’s the motivation behind introducing a new type of nested filter.
{
"filter": {
"must": [
{
"nested": {
"key": "country.cities",
"filter": {
"must": [
{
"key": "population",
"range": {
"gte": 2
}
},
{
"key": "area",
"range": {
"gt": 500,
"lte": 1000
}
}
]
}
}
}
]
},
"limit": 3
}
The syntax is consistent with all the other supported filters and enables new possibilities. In our case, it allows us to express the joined condition on a nested structure and make the results list empty but correct.
Important changes
The latest release focuses not only on the new features but also introduces some changes making Qdrant even more reliable.
Recovery mode
There has been an issue in memory-constrained environments, such as cloud, happening when users were
pushing massive amounts of data into the service using wait=false. This data influx resulted in an
overreaching of disk or RAM limits before the Write-Ahead Logging (WAL) was fully applied. This
situation was causing Qdrant to attempt a restart and reapplication of WAL, failing recurrently due
to the same memory constraints and pushing the service into a frustrating crash loop with many
Out-of-Memory errors.
Qdrant 1.2 enters recovery mode, if enabled, when it detects a failure on startup. That makes the service halt the loading of collection data and commence operations in a partial state. This state allows for removing collections but doesn’t support search or update functions. Recovery mode has to be enabled by user.
Appendable mmap
For a long time, segments using mmap storage were non-appendable and could only be constructed by
the optimizer. Dynamically adding vectors to the mmap file is fairly complicated and thus not
implemented in Qdrant, but we did our best to implement it in the recent release. If you want
to read more about segments, check out our docs on vector storage.
Security
There are two major changes in terms of security:
- API-key support - basic authentication with a static API key to prevent unwanted access. Previously API keys were only supported in Qdrant Cloud.
- TLS support - to use encrypted connections and prevent sniffing/MitM attacks.
Release notes
As usual, our release notes describe all the changes introduced in the latest version.