
A year ago, we dropped a statement-bomb in the “Relevance Feedback in Information Retrieval” article and then went silent.
We claimed that even though the information retrieval research field has proposed many useful mechanisms for increasing the relevance of search results, none of them made it to the neural search industry, simply because these approaches are not scalable.
Certainly, there are methods widely used to improve the relevance of retrieved results: query rewriting, for example. Yet none of the vector search solutions out there have tried to use the possibilities that come with full access to the vector search index: traversing it in the direction of relevance, instead of guessing where to shoot the query to the vector space.
To break this vector-search-native tools silence, we’re introducing Relevance Feedback Query, a universal, cheap and scalable method for improving the relevance recall of your search results.
Vector Search Optimization
In vector search, like in any field, you’re always trading off speed, cost, and quality on the way to production. Everyone needs instruments to tune that balance for their use case, like vector quantization to lower costs or reranking to increase relevance.
For those instruments to work (and to stick in industry), they have to be universal, native to the stack, and reasonable.
“Reasonable” means optimizing one side of the speed–cost–quality triangle without tanking the other two.
At scale, neural search is usually limited to fairly simple dense encoders (embeddings up to a few thousand dimensions), as running large models to sift through billions of data points is, well, unreasonable.
So most search quality-boosting tools aim to adjust/align/guide these simple retrievers. The guidance can come from the search end-user or a domain expert: rescoring via business-logic-based rules, reranking with a learned-to-rank model, and using relevance feedback mechanisms.
What is Relevance Feedback
Relevance feedback distills signals from current search results into the next retrieval iteration to surface more relevant documents.
It can be provided by a human or a model, be binary (relevant–irrelevant) or granular, rescoring top documents by their relative relevance to the query.
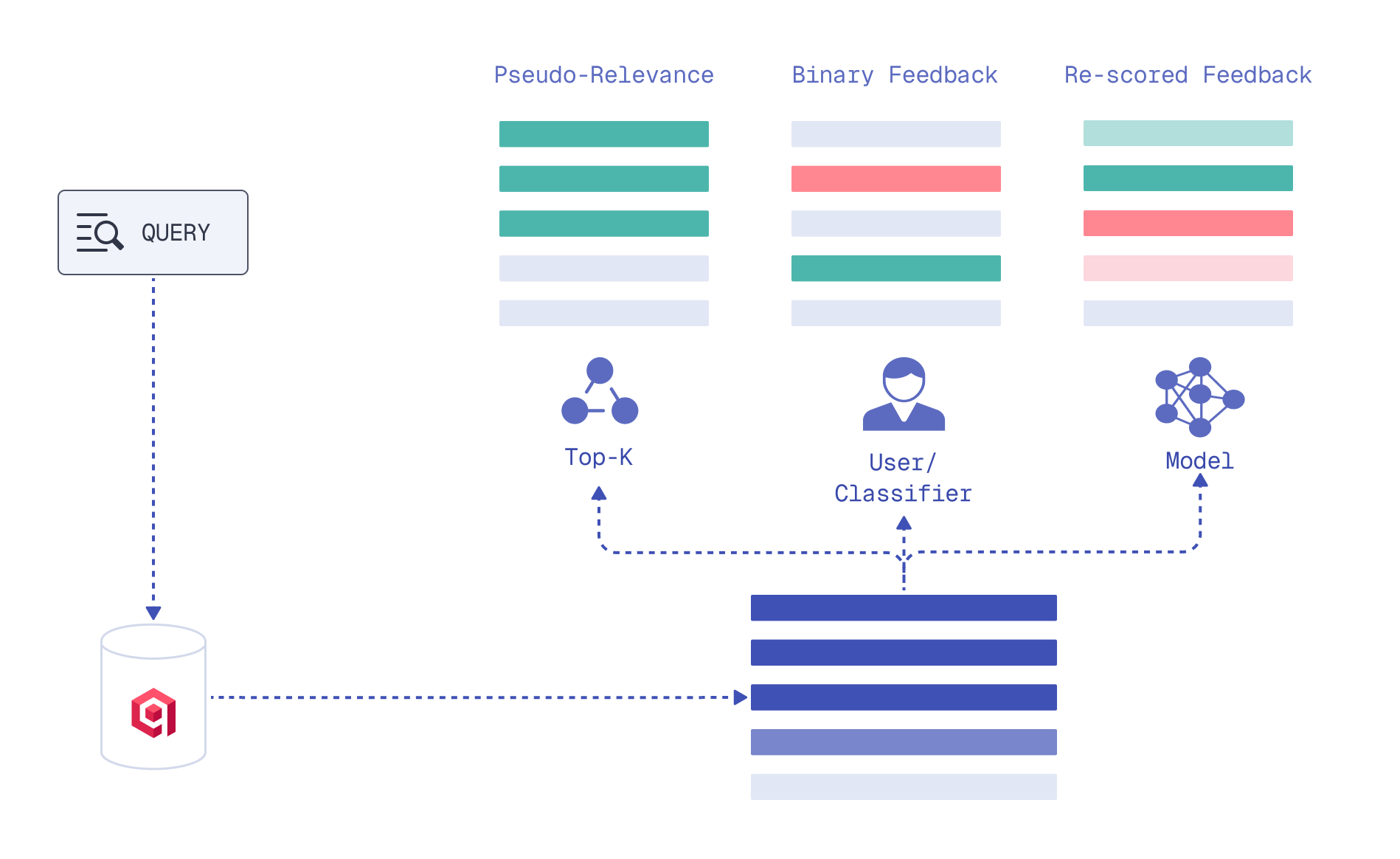
Feedback types
Based on this feedback, one of the retrieval components is adjusted: the query or the scoring method between the query and documents. The next retrieval iteration is done with this aligned component.
For a detailed taxonomy with various methods from the field, check out our article “Relevance Feedback in Information Retrieval”.
Relevance-feedback-based methods are a standard in full-text search, some of them proposed more than 50 years ago.
Yet it feels like, when it comes to modern vector search, users have to reinvent the relevance feedback wheel due to the lack of universal interfaces: prompt a search agent to rewrite queries in endless, costly loops, do heuristics-based vector math and fine-tune models per request on the client side… Simply put, they have to struggle.
Tools of a Vector Search Engine
The goal is to fill this gap and let search end-users (doesn’t matter if humans or agents) get a proper relevance feedback interface to use in our vector search engine.
So what makes a method a production-ready for vector search?
…Should Be Cheap
Since additional retrieval iterations already add to the search latency, we can’t afford to spend too much time or money on gathering feedback. That means:
Very few documents for feedback
The set of documents we pass to a feedback model should be extremely small. It is rarely affordable to run an LLM, use a cross encoder, or fine tune a machine learning model on hundreds of documents per request.
A feedback model here is anything – agent, ML model, formula, … – that’s capable of providing (numerical) information on how relevant the retrieved document is to the query.
We should already improve recall of the next retrieval iteration with that small sample. We can’t afford having the whole dataset as a feedback context for an agent.
Automated
You might have noticed that we wrote “a feedback model”. Humans are known to be the laziest at providing feedback, so the search feedback loop must run on its own.
No labeling required
Models which require many labels or domain expert input are hard to adopt. The feedback tool should be easy to train, and data – self-supervised.
…Should Be Universal
For every type of data
Vector search is attractive because it is agnostic to the data type: images, video, audio, molecules… Not only text. Vector search native tools should be the same, operating on vectors without minding their nature. That is why query rewriting as reformulating text won’t suffice.
For every type of signal
Some relevance feedback methods depend on clean feedback signals: strictly relevant or irrelevant documents.
In real life, especially when we need relevance boosting, results returned to a request could be, for example, meh and more meh. Ideally, the method should be able to use the noisy signals.
Our Idea
Usually neither LLMs nor subject matter experts providing feedback know the dataset’s exact shape or the vector space it spans. For that they would need to process a large subset of stored vectors.
What they can do is help define a relevance direction from the examples they have seen. A retriever could then use these direction hints on the next retrieval iteration.
Relevance Direction

Imagine a hiker lost in a forest with a weak phone signal. They still manage to send a couple of quick photos to a friend who knows orienteering.
The friend does not have a map of the whole forest or a live view of every tree. Still, they try to help and reply:
- “Better go away from anything looking like this plant. It might signal that a swamp is near.”
- “I see moss on this tree. Moss grows on the north side. If you keep north you might find a way out.”
Now the hiker has extra knowledge to choose a path, comparing the landscape around them to the photos and applying the direction hints from their experienced friend.
Read this as vector search.
- The forest is a vector space.
- The hiker is a retriever model.
- The brilliant friend is a feedback model.
- The photos are the hiker’s context, limited to the amount that is affordable to use for feedback.
And the hiker’s new “where-should-I-go” decisions based on the acquired information are feedback-based (forest path) scoring.
Using Entire Vector Space
So the idea is to use feedback to define a more relevant direction (closer to this, further from that) within the vector space spanned by the dataset.
That implies warping the notion of “closer” and “further”, the distance (or similarity) scoring metric used during the retrieval.
Tweaking the relevance scoring formula based on the feedback model’s signal is nothing revolutionary. What changes is that this feedback-based scoring is used during the traversal of the entire dataset used by the vector search engine, not just a subset of results.
Sketch of the Method
So, stepping away from analogies (into an even deeper forest), the algorithm should consist of:
Initial retrieval.
Getting a small amount of feedback (within the context limit) on the results of this initial retrieval.
A context limit is how many top documents from the initial retrieval the feedback model scores. We want to keep it as small as possible to save time and resources.
A good choice for feedback format is granular judgments, aka pointwise relevance scores, between the query and the retrieved documents. They are more helpful when the retrieved documents are not strictly relevant or irrelevant.
Extracting relevance signals from this feedback and propagating them into a new similarity (distance) scoring formula.
Using this new feedback-based similarity scoring formula in the next retrieval iteration on the whole dataset of documents to traverse the vector index in the direction of more relevance. Simply put, we’re no longer using cosine to score similarities, but rather a formula adjusted for feedback.
Dissecting Feedback
Let’s talk about how a very small amount of feedback can be used most effectively, what relevance signals we can extract from it, and how exactly.
Context Pairs
If we show only one document to the feedback model, it is hard for it to say whether it is already a good match. Perhaps there are no relevant matches in the dataset at all.
With two documents, this model could already judge which one is closer to what the user expects. Feedback then could be a context pair of (more) positive and (more) negative examples-documents.
A context pair (positive, negative) is two documents from the top context limit results of the initial retrieval. The positive received a higher relevance-to-query score from the feedback model, and the negative received a lower score.
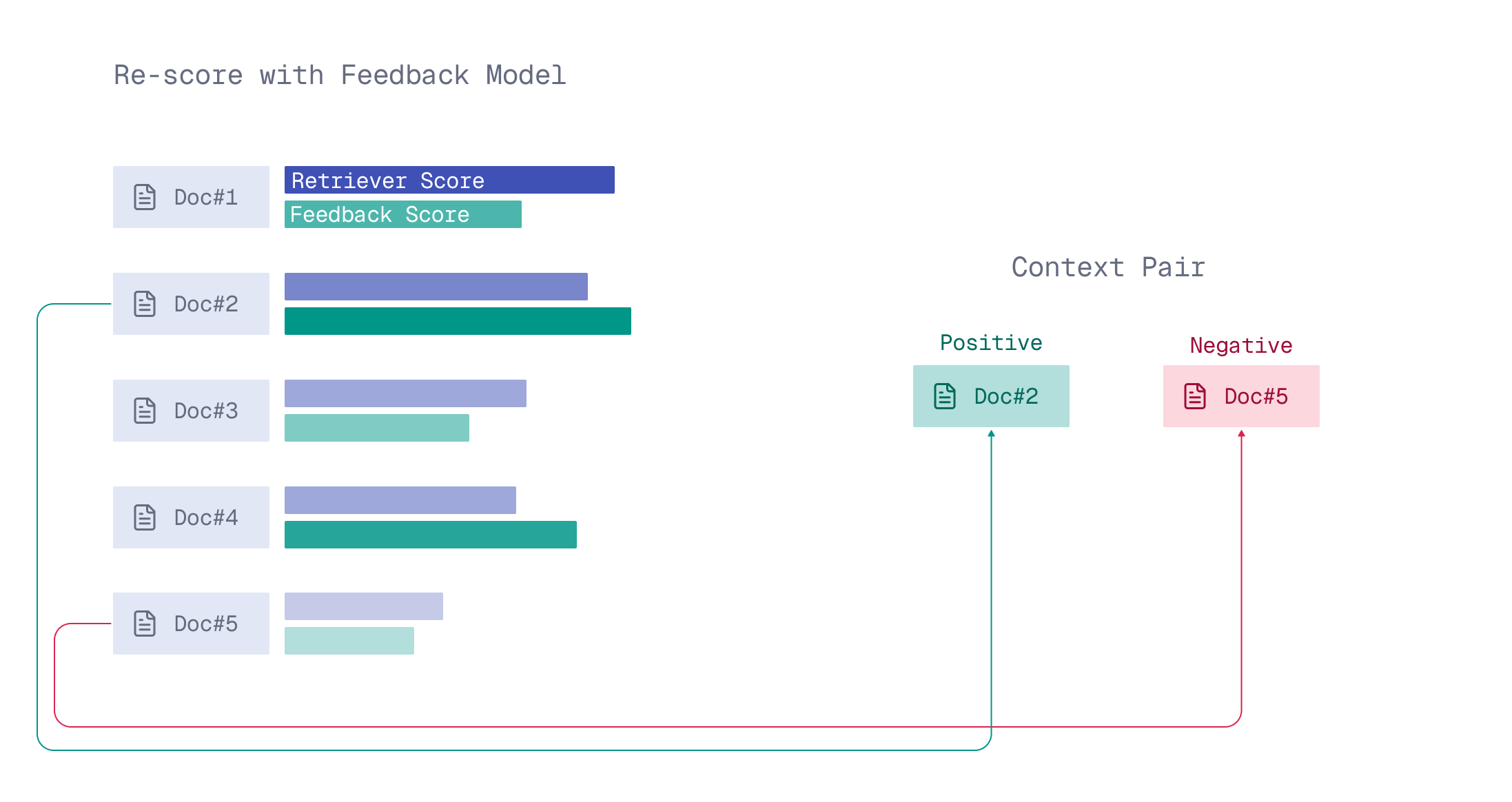
How context pairs are formed
Context Pair’s Confidence
Two documents nearly indistinguishable from the perspective of a feedback model give far less information than a context pair with one clearly more relevant document.
When documents in the context pair seem different to the feedback model, it is more confident in guiding the retriever.
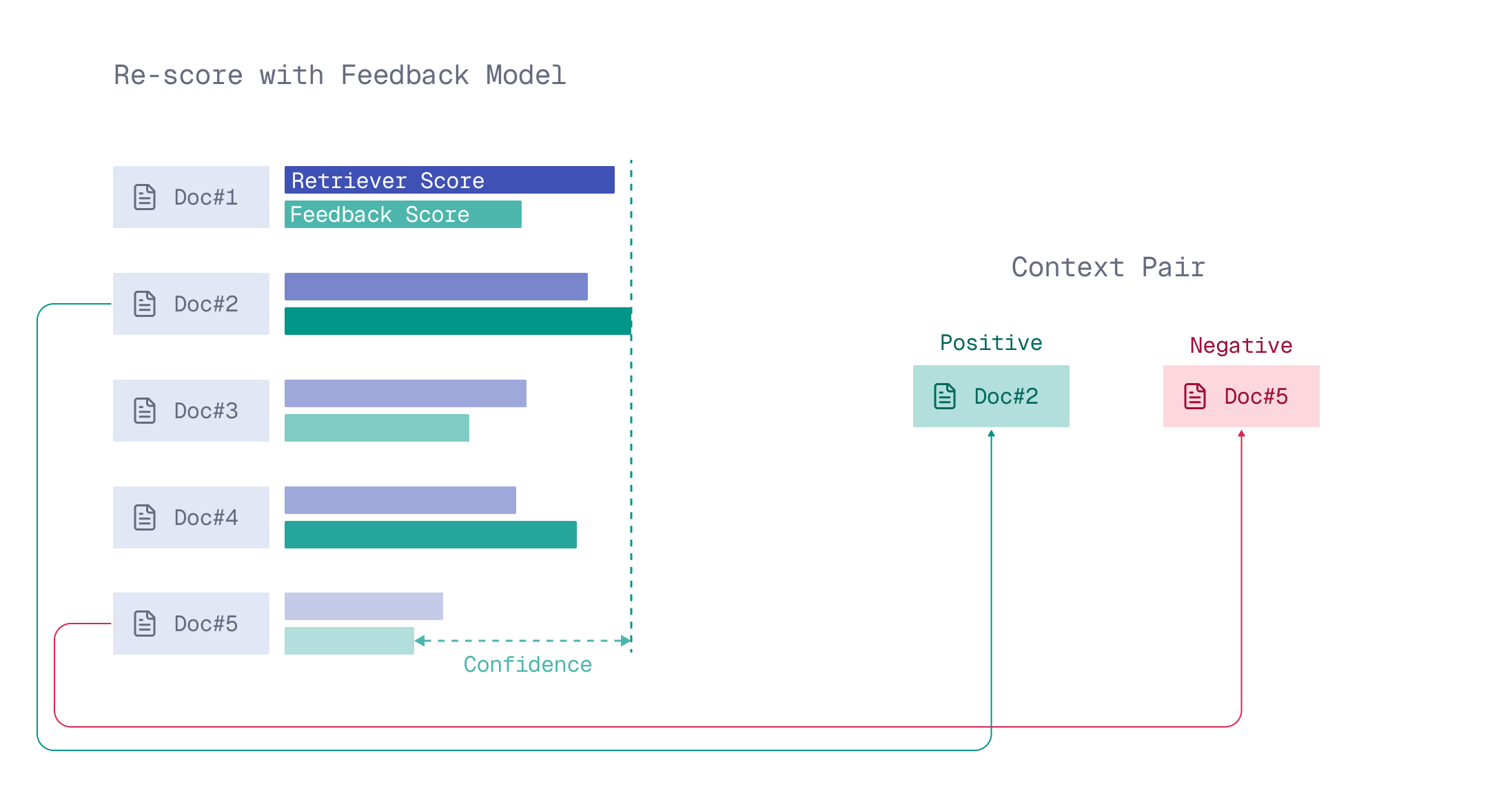
Context pair’s confidence
Direction’s Delta
Then, if the retriever favors a document closer to the negative example by some delta, the retriever should most probably adjust its search direction in the vector space.
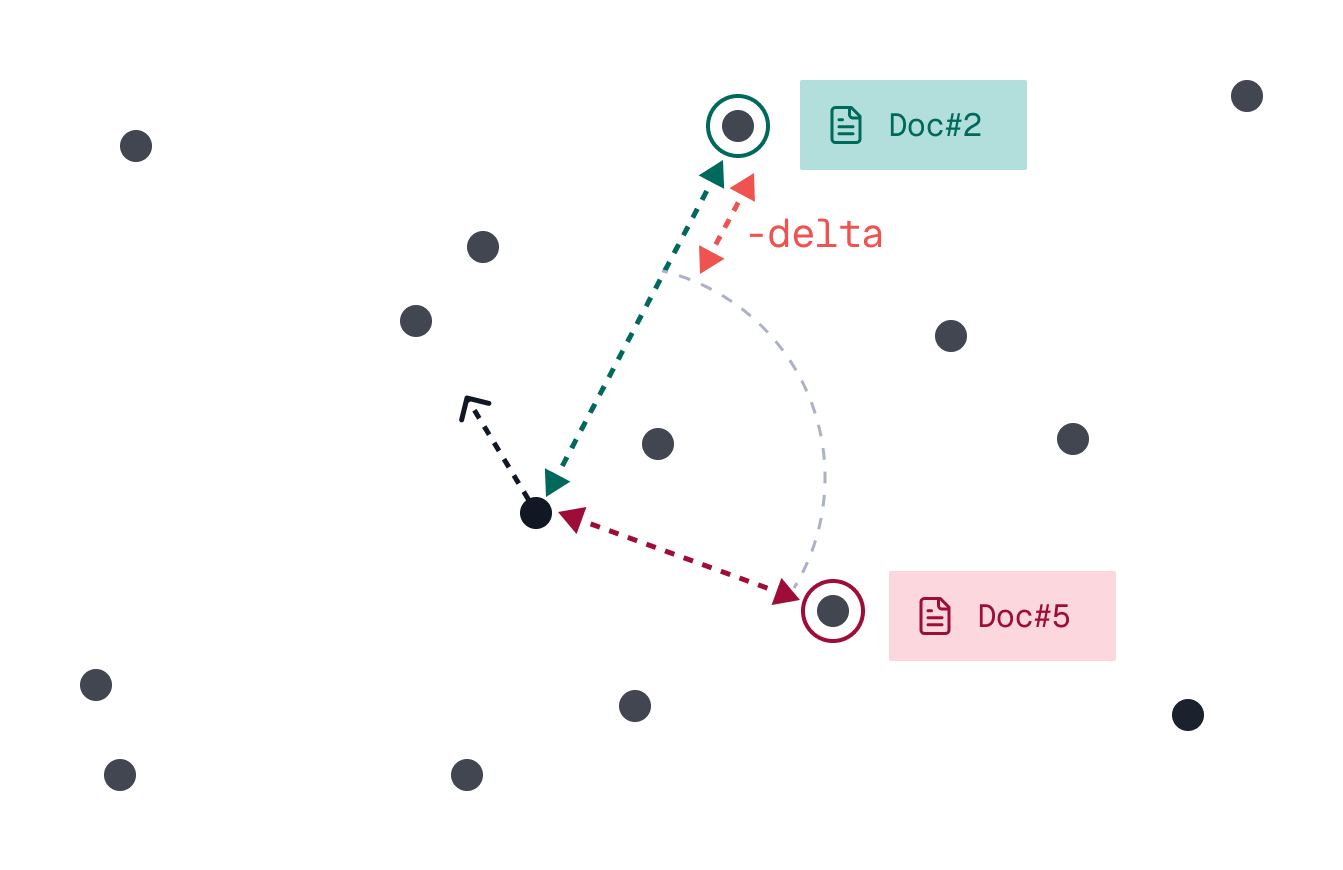
The point in vector space is closer (more similar) to the negative element of a context pair by a delta.
Feedback-Based Scoring
With the context pair(s) at our expense, we can try the following feedback-based scoring during retrieval:
- Let the retriever still have a say in what is relevant to the query, count in its score (to query).
- Yet reward candidates that are closer to the positive element of the context pair based on delta.
- Especially when the feedback model had high confidence in this pair.
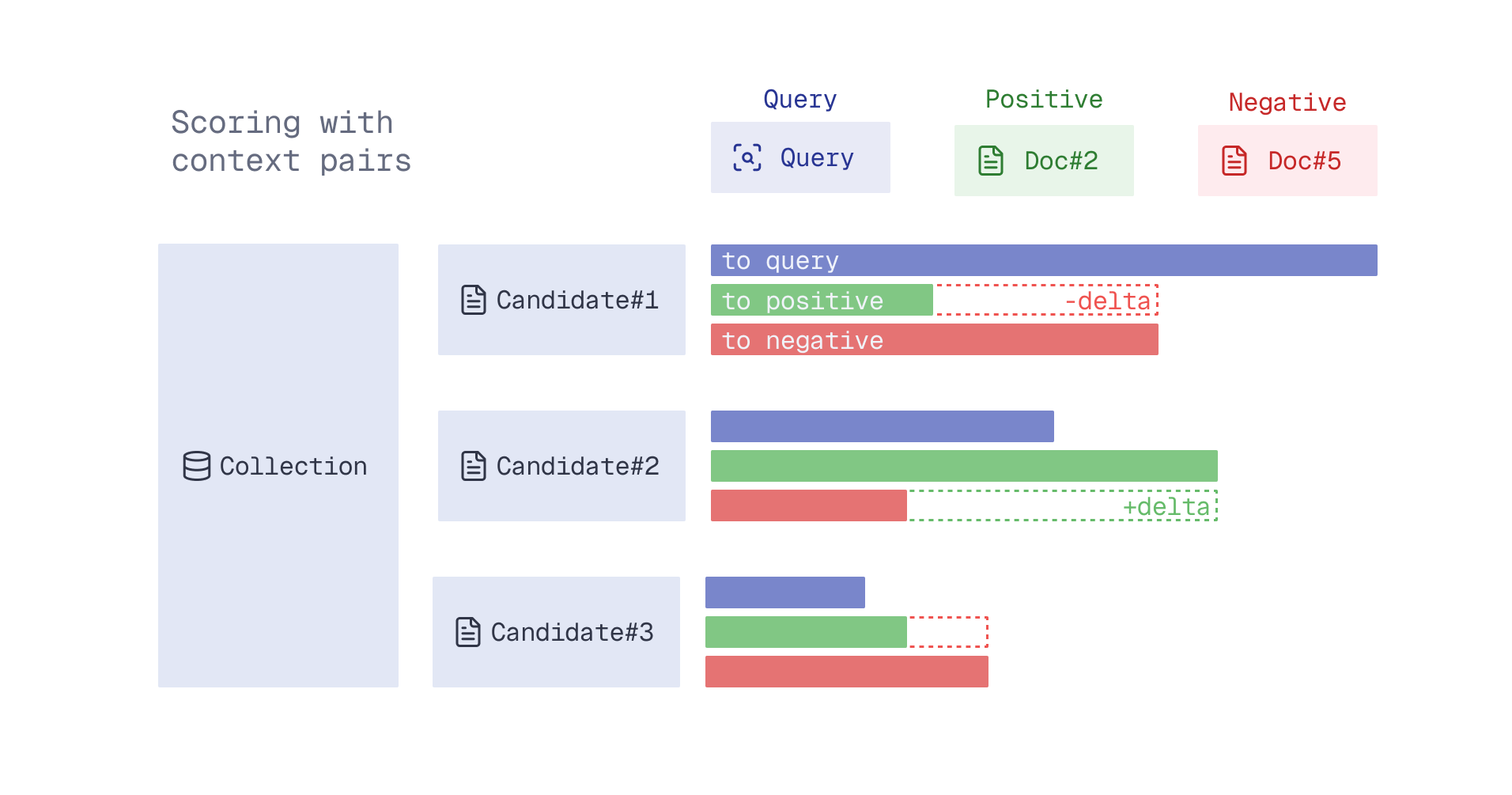
Feedback-based scoring using candidate’s similarity to the query and the context pair.
So, we need to combine signals (score, delta, confidence) in a reasonable, simple scoring formula with a few parameters.
Usually what helps in coming up with a reasonable formula is looking at edge cases.
The Math of Edge Cases
Direction’s delta is zero
If the retriever sees the positive and the negative documents (from the context pair) as equally similar to the candidate document, there’s no direction-establishing signal.
Context pair’s confidence is zero.
If, from the feedback model’s perspective, both documents in a context pair are identical to the query, there’s, once again, no information on direction of relevance.
In both cases the final formula should rely on the retriever’s judgment, as opposed to a situation where feedback signals are strong.
Naive Formula
One of the options to express this behavior is through a weighted sum of signals, ensuring confidence and delta don’t collapse into a single joint term by exponentiating one of them.
Applying the math of edge cases, we came up with this three-parameter (a, b and c) formula.
It computes the score between the query and a candidate document on the retrieval-with-relevance-feedback iteration.
As you see, the amount of context pairs used in the scoring formula can be more than one but one is also an option.
Is this formula set in stone? Absolutely not! We tried three others in experiments, and this one was the simplest that worked. In future releases we plan to allow providing custom formulas.
What Goes Into It
| What does it mean? | A similarity score between the query and the candidate embedding generated by the retriever model. F.e., cosine similarity. |
| When is it calculated? | On the second step of retrieval, during search for more relevant candidates in the vector space. |
| Example | If |
| What does it mean? | A difference in relevance to the query for the two documents forming a context pair, as scored by the feedback model. |
| When is it calculated? | At the moment feedback is collected, right after the initial retrieval. |
| Example | We have A feedback model scores them |
| What does it mean? | The difference between the candidate’s similarity (e.g., cosine) to the positive document and to the negative document from the context pair. All the similarity scores are calculated on embeddings generated by the retriever. |
| When is it calculated? | On the second step of retrieval, during search for more relevant candidates in the vector space. |
| Example | Given the context pair ( If |
Now the question is: Where do we take a, b, and c from?
We’ll need to obtain formula parameters (a, b and c) through some simple training process, because score, confidence, and delta value distributions will likely vary by dataset, retriever, and feedback model.
Training Objective
With the right a, b and c, adjusted to dataset, retriever and feedback scores distribution, the naive formula should rank documents better than our simple retriever.
That leads us to minimizing Pairwise Ranking Loss as the training objective.
Since the formula has only three parameters, the amount of training data needed is very small. A few hundred domain-relevant queries (per dataset) are more than enough.
For each query, the goal is for the feedback-based scoring formula to rank documents as well as the feedback model would. Hence, to form a training dataset:
- We retrieve the top X (
limit) documents per query. X is chosen as large as affordable, given the cost of obtaining a golden ranking on these X documents from the feedback model. - We use feedback from the top K (
context limit) results to mine context pairs for the formula, with K being much smaller than X. - The remaining X − K documents form the training pool, on which our naive formula learns to rank better (similarly to how the feedback model would).
Experiments
Before building a new interface, we needed to confirm our instinct: that a relevance feedback scoring can surface relevant documents that initial retrieval misses.
Setup
Each triplet retriever, feedback model, dataset forms one experiment.
Datasets
A subset of BEIR (Informational Retrieval benchmark):
- MSMARCO (8.84mln documents)
- SCIDOCS (25K documents)
- Quora (523K documents)
- FiQA-2018 (57K documents)
- NFCorpus (3.6K documents)
— documents and queries, no qrels needed.
Retrievers
As retrievers we chose:
- jina-embeddings-v2-base-en (768 output dimensions)
- mxbai-embed-large-v1 (1024 output dimensions)
- Qwen3-Embedding-0.6B (1024 output dimensions)
Feedback models
The cheapest feedback type suitable for testing the hypothesis that came to mind was using embedding models (bi-encoders) with higher dimensionality than those used for retrieval.
The feedback from these models is a similarity score between query and document embeddings (so, simply put, cosine similarity).
We chose as feedback models:
- mxbai-embed-large-v1 (1024 output dimensions)
- Qwen3-Embedding-0.6B (1024 output dimensions)
- Qwen3-Embedding-4B (2560 output dimensions)
- colBERTv2.0 (multivectors of 128 dimensions each)
With Qdrant’s Cloud Inference at our disposal, we ran embedding inference once for all datasets on both retrieval and feedback models, stored the embeddings in Qdrant, and then experimented with different formulas.
This way, we could use in our experiments one model interchangeably as a retriever and a feedback model.
Metric
We want to check if relevance feedback-based retrieval increases relevance recall. That means surfacing documents more relevant to the query than the vanilla retriever did.
How did we emulate “we-want-to-surface” quality in experiments?
- For each query, the retriever returned a ranked list of documents.
- We obtained a ground-truth relevance scoring of this list using the feedback model.
- We mined context pairs for the feedback-based scoring formula only from the top-K retrieved results.
This top-K emulated the context limit in production, aka the initial retrieval results available for feedback. - From the feedback model’s scores within the top-K, we took the highest score as a threshold.
Any document in the list outside the top-K whose feedback model score exceeded this threshold was considered a desired result for “the next retrieval iteration”.
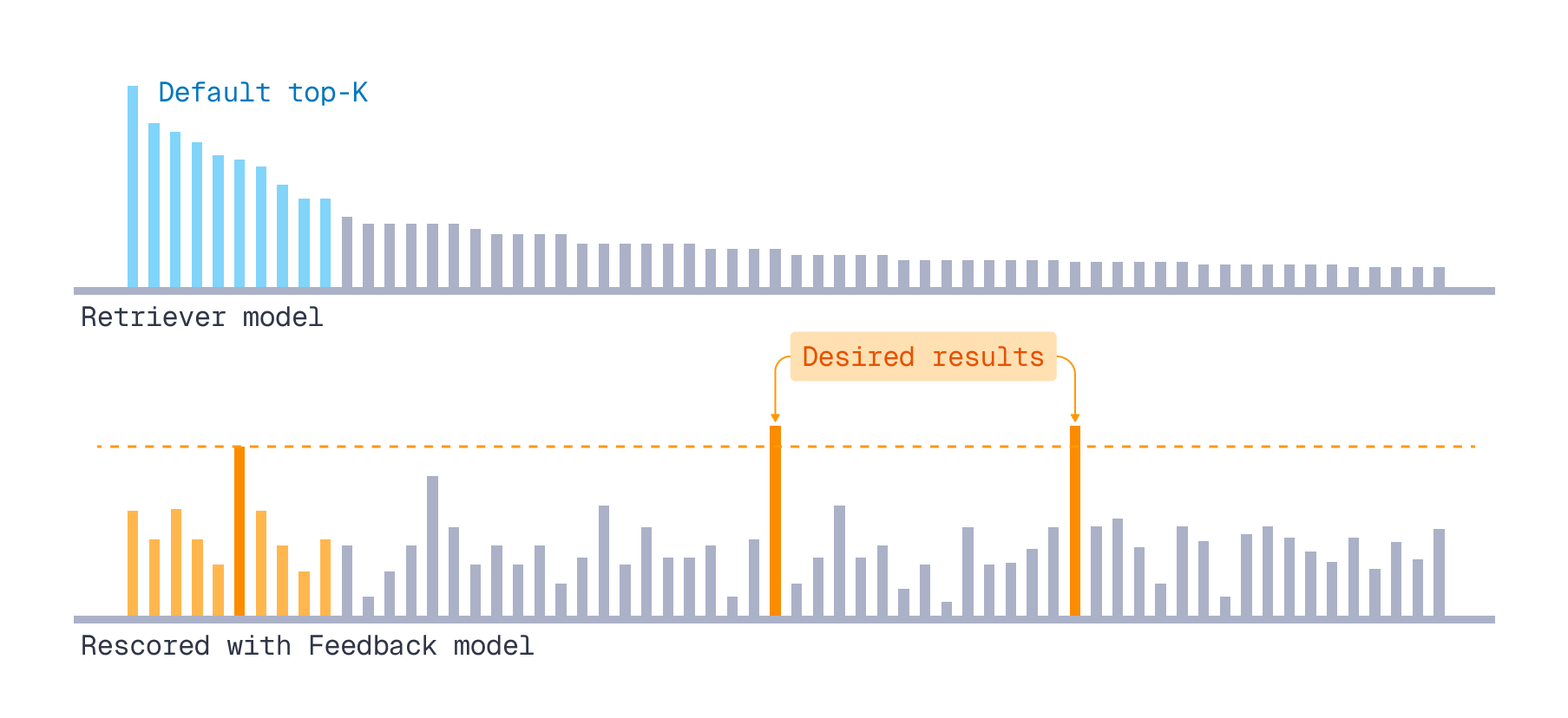
More relevant documents we’d like to surface
What we wanted to measure
On the next retrieval iteration, can our feedback-based formula pull more relevant documents into the top N than the vanilla retriever did?
Relevance is judged by the feedback model’s ground-truth scores.
For that, we came up with the abovethreshold@K metric.
Abovethreshold@N
A custom metric to compare vanilla retriever versus relevance feedback-based scoring.
How we computed it (per query):
We looked at N positions after the top-K documents used for mining context pairs (positions K+1 through K+N).
- Vanilla retriever: counted how many “we-want-to-surface” documents already appeared in these positions.
- Relevance feedback-based scoring: rescored all remaining documents (outside top-K) using a trained naive formula, reranked them, and counted how many “we-want-to-surface” documents appeared in the first N positions of the new ranking.
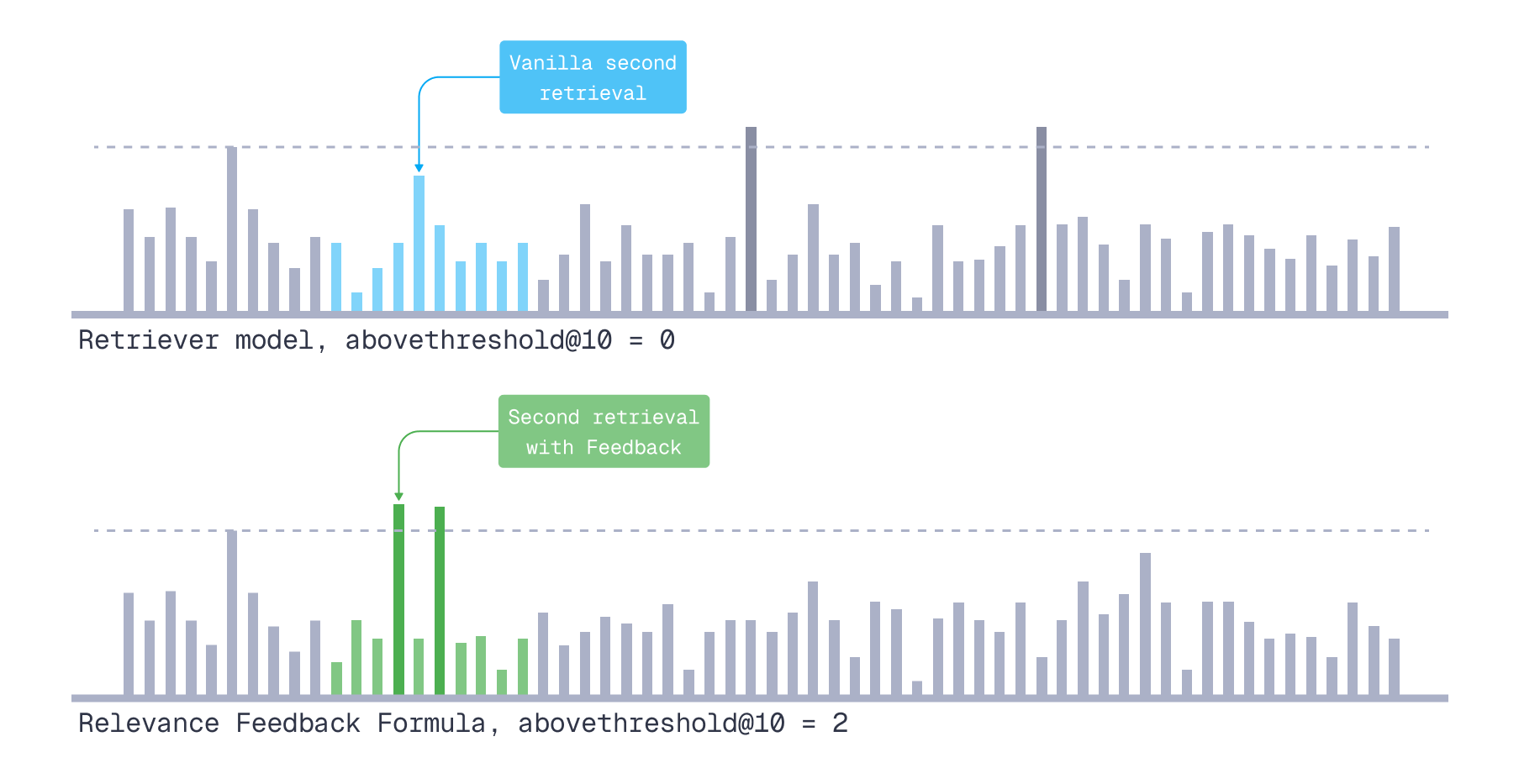
Abovethreshold@N metric
To get one number per test set, we summed abovethreshold@N counts across all queries per method and calculated the relative gain: (feedback_count - vanilla_count) / vanilla_count.
Parameters
Training data size
| Dataset | Train queries | Test queries |
|---|---|---|
| NFCorpus | 223 | 100 |
| FiQa-2018 | 500 | 148 |
| SCIDOCS | 500 | 500 |
| MSMARCO | 4000 | 1000 |
| Quora | 6000 | 1000 |
Queries for training are split in 50% train, 50% validation.
Training parameters
| Parameter | Value |
|---|---|
| Golden feedback model scoring limit (documents per query) | 100 |
| Context Limit, aka top K (to mine context pairs) | 5 |
| Context pairs used (out of all, sorted by the confidence) | top-1 |
| Learning rate | 0.005 |
| Epochs with early stopping and patience 200 | 2000 |
Testing parameters
| Parameter | Value |
|---|---|
| Context Limit, aka top K (to mine context pairs) | 3 |
| Context pairs used (out of all, sorted by the confidence) | all |
| Evaluation window size (N in abovethreshold@N) | 10 |
Results
Rescoring humongous datasets like MSMARCO on the user side for every query would not have been fun, especially while iterating on different formulas and hyperparameters. We faced the same problem that limits many relevance feedback researchers and practitioners, testing approaches only on a subset of all documents.
Our Relevance Feedback Query API is a remedy against this limitation, but first we needed experiment results to justify its implementation. A chicken-and-egg problem. Hence, to break the loop, we simulated feedback-based scoring on a hundred documents per query.
Out of all retriever–feedback model pairs, three leaders emerged with the following relative gain in abovethreshold@10 compared to the vanilla retriever:
| Qwen3-0.6B → colBERTv2.0 | Qwen3-0.6B → Qwen3-4B | mxbai-large-v1 → colBERTv2.0 | |
|---|---|---|---|
| NFCorpus | +10.34% | +10.61% | +21.57% |
| FiQA-2018 | +6.45% | +10.94% | +12.24% |
| SCIDOCS | +38.72% | +0.69% | +9.55% |
| MSMARCO | +23.23% | +16.73% | +2.40% |
| Quora | +5.04% | +2.67% | 0.00% |
jina-embeddings-v2-base-en, being a smaller and less expressive retriever, did not benefit from the feedback signal. Results varied significantly across queries, with no consistent improvement from adding feedback-based scoring.
| jina-v2-base → mxbai-large-v1 | jina-v2-base → Qwen3-0.6B | jina-v2-base → Qwen3-4B | |
|---|---|---|---|
| NFCorpus | +4.62% | −3.85% | +2.86% |
| FiQA-2018 | −3.90% | −1.59% | +3.97% |
| SCIDOCS | +4.55% | +1.62% | +1.82% |
| MSMARCO | +2.57% | +2.23% | +2.82% |
| Quora | 0.00% | −1.37% | 0.00% |
Takeaways
Relevance feedback scoring is most effective when the feedback model (reasonably) disagrees with the retriever’s ordering within the top-K (context limit). “Reasonably” meaning the feedback aligns with the user’s actual notion of relevance.
The retriever’s expressiveness limits how much it can benefit from feedback. The retriever operates in a lower-dimensional space and can’t capture all the distinctions the feedback model makes. Past a certain point, a more sophisticated feedback model won’t help.
Initially we used only the single highest-confidence context pair in the feedback-based scoring formula, both during training and at inference. We then discovered that at inference time, incorporating signals from additional (all) context pairs improves results.
Relevance Feedback Query
The results were convincing enough to justify implementing Relevance Feedback Query. And here it is, ready for your retrieval pipelines!
When to Use It
Use Relevance Feedback Query once a basic retrieval pipeline is in place and you’re looking for additional techniques to boost result relevance, such as Maximal Marginal Relevance (MMR), Reranking, or Score Boosting.
It’s here not to replace but to complement other search relevance tools.
For example, Relevance Feedback Query can be a great aid for search agents, letting you propagate the agent’s understanding of your use case directly to the vector search index.
How to Use It
For ease of use, as one shouldn’t need a machine learning degree to use a new feature, we published a Python package that customizes Naive Formula weights for your dataset, retriever, and feedback model.
What you need is a Qdrant collection, an idea of which feedback model you’d like to use to guide your retriever, and, optionally, a small set of use case-specific queries (50–300).
We provide QdrantRetriever (using our Cloud Inference or FastEmbed locally) and FastembedFeedback with bi-encoders, late interaction models, and cross-encoders as feedback model options.
That said, you can define your own retrievers and feedback models, whatever works best for your data modality and use case.
A feedback model can be anything: a bi-encoder, a late interaction model, a cross-encoder, or an LLM.
If no training queries are supplied, the package will train the formula directly on documents sampled from your Qdrant collection.
Warning: If your use case doesn’t involve document-to-document semantic similarity search, training on sampled documents alone may completely cancel the effect of relevance feedback scoring on real data.
It’s far more effective to use real queries.
Once you’ve obtained the weights, simply plug them into your Qdrant Client of choice.
Evaluating Your Gains
Additionally, the Relevance Feedback Parameters package provides an Evaluator module with two metrics: relative gain based on the abovethreshold@N metric from the “Experiments” section above, and a metric more recognizable to people in search – Discounted Cumulative Gain (DCG) Win Rate.
- Discounted Cumulative Gain (DCG) Win Rate
For each query, we compute DCG@N for both compared methods (vanilla and relevance feedback-based retrieval) against ground truth relevancy scores from a feedback model. The method with the higher DCG@N gets a “win”.
With this module you can immediately check the potential benefit of adding Relevance Feedback-based retrieval to your pipelines (or reproduce the benchmarks above).
If you don’t see any relative gain on your test queries, this particular “feedback model, retriever, dataset” triplet might just not work together; for example, if the feedback model fully agrees with the retriever’s ranking in all the cases, making the relevance feedback signal redundant.
If you’re unsure which feedback model to try next or have questions about Relevance Feedback Query in general, reach out in our Discord community.
Conclusion
We’ve released a new relevance feedback tool in Qdrant 1.17.0 to help increase the relevance of vector search results. It is built for scale, cheap, customizable, and universal.
It is cheap to use, as the time and resources spent on obtaining relevance feedback are minimal.
It is easy to adapt to your use case: dataset, retriever, and feedback model (any, from a bi-encoder to an LLM).
It is universal – data type agnostic (texts, images, code, molecules, you name it), as it works directly on embeddings.
It applies to the whole vector space, not just a subset of documents, a key distinction from approaches limited to reranking retrieved results.
It’s a tool for production.
If you’d like advice on Relevance Feedback Query usage or have ideas on how to enhance the method, reach out in our Discord community. Follow our LinkedIn for upcoming tutorials on various applications of Relevance Feedback Query.