On Unstructured Data, Vector Databases, New AI Age, and Our Seed Round.
Andre Zayarni
·April 19, 2023

Vector databases are here to stay. The New Age of AI is powered by vector embeddings, and vector databases are a foundational part of the stack. At Qdrant, we are working on cutting-edge open-source vector similarity search solutions to power fantastic AI applications with the best possible performance and excellent developer experience.
Our 7.5M seed funding – led by Unusual Ventures, awesome angels, and existing investors – will help us bring these innovations to engineers and empower them to make the most of their unstructured data and the awesome power of LLMs at any scale.
We are thrilled to announce that we just raised our seed round from the best possible investor we could imagine for this stage. Let’s talk about fundraising later – it is a story itself that I could probably write a bestselling book about. First, let’s dive into a bit of background about our project, our progress, and future plans.
A need for vector databases.
Unstructured data is growing exponentially, and we are all part of a huge unstructured data workforce. This blog post is unstructured data; your visit here produces unstructured and semi-structured data with every web interaction, as does every photo you take or email you send. The global datasphere will grow to 165 zettabytes by 2025, and about 80% of that will be unstructured. At the same time, the rising demand for AI is vastly outpacing existing infrastructure. Around 90% of machine learning research results fail to reach production because of a lack of tools.
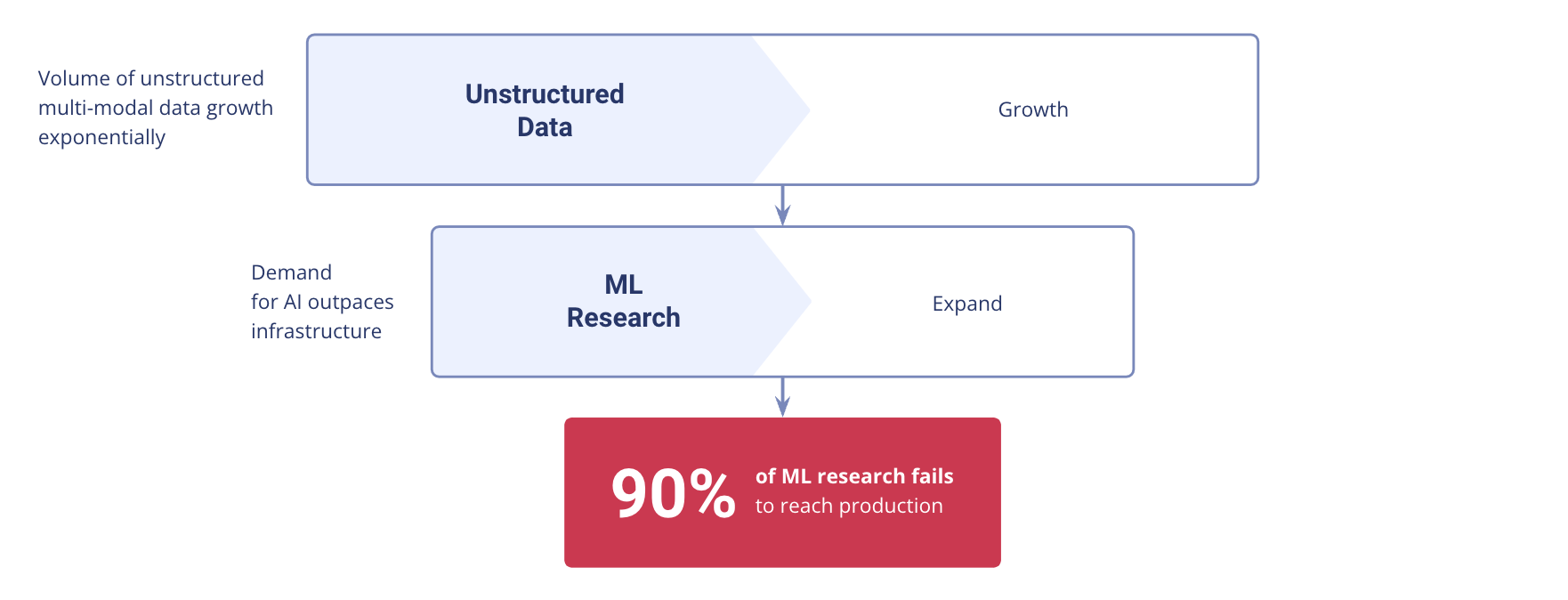
Demand for AI tools
Thankfully there’s a new generation of tools that let developers work with unstructured data in the form of vector embeddings, which are deep representations of objects obtained from a neural network model. A vector database, also known as a vector similarity search engine or approximate nearest neighbour (ANN) search database, is a database designed to store, manage, and search high-dimensional data with an additional payload. Vector Databases turn research prototypes into commercial AI products. Vector search solutions are industry agnostic and bring solutions for a number of use cases, including classic ones like semantic search, matching engines, and recommender systems to more novel applications like anomaly detection, working with time series, or biomedical data. The biggest limitation is to have a neural network encoder in place for the data type you are working with.
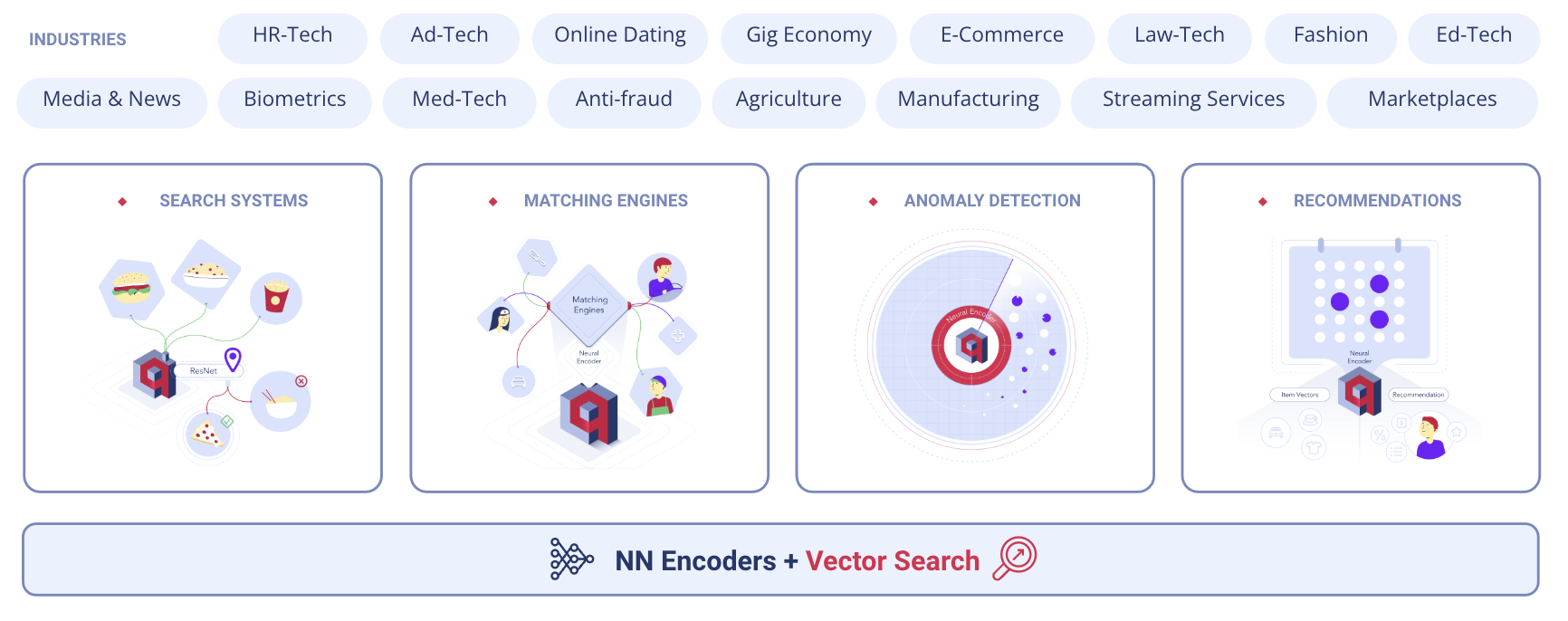
Vector Search Use Cases
With the rise of large language models (LLMs), Vector Databases have become the fundamental building block of the new AI Stack. They let developers build even more advanced applications by extending the “knowledge base” of LLMs-based applications like ChatGPT with real-time and real-world data.
A new AI product category, “Co-Pilot for X,” was born and is already affecting how we work. Starting from producing content to developing software. And this is just the beginning, there are even more types of novel applications being developed on top of this stack.
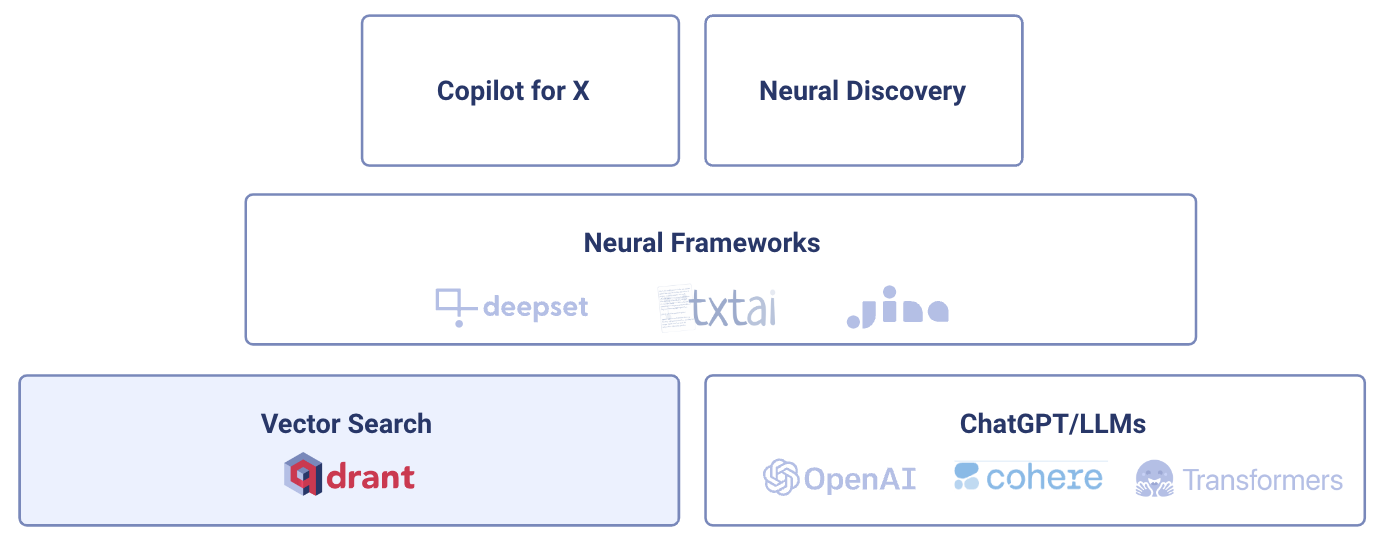
New AI Stack
Enter Qdrant.
At the same time, adoption has only begun. Vector Search Databases are replacing VSS libraries like FAISS, etc., which, despite their disadvantages, are still used by ~90% of projects out there They’re hard-coupled to the application code, lack of production-ready features like basic CRUD operations or advanced filtering, are a nightmare to maintain and scale and have many other difficulties that make life hard for developers.
The current Qdrant ecosystem consists of excellent products to work with vector embeddings. We launched our managed vector database solution, Qdrant Cloud, early this year, and it is already serving more than 1,000 Qdrant clusters. We are extending our offering now with managed on-premise solutions for enterprise customers.
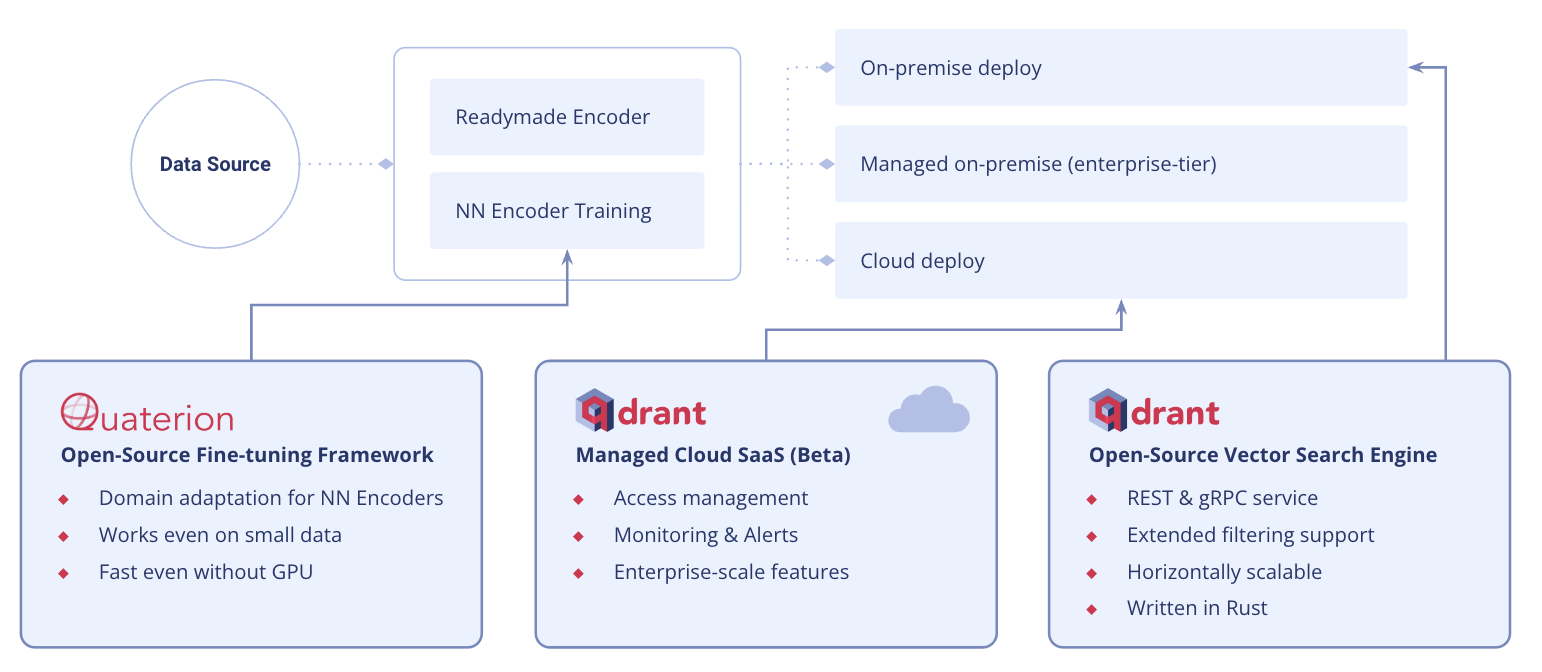
Qdrant Ecosystem
Our plan for the current open-source roadmap is to make billion-scale vector search affordable. Our recent release of the Scalar Quantization improves both memory usage (x4) as well as speed (x2). Upcoming Product Quantization will introduce even another option with more memory saving. Stay tuned.
Qdrant started more than two years ago with the mission of building a vector database powered by a well-thought-out tech stack. Using Rust as the system programming language and technical architecture decision during the development of the engine made Qdrant the leading and one of the most popular vector database solutions.
Our unique custom modification of the HNSW algorithm for Approximate Nearest Neighbor Search (ANN) allows querying the result with a state-of-the-art speed and applying filters without compromising on results. Cloud-native support for distributed deployment and replications makes the engine suitable for high-throughput applications with real-time latency requirements. Rust brings stability, efficiency, and the possibility to make optimization on a very low level. In general, we always aim for the best possible results in performance, code quality, and feature set.
Most importantly, we want to say a big thank you to our open-source community, our adopters, our contributors, and our customers. Your active participation in the development of our products has helped make Qdrant the best vector database on the market. I cannot imagine how we could do what we’re doing without the community or without being open-source and having the TRUST of the engineers. Thanks to all of you!
I also want to thank our team. Thank you for your patience and trust. Together we are strong. Let’s continue doing great things together.
Fundraising
The whole process took only a couple of days, we got several offers, and most probably, we would get more with different conditions. We decided to go with Unusual Ventures because they truly understand how things work in the open-source space. They just did it right.
Here is a big piece of advice for all investors interested in open-source: Dive into the community, and see and feel the traction and product feedback instead of looking at glossy pitch decks. With Unusual on our side, we have an active operational partner instead of one who simply writes a check. That help is much more important than overpriced valuations and big shiny names.
Ultimately, the community and adopters will decide what products win and lose, not VCs. Companies don’t need crazy valuations to create products that customers love. You do not need Ph.D. to innovate. You do not need to over-engineer to build a scalable solution. You do not need ex-FANG people to have a great team. You need clear focus, a passion for what you’re building, and the know-how to do it well.
We know how.
PS: This text is written by me in an old-school way without any ChatGPT help. Sometimes you just need inspiration instead of AI ;-)