Problems of Multi-Vector Search
Multi-vector search delivers impressive retrieval quality, but it comes with significant challenges. Before deploying multi-vector search in production, you need to understand these limitations and plan accordingly.
The good news: Module 3 covers optimization techniques that address many of these challenges.
The Indexing Challenge: Why HNSW Doesn’t Work
One of the fundamental challenges with multi-vector search stems from HNSW indexing incompatibility. As you learned in the MaxSim lesson, traditional vector search relies on HNSW (Hierarchical Navigable Small World) graphs to enable fast approximate nearest neighbor search. HNSW works by building static proximity graphs that connect similar documents, allowing efficient traversal during queries.
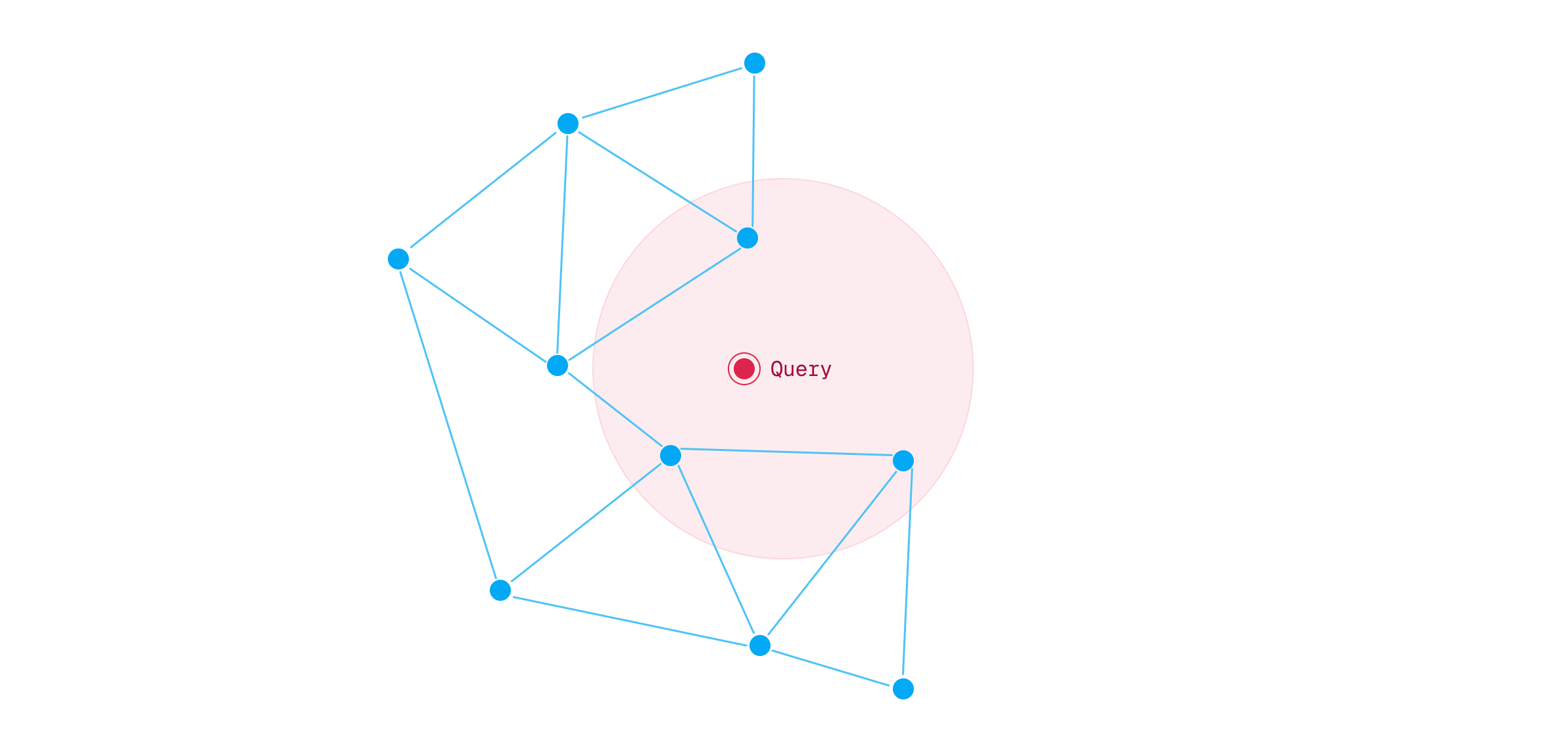
However, HNSW requires distance functions to be symmetric and query-independent. MaxSim breaks both assumptions by design. Remember that MaxSim(Q, D) ≠ MaxSim(D, Q) - when you swap the parameters, you iterate over different token sets, fundamentally changing the computation. A query with 3 tokens produces a different score than iterating over a document’s 200 tokens.
This asymmetry creates query-dependent nearest neighbor relationships. A document’s closest neighbors change based on which query you’re processing, making it impossible to build the static proximity graph that HNSW requires. The practical consequence: you must compute MaxSim against every document at query time using brute force comparison. For collections with millions of documents, this becomes prohibitively slow without optimization strategies.

The Resource Challenge: Memory and Computational Overhead
Beyond indexing challenges, multi-vector search demands significantly more resources than traditional single-vector approaches. You’ve seen the precision benefits in the previous lesson on use cases - now let’s understand the costs.
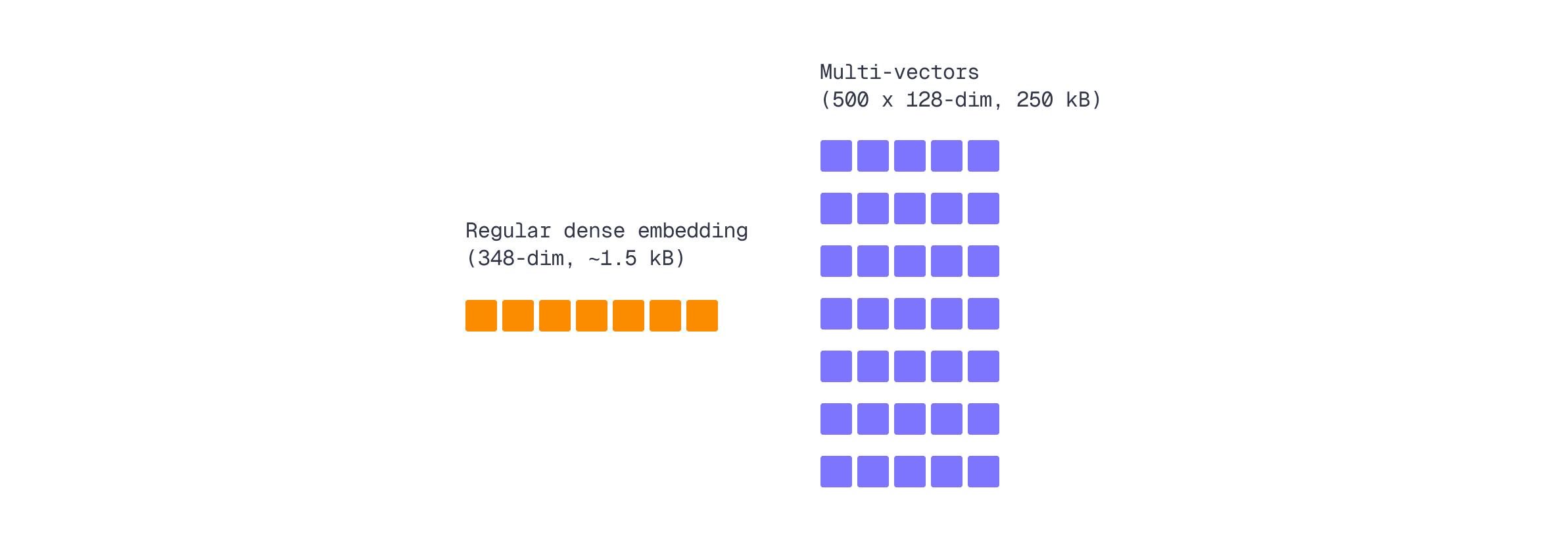
The overhead manifests in three ways: storage, memory, and computation. While single-vector search represents each document with one embedding (typically at least 384 dimensions), late interaction models like ColBERT use smaller per-token dimensions - around 128 dimensions per token - but maintain separate embeddings for every token.
Even with these smaller dimensions, the total storage explodes. Consider a technical article with 500 tokens: you’re storing 500 × 128 = 64,000 floats versus just 384 floats for a single dense embedding - roughly 167x more storage for that document. The lower dimensionality per token doesn’t compensate for the sheer number of vectors.
Each query-document pair requires computing multiple dot products (query tokens × document tokens), creating substantial computational overhead. A query with 10 tokens against a document with 200 tokens means 2,000 dot product operations instead of a single comparison.
This memory overhead combined with brute-force scanning creates fundamental scalability limits. While multi-vector search may work acceptably for collections with thousands or even millions of documents, brute-force MaxSim doesn’t scale indefinitely. At billion-scale collections, computing MaxSim against every document becomes prohibitively expensive - both in terms of memory required to keep all vectors and latency from scanning the entire dataset. Whether you can deploy multi-vector search in production depends on your collection size, infrastructure budget, and latency requirements. For some applications with manageable collection sizes, the precision gains justify the resource investment. For billion-scale systems, the optimization techniques covered in Module 3 become essential rather than optional.
These Challenges Are Solvable
While these limitations are real, solutions exist. The precision benefits of multi-vector search sometimes justify the costs for applications that demand fine-grained semantic matching. Understanding these trade-offs helps you make informed decisions about when and how to deploy multi-vector search in production.
What’s Next
Understanding these fundamental limitations prepares you for practical implementation. In the next lesson, you’ll learn how to use Qdrant multi-vector search, including collection configuration and storage optimization strategies.
From theory to practice - let’s see how Qdrant makes multi-vector search work.