ColPali Family Overview
The ColPali is not only the name of a model. Still, it is also often used to refer to an entire family of models that convert images and text into multi-vector representations, based on Vision Language Models.
Let’s explore what the options are and which model to choose depending on the data you work with.
The ColPali family includes several model variants. When selecting a model for your application, you’ll need to consider factors like model size, supported languages, computational requirements, and licensing constraints - each variant offers different trade-offs along these dimensions.
Model Size
While the original ColPali model delivers good performance, its multi-billion parameter size can be challenging for resource-constrained environments, demos, or CPU-only deployments. Fortunately, smaller alternatives maintain competitive performance while dramatically reducing computational requirements.
ColSmol: Efficient Small-Scale Models
The ColSmol family offers compact variants built on SmolVLM, available in 256M and 500M parameter sizes. These Apache 2.0 licensed models generate ColBERT-style multi-vector representations while being small enough for resource-constrained environments, like browser-based applications, or edge computing.
ColFlor: Ultra-Compact Retrieval
ColFlor pushes efficiency even further with only 174 million parameters, achieving performance 17× smaller and up to 9.8× faster than ColPali with only a 1.8% drop in accuracy on text-rich English documents. Built on Florence-2’s architecture, ColFlor is particularly attractive for demo environments, educational purposes, and scenarios where computational efficiency outweighs marginal performance differences.
Supported Languages
Original ColPali model primarily focuses on English documents, but several multilingual alternatives have emerged that extend multi-vector capabilities across different languages.
NVIDIA Multilingual Models
The NVIDIA Llama-NeMoRetriever-ColEmbed-3B-v1 was among the leading multilingual visual document retrieval models when it was released. Built on top of Google’s SigLIP-2 vision encoder and Meta’s Llama 3.2-3B language model, this late interaction embedding model demonstrated strong performance on multilingual retrieval benchmarks including ViDoRe and MIRACL-VISION.
However, potential users should be aware of licensing restrictions. The model is available for non-commercial and research use only due to multiple overlapping licenses: NVIDIA’s Non-Commercial License, Apache 2.0 for the SigLIP-2 component, and Meta’s Llama 3.2 Community License Agreement. Organizations requiring commercial deployment should carefully review these license terms or consider alternatives.
Open-Source Multilingual Alternative
For commercial applications, Nomic AI’s ColNomic-Embed-Multimodal-7B offers a compelling fully open-source alternative. Released in early 2025, this model demonstrated competitive performance on multilingual retrieval benchmarks. The model is available under an open-source license that permits commercial use, making it suitable for production deployments without licensing concerns. Nomic AI released a complete suite including both multi-vector (ColNomic) and single-vector variants in 3B and 7B parameter sizes, giving developers flexibility in choosing the right trade-off between performance and resource requirements.
Benchmarking Visual Document Retrieval
The ViDoRe (Visual Document Retrieval) Benchmark has emerged as the leading evaluation framework for visual retrieval models on document understanding tasks. As of January 2026, it stands as the largest and most comprehensive benchmark in the field, evaluating models across multiple domains, 6 languages (including English and French), and realistic retrieval scenarios including cross-document and long-form queries. You can explore the latest model performance and compare different approaches on the ViDoRe leaderboard.
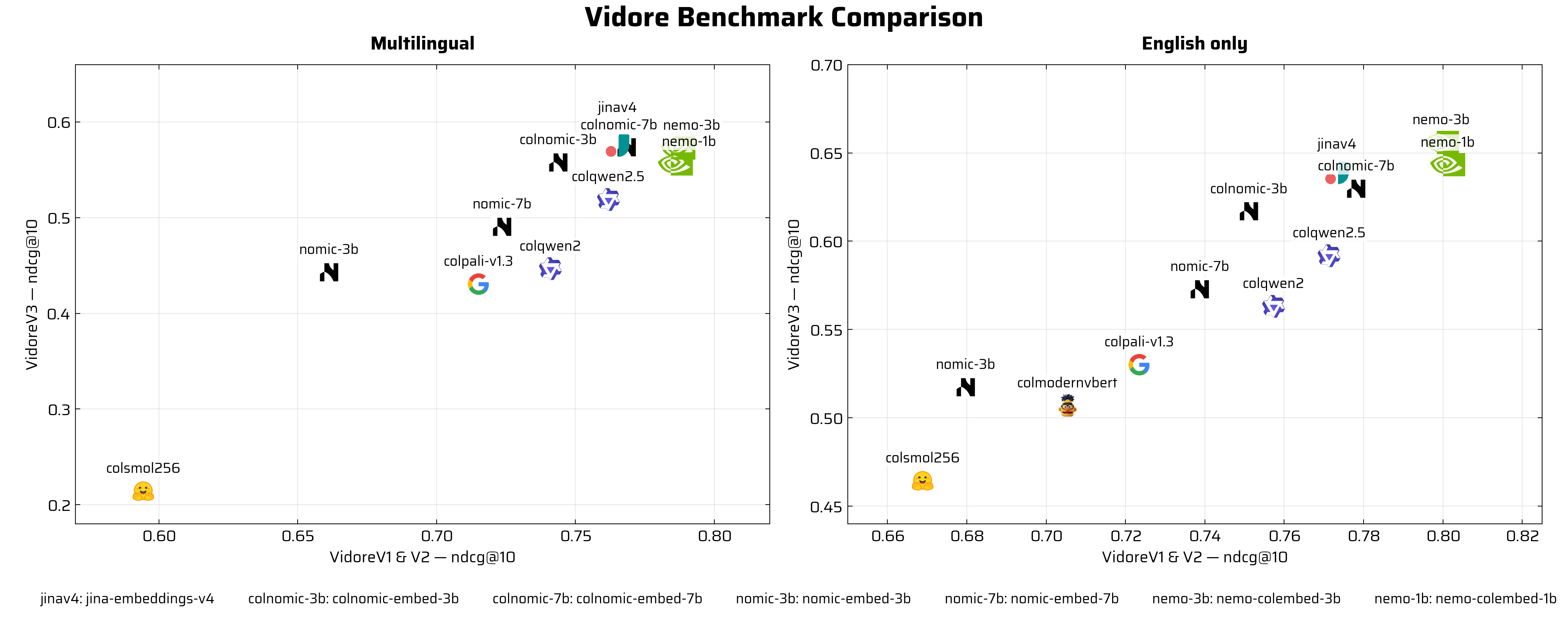
Source: https://huggingface.co/vidore
The current version, ViDoRe V3, represents the benchmark’s scale and ambition with 26,000+ pages across 3,099 queries in 6 languages, spanning 10 datasets (8 public, 2 private). The benchmark uses nDCG (Normalized Discounted Cumulative Gain) as its primary metric and includes challenging datasets spanning diverse domains - including HR, finance, industrial, pharmaceuticals, physics, computer science, and energy sectors. What sets ViDoRe V3 apart is its focus on real-world complexity: models are tested on truly challenging retrieval tasks with human-verified annotations that mirror actual user behavior in enterprise document retrieval scenarios.
The Impact of Bidirectional Attention
Bidirectional attention has emerged as a promising approach for multi-vector representations of multi-modal data.
The choice between unidirectional and bidirectional attention mechanisms significantly impacts model performance for embedding tasks. Understanding this distinction helps explain why certain architectures excel at retrieval while others are optimized for generation. Let’s first examine unidirectional attention and its limitations, then see how bidirectional attention addresses these constraints.
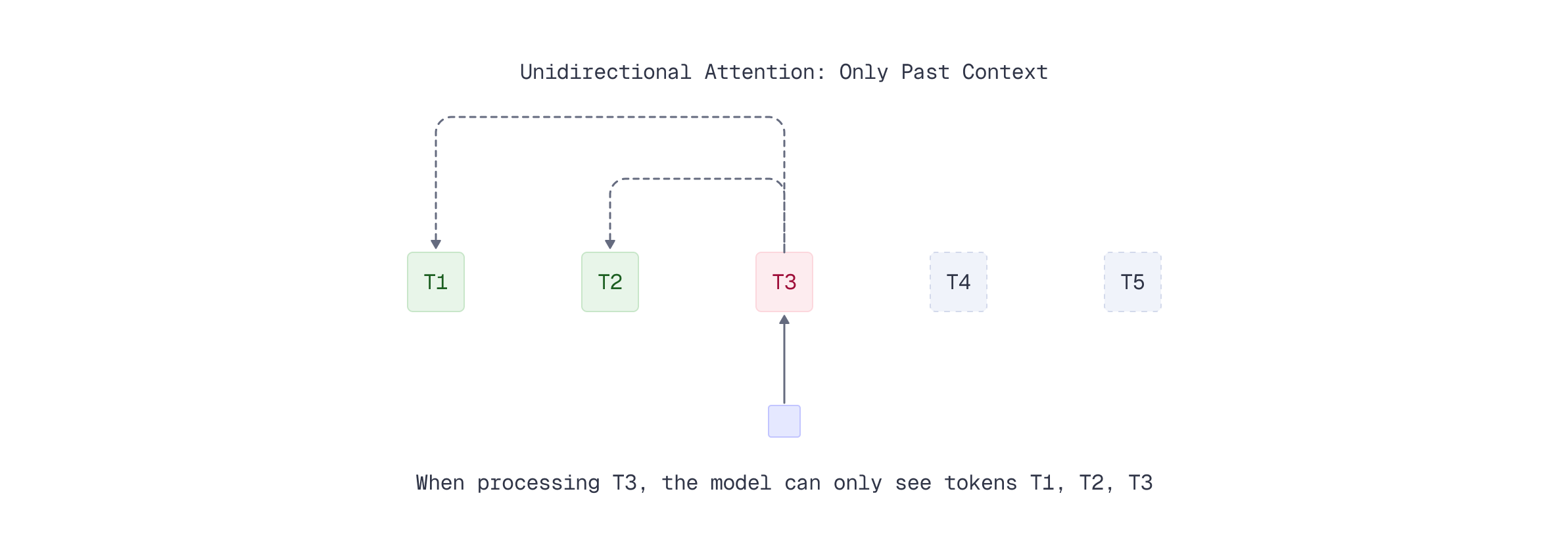
Unidirectional Attention: Designed for Generation
Most large language models (LLMs) and vision-language models (VLMs) like GPT, Llama, and the base models of ColPali use unidirectional (causal) attention. In this approach, each token can only attend to tokens that came before it in the sequence - the model looks backward but never forward.
This design makes perfect sense for generative tasks: when predicting the next token, the model should only use past context, not future information it hasn’t generated yet. However, this constraint creates limitations for embedding tasks. Token representations encode only information from previous context, missing crucial contextual information from subsequent tokens in the sequence.
The default ColPali model uses the unidirectional attention, derived from the underlying VLM. As a reminder, here is how we load the ColPali v.1.3 with FastEmbed.
from fastembed import LateInteractionMultimodalEmbedding
# Load the Qdrant/colpali-v1.3-fp16 model from HF hub
colpali_model = LateInteractionMultimodalEmbedding(
model_name="Qdrant/colpali-v1.3-fp16"
)
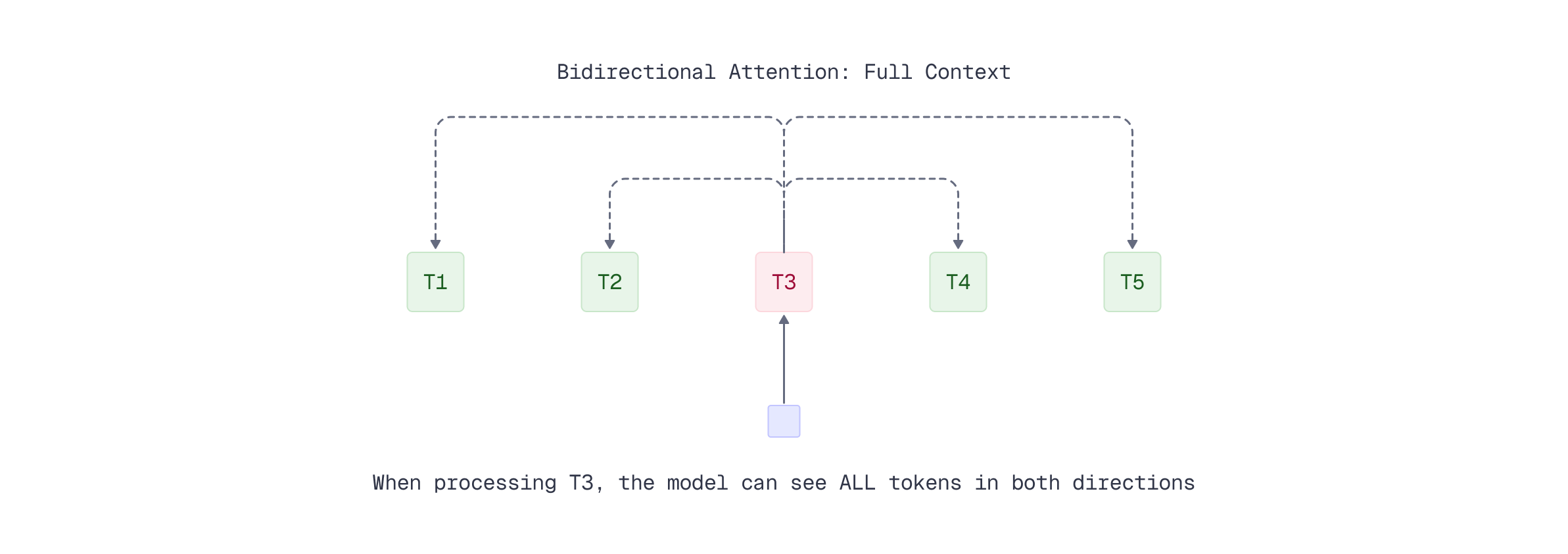
Bidirectional Attention: Optimized for Embeddings
Bidirectional attention, as used in encoder models like BERT, allows each token to attend to the entire input sequence - both past and future tokens. This creates richer, more contextually informed representations since each token’s embedding incorporates information from the complete surrounding context.
Research has shown that bidirectional encoder models are often the best option when training visual retrievers. The ColModernVBERT model exemplifies this approach: with only ~250 million parameters - over 10 times fewer than ColPali - it achieves performance only slightly lower on the ViDoRe benchmark.
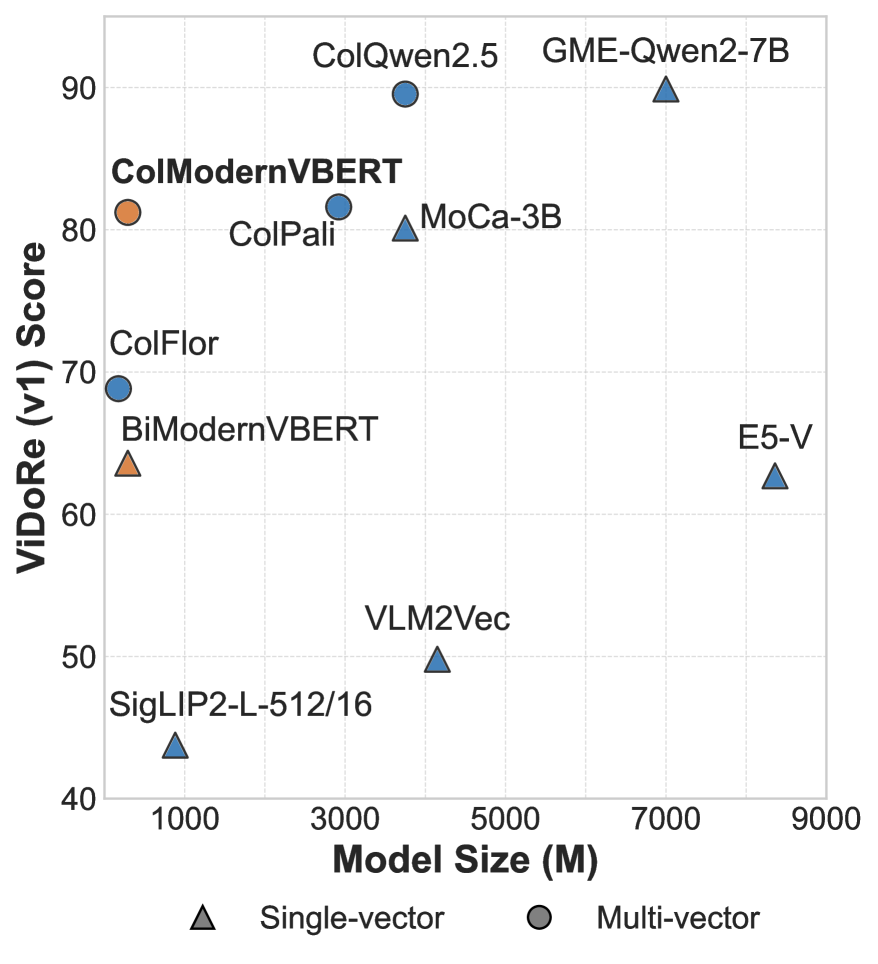
Source: Teiletche, P., Macé, Q., Conti, M., Loison, A., Viaud, G., Colombo, P., & Faysse, M. (2025). ModernVBERT: Towards Smaller Visual Document Retrievers. arXiv preprint arXiv:2510.01149. https://arxiv.org/abs/2510.01149
The chart above compares performance on the ViDoRe V2 benchmark. While ColPali and ColQwen achieve strong results with unidirectional attention, ColModernVBERT stands out as the only bidirectional model - proving that full-context attention enables competitive performance with dramatically fewer parameters. By allowing context to flow in both directions, these compact models generate embeddings that capture the nuanced semantic relationships critical for accurate multi-modal retrieval where visual and textual information must be jointly understood.
This efficiency makes ModernVBERT particularly attractive for resource-constrained environments or CPU-only deployments, where the slight performance trade-off is worthwhile for the substantial gains in speed and reduced computational requirements.
ColModernVBERT is available in FastEmbed and might be used like any other late interaction model for multi-modal data.
from fastembed import LateInteractionMultimodalEmbedding
# Load the Qdrant/colmodernvbert model from HF hub
colpali_model = LateInteractionMultimodalEmbedding(
model_name="Qdrant/colmodernvbert"
)
Future of Multi-Vector Representations
The multi-vector approach extends naturally to new modalities beyond images. Models like TomoroAI/tomoro-colqwen3-embed-8b, based on ColQwen3, demonstrate this extensibility by adding support for short video retrieval. Based on preliminary findings, ColQwen3 generalizes to videos while learning from image-text retrieval tasks - it samples video clips, encodes frames, then pools frame embeddings with per-dimension max before MaxSim scoring.
While not yet fine-tuned on large-scale video retrieval datasets, this lightweight approach highlights a key strength of the multi-vector paradigm, where new modalities can be added while preserving the core late interaction architecture.
What’s next
You’ve explored the ColPali family ecosystem - from ultra-compact models like ColFlor (174M parameters) to multilingual alternatives from NVIDIA and Nomic AI. You’ve learned how bidirectional attention architectures can achieve competitive results with far fewer parameters, and seen the benchmark results that guide model selection based on your performance and resource requirements.
Now that you know which model to use, let’s learn how to interpret what ColPali “sees” in your documents.