What is Agentic RAG? Building Agents with Qdrant
Kacper Łukawski
·November 22, 2024

Standard Retrieval Augmented Generation follows a predictable, linear path: receive a query, retrieve relevant documents, and generate a response. In many cases that might be enough to solve a particular problem. In the worst case scenario, your LLM will just decide to not answer the question, because the context does not provide enough information.
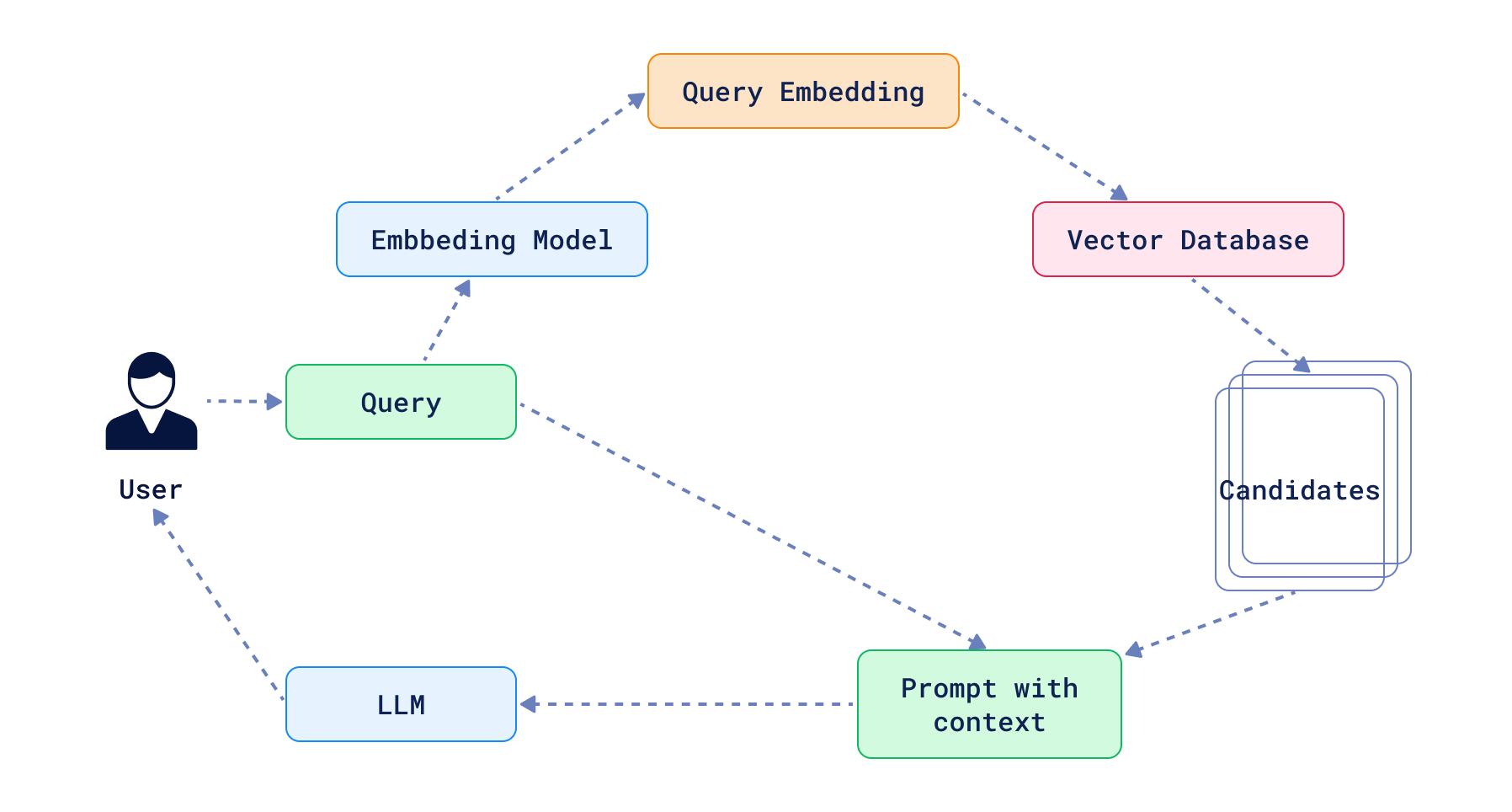
On the other hand, we have agents. These systems are given more freedom to act, and can take multiple non-linear steps to achieve a certain goal. There isn’t a single definition of what an agent is, but in general, it is an application that uses LLM and usually some tools to communicate with the outside world. LLMs are used as decision-makers which decide what action to take next. Actions can be anything, but they are usually well-defined and limited to a certain set of possibilities. One of these actions might be to query a vector database, like Qdrant, to retrieve relevant documents, if the context is not enough to make a decision. However, RAG is just a single tool in the agent’s arsenal.
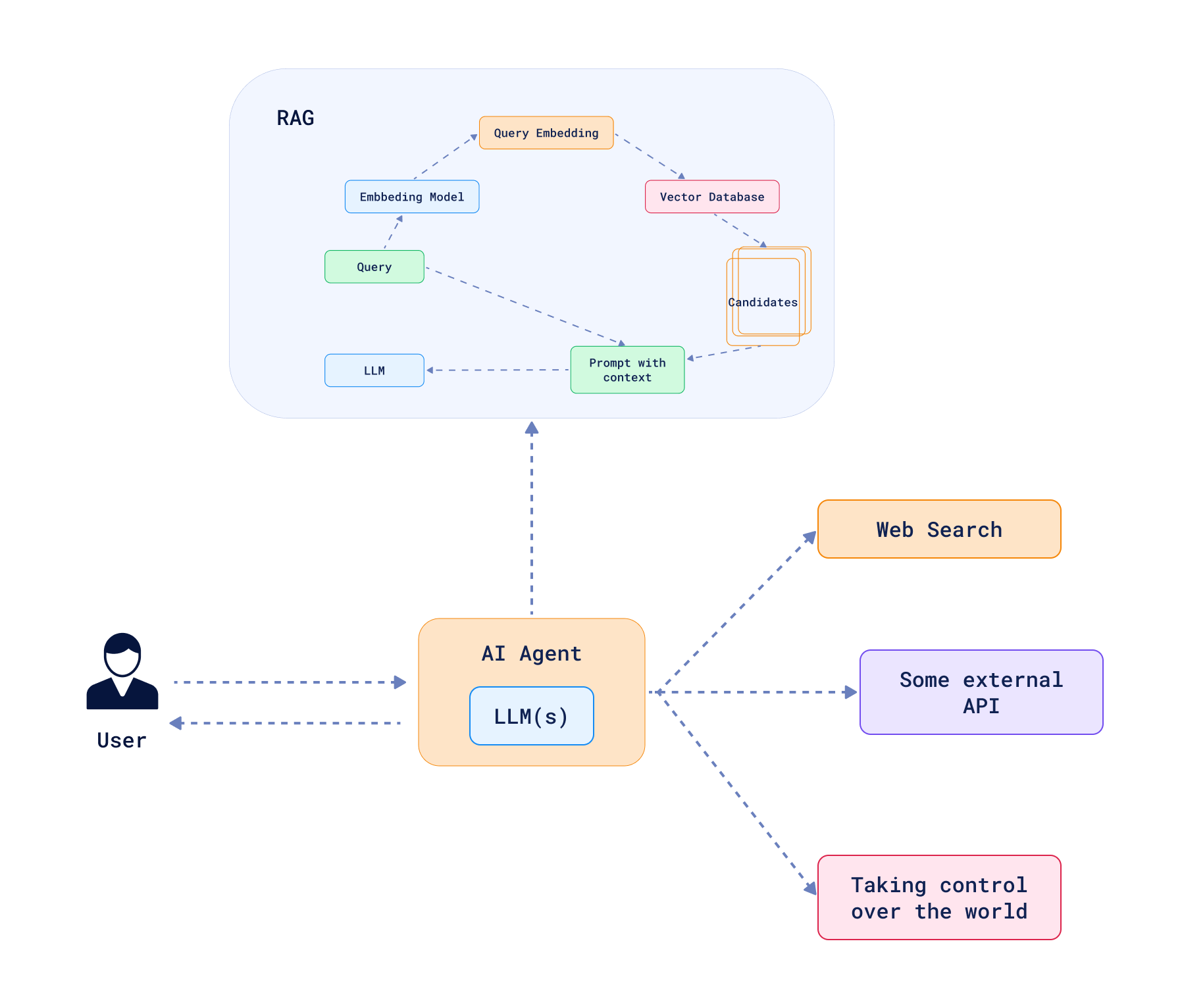
Agentic RAG: Combining RAG with Agents
Since the agent definition is vague, the concept of Agentic RAG is also not well-defined. In general, it refers to the combination of RAG with agents. This allows the agent to use external knowledge sources to make decisions, and primarily to decide when the external knowledge is needed. We can describe a system as Agentic RAG if it breaks the linear flow of a standard RAG system, and gives the agent the ability to take multiple steps to achieve a goal.
A simple router that chooses a path to follow is often described as the simplest form of an agent. Such a system has multiple paths with conditions describing when to take a certain path. In the context of Agentic RAG, the agent can decide to query a vector database if the context is not enough to answer, or skip the query if it’s enough, or when the question refers to common knowledge. Alternatively, there might be multiple collections storing different kinds of information, and the agent can decide which collection to query based on the context. The key factor is that the decision of choosing a path is made by the LLM, which is the core of the agent. A routing agent never comes back to the previous step, so it’s ultimately just a conditional decision-making system.
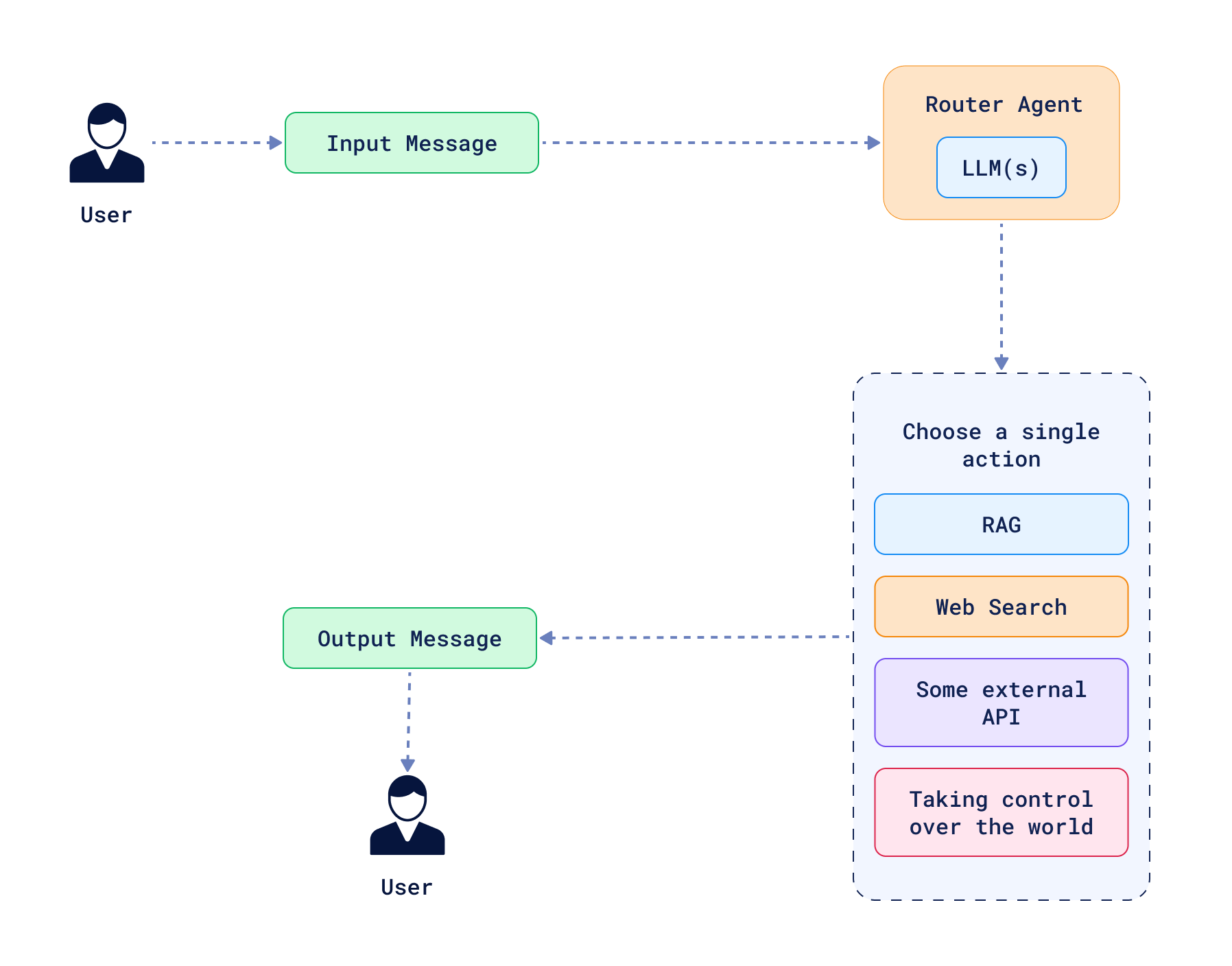
However, routing is just the beginning. Agents can be much more complex, and extreme forms of agents can have complete freedom to act. In such cases, the agent is given a set of tools and can autonomously decide which ones to use, how to use them, and in which order. LLMs are asked to plan and execute actions, and the agent can take multiple steps to achieve a goal, including taking steps back if needed. Such a system does not have to follow a DAG structure (Directed Acyclic Graph), and can have loops that help to self-correct the decisions made in the past. An agentic RAG system built in that manner can have tools not only to query a vector database, but also to play with the query, summarize the results, or even generate new data to answer the question. Options are endless, but there are some common patterns that can be observed in the wild.
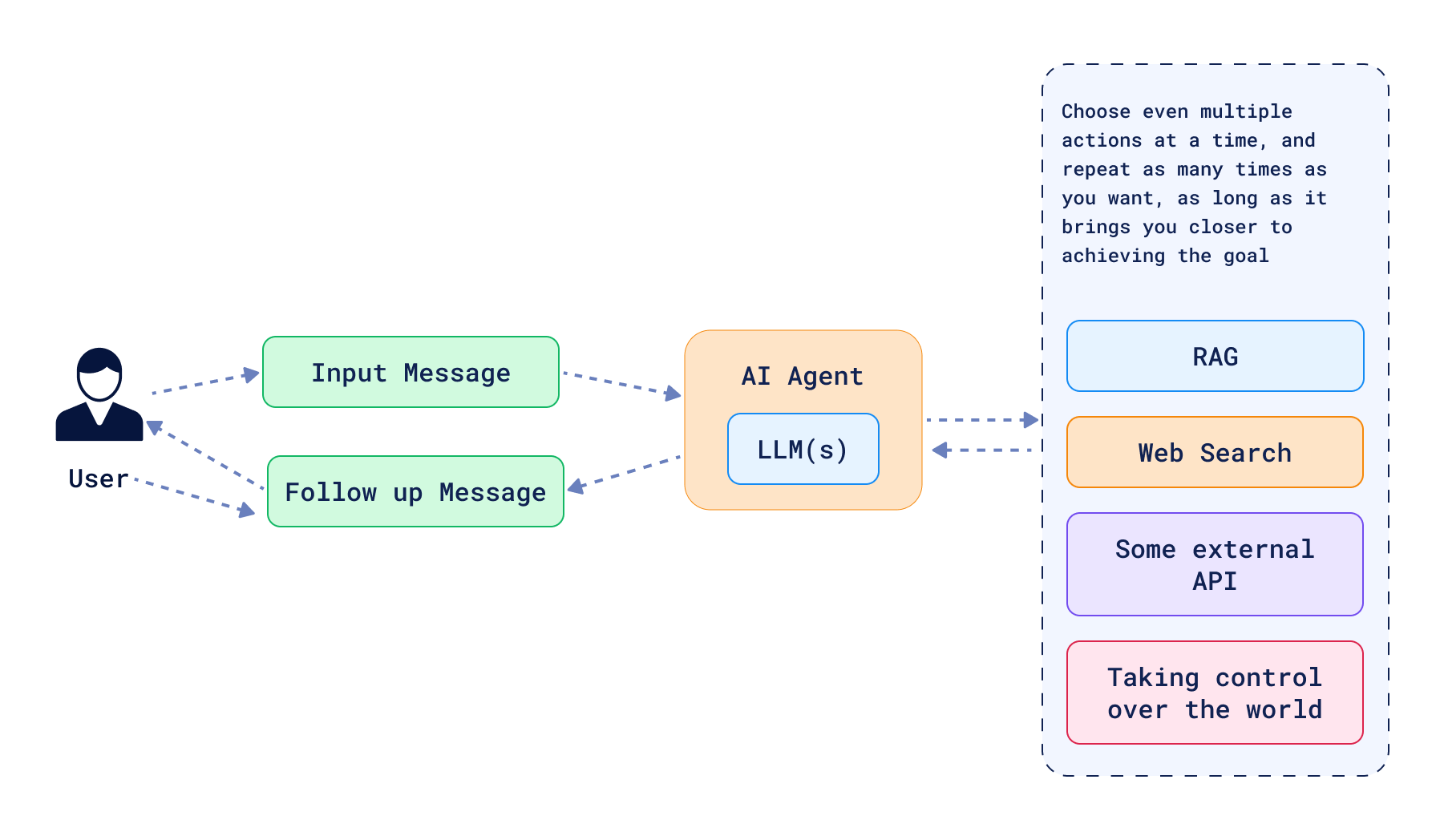
Solving Information Retrieval Problems with LLMs
Generally speaking, tools exposed in an agentic RAG system are used to solve information retrieval problems which are not new to the search community. LLMs have changed how we approach these problems, but the core of the problem remains the same. What kind of tools you can consider using in an agentic RAG? Here are some examples:
- Querying a vector database - the most common tool used in agentic RAG systems. It allows the agent to retrieve relevant documents based on the query.
- Query expansion - a tool that can be used to improve the query. It can be used to add synonyms, correct typos, or
even to generate new queries based on the original one.

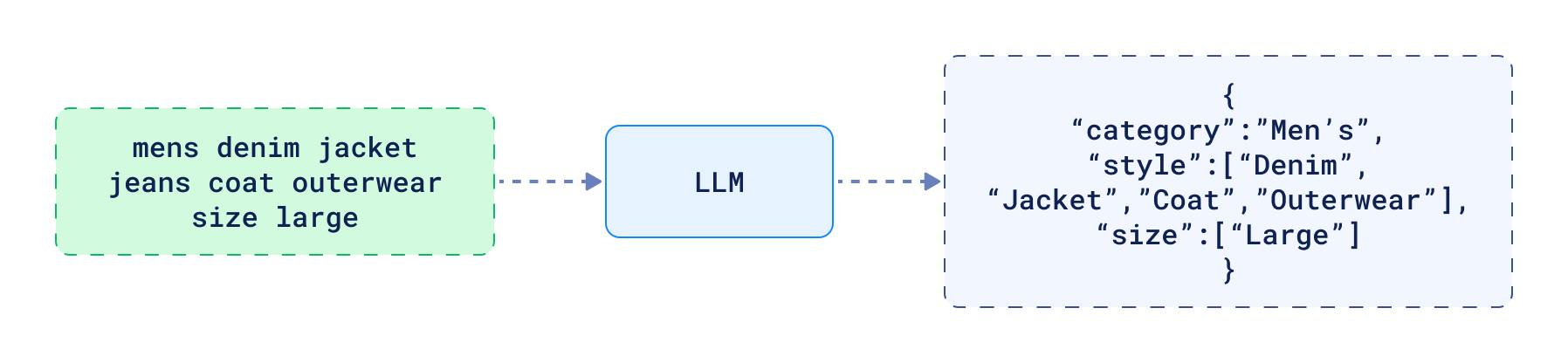
- Extracting filters - vector search alone is sometimes not enough. In many cases, you might want to narrow down
the results based on specific parameters. This extraction process can automatically identify relevant conditions from
the query. Otherwise, your users would have to manually define these search constraints.
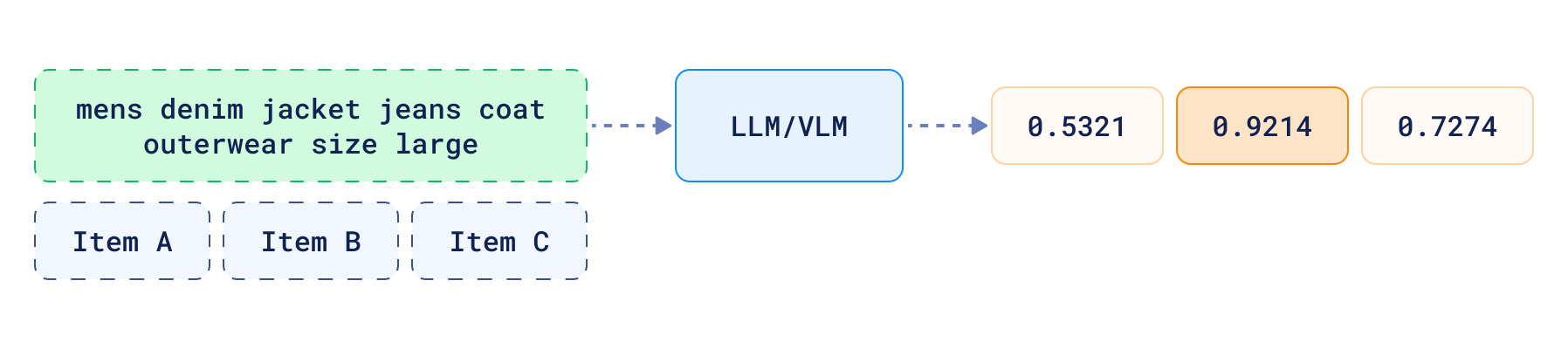
- Quality judgement - knowing the quality of the results for given query can be used to decide whether they are good
enough to answer, or if the agent should take another step to improve them somehow. Alternatively it can also admit
the failure to provide good response.
These are just some of the examples, but the list is not exhaustive. For example, your LLM could possibly play with Qdrant search parameters or choose different methods to query it. An example? If your users are searching using some specific keywords, you may prefer sparse vectors to dense vectors, as they are more efficient in such cases. In that case you have to arm your agent with tools to decide when to use sparse vectors and when to use dense vectors. Agent aware of the collection structure can make such decisions easily.
Each of these tools might be a separate agent on its own, and multi-agent systems are not uncommon. In such cases, agents can communicate with each other, and one agent can decide to use another agent to solve a particular problem. Pretty useful component of an agentic RAG is also a human in the loop, which can be used to correct the agent’s decisions, or steer it in the right direction.
Where are Agents Used?
Agents are an interesting concept, but since they heavily rely on LLMs, they are not applicable to all problems. Using Large Language Models is expensive and tend to be slow, what in many cases, it’s not worth the cost. Standard RAG involves just a single call to the LLM, and the response is generated in a predictable way. Agents, on the other hand, can take multiple steps, and the latency experienced by the user adds up. In many cases, it’s not acceptable. Agentic RAG is probably not that widely applicable in ecommerce search, where the user expects a quick response, but might be fine for customer support, where the user is willing to wait a bit longer for a better answer.
Which Framework is Best?
There are lots of frameworks available to build agents, and choosing the best one is not easy. It depends on your existing stack or the tools you are familiar with. Some of the most popular LLM libraries have already drifted towards the agent paradigm, and they are offering tools to build them. There are, however, some tools built primarily for agents development, so let’s focus on them.
LangGraph
Developed by the LangChain team, LangGraph seems like a natural extension for those who already use LangChain for building their RAG systems, and would like to start with agentic RAG.
Surprisingly, LangGraph has nothing to do with Large Language Models on its own. It’s a framework for building graph-based applications in which each node is a step of the workflow. Each node takes an application state as an input, and produces a modified state as an output. The state is then passed to the next node, and so on. Edges between the nodes might be conditional what makes branching possible. Contrary to some DAG-based tool (i.e. Apache Airflow), LangGraph allows for loops in the graph, which makes it possible to implement cyclic workflows, so an agent can achieve self-reflection and self-correction. Theoretically, LangGraph can be used to build any kind of applications in a graph-based manner, not only LLM agents.
Some of the strengths of LangGraph include:
- Persistence - the state of the workflow graph is stored as a checkpoint. That happens at each so-called super-step (which is a single sequential node of a graph). It enables replying certain steps of the workflow, fault-tolerance, and including human-in-the-loop interactions. This mechanism also acts as a short-term memory, accessible in a context of a particular workflow execution.
- Long-term memory - LangGraph also has a concept of memories that are shared between different workflow runs. However, this mechanism has to explicitly handled by our nodes. Qdrant with its semantic search capabilities is often used as a long-term memory layer.
- Multi-agent support - while there is no separate concept of multi-agent systems in LangGraph, it’s possible to create such an architecture by building a graph that includes multiple agents and some kind of supervisor that makes a decision which agent to use in a given situation. If a node might be anything, then it might be another agent as well.
Some other interesting features of LangGraph include the ability to visualize the graph, automate the retries of failed steps, and include human-in-the-loop interactions.
A minimal example of an agentic RAG could improve the user query, e.g. by fixing typos, expanding it with synonyms, or even generating a new query based on the original one. The agent could then retrieve documents from a vector database based on the improved query, and generate a response. The LangGraph app implementing this approach could look like this:
from typing import Sequence
from typing_extensions import TypedDict, Annotated
from langchain_core.messages import BaseMessage
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
class AgentState(TypedDict):
# The state of the agent includes at least the messages exchanged between the agent(s)
# and the user. It is, however, possible to include other information in the state, as
# it depends on the specific agent.
messages: Annotated[Sequence[BaseMessage], add_messages]
def improve_query(state: AgentState):
...
def retrieve_documents(state: AgentState):
...
def generate_response(state: AgentState):
...
# Building a graph requires defining nodes and building the flow between them with edges.
builder = StateGraph(AgentState)
builder.add_node("improve_query", improve_query)
builder.add_node("retrieve_documents", retrieve_documents)
builder.add_node("generate_response", generate_response)
builder.add_edge(START, "improve_query")
builder.add_edge("improve_query", "retrieve_documents")
builder.add_edge("retrieve_documents", "generate_response")
builder.add_edge("generate_response", END)
# Compiling the graph performs some checks and prepares the graph for execution.
compiled_graph = builder.compile()
# Compiled graph might be invoked with the initial state to start.
compiled_graph.invoke({
"messages": [
("user", "Why Qdrant is the best vector database out there?"),
]
})
Each node of the process is just a Python function that does certain operation. You can call an LLM of your choice inside of them, if you want to, but there is no assumption about the messages being created by any AI. LangGraph rather acts as a runtime that launches these functions in a specific order, and passes the state between them. While LangGraph integrates well with the LangChain ecosystem, it can be used independently. For teams looking for additional support and features, there’s also a commercial offering called LangGraph Platform. The framework is available for both Python and JavaScript environments, making it possible to be used in different tech stacks.
CrewAI
CrewAI is another popular choice for building agents, including agentic RAG. It’s a high-level framework that assumes there are some LLM-based agents working together to achieve a common goal. That’s where the “crew” in CrewAI comes from. CrewAI is designed with multi-agent systems in mind. Contrary to LangGraph, the developer does not create a graph of processing, but defines agents and their roles within the crew.
Some of the key concepts of CrewAI include:
- Agent - a unit that has a specific role and goal, controlled by an LLM. It can optionally use some external tools to communicate with the outside world, but generally steered by prompt we provide to the LLM.
- Process - currently either sequential or hierarchical. It defines how the task will be executed by the agents. In a sequential process, agents are executed one after another, while in a hierarchical process, agent is selected by the manager agent, which is responsible for making decisions about which agent to use in a given situation.
- Roles and goals - each agent has a certain role within the crew, and the goal it should aim to achieve. These are set when we define an agent and are used to make decisions about which agent to use in a given situation.
- Memory - an extensive memory system consists of short-term memory, long-term memory, entity memory, and contextual memory that combines the other three. There is also user memory for preferences and personalization. This is where Qdrant comes into play, as it might be used as a long-term memory layer.
CrewAI provides a rich set of tools integrated into the framework. That may be a huge advantage for those who want to combine RAG with e.g. code execution, or image generation. The ecosystem is rich, however bringing your own tools is not a big deal, as CrewAI is designed to be extensible.
A simple agentic RAG application implemented in CrewAI could look like this:
from crewai import Crew, Agent, Task
from crewai.memory.entity.entity_memory import EntityMemory
from crewai.memory.short_term.short_term_memory import ShortTermMemory
from crewai.memory.storage.rag_storage import RAGStorage
class QdrantStorage(RAGStorage):
...
response_generator_agent = Agent(
role="Generate response based on the conversation",
goal="Provide the best response, or admit when the response is not available.",
backstory=(
"I am a response generator agent. I generate "
"responses based on the conversation."
),
verbose=True,
)
query_reformulation_agent = Agent(
role="Reformulate the query",
goal="Rewrite the query to get better results. Fix typos, grammar, word choice, etc.",
backstory=(
"I am a query reformulation agent. I reformulate the "
"query to get better results."
),
verbose=True,
)
task = Task(
description="Let me know why Qdrant is the best vector database out there.",
expected_output="3 bullet points",
agent=response_generator_agent,
)
crew = Crew(
agents=[response_generator_agent, query_reformulation_agent],
tasks=[task],
memory=True,
entity_memory=EntityMemory(storage=QdrantStorage("entity")),
short_term_memory=ShortTermMemory(storage=QdrantStorage("short-term")),
)
crew.kickoff()
Disclaimer: QdrantStorage is not a part of the CrewAI framework, but it’s taken from the Qdrant documentation on how to integrate Qdrant with CrewAI.
Although it’s not a technical advantage, CrewAI has a great documentation. The framework is available for Python, and it’s easy to get started with it. CrewAI also has a commercial offering, CrewAI Enterprise, which provides a platform for building and deploying agents at scale.
AutoGen
AutoGen emphasizes multi-agent architectures as a fundamental design principle. The framework requires at least two agents in any system to really call an application agentic - typically an assistant and a user proxy exchange messages to achieve a common goal. Sequential chat with more than two agents is also supported, as well as group chat and nested chat for internal dialogue. However, AutoGen does not assume there is a structured state that is passed between the agents, and the chat conversation is the only way to communicate between them.
There are many interesting concepts in the framework, some of them even quite unique:
- Tools/functions - external components that can be used by agents to communicate with the outside world. They are defined as Python callables, and can be used for any external interaction we want to allow the agent to do. Type annotations are used to define the input and output of the tools, and Pydantic models are supported for more complex type schema. AutoGen supports only OpenAI-compatible tool call API for the time being.
- Code executors - built-in code executors include local command, Docker command, and Jupyter. An agent can write and launch code, so theoretically the agents can do anything that can be done in Python. None of the other frameworks made code generation and execution that prominent. Code execution being the first-class citizen in AutoGen is an interesting concept.
Each AutoGen agent uses at least one of the components: human-in-the-loop, code executor, tool executor, or LLM. A simple agentic RAG, based on the conversation of two agents which can retrieve documents from a vector database, or improve the query, could look like this:
from os import environ
from autogen import ConversableAgent
from autogen.agentchat.contrib.retrieve_user_proxy_agent import RetrieveUserProxyAgent
from qdrant_client import QdrantClient
client = QdrantClient(...)
response_generator_agent = ConversableAgent(
name="response_generator_agent",
system_message=(
"You answer user questions based solely on the provided context. You ask to retrieve relevant documents for "
"your query, or reformulate the query, if it is incorrect in some way."
),
description="A response generator agent that can answer your queries.",
llm_config={"config_list": [{"model": "gpt-4", "api_key": environ.get("OPENAI_API_KEY")}]},
human_input_mode="NEVER",
)
user_proxy = RetrieveUserProxyAgent(
name="retrieval_user",
llm_config={"config_list": [{"model": "gpt-4", "api_key": environ.get("OPENAI_API_KEY")}]},
human_input_mode="NEVER",
retrieve_config={
"task": "qa",
"chunk_token_size": 2000,
"vector_db": "qdrant",
"db_config": {"client": client},
"get_or_create": True,
"overwrite": True,
},
)
result = user_proxy.initiate_chat(
response_generator_agent,
message=user_proxy.message_generator,
problem="Why Qdrant is the best vector database out there?",
max_turns=10,
)
For those new to agent development, AutoGen offers AutoGen Studio, a low-code interface for prototyping agents. While not intended for production use, it significantly lowers the barrier to entry for experimenting with agent architectures.
It’s worth noting that AutoGen is currently undergoing significant updates, with version 0.4.x in development introducing substantial API changes compared to the stable 0.2.x release. While the framework currently has limited built-in persistence and state management capabilities, these features may evolve in future releases.
OpenAI Swarm
Unliked the other frameworks described in this article, OpenAI Swarm is an educational project, and it’s not ready for production use. It’s worth mentioning, though, as it’s pretty lightweight and easy to get started with. OpenAI Swarm is an experimental framework for orchestrating multi-agent workflows that focuses on agent coordination through direct handoffs rather than complex orchestration patterns.
With that setup, agents are just exchanging messages in a chat, optionally calling some Python functions to communicate with external services, or handing off the conversation to another agent, if the other one seems to be more suitable to answer the question. Each agent has a certain role, defined by the instructions we have to define. We have to decide which LLM will a particular agent use, and a set of functions it can call. For example, a retrieval agent could use a vector database to retrieve documents, and return the results to the next agent. That means, there should be a function that performs the semantic search on its behalf, but the model will decide how the query should look like.
Here is how a similar agentic RAG application, implemented in OpenAI Swarm, could look like:
from swarm import Swarm, Agent
client = Swarm()
def retrieve_documents(query: str) -> list[str]:
"""
Retrieve documents based on the query.
"""
...
def transfer_to_query_improve_agent():
return query_improve_agent
query_improve_agent = Agent(
name="Query Improve Agent",
instructions=(
"You are a search expert that takes user queries and improves them to get better results. You fix typos and "
"extend queries with synonyms, if needed. You never ask the user for more information."
),
)
response_generation_agent = Agent(
name="Response Generation Agent",
instructions=(
"You take the whole conversation and generate a final response based on the chat history. "
"If you don't have enough information, you can retrieve the documents from the knowledge base or "
"reformulate the query by transferring to other agent. You never ask the user for more information. "
"You have to always be the last participant of each conversation."
),
functions=[retrieve_documents, transfer_to_query_improve_agent],
)
response = client.run(
agent=response_generation_agent,
messages=[
{
"role": "user",
"content": "Why Qdrant is the best vector database out there?"
}
],
)
Even though we don’t explicitly define the graph of processing, the agents can still decide to hand off the processing to a different agent. There is no concept of a state, so everything relies on the messages exchanged between different components.
OpenAI Swarm does not focus on integration with external tools, and if you would like to integrate semantic search with Qdrant, you would have to implement it fully yourself. Obviously, the library is tightly coupled with OpenAI models, and while using some other ones is possible, it requires some additional work like setting up proxy that will adjust the interface to OpenAI API.
The winner?
Choosing the best framework for your agentic RAG system depends on your existing stack, team expertise, and the specific requirements of your project. All the described tools are strong contenders, and they are developed at rapid pace. It’s worth keeping an eye on all of them, as they are likely to evolve and improve over time. Eventually, you should be able to build the same processes with any of them, but some of them may be more suitable in a specific ecosystem of the tools you want your agent to interact with.
There are, however, some important factors to consider when choosing a framework for your agentic RAG system:
- Human-in-the-loop - even though we aim to build autonomous agents, it’s often important to include the feedback from the human, so our agents cannot perform malicious actions.
- Observability - how easy it is to debug the system, and how easy it is to understand what’s happening inside. Especially important, since we are dealing with lots of LLM prompts.
Still, choosing the right toolkit depends on the state of your project, and the specific requirements you have. If you want to integrate your agent with number of external tools, CrewAI might be the best choice, as the set of out-of-the-box integrations is the biggest. However, LangGraph integrates well with LangChain, so if you are familiar with that ecosystem, it may suit you better.
All the frameworks have different approaches to building agents, so it’s worth experimenting with all of them to see which one fits your needs the best. LangGraph and CrewAI are more mature and have more features, while AutoGen and OpenAI Swarm are more lightweight and more experimental. However, none of the existing frameworks solves all the mentioned Information Retrieval problems, so you still have to build your own tools to fill the gaps.
Building Agentic RAG with Qdrant
No matter which framework you choose, Qdrant is a great tool to build agentic RAG systems. Please check out our integrations to choose the best one for your use case and preferences. The easiest way to start using Qdrant is to use our managed service, Qdrant Cloud. A free 1GB cluster is available for free, so you can start building your agentic RAG system in minutes.
Further Reading
See how Qdrant integrates with: