Enhance Search Efficiency with Binary Quantization
Nirant Kasliwal
·February 21, 2024

OpenAI Ada-003 embeddings are a powerful tool for natural language processing (NLP). However, the size of the embeddings are a challenge, especially with real-time search and retrieval. In this article, we explore how you can use Qdrant’s Binary Quantization to enhance the performance and efficiency of OpenAI embeddings.
In this post, we discuss:
- The significance of OpenAI embeddings and real-world challenges.
- Qdrant’s Binary Quantization, and how it can improve the performance of OpenAI embeddings
- Results of an experiment that highlights improvements in search efficiency and accuracy
- Implications of these findings for real-world applications
- Best practices for leveraging Binary Quantization to enhance OpenAI embeddings
If you’re new to Binary Quantization, consider reading our article which walks you through the concept and how to use it with Qdrant
You can also try out these techniques as described in Binary Quantization OpenAI, which includes Jupyter notebooks.
New OpenAI embeddings: performance and changes
As the technology of embedding models has advanced, demand has grown. Users are looking more for powerful and efficient text-embedding models. OpenAI’s Ada-003 embeddings offer state-of-the-art performance on a wide range of NLP tasks, including those noted in MTEB and MIRACL.
These models include multilingual support in over 100 languages. The transition from text-embedding-ada-002 to text-embedding-3-large has led to a significant jump in performance scores (from 31.4% to 54.9% on MIRACL).
Matryoshka representation learning
The new OpenAI models have been trained with a novel approach called “Matryoshka Representation Learning”. Developers can set up embeddings of different sizes (number of dimensions). In this post, we use small and large variants. Developers can select embeddings which balances accuracy and size.
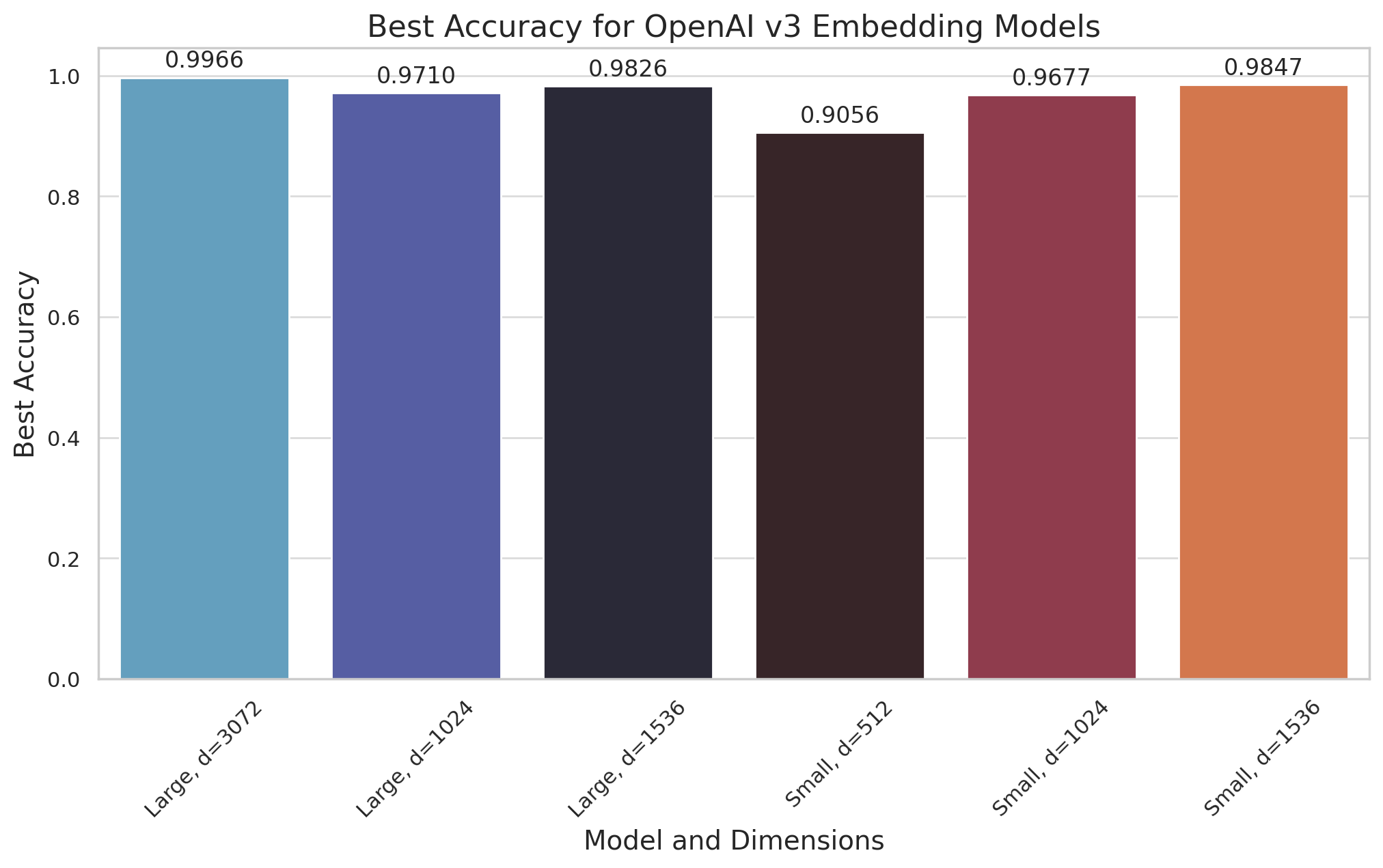
Here, we show how the accuracy of binary quantization is quite good across different dimensions – for both the models.
Enhanced performance and efficiency with binary quantization
By reducing storage needs, you can scale applications with lower costs. This addresses a critical challenge posed by the original embedding sizes. Binary Quantization also speeds the search process. It simplifies the complex distance calculations between vectors into more manageable bitwise operations, which supports potentially real-time searches across vast datasets.
The accompanying graph illustrates the promising accuracy levels achievable with binary quantization across different model sizes, showcasing its practicality without severely compromising on performance. This dual advantage of storage reduction and accelerated search capabilities underscores the transformative potential of Binary Quantization in deploying OpenAI embeddings more effectively across various real-world applications.
The efficiency gains from Binary Quantization are as follows:
- Reduced storage footprint: It helps with large-scale datasets. It also saves on memory, and scales up to 30x at the same cost.
- Enhanced speed of data retrieval: Smaller data sizes generally leads to faster searches.
- Accelerated search process: It is based on simplified distance calculations between vectors to bitwise operations. This enables real-time querying even in extensive databases.
Experiment setup: OpenAI embeddings in focus
To identify Binary Quantization’s impact on search efficiency and accuracy, we designed our experiment on OpenAI text-embedding models. These models, which capture nuanced linguistic features and semantic relationships, are the backbone of our analysis. We then delve deep into the potential enhancements offered by Qdrant’s Binary Quantization feature.
This approach not only leverages the high-caliber OpenAI embeddings but also provides a broad basis for evaluating the search mechanism under scrutiny.
Dataset
The research employs 100K random samples from the OpenAI 1M 1M dataset, focusing on 100 randomly selected records. These records serve as queries in the experiment, aiming to assess how Binary Quantization influences search efficiency and precision within the dataset. We then use the embeddings of the queries to search for the nearest neighbors in the dataset.
Parameters: oversampling, rescoring, and search limits
For each record, we run a parameter sweep over the number of oversampling, rescoring, and search limits. We can then understand the impact of these parameters on search accuracy and efficiency. Our experiment was designed to assess the impact of Binary Quantization under various conditions, based on the following parameters:
Oversampling: By oversampling, we can limit the loss of information inherent in quantization. This also helps to preserve the semantic richness of your OpenAI embeddings. We experimented with different oversampling factors, and identified the impact on the accuracy and efficiency of search. Spoiler: higher oversampling factors tend to improve the accuracy of searches. However, they usually require more computational resources.
Rescoring: Rescoring refines the first results of an initial binary search. This process leverages the original high-dimensional vectors to refine the search results, always improving accuracy. We toggled rescoring on and off to measure effectiveness, when combined with Binary Quantization. We also measured the impact on search performance.
Search Limits: We specify the number of results from the search process. We experimented with various search limits to measure their impact the accuracy and efficiency. We explored the trade-offs between search depth and performance. The results provide insight for applications with different precision and speed requirements.
Through this detailed setup, our experiment sought to shed light on the nuanced interplay between Binary Quantization and the high-quality embeddings produced by OpenAI’s models. By meticulously adjusting and observing the outcomes under different conditions, we aimed to uncover actionable insights that could empower users to harness the full potential of Qdrant in combination with OpenAI’s embeddings, regardless of their specific application needs.
Results: binary quantization’s impact on OpenAI embeddings
To analyze the impact of rescoring (True or False), we compared results across different model configurations and search limits. Rescoring sets up a more precise search, based on results from an initial query.
Rescoring
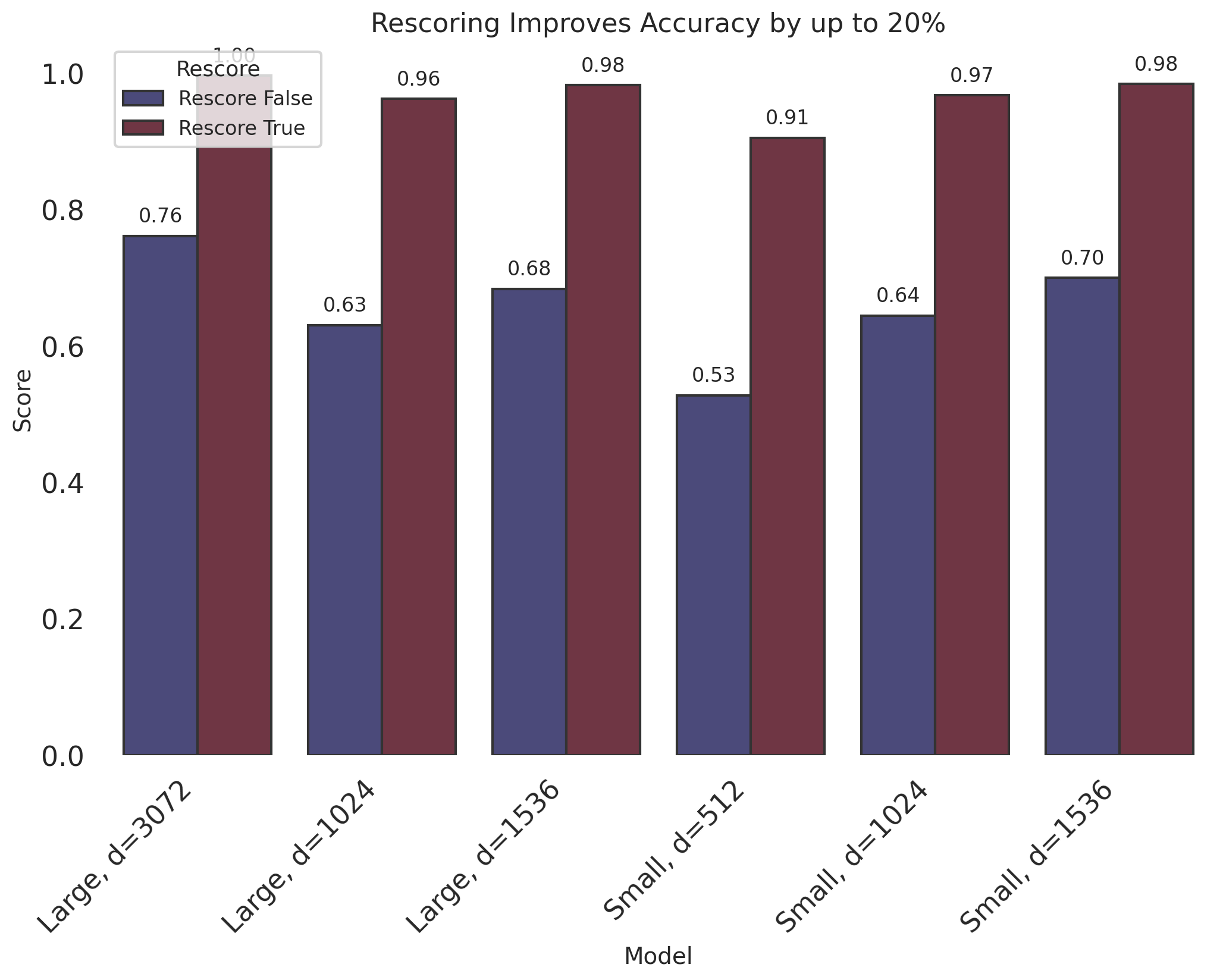
Here are some key observations, which analyzes the impact of rescoring (True or False):
Significantly Improved Accuracy:
- Across all models and dimension configurations, enabling rescoring (
True) consistently results in higher accuracy scores compared to when rescoring is disabled (False). - The improvement in accuracy is true across various search limits (10, 20, 50, 100).
- Across all models and dimension configurations, enabling rescoring (
Model and Dimension Specific Observations:
- For the
text-embedding-3-largemodel with 3072 dimensions, rescoring boosts the accuracy from an average of about 76-77% without rescoring to 97-99% with rescoring, depending on the search limit and oversampling rate. - The accuracy improvement with increased oversampling is more pronounced when rescoring is enabled, indicating a better utilization of the additional binary codes in refining search results.
- With the
text-embedding-3-smallmodel at 512 dimensions, accuracy increases from around 53-55% without rescoring to 71-91% with rescoring, highlighting the significant impact of rescoring, especially at lower dimensions.
- For the
In contrast, for lower dimension models (such as text-embedding-3-small with 512 dimensions), the incremental accuracy gains from increased oversampling levels are less significant, even with rescoring enabled. This suggests a diminishing return on accuracy improvement with higher oversampling in lower dimension spaces.
- Influence of Search Limit:
- The performance gain from rescoring seems to be relatively stable across different search limits, suggesting that rescoring consistently enhances accuracy regardless of the number of top results considered.
In summary, enabling rescoring dramatically improves search accuracy across all tested configurations. It is crucial feature for applications where precision is paramount. The consistent performance boost provided by rescoring underscores its value in refining search results, particularly when working with complex, high-dimensional data like OpenAI embeddings. This enhancement is critical for applications that demand high accuracy, such as semantic search, content discovery, and recommendation systems, where the quality of search results directly impacts user experience and satisfaction.
Dataset combinations
For those exploring the integration of text embedding models with Qdrant, it’s crucial to consider various model configurations for optimal performance. The dataset combinations defined above illustrate different configurations to test against Qdrant. These combinations vary by two primary attributes:
Model Name: Signifying the specific text embedding model variant, such as “text-embedding-3-large” or “text-embedding-3-small”. This distinction correlates with the model’s capacity, with “large” models offering more detailed embeddings at the cost of increased computational resources.
Dimensions: This refers to the size of the vector embeddings produced by the model. Options range from 512 to 3072 dimensions. Higher dimensions could lead to more precise embeddings but might also increase the search time and memory usage in Qdrant.
Optimizing these parameters is a balancing act between search accuracy and resource efficiency. Testing across these combinations allows users to identify the configuration that best meets their specific needs, considering the trade-offs between computational resources and the quality of search results.
dataset_combinations = [
{
"model_name": "text-embedding-3-large",
"dimensions": 3072,
},
{
"model_name": "text-embedding-3-large",
"dimensions": 1024,
},
{
"model_name": "text-embedding-3-large",
"dimensions": 1536,
},
{
"model_name": "text-embedding-3-small",
"dimensions": 512,
},
{
"model_name": "text-embedding-3-small",
"dimensions": 1024,
},
{
"model_name": "text-embedding-3-small",
"dimensions": 1536,
},
]
Exploring dataset combinations and their impacts on model performance
The code snippet iterates through predefined dataset and model combinations. For each combination, characterized by the model name and its dimensions, the corresponding experiment’s results are loaded. These results, which are stored in JSON format, include performance metrics like accuracy under different configurations: with and without oversampling, and with and without a rescore step.
Following the extraction of these metrics, the code computes the average accuracy across different settings, excluding extreme cases of very low limits (specifically, limits of 1 and 5). This computation groups the results by oversampling, rescore presence, and limit, before calculating the mean accuracy for each subgroup.
After gathering and processing this data, the average accuracies are organized into a pivot table. This table is indexed by the limit (the number of top results considered), and columns are formed based on combinations of oversampling and rescoring.
import pandas as pd
for combination in dataset_combinations:
model_name = combination["model_name"]
dimensions = combination["dimensions"]
print(f"Model: {model_name}, dimensions: {dimensions}")
results = pd.read_json(f"../results/results-{model_name}-{dimensions}.json", lines=True)
average_accuracy = results[results["limit"] != 1]
average_accuracy = average_accuracy[average_accuracy["limit"] != 5]
average_accuracy = average_accuracy.groupby(["oversampling", "rescore", "limit"])[
"accuracy"
].mean()
average_accuracy = average_accuracy.reset_index()
acc = average_accuracy.pivot(
index="limit", columns=["oversampling", "rescore"], values="accuracy"
)
print(acc)
Here is a selected slice of these results, with rescore=True:
| Method | Dimensionality | Test Dataset | Recall | Oversampling |
|---|---|---|---|---|
| OpenAI text-embedding-3-large (highest MTEB score from the table) | 3072 | DBpedia 1M | 0.9966 | 3x |
| OpenAI text-embedding-3-small | 1536 | DBpedia 100K | 0.9847 | 3x |
| OpenAI text-embedding-3-large | 1536 | DBpedia 1M | 0.9826 | 3x |
Impact of oversampling
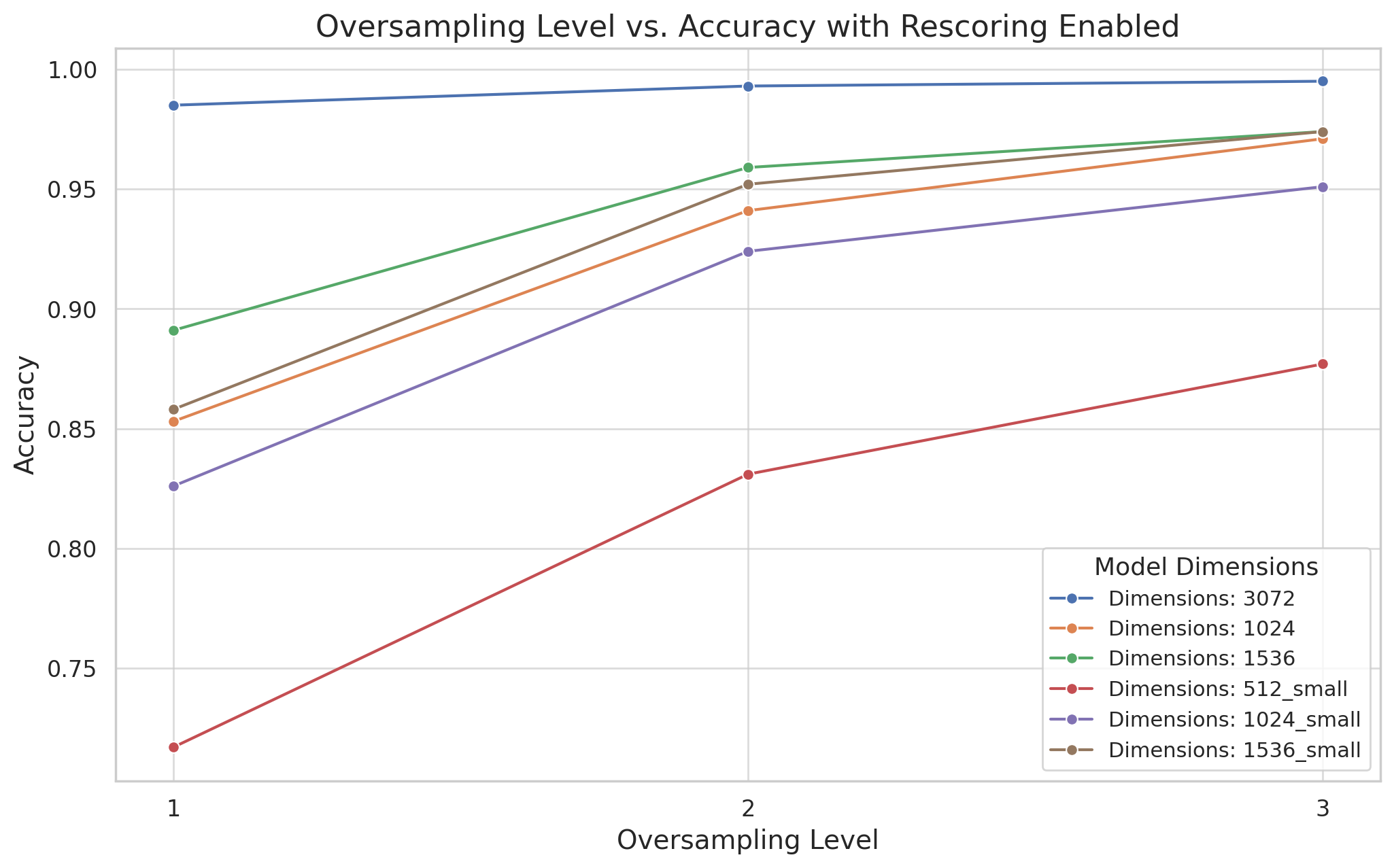
You can use oversampling in machine learning to counteract imbalances in datasets. It works well when one class significantly outnumbers others. This imbalance can skew the performance of models, which favors the majority class at the expense of others. By creating additional samples from the minority classes, oversampling helps equalize the representation of classes in the training dataset, thus enabling more fair and accurate modeling of real-world scenarios.
The screenshot showcases the effect of oversampling on model performance metrics. While the actual metrics aren’t shown, we expect to see improvements in measures such as precision, recall, or F1-score. These improvements illustrate the effectiveness of oversampling in creating a more balanced dataset. It allows the model to learn a better representation of all classes, not just the dominant one.
Without an explicit code snippet or output, we focus on the role of oversampling in model fairness and performance. Through graphical representation, you can set up before-and-after comparisons. These comparisons illustrate the contribution to machine learning projects.
Leveraging binary quantization: best practices
We recommend the following best practices for leveraging Binary Quantization to enhance OpenAI embeddings:
- Embedding Model: Use the text-embedding-3-large from MTEB. It is most accurate among those tested.
- Dimensions: Use the highest dimension available for the model, to maximize accuracy. The results are true for English and other languages.
- Oversampling: Use an oversampling factor of 3 for the best balance between accuracy and efficiency. This factor is suitable for a wide range of applications.
- Rescoring: Enable rescoring to improve the accuracy of search results.
- RAM: Store the full vectors and payload on disk. Limit what you load from memory to the binary quantization index. This helps reduce the memory footprint and improve the overall efficiency of the system. The incremental latency from the disk read is negligible compared to the latency savings from the binary scoring in Qdrant, which uses SIMD instructions where possible.
What’s next?
Binary quantization is exceptional if you need to work with large volumes of data under high recall expectations. You can try this feature either by spinning up a Qdrant container image locally or, having us create one for you through a free account in our cloud hosted service.
The article gives examples of data sets and configuration you can use to get going. Our documentation covers adding large datasets to Qdrant to your Qdrant instance as well as more quantization methods.
Want to discuss these findings and learn more about Binary Quantization? Join our Discord community.