Quantization
Quantization is an optional feature in Qdrant that enables efficient storage and search of high-dimensional vectors. By transforming original vectors into new representations, quantization compresses data while preserving close to original relative distances between vectors. Different quantization methods have different mechanics and tradeoffs. We will cover them in this section.
Quantization is primarily used to reduce the memory footprint and accelerate the search process in high-dimensional vector spaces. In the context of Qdrant, quantization allows you to optimize the search engine for specific use cases, striking a balance between accuracy, storage efficiency, and search speed.
There are tradeoffs associated with quantization. On the one hand, quantization allows for significant reductions in storage requirements and faster search times. This can be particularly beneficial in large-scale applications where minimizing the use of resources is a top priority. On the other hand, quantization introduces an approximation error, which can lead to a slight decrease in search quality. The level of this tradeoff depends on the quantization method and its parameters, as well as the characteristics of the data.
Qdrant supports four quantization methods:
- TurboQuant supports up to 32x compression, with strong recall across most embedding models.
- Scalar Quantization compresses each vector component from a 32-bit float to an 8-bit integer, achieving 4x compression with minimal accuracy loss.
- Binary Quantization reduces each vector component to one to two bits for up to 32x compression. Best suited for high-dimensional, centered vector distributions.
- Product Quantization enables up to 64x compression when minimizing memory is the top priority.
To help you choose the right quantization method for your use case, refer to the next section.
How to Choose the Right Quantization Method
Depending on your requirements for recall, compression, and distance metrics, consult this table for guidance:
| Compression | Method |
|---|---|
| 4 | Use Scalar Quantization. It is a well-established quantization method with a good balance between recall and compression. However, unless you need to use the Manhattan (L1) distance metric, consider using 4-bit TurboQuant instead of scalar quantization, as it offers comparable recall at double the compression. |
| 8 | Use 4-bit TurboQuant. It offers a good balance between recall and compression. When using the Manhattan (L1) distance metric, consider using another quantization method. |
| 16 | 2-bit TurboQuant and 2-bit binary quantization offer similar results at this compression level. Binary quantization is faster, but TurboQuant provides better recall. |
| 24 | 1.5-bit TurboQuant and 1.5-bit binary quantization offer similar results at this compression level. Binary quantization is faster, but TurboQuant provides better recall. |
| 32 | 1-bit TurboQuant and 1-bit binary quantization offer similar results at this compression level. Binary quantization is faster, but TurboQuant provides better recall. |
| Up to 64 | Use Product Quantization if the memory footprint is the top priority and accuracy and speed are not critical. |
TurboQuant Quantization
Available as of v1.18.0
TurboQuant is a quantization method developed by Google. It operates by applying a fast random rotation to vectors before compression, which evenly redistributes data across coordinates. This allows applying a single pre-computed, globally optimized quantization mapping across the dataset, enabling TurboQuant to work effectively with any vector distribution and overcoming a key limitation found in binary quantization.
Qdrant’s implementation of TurboQuant extends the original algorithm to close the gap between the algorithm’s theoretical assumptions and real-world embeddings.
TurboQuant uses asymmetric quantization automatically: only stored vectors are compressed, while queries are scored in full precision. This improves accuracy and requires no additional configuration.
Encoding Options
TurboQuant supports four bit depths:
| Encoding | Bit Depth | Compression |
|---|---|---|
bits4 (default) | 4 bits | 8× |
bits2 | 2 bits | 16× |
bits1_5 | 1.5 bits | 24× |
bits1 | 1 bit | 32× |
In our benchmarks, 4-bit TurboQuant, at twice the compression ratio of scalar quantization, delivers similar recall and speed. Results vary by dataset and embedding model: it may outperform or slightly underperform scalar quantization. This makes 4-bit TurboQuant a good default choice for many use cases.
Compared to binary quantization, TurboQuant offers better recall at lower speed and equivalent storage budgets.
The default encoding is bits4, which offers the best accuracy.
Distance Metric Support
TurboQuant fully supports Cosine, Dot, and Euclidean (L2) distance with SIMD-accelerated scoring.
Manhattan (L1) distance is supported but requires full vector reconstruction per comparison, making it significantly slower than the other metrics. Use Cosine, Dot, or Euclidean distance for best performance with TurboQuant.
Scalar Quantization
Available as of v1.1.0
Scalar quantization, in the context of vector search engines, is a compression technique that compresses vectors by reducing the number of bits used to represent each vector component.
For instance, Qdrant uses 32-bit floating numbers to represent the original vector components. Scalar quantization allows you to reduce the number of bits used to 8.
In other words, Qdrant performs float32 -> uint8 conversion for each vector component.
Effectively, this means that the amount of memory required to store a vector is reduced by a factor of 4.
In addition to reducing the memory footprint, scalar quantization also speeds up the search process.
Qdrant uses a special SIMD CPU instruction to perform fast vector comparison.
This instruction works with 8-bit integers, so the conversion to uint8 allows Qdrant to perform the comparison faster.
The main drawback of scalar quantization is the loss of accuracy. The float32 -> uint8 conversion introduces an error that can lead to a slight decrease in search quality.
However, this error is usually negligible, and tends to be less significant for high-dimensional vectors.
In our experiments, we found that the error introduced by scalar quantization is usually less than 1%.
However, this value depends on the data and the quantization parameters. Please refer to the Quantization Tips section for more information on how to optimize the quantization parameters for your use case.
Binary Quantization
Available as of v1.5.0
Binary quantization is an extreme case of scalar quantization. This feature lets you represent each vector component as a single bit, effectively reducing the memory footprint by a factor of 32. This is the fastest quantization method, since it lets you perform a vector comparison with a few CPU instructions. Binary quantization can achieve up to a 40x speedup compared to the original vectors.
However, binary quantization is only efficient for high-dimensional vectors and requires a centered distribution of vector components.
At the moment, binary quantization shows good accuracy results with the following models:
- OpenAI
text-embedding-ada-002- 1536d tested with dbpedia dataset achieving 0.98 recall@100 with 4x oversampling - Cohere AI
embed-english-v2.0- 4096d tested on Wikipedia embeddings - 0.98 recall@50 with 2x oversampling
Models with a lower dimensionality or a different distribution of vector components may require additional experiments to find the optimal quantization parameters.
We recommend using binary quantization only with rescoring enabled, as this can significantly improve search quality. However, keep in mind that if the original vectors are stored on disk, rescoring can significantly decrease search speed.
Additionally, oversampling can be used to tune the tradeoff between search speed and search quality at query time.
Binary Quantization as Hamming Distance
The additional benefit of this method is that you can efficiently emulate Hamming distance with dot product.
Specifically, if original vectors contain {-1, 1} as possible values, then the dot product of two vectors is equal to the Hamming distance by simply replacing -1 with 0 and 1 with 1.
Sample truth table
| Vector 1 | Vector 2 | Dot product |
|---|---|---|
| 1 | 1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| Vector 1 | Vector 2 | Hamming distance |
|---|---|---|
| 1 | 1 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
As you can see, both functions are equal up to a constant factor, which makes similarity search equivalent. Binary quantization makes it efficient to compare vectors using this representation.
1.5-Bit and 2-Bit Quantization
Available as of v1.15.0
Binary quantization storage can use 2 and 1.5 bits per dimension, improving precision for smaller vectors. One-bit compression resulted in significant data loss and precision drops for vectors smaller than a thousand dimensions, often requiring expensive rescoring. 2-bit quantization offers 16X compression compared to 32X with one bit, improving performance for smaller vector dimensions. The 1.5-bit quantization compression offers 24X compression and intermediate accuracy.
A major limitation of binary quantization is poor handling of values close to zero. 2-bit quantization addresses this by explicitly representing zeros using an efficient scoring mechanism. In the case of 1.5-bit quantization, the zero-bit is shared between two values, balancing the efficiency of binary quantization with the accuracy improvements of 2-bit quantization, especially when 2-bit BQ requires too much memory.
In order to build 2-bit representation, Qdrant computes values distribution and then assigns bit values to 3 possible buckets:
-1- 000- 011- 11
1.5-bit quantization is similar, but it merges buckets of element pairs into binary triplets.
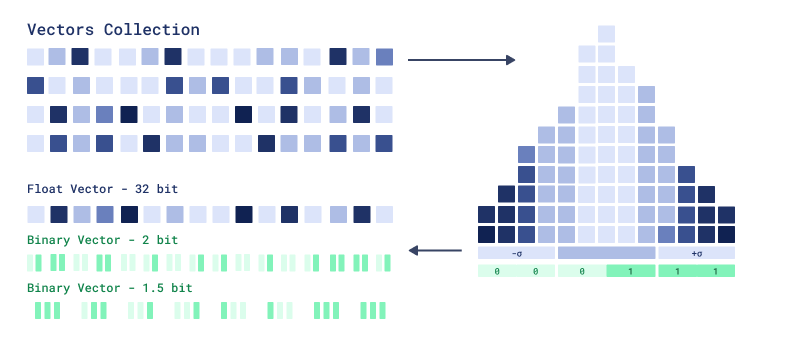
2-bit quantization
See how to set up 1.5-bit and 2-bit quantization in the following section.
Asymmetric Quantization
Available as of v1.15.0
The Asymmetric Quantization technique allows Qdrant to use different vector encoding algorithms for stored vectors and queries. A particularly interesting combination is binary stored vectors and Scalar quantized queries.
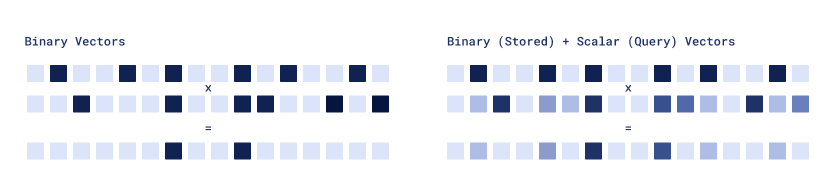
Asymmetric quantization
This approach maintains storage size and RAM usage similar to binary quantization while offering improved precision. It is beneficial for memory-constrained deployments, or where the bottleneck is disk I/O rather than CPU. This is particularly useful for indexing millions of vectors as it improves precision without sacrificing much because the limitation in such scenarios is disk speed, not CPU. This approach requires less rescoring for the same quality output.
See how to set up Asymmetric Quantization quantization in the following section
Product Quantization
Available as of v1.2.0
Product quantization is a method of compressing vectors to minimize their memory usage by dividing them into chunks and quantizing each segment individually. Each chunk is approximated by a centroid index that represents the original vector component. The positions of the centroids are determined through the utilization of a clustering algorithm such as k-means. For now, Qdrant uses only 256 centroids, so each centroid index can be represented by a single byte.
Product quantization can compress by a more prominent factor than a scalar one. But there are some tradeoffs. Product quantization distance calculations are not SIMD-friendly, so it is slower than scalar quantization. Also, product quantization has a loss of accuracy, so it is recommended to use it only for high-dimensional vectors.
Please refer to the Quantization Tips section for more information on how to optimize the quantization parameters for your use case.
Setting Up Quantization in Qdrant
You can configure quantization for a collection by specifying the quantization parameters in the quantization_config section of the collection configuration.
Quantization will be automatically applied to all vectors during the indexation process. Quantized vectors are stored alongside the original vectors in the collection, so you will still have access to the original vectors if you need them.
Available as of v1.1.1
The quantization_config can also be set on a per vector basis by specifying it in a named vector.
Setting Up TurboQuant
To enable TurboQuant, specify it in the quantization_config section of the collection configuration.
When enabling TurboQuant on an existing collection, use a PATCH request or the corresponding update_collection method and omit the vector configuration, as it’s already defined.
PUT /collections/{collection_name}
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"quantization_config": {
"turbo": {
"always_ram": true
}
}
}
from qdrant_client import QdrantClient, models
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),
quantization_config=models.TurboQuantization(
turbo=models.TurboQuantQuantizationConfig(
always_ram=True,
),
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
client.createCollection("{collection_name}", {
vectors: {
size: 1536,
distance: "Cosine",
},
quantization_config: {
turbo: {
always_ram: true,
},
},
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, Distance, TurboQuantizationBuilder, VectorParamsBuilder,
};
use qdrant_client::Qdrant;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(1536, Distance::Cosine))
.quantization_config(TurboQuantizationBuilder::new().always_ram(true)),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.TurboQuantization;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(1536)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setTurboquant(TurboQuantization.newBuilder().setAlwaysRam(true).build())
.build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 1536, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Turboquant = new TurboQuantization { AlwaysRam = true }
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 1536,
Distance: qdrant.Distance_Cosine,
}),
QuantizationConfig: qdrant.NewQuantizationTurbo(
&qdrant.TurboQuantization{
AlwaysRam: qdrant.PtrOf(true),
},
),
})
bits - the encoding bit depth. Defaults to bits4. Available values: bits4, bits2, bits1_5, and bits1. Lower bit depths offer higher compression at the cost of accuracy.
always_ram - whether to keep quantized vectors always cached in RAM or not. By default, quantized vectors are loaded in the same way as the original vectors. Set always_ram to true to store quantized vectors in RAM.
Select a Bit Depth
To use a specific compression level, set the bits parameter:
PUT /collections/{collection_name}
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"quantization_config": {
"turbo": {
"bits": "bits2",
"always_ram": true
}
}
}
from qdrant_client import QdrantClient, models
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),
quantization_config=models.TurboQuantization(
turbo=models.TurboQuantQuantizationConfig(
always_ram=True,
bits=models.TurboQuantBitSize.BITS2,
),
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
client.createCollection("{collection_name}", {
vectors: {
size: 1536,
distance: "Cosine",
},
quantization_config: {
turbo: {
always_ram: true,
bits: "bits2",
},
},
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, Distance, TurboQuantBitSize, TurboQuantizationBuilder,
VectorParamsBuilder,
};
use qdrant_client::Qdrant;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(1536, Distance::Cosine))
.quantization_config(
TurboQuantizationBuilder::new()
.always_ram(true)
.bits(TurboQuantBitSize::Bits2),
),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.TurboQuantBitSize;
import io.qdrant.client.grpc.Collections.TurboQuantization;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(1536)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setTurboquant(
TurboQuantization.newBuilder()
.setAlwaysRam(true)
.setBits(TurboQuantBitSize.Bits2)
.build())
.build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 1536, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Turboquant = new TurboQuantization { AlwaysRam = true, Bits = TurboQuantBitSize.Bits2 }
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 1536,
Distance: qdrant.Distance_Cosine,
}),
QuantizationConfig: qdrant.NewQuantizationTurbo(
&qdrant.TurboQuantization{
AlwaysRam: qdrant.PtrOf(true),
Bits: qdrant.TurboQuantBitSize_Bits2.Enum(),
},
),
})
Setting Up Scalar Quantization
To enable scalar quantization, you need to specify the quantization parameters in the quantization_config section of the collection configuration.
When enabling scalar quantization on an existing collection, use a PATCH request or the corresponding update_collection method and omit the vector configuration, as it’s already defined.
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"quantization_config": {
"scalar": {
"type": "int8",
"quantile": 0.99,
"always_ram": true
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8,
quantile=0.99,
always_ram=True,
),
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
quantization_config: {
scalar: {
type: "int8",
quantile: 0.99,
always_ram: true,
},
},
});
use qdrant_client::qdrant::{
CreateCollectionBuilder, Distance, QuantizationType, ScalarQuantizationBuilder,
VectorParamsBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(768, Distance::Cosine))
.quantization_config(
ScalarQuantizationBuilder::default()
.r#type(QuantizationType::Int8.into())
.quantile(0.99)
.always_ram(true),
),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.QuantizationType;
import io.qdrant.client.grpc.Collections.ScalarQuantization;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setScalar(
ScalarQuantization.newBuilder()
.setType(QuantizationType.Int8)
.setQuantile(0.99f)
.setAlwaysRam(true)
.build())
.build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Scalar = new ScalarQuantization
{
Type = QuantizationType.Int8,
Quantile = 0.99f,
AlwaysRam = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 768,
Distance: qdrant.Distance_Cosine,
}),
QuantizationConfig: qdrant.NewQuantizationScalar(
&qdrant.ScalarQuantization{
Type: qdrant.QuantizationType_Int8,
Quantile: qdrant.PtrOf(float32(0.99)),
AlwaysRam: qdrant.PtrOf(true),
},
),
})
There are 3 parameters that you can specify in the quantization_config section:
type - the type of the quantized vector components. Currently, Qdrant supports only int8.
quantile - the quantile of the quantized vector components.
The quantile is used to calculate the quantization bounds.
For instance, if you specify 0.99 as the quantile, 1% of extreme values will be excluded from the quantization bounds.
Using quantiles lower than 1.0 might be useful if there are outliers in your vector components.
This parameter only affects the resulting precision and not the memory footprint.
It might be worth tuning this parameter if you experience a significant decrease in search quality.
always_ram - whether to keep quantized vectors always cached in RAM or not. By default, quantized vectors are loaded in the same way as the original vectors.
However, in some setups you might want to keep quantized vectors in RAM to speed up the search process.
In this case, you can set always_ram to true to store quantized vectors in RAM.
Setting Up Binary Quantization
To enable binary quantization, you need to specify the quantization parameters in the quantization_config section of the collection configuration.
When enabling binary quantization on an existing collection, use a PATCH request or the corresponding update_collection method and omit the vector configuration, as it’s already defined.
PUT /collections/{collection_name}
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"quantization_config": {
"binary": {
"always_ram": true
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
always_ram=True,
),
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 1536,
distance: "Cosine",
},
quantization_config: {
binary: {
always_ram: true,
},
},
});
use qdrant_client::qdrant::{
BinaryQuantizationBuilder, CreateCollectionBuilder, Distance, VectorParamsBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(1536, Distance::Cosine))
.quantization_config(BinaryQuantizationBuilder::new(true)),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.BinaryQuantization;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(1536)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setBinary(BinaryQuantization.newBuilder().setAlwaysRam(true).build())
.build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 1536, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Binary = new BinaryQuantization { AlwaysRam = true }
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 1536,
Distance: qdrant.Distance_Cosine,
}),
QuantizationConfig: qdrant.NewQuantizationBinary(
&qdrant.BinaryQuantization{
AlwaysRam: qdrant.PtrOf(true),
},
),
})
always_ram - whether to keep quantized vectors always cached in RAM or not. By default, quantized vectors are loaded in the same way as the original vectors.
However, in some setups you might want to keep quantized vectors in RAM to speed up the search process.
In this case, you can set always_ram to true to store quantized vectors in RAM.
Set Up Bit Depth
To enable 2bit or 1.5bit quantization, you need to specify encoding parameter in the quantization_config section of the collection configuration. Available values are two_bits and one_and_half_bits.
PUT /collections/{collection_name}
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"quantization_config": {
"binary": {
"encoding": "two_bits",
"always_ram": true
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
encoding=models.BinaryQuantizationEncoding.TWO_BITS,
always_ram=True,
),
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 1536,
distance: "Cosine",
},
quantization_config: {
binary: {
encoding: "two_bits",
always_ram: true,
},
},
});
use qdrant_client::qdrant::{
BinaryQuantizationBuilder,
CreateCollectionBuilder,
Distance,
VectorParamsBuilder,
BinaryQuantizationEncoding,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(1536, Distance::Cosine))
.quantization_config(BinaryQuantizationBuilder::new(true)
.encoding(BinaryQuantizationEncoding::TwoBits)
),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.BinaryQuantization;
import io.qdrant.client.grpc.Collections.BinaryQuantizationEncoding;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(1536)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setBinary(BinaryQuantization
.newBuilder()
.setEncoding(BinaryQuantizationEncoding.TwoBits)
.setAlwaysRam(true)
.build())
.build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 1536, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Binary = new BinaryQuantization {
Encoding = BinaryQuantizationEncoding.TwoBits,
AlwaysRam = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 1536,
Distance: qdrant.Distance_Cosine,
}),
QuantizationConfig: qdrant.NewQuantizationBinary(
&qdrant.BinaryQuantization{
Encoding: qdrant.BinaryQuantizationEncoding_TwoBits.Enum(),
AlwaysRam: qdrant.PtrOf(true),
},
),
})
Set Up Asymmetric Quantization
To enable asymmetric quantization, you need to specify query_encoding parameter in the quantization_config section of the collection configuration. Available values are:
defaultandbinary- use regular binary quantization for the query.scalar8bits- use 8bit quantization for the query.scalar4bits- use 4bit quantization for the query.
PUT /collections/{collection_name}
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"quantization_config": {
"binary": {
"query_encoding": "scalar8bits",
"always_ram": true
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(
query_encoding=models.BinaryQuantizationQueryEncoding.SCALAR8BITS,
always_ram=True,
),
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 1536,
distance: "Cosine",
},
quantization_config: {
binary: {
query_encoding: "scalar8bits",
always_ram: true,
},
},
});
use qdrant_client::qdrant::{
BinaryQuantizationBuilder,
CreateCollectionBuilder,
Distance,
VectorParamsBuilder,
BinaryQuantizationQueryEncoding,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(1536, Distance::Cosine))
.quantization_config(
BinaryQuantizationBuilder::new(true)
.query_encoding(BinaryQuantizationQueryEncoding::scalar8bits())
),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.BinaryQuantization;
import io.qdrant.client.grpc.Collections.BinaryQuantizationQueryEncoding;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(1536)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setBinary(BinaryQuantization.newBuilder()
.setQueryEncoding(BinaryQuantizationQueryEncoding
.newBuilder()
.setSetting(BinaryQuantizationQueryEncoding.Setting.Scalar8Bits)
.build())
.setAlwaysRam(true)
.build())
.build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 1536, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Binary = new BinaryQuantization {
QueryEncoding = new BinaryQuantizationQueryEncoding
{
Setting = BinaryQuantizationQueryEncoding.Types.Setting.Scalar8Bits,
},
AlwaysRam = true
}
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 1536,
Distance: qdrant.Distance_Cosine,
}),
QuantizationConfig: qdrant.NewQuantizationBinary(
&qdrant.BinaryQuantization{
QueryEncoding: qdrant.NewBinaryQuantizationQueryEncodingSetting(qdrant.BinaryQuantizationQueryEncoding_Scalar8Bits),
AlwaysRam: qdrant.PtrOf(true),
},
),
})
Setting Up Product Quantization
To enable product quantization, you need to specify the quantization parameters in the quantization_config section of the collection configuration.
When enabling product quantization on an existing collection, use a PATCH request or the corresponding update_collection method and omit the vector configuration, as it’s already defined.
PUT /collections/{collection_name}
{
"vectors": {
"size": 768,
"distance": "Cosine"
},
"quantization_config": {
"product": {
"compression": "x16",
"always_ram": true
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
quantization_config=models.ProductQuantization(
product=models.ProductQuantizationConfig(
compression=models.CompressionRatio.X16,
always_ram=True,
),
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 768,
distance: "Cosine",
},
quantization_config: {
product: {
compression: "x16",
always_ram: true,
},
},
});
use qdrant_client::qdrant::{
CompressionRatio, CreateCollectionBuilder, Distance, ProductQuantizationBuilder,
VectorParamsBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.vectors_config(VectorParamsBuilder::new(768, Distance::Cosine))
.quantization_config(
ProductQuantizationBuilder::new(CompressionRatio::X16.into()).always_ram(true),
),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CompressionRatio;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.ProductQuantization;
import io.qdrant.client.grpc.Collections.QuantizationConfig;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(
VectorsConfig.newBuilder()
.setParams(
VectorParams.newBuilder()
.setSize(768)
.setDistance(Distance.Cosine)
.build())
.build())
.setQuantizationConfig(
QuantizationConfig.newBuilder()
.setProduct(
ProductQuantization.newBuilder()
.setCompression(CompressionRatio.x16)
.setAlwaysRam(true)
.build())
.build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine },
quantizationConfig: new QuantizationConfig
{
Product = new ProductQuantization { Compression = CompressionRatio.X16, AlwaysRam = true }
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 768,
Distance: qdrant.Distance_Cosine,
}),
QuantizationConfig: qdrant.NewQuantizationProduct(
&qdrant.ProductQuantization{
Compression: qdrant.CompressionRatio_x16,
AlwaysRam: qdrant.PtrOf(true),
},
),
})
There are two parameters that you can specify in the quantization_config section:
compression - compression ratio.
Compression ratio represents the size of the quantized vector in bytes divided by the size of the original vector in bytes.
In this case, the quantized vector will be 16 times smaller than the original vector.
always_ram - whether to keep quantized vectors always cached in RAM or not. By default, quantized vectors are loaded in the same way as the original vectors.
However, in some setups you might want to keep quantized vectors in RAM to speed up the search process. Then set always_ram to true.
Disabling Quantization
To disable quantization in an existing collection, you can do the following:
PATCH /collections/{collection_name}
{
"quantization_config": "Disabled"
}
curl -X PATCH http://localhost:6333/collections/{collection_name} \
-H 'Content-Type: application/json' \
--data-raw '{
"quantization_config": "Disabled"
}'
client.update_collection(
collection_name="{collection_name}",
quantization_config=models.Disabled.DISABLED,
)
client.updateCollection("{collection_name}", {
quantization_config: 'Disabled'
});
use qdrant_client::qdrant::{Disabled, UpdateCollectionBuilder};
client
.update_collection(UpdateCollectionBuilder::new("{collection_name}").quantization_config(Disabled {}))
.await?;
import io.qdrant.client.grpc.Collections.Disabled;
import io.qdrant.client.grpc.Collections.QuantizationConfigDiff;
import io.qdrant.client.grpc.Collections.UpdateCollection;
client.updateCollectionAsync(
UpdateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setQuantizationConfig(
QuantizationConfigDiff.newBuilder()
.setDisabled(Disabled.getDefaultInstance())
.build())
.build());
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.UpdateCollectionAsync(
collectionName: "{collection_name}",
quantizationConfig: new QuantizationConfigDiff { Disabled = new Disabled() }
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.UpdateCollection(context.Background(), &qdrant.UpdateCollection{
CollectionName: "{collection_name}",
QuantizationConfig: qdrant.NewQuantizationDiffDisabled(),
})
Searching with Quantization
Once you have configured quantization for a collection, you don’t need to do anything extra to search with quantization. Qdrant will automatically use quantized vectors if they are available.
However, there are a few options that you can use to control the search process:
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.7],
"params": {
"quantization": {
"ignore": false,
"rescore": true,
"oversampling": 2.0
}
},
"limit": 10
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(
ignore=False,
rescore=True,
oversampling=2.0,
)
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
params: {
quantization: {
ignore: false,
rescore: true,
oversampling: 2.0,
},
},
limit: 10,
});
use qdrant_client::qdrant::{
QuantizationSearchParamsBuilder, QueryPointsBuilder, SearchParamsBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(10)
.params(
SearchParamsBuilder::default().quantization(
QuantizationSearchParamsBuilder::default()
.ignore(false)
.rescore(true)
.oversampling(2.0),
),
),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QuantizationSearchParams;
import io.qdrant.client.grpc.Points.QueryPoints;
import io.qdrant.client.grpc.Points.SearchParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setParams(
SearchParams.newBuilder()
.setQuantization(
QuantizationSearchParams.newBuilder()
.setIgnore(false)
.setRescore(true)
.setOversampling(2.0)
.build())
.build())
.setLimit(10)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
searchParams: new SearchParams
{
Quantization = new QuantizationSearchParams
{
Ignore = false,
Rescore = true,
Oversampling = 2.0
}
},
limit: 10
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
Params: &qdrant.SearchParams{
Quantization: &qdrant.QuantizationSearchParams{
Ignore: qdrant.PtrOf(false),
Rescore: qdrant.PtrOf(true),
Oversampling: qdrant.PtrOf(2.0),
},
},
})
ignore - Toggle whether to ignore quantized vectors during the search process. By default, Qdrant will use quantized vectors if they are available.
rescore - Qdrant can re-evaluate top-k search results using the original vectors. While this can improve search quality, it may decrease search speed, especially if the original vectors are stored on disk. In such cases, it is recommended to disable rescoring. By default, rescoring is only enabled for four quantization methods: binary quantization, TurboQuant 1 Bit, TurboQuant 1.5 Bit, and TurboQuant 2 Bit. Other quantization methods do not rescore by default.
Available as of v1.3.0
oversampling - Defines how many extra vectors should be pre-selected using quantized index, and then re-scored using original vectors.
For example, if oversampling is 2.4 and limit is 100, then 240 vectors will be pre-selected using quantized index, and then top-100 will be returned after re-scoring.
Oversampling is useful if you want to tune the tradeoff between search speed and search quality in the query time.
Quantization Tips
Accuracy Tuning
In this section, we will discuss how to tune the search precision. The fastest way to understand the impact of quantization on the search quality is to compare the search results with and without quantization.
In order to disable quantization, you can set ignore to true in the search request:
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.7],
"params": {
"quantization": {
"ignore": true
}
},
"limit": 10
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
search_params=models.SearchParams(
quantization=models.QuantizationSearchParams(
ignore=True,
)
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
params: {
quantization: {
ignore: true,
},
},
});
use qdrant_client::qdrant::{
QuantizationSearchParamsBuilder, QueryPointsBuilder, SearchParamsBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(3)
.params(
SearchParamsBuilder::default()
.quantization(QuantizationSearchParamsBuilder::default().ignore(true)),
),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QuantizationSearchParams;
import io.qdrant.client.grpc.Points.QueryPoints;
import io.qdrant.client.grpc.Points.SearchParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setParams(
SearchParams.newBuilder()
.setQuantization(
QuantizationSearchParams.newBuilder().setIgnore(true).build())
.build())
.setLimit(10)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
searchParams: new SearchParams
{
Quantization = new QuantizationSearchParams { Ignore = true }
},
limit: 10
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
Params: &qdrant.SearchParams{
Quantization: &qdrant.QuantizationSearchParams{
Ignore: qdrant.PtrOf(false),
},
},
})
Adjust the quantile parameter: The quantile parameter in scalar quantization determines the quantization bounds. By setting it to a value lower than 1.0, you can exclude extreme values (outliers) from the quantization bounds. For example, if you set the quantile to 0.99, 1% of the extreme values will be excluded. By adjusting the quantile, you find an optimal value that will provide the best search quality for your collection.
Enable rescoring: Qdrant can re-evaluate top-k search results using the original vectors. While this can improve search quality, it may decrease search speed, especially if the original vectors are stored on disk. In such cases, it is recommended to disable rescoring. By default, rescoring is only enabled for four quantization methods: binary quantization, TurboQuant 1 Bit, TurboQuant 1.5 Bit, and TurboQuant 2 Bit. Other quantization methods do not rescore by default.
Memory and Speed Tuning
In this section, we will discuss how to tune the memory and speed of the search process with quantization.
There are 3 possible modes to place storage of vectors within the qdrant collection:
All in RAM - all vectors, original and quantized, are loaded and kept in RAM. This is the fastest mode, but requires a lot of RAM. Enabled by default.
Original on Disk, quantized in RAM - this is a hybrid mode that provides a good balance between speed and memory usage. It is recommended if you are aiming to shrink the memory footprint while keeping the search speed.
This mode is enabled by setting
always_ramtotruein the quantization config while using memmap storage:PUT /collections/{collection_name} { "vectors": { "size": 768, "distance": "Cosine", "on_disk": true }, "quantization_config": { "scalar": { "type": "int8", "always_ram": true } } }from qdrant_client import QdrantClient, models client = QdrantClient(url="http://localhost:6333") client.create_collection( collection_name="{collection_name}", vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE, on_disk=True), quantization_config=models.ScalarQuantization( scalar=models.ScalarQuantizationConfig( type=models.ScalarType.INT8, always_ram=True, ), ), )import { QdrantClient } from "@qdrant/js-client-rest"; const client = new QdrantClient({ host: "localhost", port: 6333 }); client.createCollection("{collection_name}", { vectors: { size: 768, distance: "Cosine", on_disk: true, }, quantization_config: { scalar: { type: "int8", always_ram: true, }, }, });use qdrant_client::qdrant::{ CreateCollectionBuilder, Distance, QuantizationType, ScalarQuantizationBuilder, VectorParamsBuilder, }; use qdrant_client::Qdrant; let client = Qdrant::from_url("http://localhost:6334").build()?; client .create_collection( CreateCollectionBuilder::new("{collection_name}") .vectors_config(VectorParamsBuilder::new(768, Distance::Cosine)) .quantization_config( ScalarQuantizationBuilder::default() .r#type(QuantizationType::Int8.into()) .always_ram(true), ), ) .await?;import io.qdrant.client.QdrantClient; import io.qdrant.client.QdrantGrpcClient; import io.qdrant.client.grpc.Collections.CreateCollection; import io.qdrant.client.grpc.Collections.Distance; import io.qdrant.client.grpc.Collections.OptimizersConfigDiff; import io.qdrant.client.grpc.Collections.QuantizationConfig; import io.qdrant.client.grpc.Collections.QuantizationType; import io.qdrant.client.grpc.Collections.ScalarQuantization; import io.qdrant.client.grpc.Collections.VectorParams; import io.qdrant.client.grpc.Collections.VectorsConfig; QdrantClient client = new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build()); client .createCollectionAsync( CreateCollection.newBuilder() .setCollectionName("{collection_name}") .setVectorsConfig( VectorsConfig.newBuilder() .setParams( VectorParams.newBuilder() .setSize(768) .setDistance(Distance.Cosine) .setOnDisk(true) .build()) .build()) .setQuantizationConfig( QuantizationConfig.newBuilder() .setScalar( ScalarQuantization.newBuilder() .setType(QuantizationType.Int8) .setAlwaysRam(true) .build()) .build()) .build()) .get();using Qdrant.Client; using Qdrant.Client.Grpc; var client = new QdrantClient("localhost", 6334); await client.CreateCollectionAsync( collectionName: "{collection_name}", vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine, OnDisk = true }, quantizationConfig: new QuantizationConfig { Scalar = new ScalarQuantization { Type = QuantizationType.Int8, AlwaysRam = true } } );import ( "context" "github.com/qdrant/go-client/qdrant" ) client, err := qdrant.NewClient(&qdrant.Config{ Host: "localhost", Port: 6334, }) client.CreateCollection(context.Background(), &qdrant.CreateCollection{ CollectionName: "{collection_name}", VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{ Size: 768, Distance: qdrant.Distance_Cosine, OnDisk: qdrant.PtrOf(true), }), QuantizationConfig: qdrant.NewQuantizationScalar(&qdrant.ScalarQuantization{ Type: qdrant.QuantizationType_Int8, AlwaysRam: qdrant.PtrOf(true), }), })In this scenario, the number of disk reads may play a significant role in the search speed. In a system with high disk latency, the re-scoring step may become a bottleneck.
Consider disabling
rescoreto improve the search speed:POST /collections/{collection_name}/points/query { "query": [0.2, 0.1, 0.9, 0.7], "params": { "quantization": { "rescore": false } }, "limit": 10 }from qdrant_client import QdrantClient, models client = QdrantClient(url="http://localhost:6333") client.query_points( collection_name="{collection_name}", query=[0.2, 0.1, 0.9, 0.7], search_params=models.SearchParams( quantization=models.QuantizationSearchParams(rescore=False) ), )import { QdrantClient } from "@qdrant/js-client-rest"; const client = new QdrantClient({ host: "localhost", port: 6333 }); client.query("{collection_name}", { query: [0.2, 0.1, 0.9, 0.7], params: { quantization: { rescore: false, }, }, });use qdrant_client::qdrant::{ QuantizationSearchParamsBuilder, QueryPointsBuilder, SearchParamsBuilder, }; use qdrant_client::Qdrant; let client = Qdrant::from_url("http://localhost:6334").build()?; client .query( QueryPointsBuilder::new("{collection_name}") .query(vec![0.2, 0.1, 0.9, 0.7]) .limit(3) .params( SearchParamsBuilder::default() .quantization(QuantizationSearchParamsBuilder::default().rescore(false)), ), ) .await?;import static io.qdrant.client.QueryFactory.nearest; import io.qdrant.client.QdrantClient; import io.qdrant.client.QdrantGrpcClient; import io.qdrant.client.grpc.Points.QuantizationSearchParams; import io.qdrant.client.grpc.Points.QueryPoints; import io.qdrant.client.grpc.Points.SearchParams; QdrantClient client = new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build()); client.queryAsync( QueryPoints.newBuilder() .setCollectionName("{collection_name}") .setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f)) .setParams( SearchParams.newBuilder() .setQuantization( QuantizationSearchParams.newBuilder().setRescore(false).build()) .build()) .setLimit(3) .build()) .get();using Qdrant.Client; using Qdrant.Client.Grpc; var client = new QdrantClient("localhost", 6334); await client.QueryAsync( collectionName: "{collection_name}", query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f }, searchParams: new SearchParams { Quantization = new QuantizationSearchParams { Rescore = false } }, limit: 3 );import ( "context" "github.com/qdrant/go-client/qdrant" ) client, err := qdrant.NewClient(&qdrant.Config{ Host: "localhost", Port: 6334, }) client.Query(context.Background(), &qdrant.QueryPoints{ CollectionName: "{collection_name}", Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7), Params: &qdrant.SearchParams{ Quantization: &qdrant.QuantizationSearchParams{ Rescore: qdrant.PtrOf(false), }, }, })All on Disk - all vectors, original and quantized, are stored on disk. This mode achieves the smallest memory footprint, but at the cost of search speed.
It is recommended to use this mode if you have a large collection and fast storage (e.g. SSD or NVMe).
This mode is enabled by setting
always_ramtofalsein the quantization config while using mmap storage:PUT /collections/{collection_name} { "vectors": { "size": 768, "distance": "Cosine", "on_disk": true }, "quantization_config": { "scalar": { "type": "int8", "always_ram": false } } }from qdrant_client import QdrantClient, models client = QdrantClient(url="http://localhost:6333") client.create_collection( collection_name="{collection_name}", vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE, on_disk=True), quantization_config=models.ScalarQuantization( scalar=models.ScalarQuantizationConfig( type=models.ScalarType.INT8, always_ram=False, ), ), )import { QdrantClient } from "@qdrant/js-client-rest"; const client = new QdrantClient({ host: "localhost", port: 6333 }); client.createCollection("{collection_name}", { vectors: { size: 768, distance: "Cosine", on_disk: true, }, quantization_config: { scalar: { type: "int8", always_ram: false, }, }, });use qdrant_client::qdrant::{ CreateCollectionBuilder, Distance, QuantizationType, ScalarQuantizationBuilder, VectorParamsBuilder, }; use qdrant_client::Qdrant; let client = Qdrant::from_url("http://localhost:6334").build()?; client .create_collection( CreateCollectionBuilder::new("{collection_name}") .vectors_config(VectorParamsBuilder::new(768, Distance::Cosine).on_disk(true)) .quantization_config( ScalarQuantizationBuilder::default() .r#type(QuantizationType::Int8.into()) .always_ram(false), ), ) .await?;import io.qdrant.client.QdrantClient; import io.qdrant.client.QdrantGrpcClient; import io.qdrant.client.grpc.Collections.CreateCollection; import io.qdrant.client.grpc.Collections.Distance; import io.qdrant.client.grpc.Collections.OptimizersConfigDiff; import io.qdrant.client.grpc.Collections.QuantizationConfig; import io.qdrant.client.grpc.Collections.QuantizationType; import io.qdrant.client.grpc.Collections.ScalarQuantization; import io.qdrant.client.grpc.Collections.VectorParams; import io.qdrant.client.grpc.Collections.VectorsConfig; QdrantClient client = new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build()); client .createCollectionAsync( CreateCollection.newBuilder() .setCollectionName("{collection_name}") .setVectorsConfig( VectorsConfig.newBuilder() .setParams( VectorParams.newBuilder() .setSize(768) .setDistance(Distance.Cosine) .setOnDisk(true) .build()) .build()) .setQuantizationConfig( QuantizationConfig.newBuilder() .setScalar( ScalarQuantization.newBuilder() .setType(QuantizationType.Int8) .setAlwaysRam(false) .build()) .build()) .build()) .get();using Qdrant.Client; using Qdrant.Client.Grpc; var client = new QdrantClient("localhost", 6334); await client.CreateCollectionAsync( collectionName: "{collection_name}", vectorsConfig: new VectorParams { Size = 768, Distance = Distance.Cosine, OnDisk = true}, quantizationConfig: new QuantizationConfig { Scalar = new ScalarQuantization { Type = QuantizationType.Int8, AlwaysRam = false } } );import ( "context" "github.com/qdrant/go-client/qdrant" ) client, err := qdrant.NewClient(&qdrant.Config{ Host: "localhost", Port: 6334, }) client.CreateCollection(context.Background(), &qdrant.CreateCollection{ CollectionName: "{collection_name}", VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{ Size: 768, Distance: qdrant.Distance_Cosine, OnDisk: qdrant.PtrOf(true), }), QuantizationConfig: qdrant.NewQuantizationScalar( &qdrant.ScalarQuantization{ Type: qdrant.QuantizationType_Int8, AlwaysRam: qdrant.PtrOf(false), }, ), })