
Ever since the data science community discovered that vector search significantly improves LLM answers, various vendors and enthusiasts have been arguing over the proper solutions to store embeddings.
Some say storing them in a specialized engine (aka vector database) is better. Others say that it’s enough to use plugins for existing databases.
This article presents our vision and arguments on the topic . We will:
- Explain why and when you actually need a dedicated vector solution
- Debunk some ungrounded claims and anti-patterns to be avoided when building a vector search system.
A table of contents:
- Each database vendor will sooner or later introduce vector capabilities… [click]
- Having a dedicated vector database requires duplication of data. [click]
- Having a dedicated vector database requires complex data synchronization. [click]
- You have to pay for a vector service uptime and data transfer. [click]
- What is more seamless than your current database adding vector search capability? [click]
- Databases can support RAG use-case end-to-end. [click]
Responding to claims
Each database vendor will sooner or later introduce vector capabilities. That will make every database a Vector Database.
The origins of this misconception lie in the careless use of the term Vector Database. When we think of a database, we subconsciously envision a relational database like Postgres or MySQL. Or, more scientifically, a service built on ACID principles that provides transactions, strong consistency guarantees, and atomicity.
The majority of Vector Database are not databases in this sense. It is more accurate to call them search engines, but unfortunately, the marketing term vector database has already stuck, and it is unlikely to change.
What makes search engines different, and why vector DBs are built as search engines?
First of all, search engines assume different patterns of workloads and prioritize different properties of the system. The core architecture of such solutions is built around those priorities.
What types of properties do search engines prioritize?
- Scalability. Search engines are built to handle large amounts of data and queries. They are designed to be horizontally scalable and operate with more data than can fit into a single machine.
- Search speed. Search engines should guarantee low latency for queries, while the atomicity of updates is less important.
- Availability. Search engines must stay available if the majority of the nodes in a cluster are down. At the same time, they can tolerate the eventual consistency of updates.
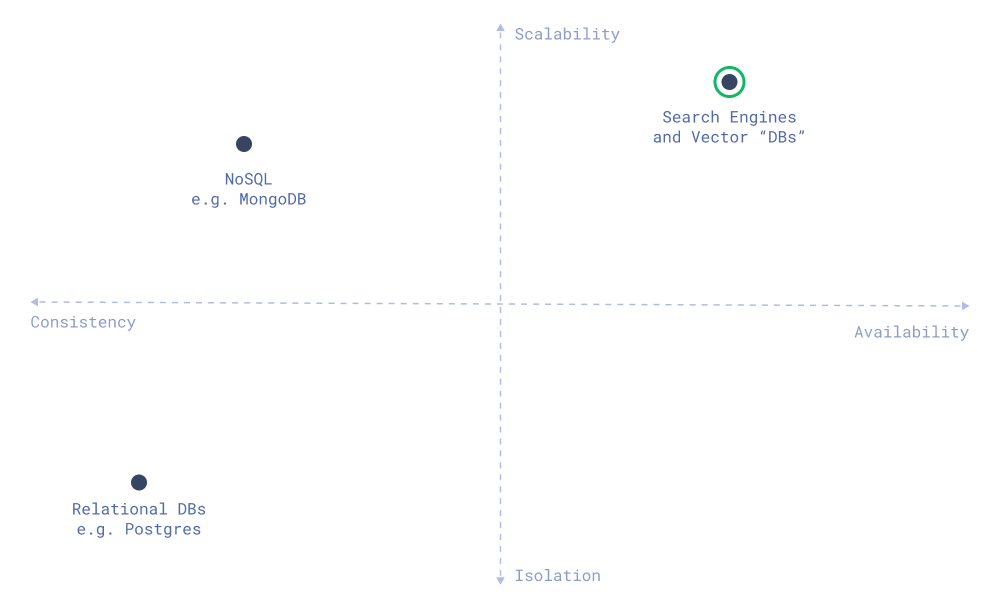
Database guarantees compass
Those priorities lead to different architectural decisions that are not reproducible in a general-purpose database, even if it has vector index support.
Having a dedicated vector database requires duplication of data.
By their very nature, vector embeddings are derivatives of the primary source data.
In the vast majority of cases, embeddings are derived from some other data, such as text, images, or additional information stored in your system. So, in fact, all embeddings you have in your system can be considered transformations of some original source.
And the distinguishing feature of derivative data is that it will change when the transformation pipeline changes. In the case of vector embeddings, the scenario of those changes is quite simple: every time you update the encoder model, all the embeddings will change.
In systems where vector embeddings are fused with the primary data source, it is impossible to perform such migrations without significantly affecting the production system.
As a result, even if you want to use a single database for storing all kinds of data, you would still need to duplicate data internally.
Having a dedicated vector database requires complex data synchronization.
Most production systems prefer to isolate different types of workloads into separate services. In many cases, those isolated services are not even related to search use cases.
For example, databases for analytics and one for serving can be updated from the same source. Yet they can store and organize the data in a way that is optimal for their typical workloads.
Search engines are usually isolated for the same reason: you want to avoid creating a noisy neighbor problem and compromise the performance of your main database.
To give you some intuition, let’s consider a practical example:
Assume we have a database with 1 million records. This is a small database by modern standards of any relational database. You can probably use the smallest free tier of any cloud provider to host it.
But if we want to use this database for vector search, 1 million OpenAI text-embedding-ada-002 embeddings will take ~6GB of RAM (sic!).
As you can see, the vector search use case completely overwhelmed the main database resource requirements.
In practice, this means that your main database becomes burdened with high memory requirements and can not scale efficiently, limited by the size of a single machine.
Fortunately, the data synchronization problem is not new and definitely not unique to vector search. There are many well-known solutions, starting with message queues and ending with specialized ETL tools.
For example, we recently released our integration with Airbyte, allowing you to synchronize data from various sources into Qdrant incrementally.
You have to pay for a vector service uptime and data transfer of both solutions.
In the open-source world, you pay for the resources you use, not the number of different databases you run. Resources depend more on the optimal solution for each use case. As a result, running a dedicated vector search engine can be even cheaper, as it allows optimization specifically for vector search use cases.
For instance, Qdrant implements a number of quantization techniques that can significantly reduce the memory footprint of embeddings.
In terms of data transfer costs, on most cloud providers, network use within a region is usually free. As long as you put the original source data and the vector store in the same region, there are no added data transfer costs.
What is more seamless than your current database adding vector search capability?
In contrast to the short-term attractiveness of integrated solutions, dedicated search engines propose flexibility and a modular approach. You don’t need to update the whole production database each time some of the vector plugins are updated. Maintenance of a dedicated search engine is as isolated from the main database as the data itself.
In fact, integration of more complex scenarios, such as read/write segregation, is much easier with a dedicated vector solution. You can easily build cross-region replication to ensure low latency for your users.
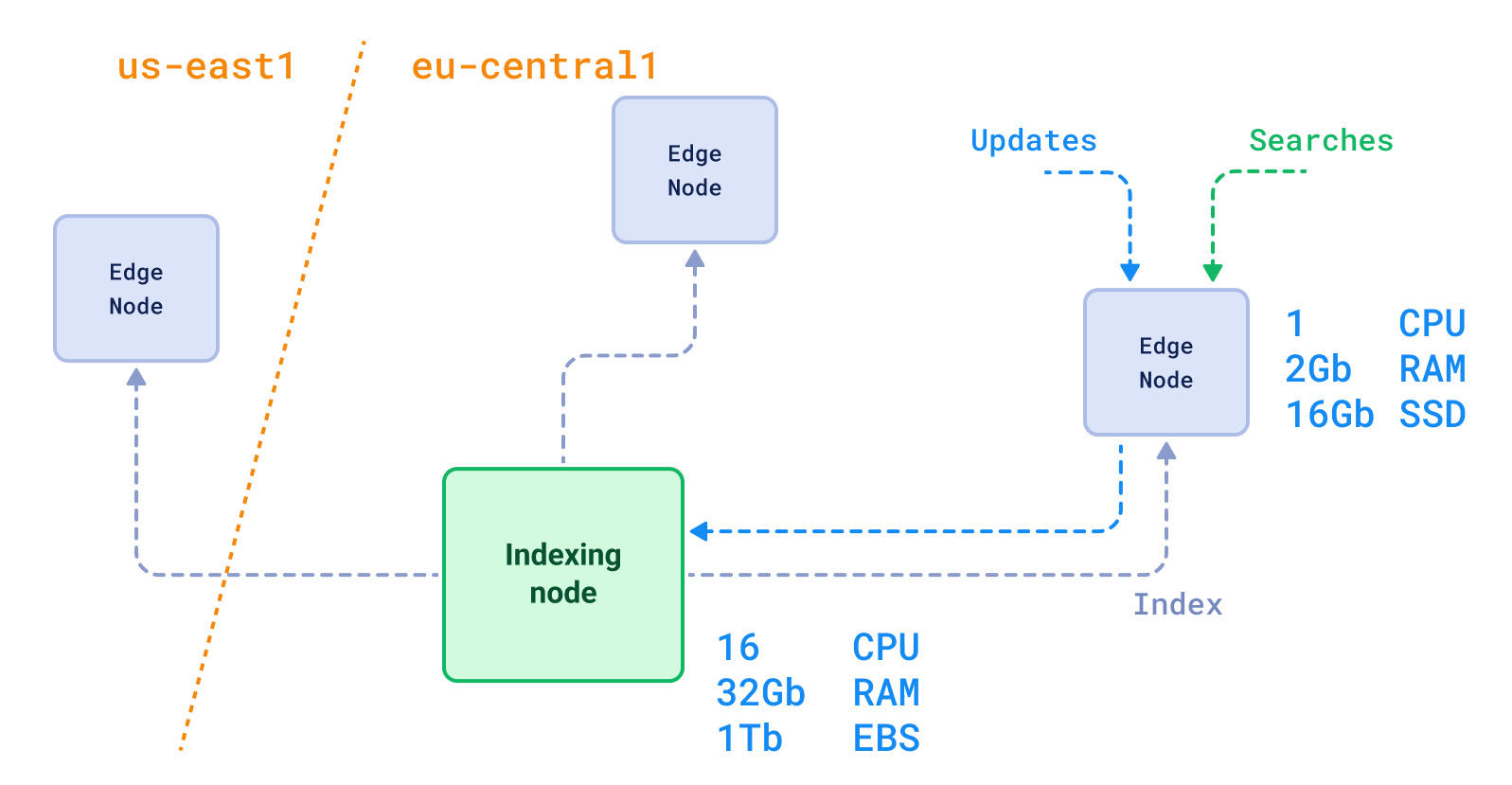
Read/Write segregation + cross-regional deployment
It is especially important in large enterprise organizations, where the responsibility for different parts of the system is distributed among different teams. In those situations, it is much easier to maintain a dedicated search engine for the AI team than to convince the core team to update the whole primary database.
Finally, the vector capabilities of the all-in-one database are tied to the development and release cycle of the entire stack. Their long history of use also means that they need to pay a high price for backward compatibility.
Databases can support RAG use-case end-to-end.
Putting aside performance and scalability questions, the whole discussion about implementing RAG in the DBs assumes that the only detail missing in traditional databases is the vector index and the ability to make fast ANN queries.
In fact, the current capabilities of vector search have only scratched the surface of what is possible. For example, in our recent article, we discuss the possibility of building an exploration API to fuel the discovery process - an alternative to kNN search, where you don’t even know what exactly you are looking for.
Summary
Ultimately, you do not need a vector database if you are looking for a simple vector search functionality with a small amount of data. We genuinely recommend starting with whatever you already have in your stack to prototype. But you need one if you are looking to do more out of it, and it is the central functionality of your application. It is just like using a multi-tool to make something quick or using a dedicated instrument highly optimized for the use case.
Large-scale production systems usually consist of different specialized services and storage types for good reasons since it is one of the best practices of modern software architecture. Comparable to the orchestration of independent building blocks in a microservice architecture.
When you stuff the database with a vector index, you compromise both the performance and scalability of the main database and the vector search capabilities. There is no one-size-fits-all approach that would not compromise on performance or flexibility. So if your use case utilizes vector search in any significant way, it is worth investing in a dedicated vector search engine, aka vector database.