
No matter if you are just beginning your journey in the world of vector search, or you are a seasoned practitioner, you have probably wondered how to choose the right embedding model to achieve the best search quality. There are some public benchmarks, such as MTEB, that can help you narrow down the options, but datasets used in those benchmarks will rarely be representative of your domain-specific data. Moreover, search quality is not the only requirement you could have. For example, some of the best models might be amazingly accurate for retrieval, but you can’t afford to run them, e.g., due to high resource usage or your budget constraints.
Selecting the best embedding model is a multi-objective optimization problem and there is no one-size-fits-all solution, and there probably never will be. In this article, we will try to provide some guidance on how to approach this problem in a practical way, and how to move from model selection to running it in production.
Evaluation: the holy grail of vector search
You can’t improve what you don’t measure. It’s cliché, but it’s true also for retrieval. Search quality might and should be measured not only in a running system, but also before you make the most important decision - which embedding model to use.
Know the language your model speaks
Embedding models are trained with specific languages in mind. When evaluating one, consider whether it supports all the
languages you have or predict to have in your data. If your data is not homogeneous, you might require a multilingual
model that can properly embed text across different languages. If you use Open Source models, then your model is likely
documented on Hugging Face Hub. For example, the popular in demos all-MiniLM-L6-v2 was trained on English data only,
so it’s not a good choice if you have data in other languages.
However, it’s not only about the language, but also about how the model treats the input data. Surprisingly, this is often overlooked. Text embedding models use a specific tokenizer to chunk the input data into pieces, and then starts all the Transformer magic with assigning each token a specific input vector representation.
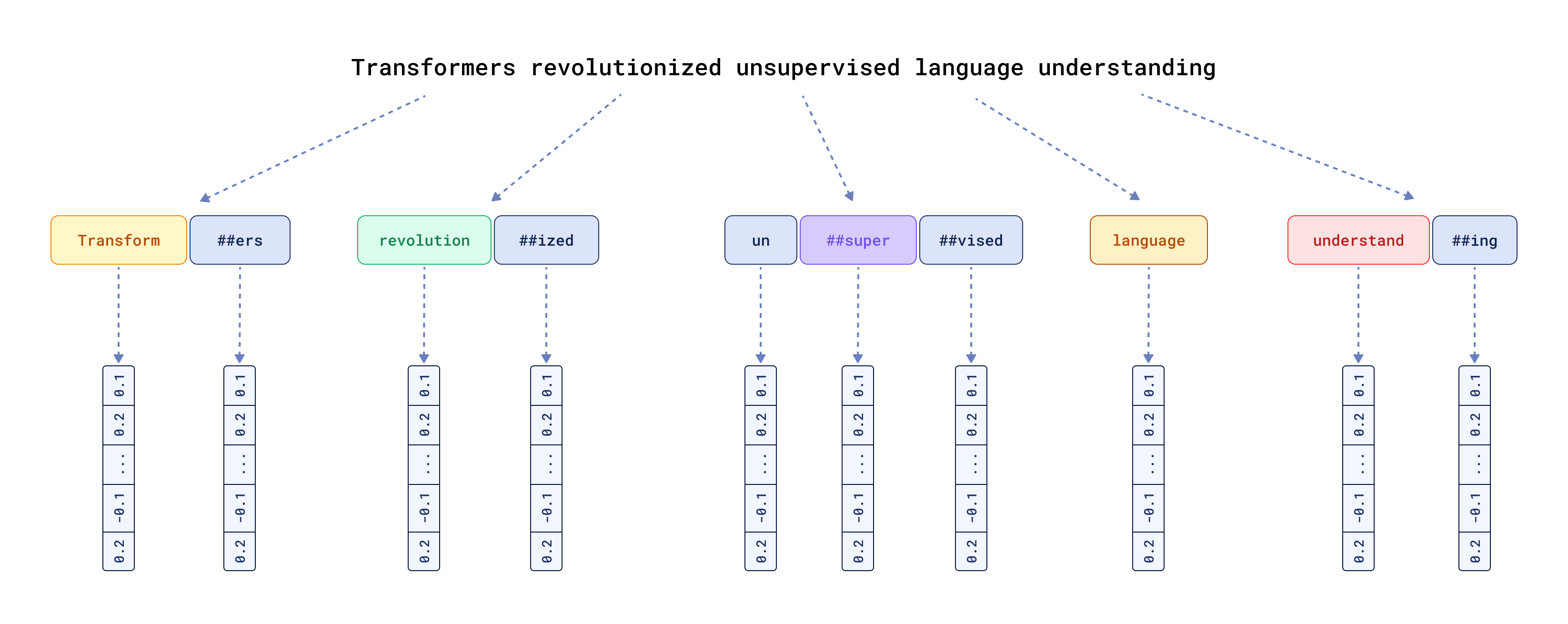
One of the effects of such inner workings is that the model can only understand what its tokenizer was trained on (yes,
tokenizers are also trainable components). As a result,
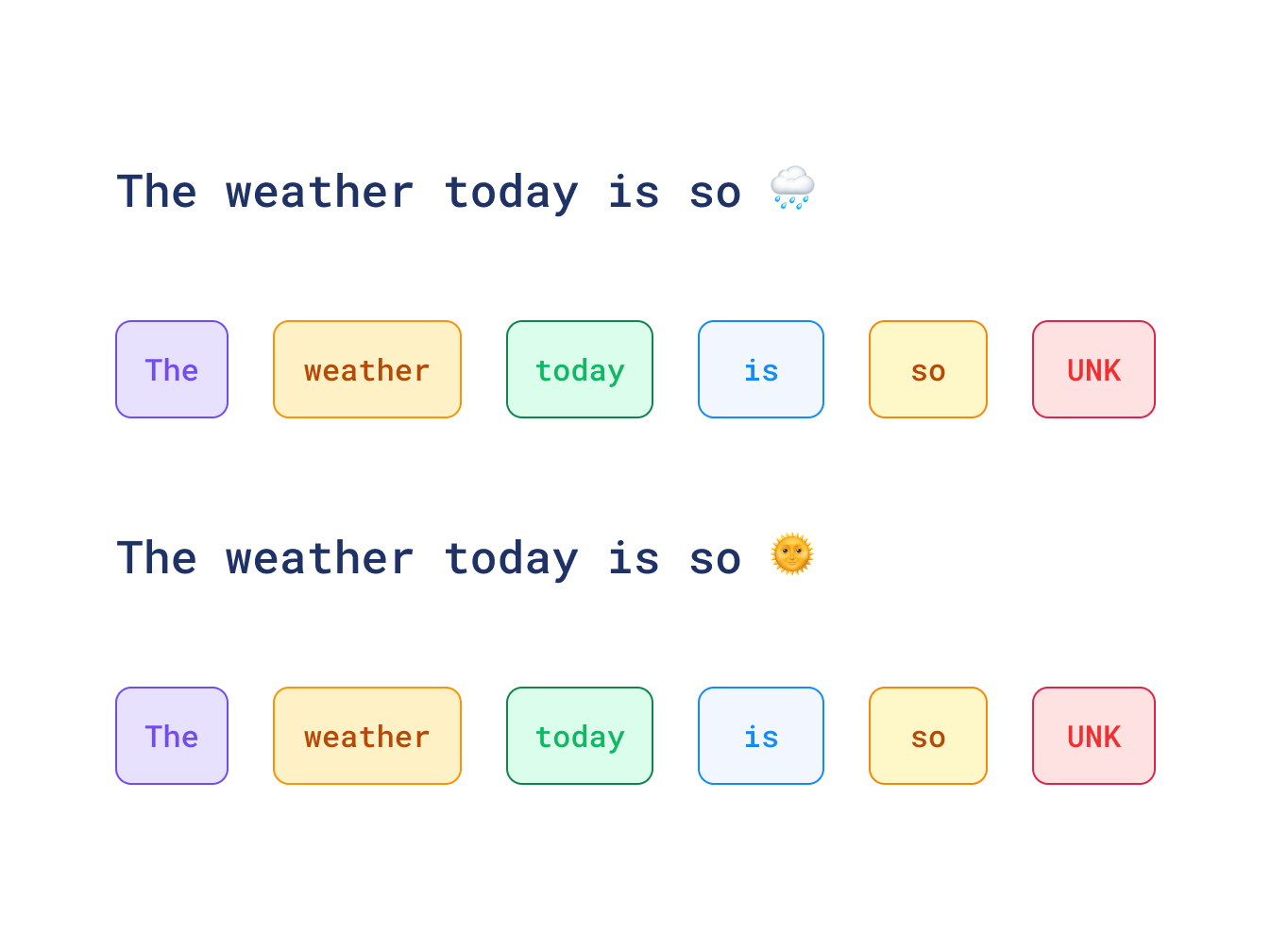
any characters it hasn’t seen during the training will be replaced with a special UNK token. If you analyze social
media data, then you might be surprised that two contradicting sentences are actually perfect matches in your search,
as presented in the following example:
The same may go for accented letters, different alphabets, etc., that dominate in your target language. However, in that case, you shouldn’t be using such a model in the first place, as it does not support your language either way. Tokenization has a bigger impact on the quality of the embeddings than many people think. If you want to understand what the effects of tokenization are, we recommend you take the course on Retrieval Optimization: From Tokenization to Vector Quantization we recorded together with DeepLearning.AI. You may find the course especially interesting if you still wonder why your semantic search engine can’t handle numerical data, such as prices or dates, and what you can do about it.
How do you know if the tokenizer supports the target language? That’s pretty easy for the Open Source models, as you can just run the tokenizer without the model and see how the yielded tokens look like. For the commercial models that might be slightly harder, but companies like OpenAI and Cohere are transparent about it and open source their tokenizers. In the worst case, you can just modify some of the suspected tokens and see how the model reacts in terms of the similarity between the original and modified text.
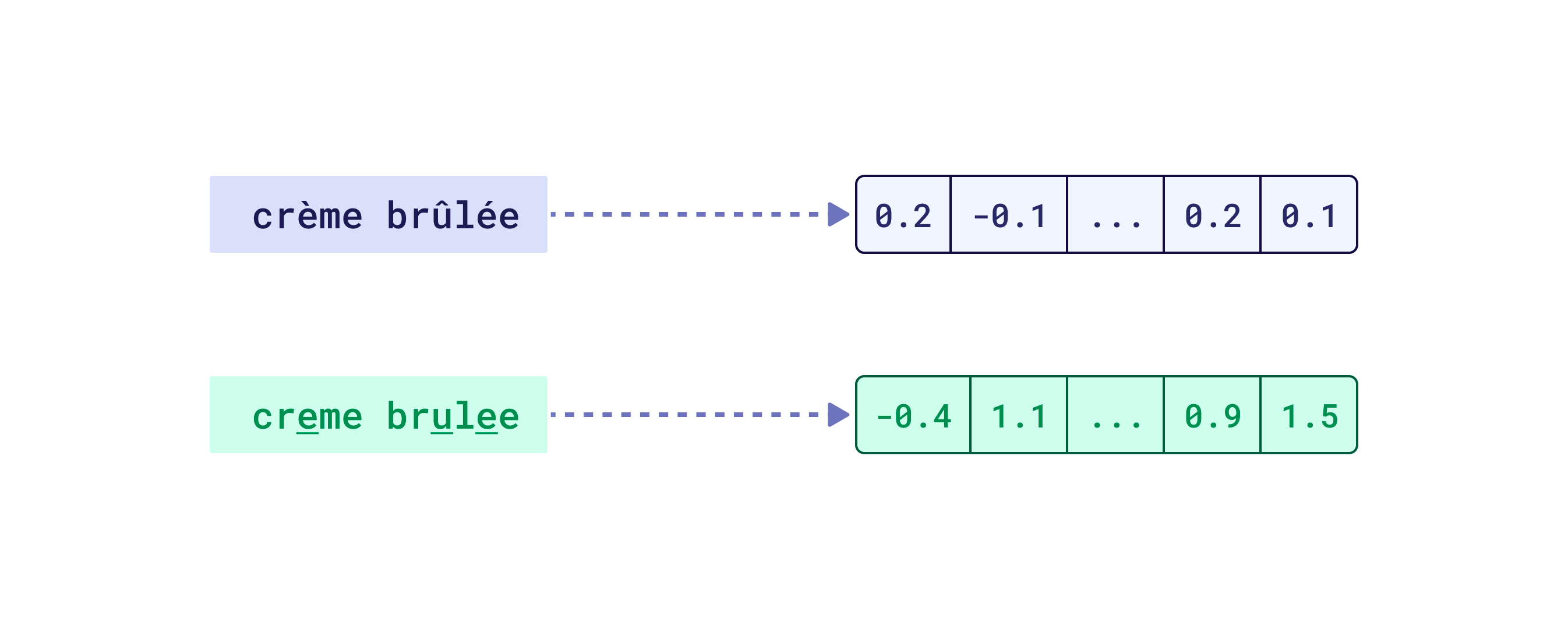
If the created representations are really far from each other in the vector space, it may indicate that some
non-supported characters are replaced with UNK tokens and thus the model can’t properly embed the input data.
Checklist of things to consider
Nevertheless, the evaluation does not focus on the input tokens only. First and foremost, we should measure how well a particular model can handle the task we want to use it for. Vector embeddings are multipurpose tools, and some models might be more suitable for semantic similarity, while others for retrieval or question answering. Nobody, except you, can tell what’s the nature of the problem you are trying to solve. Type of the task is not the only thing to consider when choosing the right embedding model:
- Sequence length - embedding models have a limited input size they can process at a time. Check how long your documents are and how many tokens they contain. If you use Open Source models, you can check the maximum sequence length in the model card on Hugging Face Hub. For commercial models, it’s better to ask the provider directly.
- Model size - larger models have more parameters and require more memory. Inference time also depends on model architecture and your hardware. Some models run effectively only on GPUs, while others can run on CPUs as well.
- Optimization support - not all models are compatible with every optimization technique. For example, Binary Quantization and Matryoshka embeddings require specific model characteristics.
The list is not exhaustive, as there might be plenty of other things to consider, but you get the idea.
That’s why you need to precisely define the task you really want to solve, get your hands dirty with the data the system is supposed to process and build a ground truth dataset for it, so you can make an informed decision.
Building the ground truth dataset
The way your dataset will look like depends on the task you want to evaluate. If we speak about semantic similarity, then you will need pairs of texts with a score indicating how similar they are.
For semantic similarity tasks, your dataset might look like this:
[
{
"text1": "I love this movie, it's fantastic",
"text2": "This film is amazing, I really enjoyed it",
"similarity_score": 0.92
},
{
"text1": "The weather is nice today",
"text2": "I need to buy groceries",
"similarity_score": 0.12
}
]
Most typically, Qdrant users build retrieval systems that they use alone, or combine them with Large Language Models
to build Retrieval Augmented Generation. When we do retrieval, we need a slightly different structure of the golden
dataset than for semantic similarity. The problem of retrieval is to find the K most relevant documents for a given
query. Therefore, we need a set of queries and a set of documents that we would expect to receive for each of them.
There are also three different ways of how to define the relevancy at different granularity levels:
- Binary relevancy - a document is either relevant or not.
- Ordinal relevancy - a document can be more or less relevant (ranking).
- Relevancy with a score - a document can have a score indicating how relevant it is.
[
{
"query": "How do vector databases work?",
"relevant_documents": [
{
"id": "doc_123",
"text": "Vector databases store and index vector embeddings...",
"relevance": 3 // Highly relevant (scale 0-3)
},
{
"id": "doc_456",
"text": "The architecture of modern vector search engines...",
"relevance": 2 // Moderately relevant
}
]
},
{
"query": "Python code example for Qdrant",
"relevant_documents": [
{
"id": "doc_789",
"text": "```python\nfrom qdrant_client import QdrantClient\n...",
"relevance": 3 // Highly relevant
}
]
}
]
Once you have the dataset, you can start evaluating the models using one of the evaluation metrics, such as
precision@k, MRR, or NDCG. There are existing libraries, such as ranx that can
help you with that. Running the evaluation process on various models is a good way to get
a sense of how they perform on your data. You can test even proprietary models that way. However, it’s not the only
thing you should consider when choosing the best model.
Please do not be afraid of building your evaluation dataset. It’s not as complicated as it might seem, and it’s a critical step! You don’t need millions of samples to get a good idea of how the model performs. A few hundred well-curated examples might be a good starting point. Even dozens are better than nothing!
Compute resource constraints
Even if you found the best performing embedding model for your domain, that doesn’t mean you can use it. Software projects do not live in isolation, and you have to consider the bigger picture. For example, you might have budget constraints that limit your choices. It’s also about being pragmatic. If you have a model that is 1% more precise, but it’s 10 times slower and consumes 10 times more resources, is it really worth it?
Eventually, enjoying the journey is more important than reaching the destination in some cases, but that doesn’t hold true for search. The simpler and faster the means that took you there, the better.
Throughput, latency and cost
When selecting an embedding model for production, you need to consider three critical operational factors:
- Throughput: How many embeddings can you generate per second? This directly impacts your system’s ability to handle load. Larger models typically have lower throughput, which might become a bottleneck during data ingestion or high-traffic periods.
- Latency: How quickly can you get a single embedding? For real-time applications like search-as-you-type or interactive chatbots, low latency is crucial. Quantized versions of larger models can offer significant latency improvements.
- Cost: This includes both infrastructure costs (CPU/GPU resources, memory) and, for API-based models, per-token or per-request charges. For example, running your own model might have higher upfront costs but lower per-request costs than some SaaS models.
The right balance depends on your specific use case. A news recommendation system might prioritize throughput for processing large volumes of articles in real-time, while a website search might prioritize latency for real-time results. Similarly, a chatbot using a Large Language Model to generate a response might prioritize cost-effectiveness, as LLMs are often slower and retrieval isn’t the most time-consuming part of the process.
Balancing all aspects
After all these considerations, you should have a table that summarizes each of the models you evaluated under all the different conditions. Now things are getting hard and answers are not obvious anymore.
Here’s an example of how such a comparison table might look:
| Model | Precision@10 | MRR | Inference Time | Memory Usage | Cost | Multilingual | Max Sequence Length |
|---|---|---|---|---|---|---|---|
| expensive-proprietary-saas-only | 0.92 | 0.87 | API-dependent | N/A | $0.25/M tokens | Probably, yet undocumented | 8192 |
| cheaper-proprietary-multilingual | 0.89 | 0.84 | API-dependent | N/A | $0.01/M tokens | Yes (94 languages) | 4096 |
| open-source-gpu-required | 0.88 | 0.83 | 120ms | 15GB | Self-hosted | English | 1024 |
| open-source-on-cpu | 0.85 | 0.79 | 30ms | 120MB | Self-hosted | English | 512 |
The decision process should be guided by your specific requirements. Organizations struggling with budget constraints might lean towards self-hosted options, while those who prefer to avoid dealing with infrastructure management might prefer API-based solutions. Who knows? Maybe your project does not require the highest precision possible, and a smaller model will do the job just fine.
Remember that this doesn’t have to be a one-time decision. As your application evolves, you might need to revisit your choice of the embedding model. Qdrant’s architecture makes it relatively easy to migrate to a different model if needed. Named vectors help to create a system with multiple models and switch between them based on the query, or build a hybrid search that takes advantage of different models or more complex search pipelines.
An important decision to make is also where to host the embedding model. Maybe you prefer not to deal with the infrastructure management and send the data you process in its original form? Qdrant now has something for you!
Locally sourced embeddings
Wouldn’t it be great to run your selected embedding model as close to your search engine as possible? Network latency might be one of the biggest enemies, and transferring millions of vectors over the network may take longer if done from a distant location. Moreover, some of the cloud providers will charge you for the data transfer, so it’s not only about the latency, but also about the cost. Finally, running an embedding model on-premises requires some expertise and resources, and if you want to focus on your core business, you might prefer to avoid that.
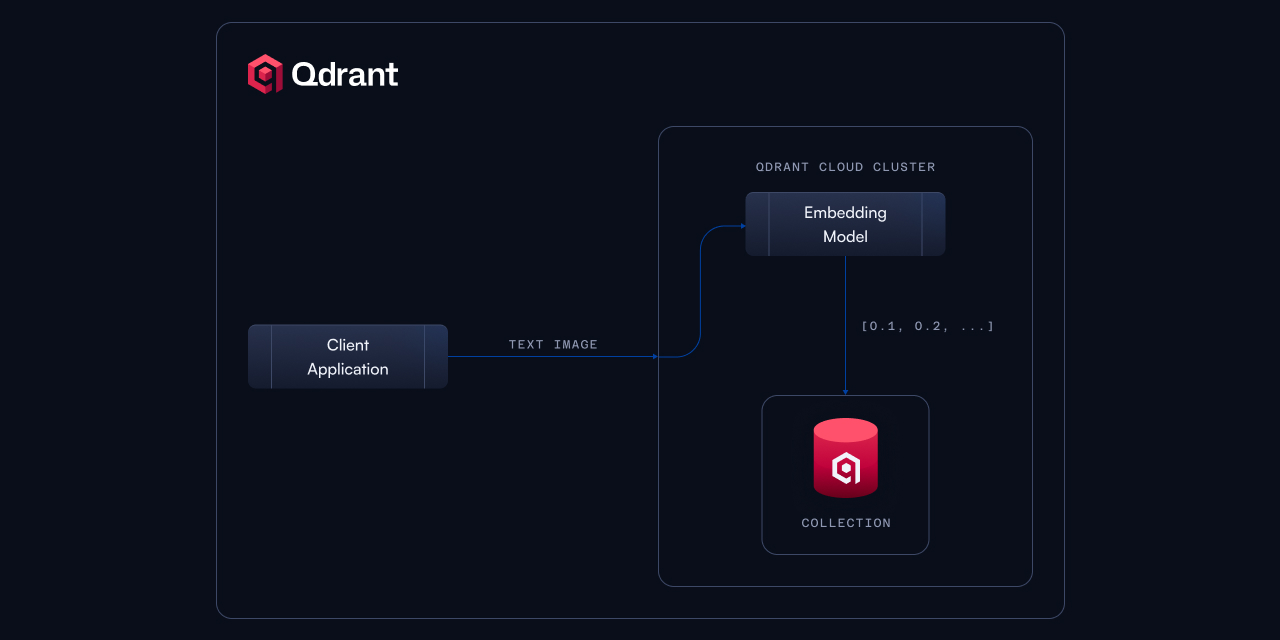
Qdrant’s Cloud Inference solves these problems by allowing you to run the embedding model next to the cluster where your vector database is running. It’s a perfect solution for those who want not to worry about the model inference and just use search that works on the data they have. Check out the Cloud Inference documentation to learn more.