How to Implement Multitenancy and Custom Sharding in Qdrant
David Myriel
·February 06, 2024

Scaling Your Machine Learning Setup: The Power of Multitenancy and Custom Sharding in Qdrant
We are seeing the topics of multitenancy and distributed deployment pop-up daily on our Discord support channel. This tells us that many of you are looking to scale Qdrant along with the rest of your machine learning setup.
Whether you are building a bank fraud-detection system, RAG for e-commerce, or services for the federal government - you will need to leverage a multitenant architecture to scale your product. In the world of SaaS and enterprise apps, this setup is the norm. It will considerably increase your application’s performance and lower your hosting costs.
Multitenancy & custom sharding with Qdrant
We have developed two major features just for this. You can now scale a single Qdrant cluster and support all of your customers worldwide. Under multitenancy, each customer’s data is completely isolated and only accessible by them. At times, if this data is location-sensitive, Qdrant also gives you the option to divide your cluster by region or other criteria that further secure your customer’s access. This is called custom sharding.
Combining these two will result in an efficiently-partitioned architecture that further leverages the convenience of a single Qdrant cluster. This article will briefly explain the benefits and show how you can get started using both features.
One collection, many tenants
When working with Qdrant, you can upsert all your data to a single collection, and then partition each vector via its payload. This means that all your users are leveraging the power of a single Qdrant cluster, but their data is still isolated within the collection. Let’s take a look at a two-tenant collection:
Figure 1: Each individual vector is assigned a specific payload that denotes which tenant it belongs to. This is how a large number of different tenants can share a single Qdrant collection.
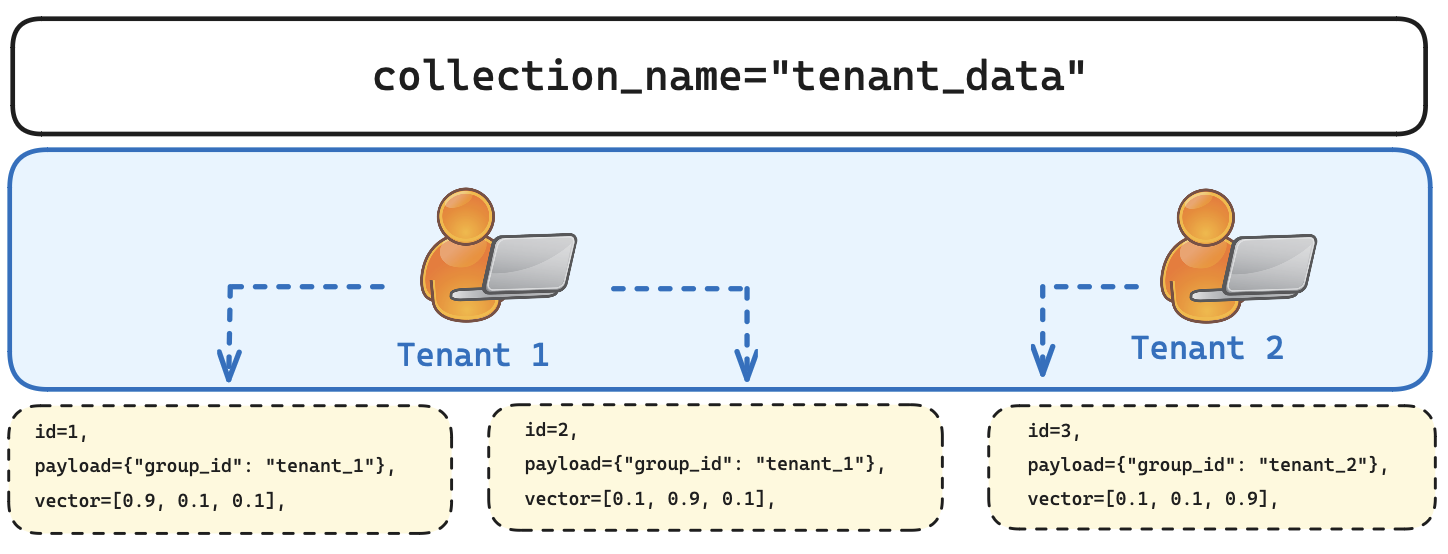
Qdrant is built to excel in a single collection with a vast number of tenants. You should only create multiple collections when your data is not homogenous or if users’ vectors are created by different embedding models. Creating too many collections may result in resource overhead and cause dependencies. This can increase costs and affect overall performance.
Sharding your database
With Qdrant, you can also specify a shard for each vector individually. This feature is useful if you want to control where your data is kept in the cluster. For example, one set of vectors can be assigned to one shard on its own node, while another set can be on a completely different node.
During vector search, your operations will be able to hit only the subset of shards they actually need. In massive-scale deployments, this can significantly improve the performance of operations that do not require the whole collection to be scanned.
This works in the other direction as well. Whenever you search for something, you can specify a shard or several shards and Qdrant will know where to find them. It will avoid asking all machines in your cluster for results. This will minimize overhead and maximize performance.
Common use cases
A clear use-case for this feature is managing a multitenant collection, where each tenant (let it be a user or organization) is assumed to be segregated, so they can have their data stored in separate shards. Sharding solves the problem of region-based data placement, whereby certain data needs to be kept within specific locations. To do this, however, you will need to move your shards between nodes.
Figure 2: Users can both upsert and query shards that are relevant to them, all within the same collection. Regional sharding can help avoid cross-continental traffic.
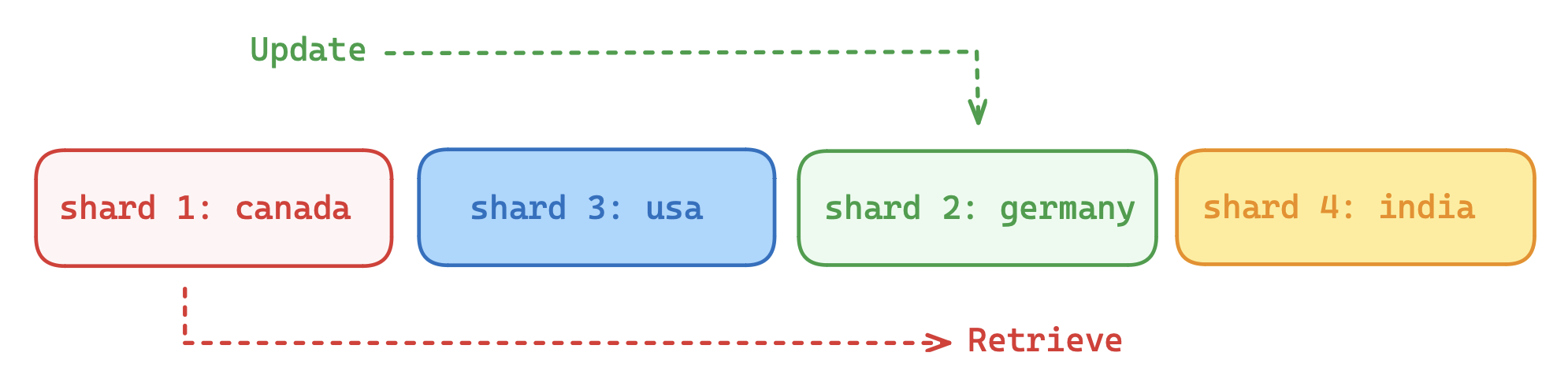
Custom sharding also gives you precise control over other use cases. A time-based data placement means that data streams can index shards that represent latest updates. If you organize your shards by date, you can have great control over the recency of retrieved data. This is relevant for social media platforms, which greatly rely on time-sensitive data.
Before I go any further…..how secure is my user data?
By design, Qdrant offers three levels of isolation. We initially introduced collection-based isolation, but your scaled setup has to move beyond this level. In this scenario, you will leverage payload-based isolation (from multitenancy) and resource-based isolation (from sharding). The ultimate goal is to have a single collection, where you can manipulate and customize placement of shards inside your cluster more precisely and avoid any kind of overhead. The diagram below shows the arrangement of your data within a two-tier isolation arrangement.
Figure 3: Users can query the collection based on two filters: the group_id and the individual shard_key_selector. This gives your data two additional levels of isolation.
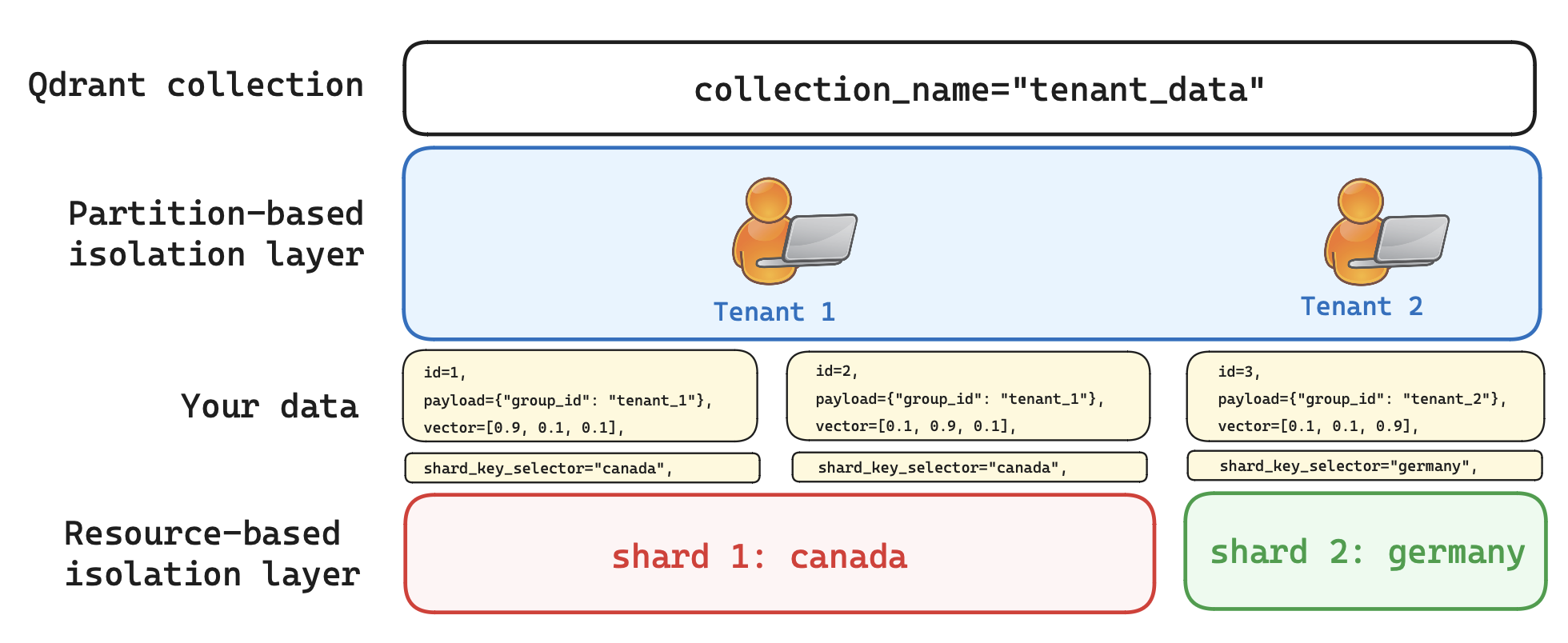
Create custom shards for a single collection
When creating a collection, you will need to configure user-defined sharding. This lets you control the shard placement of your data, so that operations can hit only the subset of shards they actually need. In big clusters, this can significantly improve the performance of operations, since you won’t need to go through the entire collection to retrieve data.
client.create_collection(
collection_name="{tenant_data}",
shard_number=2,
sharding_method=models.ShardingMethod.CUSTOM,
# ... other collection parameters
)
client.create_shard_key("{tenant_data}", "canada")
client.create_shard_key("{tenant_data}", "germany")
In this example, your cluster is divided between Germany and Canada. Canadian and German law differ when it comes to international data transfer. Let’s say you are creating a RAG application that supports the healthcare industry. Your Canadian customer data will have to be clearly separated for compliance purposes from your German customer.
Even though it is part of the same collection, data from each shard is isolated from other shards and can be retrieved as such. For additional examples on shards and retrieval, consult Distributed Deployments documentation and Qdrant Client specification.
Configure a multitenant setup for users
Let’s continue and start adding data. As you upsert your vectors to your new collection, you can add a group_id field to each vector. If you do this, Qdrant will assign each vector to its respective group.
Additionally, each vector can now be allocated to a shard. You can specify the shard_key_selector for each individual vector. In this example, you are upserting data belonging to tenant_1 to the Canadian region.
client.upsert(
collection_name="{tenant_data}",
points=[
models.PointStruct(
id=1,
payload={"group_id": "tenant_1"},
vector=[0.9, 0.1, 0.1],
),
models.PointStruct(
id=2,
payload={"group_id": "tenant_1"},
vector=[0.1, 0.9, 0.1],
),
],
shard_key_selector="canada",
)
Keep in mind that the data for each group_id is isolated. In the example below, tenant_1 vectors are kept separate from tenant_2. The first tenant will be able to access their data in the Canadian portion of the cluster. However, as shown below tenant_2 might only be able to retrieve information hosted in Germany.
client.upsert(
collection_name="{tenant_data}",
points=[
models.PointStruct(
id=3,
payload={"group_id": "tenant_2"},
vector=[0.1, 0.1, 0.9],
),
],
shard_key_selector="germany",
)
Retrieve data via filters
The access control setup is completed as you specify the criteria for data retrieval. When searching for vectors, you need to use a query_filter along with group_id to filter vectors for each user.
client.search(
collection_name="{tenant_data}",
query_filter=models.Filter(
must=[
models.FieldCondition(
key="group_id",
match=models.MatchValue(
value="tenant_1",
),
),
]
),
query_vector=[0.1, 0.1, 0.9],
limit=10,
)
Performance considerations
The speed of indexation may become a bottleneck if you are adding large amounts of data in this way, as each user’s vector will be indexed into the same collection. To avoid this bottleneck, consider bypassing the construction of a global vector index for the entire collection and building it only for individual groups instead.
By adopting this strategy, Qdrant will index vectors for each user independently, significantly accelerating the process.
To implement this approach, you should:
- Set
payload_min the HNSW configuration to a non-zero value, such as 16. - Set
min hnsw config to 0. This will disable building global index for the whole collection.
from qdrant_client import QdrantClient, models
client = QdrantClient("localhost", port=6333)
client.create_collection(
collection_name="{tenant_data}",
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE),
hnsw_config=models.HnswConfigDiff(
payload_m=16,
m=0,
),
)
- Create keyword payload index for
group_idfield.
client.create_payload_index(
collection_name="{tenant_data}",
field_name="group_id",
field_schema=models.PayloadSchemaType.KEYWORD,
)
Note: Keep in mind that global requests (without the
group_idfilter) will be slower since they will necessitate scanning all groups to identify the nearest neighbors.
Explore multitenancy and custom sharding in Qdrant for scalable solutions
Qdrant is ready to support a massive-scale architecture for your machine learning project. If you want to see whether our vector database is right for you, try the quickstart tutorial or read our docs and tutorials.
To spin up a free instance of Qdrant, sign up for Qdrant Cloud - no strings attached.
Get support or share ideas in our Discord community. This is where we talk about vector search theory, publish examples and demos and discuss vector database setups.