Is RAG Dead? Why Long Context Windows Don't Replace RAG
David Myriel
·February 27, 2024

Is RAG Dead? The Role of Vector Databases in AI Efficiency and Vector Search
When Anthropic came out with a context window of 100K tokens, they said: “Vector search is dead. LLMs are getting more accurate and won’t need RAG anymore.”
Google’s Gemini 1.5 now offers a context window of 10 million tokens. Their supporting paper claims victory over accuracy issues, even when applying Greg Kamradt’s NIAH methodology.
It’s over. RAG (Retrieval Augmented Generation) must be completely obsolete now. Right?
No.
Larger context windows are never the solution. Let me repeat. Never. They require more computational resources and lead to slower processing times.
The community is already stress testing Gemini 1.5:

This is not surprising. LLMs require massive amounts of compute and memory to run. To cite Grant, running such a model by itself “would deplete a small coal mine to generate each completion”. Also, who is waiting 30 seconds for a response?
Context stuffing is not the solution
Relying on context is expensive, and it doesn’t improve response quality in real-world applications. Retrieval based on vector search offers much higher precision.
If you solely rely on an LLM to perfect retrieval and precision, you are doing it wrong.
A large context window makes it harder to focus on relevant information. This increases the risk of errors or hallucinations in its responses.
Google found Gemini 1.5 significantly more accurate than GPT-4 at shorter context lengths and “a very small decrease in recall towards 1M tokens”. The recall is still below 0.8.
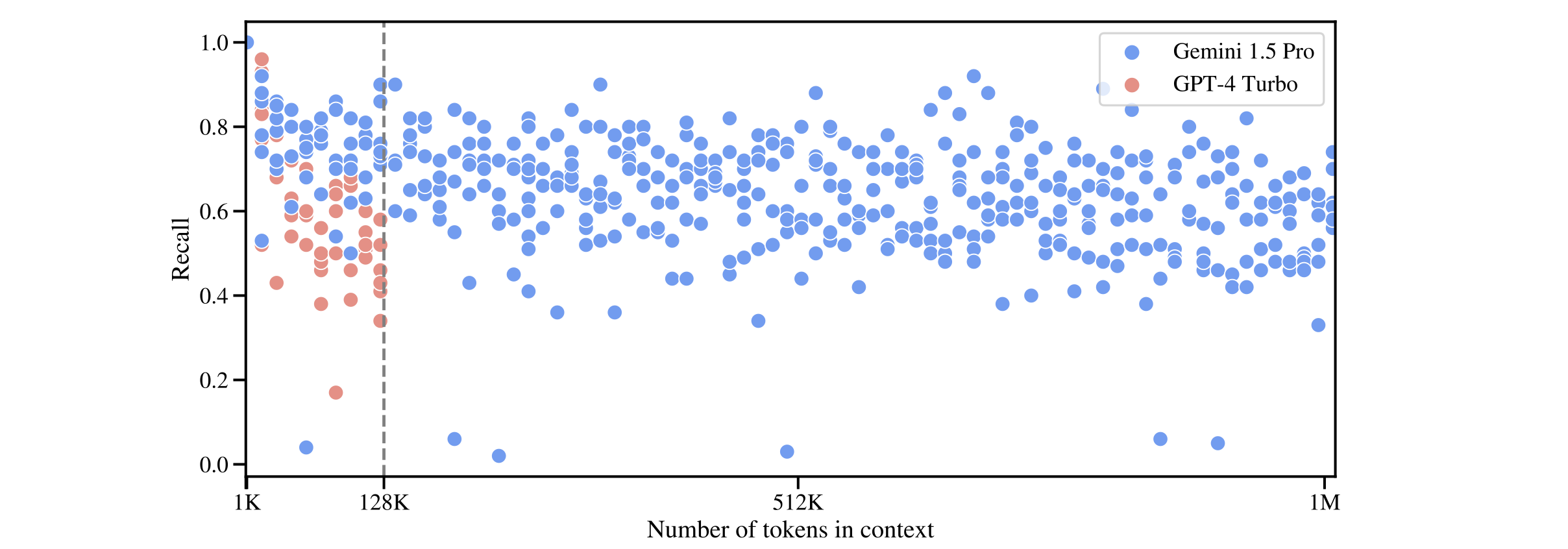
We don’t think 60-80% is good enough. The LLM might retrieve enough relevant facts in its context window, but it still loses up to 40% of the available information.
The whole point of vector search is to circumvent this process by efficiently picking the information your app needs to generate the best response. A vector database keeps the compute load low and the query response fast. You don’t need to wait for the LLM at all.
Qdrant’s benchmark results are strongly in favor of accuracy and efficiency. We recommend that you consider them before deciding that an LLM is enough. Take a look at our open-source benchmark reports and try out the tests yourself.
Vector search in compound systems
The future of AI lies in careful system engineering. As per Zaharia et al., results from Databricks find that “60% of LLM applications use some form of RAG, while 30% use multi-step chains.”
Even Gemini 1.5 demonstrates the need for a complex strategy. When looking at Google’s MMLU Benchmark, the model was called 32 times to reach a score of 90.0% accuracy. This shows us that even a basic compound arrangement is superior to monolithic models.
As a retrieval system, a vector database perfectly fits the need for compound systems. Introducing them into your design opens the possibilities for superior applications of LLMs. It is superior because it’s faster, more accurate, and much cheaper to run.
The key advantage of RAG is that it allows an LLM to pull in real-time information from up-to-date internal and external knowledge sources, making it more dynamic and adaptable to new information. - Oliver Molander, CEO of IMAGINAI
Qdrant scales to enterprise RAG scenarios
People still don’t understand the economic benefit of vector databases. Why would a large corporate AI system need a standalone vector database like Qdrant? In our minds, this is the most important question. Let’s pretend that LLMs cease struggling with context thresholds altogether.
How much would all of this cost?
If you are running a RAG solution in an enterprise environment with petabytes of private data, your compute bill will be unimaginable. Let’s assume 1 cent per 1K input tokens (which is the current GPT-4 Turbo pricing). Whatever you are doing, every time you go 100 thousand tokens deep, it will cost you $1.
That’s a buck a question.
According to our estimations, vector search queries are at least 100 million times cheaper than queries made by LLMs.
Conversely, the only up-front investment with vector databases is the indexing (which requires more compute). After this step, everything else is a breeze. Once setup, Qdrant easily scales via features like Multitenancy and Sharding. This lets you scale up your reliance on the vector retrieval process and minimize your use of the compute-heavy LLMs. As an optimization measure, Qdrant is irreplaceable.
Julien Simon from HuggingFace says it best:
RAG is not a workaround for limited context size. For mission-critical enterprise use cases, RAG is a way to leverage high-value, proprietary company knowledge that will never be found in public datasets used for LLM training. At the moment, the best place to index and query this knowledge is some sort of vector index. In addition, RAG downgrades the LLM to a writing assistant. Since built-in knowledge becomes much less important, a nice small 7B open-source model usually does the trick at a fraction of the cost of a huge generic model.
Get superior accuracy with Qdrant’s vector database
As LLMs continue to require enormous computing power, users will need to leverage vector search and RAG.
Our customers remind us of this fact every day. As a product, our vector database is highly scalable and business-friendly. We develop our features strategically to follow our company’s Unix philosophy.
We want to keep Qdrant compact, efficient and with a focused purpose. This purpose is to empower our customers to use it however they see fit.
When large enterprises release their generative AI into production, they need to keep costs under control, while retaining the best possible quality of responses. Qdrant has the vector search solutions to do just that. Revolutionize your vector search capabilities and get started with a Qdrant demo.