Fine-Tuning Sparse Embeddings for E-Commerce Search | Part 4: Specialization vs Generalization
Thierry Damiba
·March 09, 2026

This is Part 4 of a 5-part series on fine-tuning sparse embeddings for e-commerce search. In Part 3, we evaluated our model and implemented hard negative mining. Now we test how well it generalizes.
Series:
- Part 1: Why Sparse Embeddings Beat BM25
- Part 2: Training SPLADE on Modal
- Part 3: Evaluation & Hard Negatives
- Part 4: Specialization vs Generalization (here)
- Part 5: From Research to Product
We’ve built a SPLADE model that beats BM25 by 28% on Amazon ESCI. But here’s the question that determines whether this is a lab result or a production strategy: does it work on data it wasn’t trained on? Full code is on GitHub, you can try the fine-tuned models on HuggingFace, or fine-tune on your own catalog with the sparse-finetune CLI.
In this final article, we test cross-domain generalization, train a multi-domain model, and lay out a decision framework for when to specialize vs generalize.
Cross-Domain Evaluation
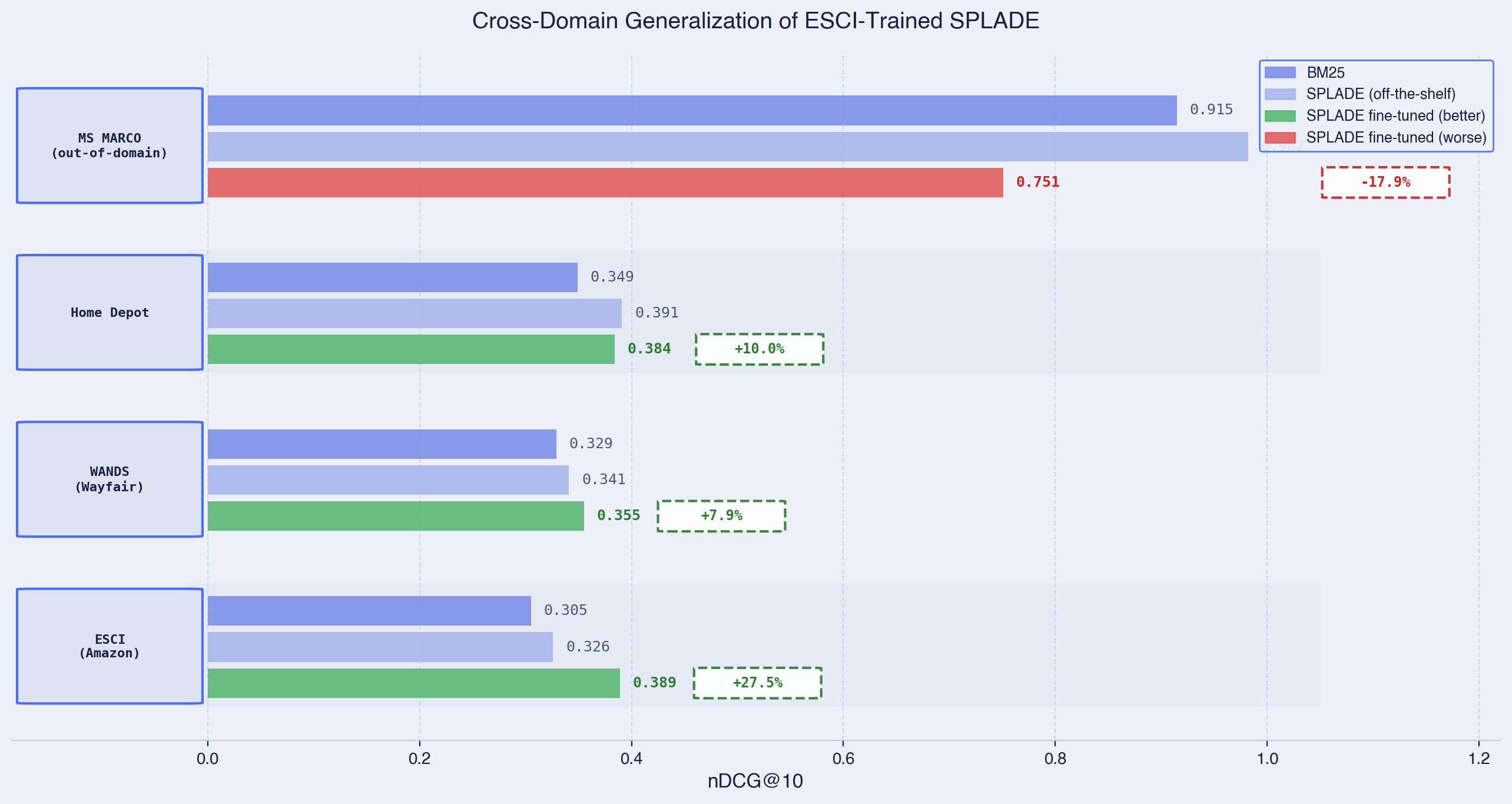
We took our Amazon ESCI-trained model and tested it on three additional datasets:
- WANDS (Wayfair): Furniture and home goods search
- Home Depot: Hardware and home improvement search
- MS MARCO: General web search (the “out of distribution” control)
| Dataset | BM25 | SPLADE (OTS) | SPLADE (tuned) | vs BM25 |
|---|---|---|---|---|
| ESCI (Amazon) | 0.305 | 0.326 | 0.389 | +27.5% |
| WANDS (Wayfair) | 0.329 | 0.341 | 0.355 | +7.9% |
| Home Depot | 0.349 | 0.391 | 0.384* | +10.0% |
| MS MARCO (web) | 0.915 | 0.982 | 0.751 | -17.9% |
*On Home Depot, the off-the-shelf model edges out the fine-tuned one (0.391 vs 0.384).
Three patterns emerge:
In-domain (ESCI): +28% over BM25. The model was trained on this data. No surprise it does well.
Cross-domain e-commerce: +8-10% over BM25. The Amazon-trained model still helps on Wayfair and Home Depot. E-commerce search shares enough structure (brand matching, attribute weighting, product vocabulary) that the patterns transfer. But notice the gap to off-the-shelf SPLADE narrows. On Home Depot, the off-the-shelf model actually wins (0.391 vs 0.384).
Out-of-domain (MS MARCO): -18% vs BM25. This is catastrophic forgetting in action. The model overfitted to e-commerce patterns. “Apple” became a brand, not a fruit. “Prime” became a shipping speed, not a math concept. The general IR capabilities of the original DistilBERT were overwritten during fine-tuning.
Why Generalization Degrades
The cross-domain results reveal a fundamental tradeoff. Fine-tuning teaches the model:
- Amazon-specific query patterns: short, product-focused queries with brand names and model numbers
- Amazon-specific vocabulary: “renewed” (refurbished), “subscribe & save”, “prime eligible”
- Amazon-specific relevance signals: what Amazon shoppers consider a good match vs a substitute
Wayfair customers search differently (“mid-century modern coffee table” vs “coffee table”). Home Depot customers use industry terminology (“3/8 inch drive socket set”). The Amazon-trained model helps on these datasets because e-commerce is e-commerce, but it’s not optimal.
MS MARCO is the extreme case. Web search queries like “what is the capital of France” or “how to tie a tie” are nothing like e-commerce queries. The model’s learned biases actively hurt.
Multi-Domain Training
To address the generalization problem, we trained a multi-domain SPLADE model on combined data from ESCI, WANDS, and Home Depot: roughly 50K training pairs from each dataset, 150K total.
The hypothesis: exposure to diverse e-commerce catalogs should improve cross-domain transfer while maintaining reasonable in-domain performance.
| Dataset | ESCI-only | Multi-domain | Difference |
|---|---|---|---|
| ESCI | 0.389 | 0.372 | -4.4% |
| WANDS | 0.355 | 0.366 | +3.1% |
| Home Depot | 0.384 | 0.410 | +6.8% |
| MS MARCO | 0.751 | 0.829 | +10.4% |
Multi-domain training does exactly what you’d expect:
- ESCI drops 4%: Less specialization means less Amazon-specific optimization. The model can’t memorize Amazon’s vocabulary as deeply when it’s also learning Wayfair and Home Depot patterns.
- WANDS and Home Depot gain 3-7%: Direct benefit from training data. The model now understands furniture terminology and hardware vocabulary.
- MS MARCO recovers 10%: More diverse training data prevents the catastrophic forgetting we saw with ESCI-only training. The model retains more general language understanding.
Setting Up Multi-Domain Training
The multi-domain loader normalizes labels across datasets:
# configs/splade_multidomain.yaml
run_name: splade_multidomain
base_model: distilbert/distilbert-base-uncased
architecture: splade
batch_size: 32
learning_rate: 2e-5
num_epochs: 1
datasets:
- name: esci
max_samples: 50000
- name: wands
max_samples: 50000
- name: homedepot
max_samples: 50000
Label normalization is the key challenge. ESCI uses character labels (E, S, C, I), WANDS uses numeric scores (0, 1, 2), and Home Depot uses relevance ratings. The multi-domain loader maps everything to a common format: positive (relevant) and negative (irrelevant) pairs for contrastive training.
Decision Framework
After running all these experiments, here’s when to use each approach:
| Scenario | Recommended approach |
|---|---|
| Single retailer, lots of training data | Domain-specific fine-tuning — maximum performance on your catalog |
| Multi-retailer or marketplace | Multi-domain training — better generalization across catalogs |
| New domain, limited data | Off-the-shelf SPLADE — strong baseline without training data |
| Hybrid (e-commerce + general search) | Multi-domain training — preserves general IR capabilities |
Single retailer with abundant data. If you’re building search for Amazon, Wayfair, or any single retailer with click logs, domain-specific fine-tuning wins. The 4% you lose on other domains doesn’t matter if you only serve one catalog.
Marketplace or multi-retailer. If you’re building a platform that serves multiple retailers (Shopify search, a price comparison engine), multi-domain training provides better balance. You sacrifice some peak performance for consistency across catalogs.
Cold start. New to a domain with no training data? Off-the-shelf SPLADE (like naver/splade-v3) is a strong baseline. It beats BM25 on most e-commerce datasets without any fine-tuning. Start here, collect click data, then fine-tune.
The Case for Fine-Tuning
Why fine-tune when off-the-shelf models already beat BM25?
Domain knowledge matters. Generic models don’t know that “AirPods Max” is a specific product, that “prime” means fast shipping, or that “organic” is a critical filter in grocery. Fine-tuning on your catalog teaches the model your vocabulary and your customers’ search patterns.
You control the training data. Click logs, add-to-cart signals, and purchase data are unique to your business. Fine-tuning converts this proprietary data into a model that understands your domain better than any general-purpose model can.
The model is portable. Your fine-tuned model runs wherever you need it: Modal, your own GPUs, CPU inference, or any cloud provider. Deploy it however makes sense for your infrastructure.
Performance compounds. As we saw, domain-specific training delivers +28% over BM25. That’s not a marginal improvement. It’s the difference between showing a customer the right product on the first page or burying it on the third.
The Data Flywheel
Fine-tuning isn’t a one-time investment. It’s the start of a compounding loop:
- Better model leads to better rankings
- Better rankings lead to more clicks
- More clicks produce better training data
- Better training data produces an even better model
- Repeat
Phase 1: Bootstrap. Use product metadata and relevance labels (or the ESCI dataset as a proxy). Train the initial model. This is what we’ve done in this series.
Phase 2: Implicit feedback. Log queries with clicked products (positive pairs). Log impressions without clicks (negative signals). Track add-to-cart and purchase events (high-confidence positives).
Phase 3: Continuous improvement. Retrain periodically on accumulated click data. A/B test new models against production. Monitor nDCG on held-out queries.
The 28% improvement we demonstrated is the starting point. Each iteration incorporates what customers actually searched for and clicked on, data your competitors can’t access.
What’s Next
We’ve covered the full pipeline: from understanding why sparse embeddings work for e-commerce, through training on Modal and evaluating with Qdrant, to the specialization-generalization tradeoff.
Extensions worth exploring:
- Cross-encoder reranking: Add a second-stage ranker for the top-k results from SPLADE. This is the standard two-stage retrieval architecture in production systems.
- Larger base models: ModernBERT or DeBERTa instead of DistilBERT. More parameters, better representations, slower inference.
- Full dataset training: We used 100K samples from ESCI. The full 1.2M with multiple epochs would likely improve results further.
- Curriculum learning: Start with general data, gradually specialize to your domain. This can mitigate catastrophic forgetting while still achieving strong in-domain performance.
The code is open source. The pre-trained models are on HuggingFace (including a multi-domain variant). Training runs on Modal for under $1. Qdrant handles the sparse vectors, indexing, and retrieval out of the box. The barrier to building better e-commerce search has never been lower.
We also packaged this entire pipeline into an open-source toolkit with a CLI and web dashboard. See Part 5: From Research to Product for how to fine-tune a SPLADE model on your own catalog with a single command.
Series Summary
- Part 1: Why sparse embeddings for e-commerce - SPLADE combines keyword precision with learned expansion
- Part 2: Training pipeline on Modal - 6 min training, <$1, persistent checkpoints
- Part 3: Evaluation and hard negatives - +28% vs BM25, +19% vs off-the-shelf SPLADE
- Part 4: Specialization vs generalization - Domain-specific wins for single retailers; multi-domain for platforms
- Part 5: From research to product - CLI + dashboard that runs the full pipeline