
Not every search journey begins with a specific destination in mind. Sometimes, you just want to explore and see what’s out there and what you might like. This is especially true when it comes to food. You might be craving something sweet, but you don’t know what. You might be also looking for a new dish to try, and you just want to see the options available. In these cases, it’s impossible to express your needs in a textual query, as the thing you are looking for is not yet defined. Qdrant’s semantic search for images is useful when you have a hard time expressing your tastes in words.
General architecture
We are happy to announce a refreshed version of our Food Discovery Demo. This time available as an open source project, so you can easily deploy it on your own and play with it. If you prefer to dive into the source code directly, then feel free to check out the GitHub repository . Otherwise, read on to learn more about the demo and how it works!
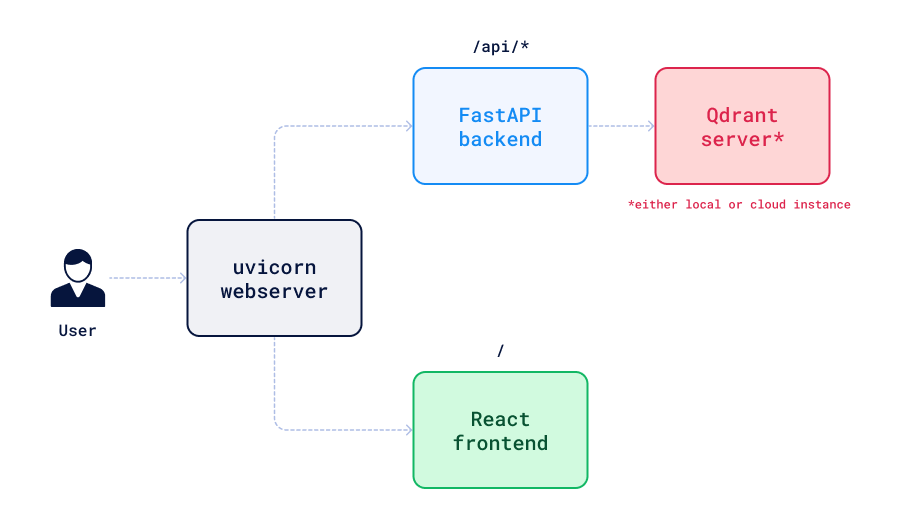
In general, our application consists of three parts: a FastAPI backend, a React frontend, and a Qdrant instance. The architecture diagram below shows how these components interact with each other:
Why did we use a CLIP model?
CLIP is a neural network that can be used to encode both images and texts into vectors. And more importantly, both images and texts are vectorized into the same latent space, so we can compare them directly. This lets you perform semantic search on images using text queries and the other way around. For example, if you search for “flat bread with toppings”, you will get images of pizza. Or if you search for “pizza”, you will get images of some flat bread with toppings, even if they were not labeled as “pizza”. This is because CLIP embeddings capture the semantics of the images and texts and can find the similarities between them no matter the wording.
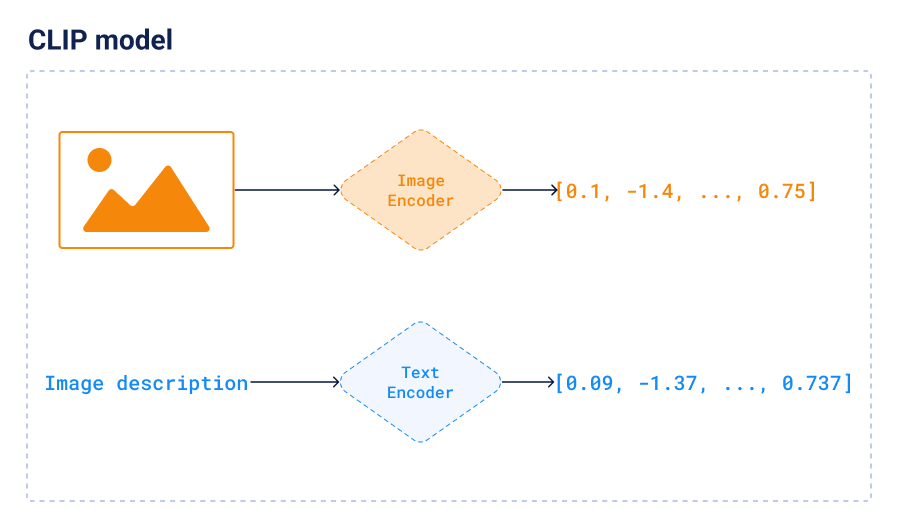
CLIP is available in many different ways. We used the pretrained clip-ViT-B-32 model available in the Sentence-Transformers
library, as this is the easiest way to get started.
The dataset
The demo is based on the Wolt dataset. It contains over 2M images of dishes from different restaurants along with some additional metadata. This is how a payload for a single dish looks like:
{
"cafe": {
"address": "VGX7+6R2 Vecchia Napoli, Valletta",
"categories": ["italian", "pasta", "pizza", "burgers", "mediterranean"],
"location": {"lat": 35.8980154, "lon": 14.5145106},
"menu_id": "610936a4ee8ea7a56f4a372a",
"name": "Vecchia Napoli Is-Suq Tal-Belt",
"rating": 9,
"slug": "vecchia-napoli-skyparks-suq-tal-belt"
},
"description": "Tomato sauce, mozzarella fior di latte, crispy guanciale, Pecorino Romano cheese and a hint of chilli",
"image": "https://wolt-menu-images-cdn.wolt.com/menu-images/610936a4ee8ea7a56f4a372a/005dfeb2-e734-11ec-b667-ced7a78a5abd_l_amatriciana_pizza_joel_gueller1.jpeg",
"name": "L'Amatriciana"
}
Processing this amount of records takes some time, so we precomputed the CLIP embeddings, stored them in a Qdrant collection and exported the collection as a snapshot. You may download it here.
Different search modes
The FastAPI backend exposes just a single endpoint, however it handles multiple scenarios. Let’s dive into them one by one and understand why they are needed.
Cold start
Recommendation systems struggle with a cold start problem. When a new user joins the system, there is no data about their preferences, so it’s hard to recommend anything. The same applies to our demo. When you open it, you will see a random selection of dishes, and it changes every time you refresh the page. Internally, the demo chooses some random points in the vector space.
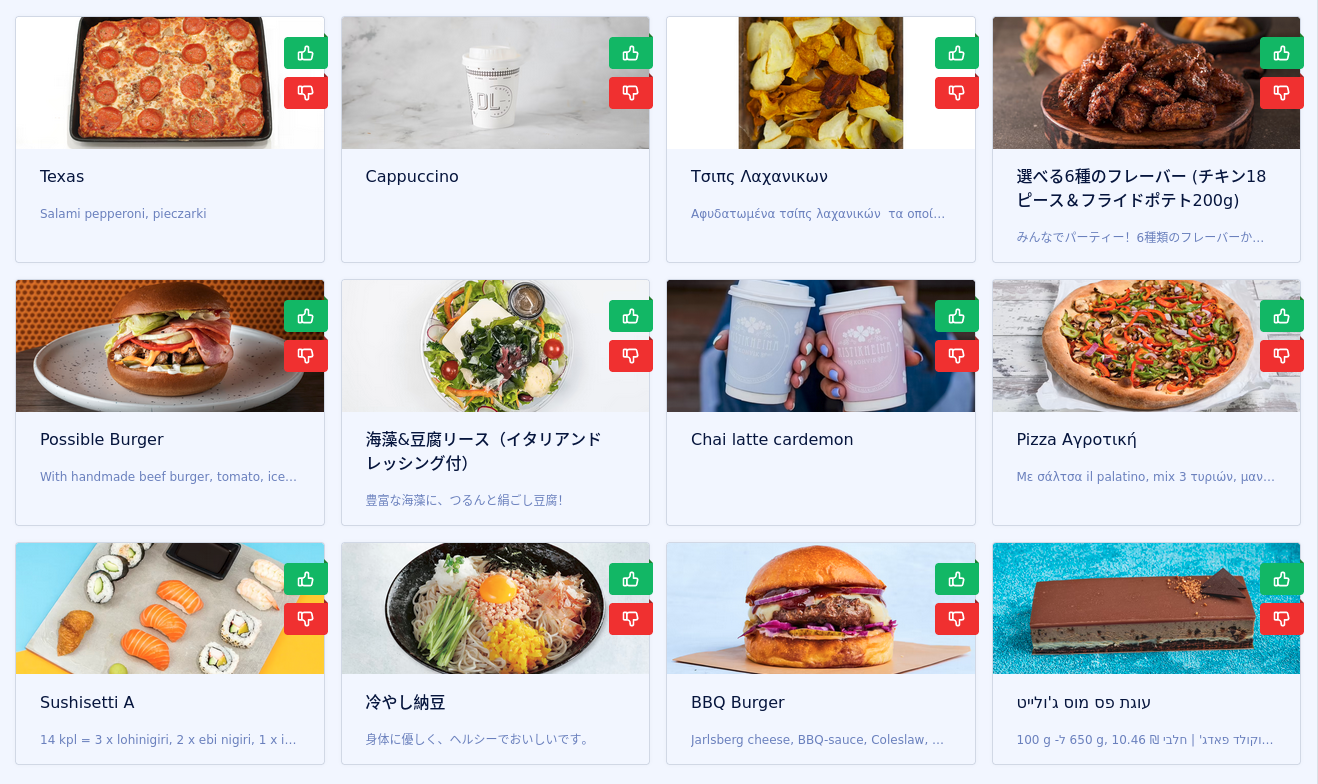
That procedure should result in returning diverse results, so we have a higher chance of showing something interesting to the user.
Textual search
Since the demo suffers from the cold start problem, we implemented a textual search mode that is useful to start exploring the data. You can type in any text query by clicking a search icon in the top right corner. The demo will use the CLIP model to encode the query into a vector and then search for the nearest neighbors in the vector space.
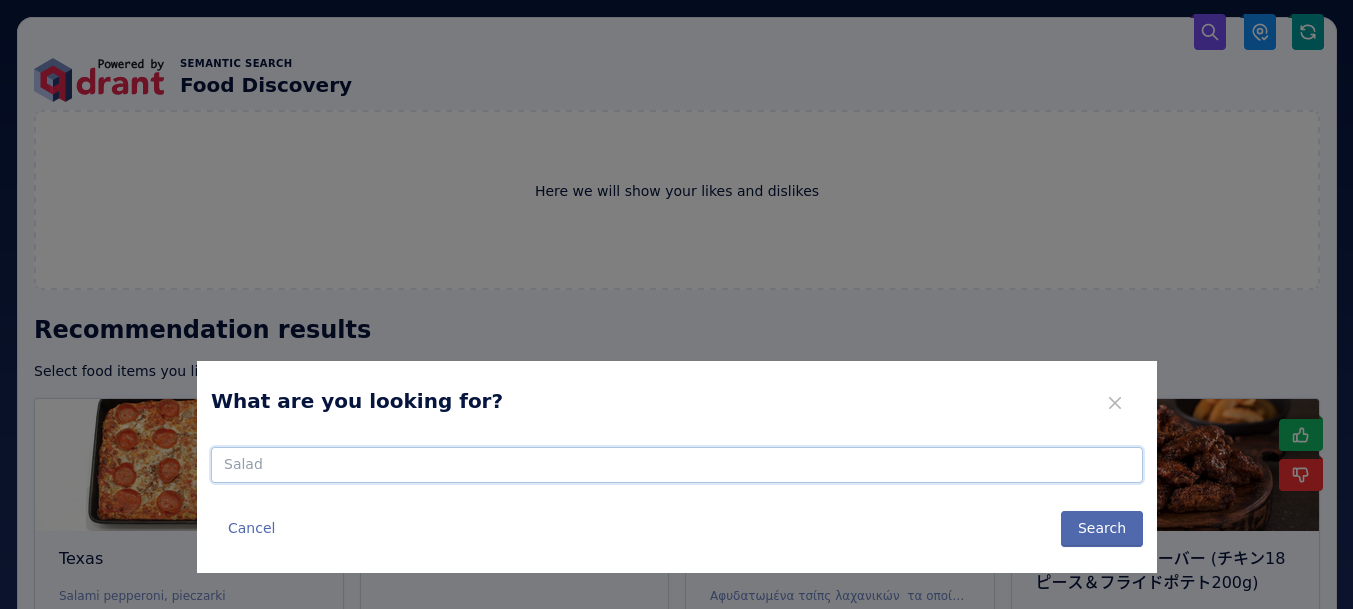
This is implemented as a group search query to Qdrant.
We didn’t use a simple search, but performed grouping by the restaurant to get more diverse results. Search groups
is a mechanism similar to GROUP BY clause in SQL, and it’s useful when you want to get a specific number of result per group (in our case just one).
import settings
# Encode query into a vector, model is an instance of
# sentence_transformers.SentenceTransformer that loaded CLIP model
query_vector = model.encode(query).tolist()
# Search for nearest neighbors, client is an instance of
# qdrant_client.QdrantClient that has to be initialized before
response = client.search_groups(
settings.QDRANT_COLLECTION,
query_vector=query_vector,
group_by=settings.GROUP_BY_FIELD,
limit=search_query.limit,
)
Exploring the results
The main feature of the demo is the ability to explore the space of the dishes. You can click on any of them to see more details, but first of all you can like or dislike it, and the demo will update the search results accordingly.
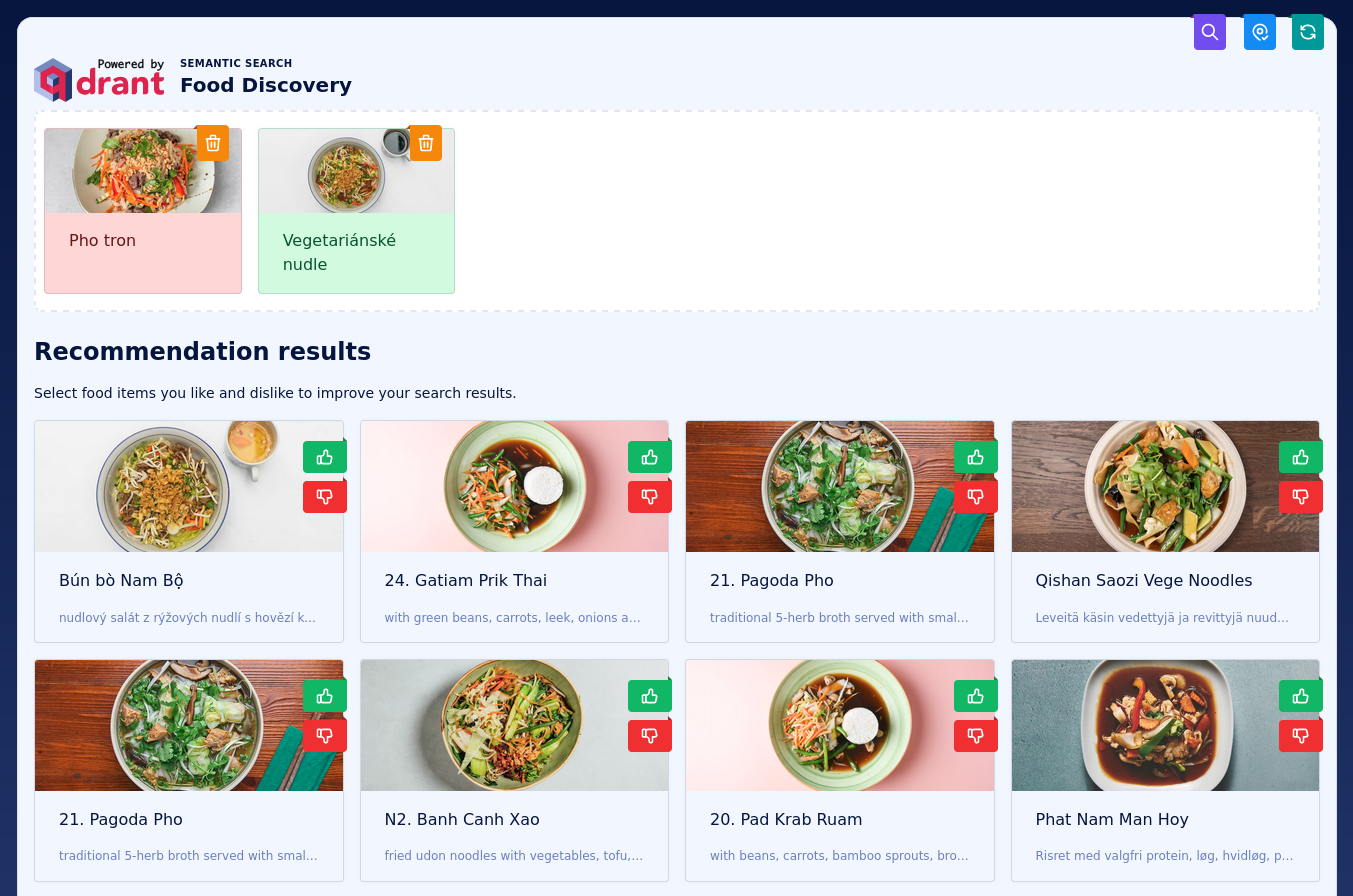
Negative feedback only
Qdrant Recommendation API needs at least one positive example to work. However, in our demo we want to be able to provide only negative examples. This is because we want to be able to say “I don’t like this dish” without having to like anything first. To achieve this, we use a trick. We negate the vectors of the disliked dishes and use their mean as a query. This way, the disliked dishes will be pushed away from the search results. This works because the cosine distance is based on the angle between two vectors, and the angle between a vector and its negation is 180 degrees.
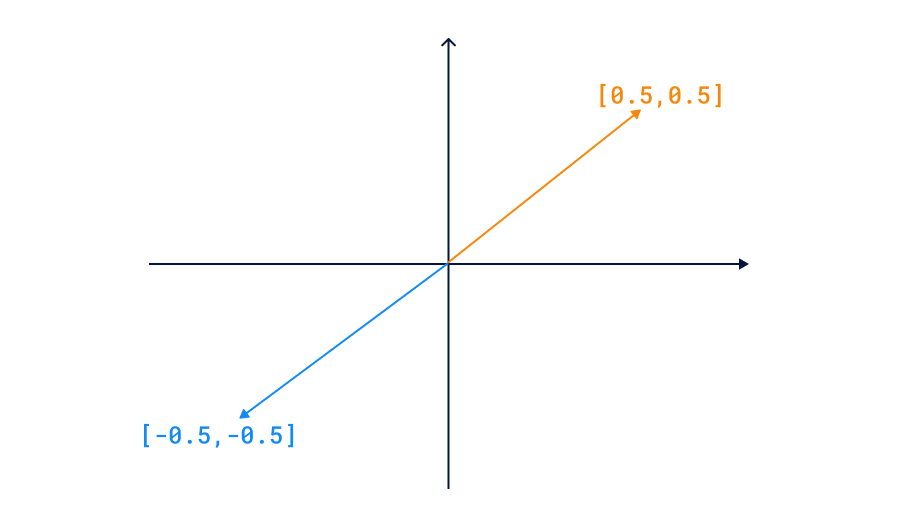
Food Discovery Demo implements that trick by calling Qdrant twice. Initially, we use the Scroll API to find disliked items, and then calculate a negated mean of all their vectors. That allows using the Search Groups API to find the nearest neighbors of the negated mean vector.
import numpy as np
# Retrieve the disliked points based on their ids
disliked_points, _ = client.scroll(
settings.QDRANT_COLLECTION,
scroll_filter=models.Filter(
must=[
models.HasIdCondition(has_id=search_query.negative),
]
),
with_vectors=True,
)
# Calculate a mean vector of disliked points
disliked_vectors = np.array([point.vector for point in disliked_points])
mean_vector = np.mean(disliked_vectors, axis=0)
negated_vector = -mean_vector
# Search for nearest neighbors of the negated mean vector
response = client.search_groups(
settings.QDRANT_COLLECTION,
query_vector=negated_vector.tolist(),
group_by=settings.GROUP_BY_FIELD,
limit=search_query.limit,
)
Positive and negative feedback
Since the Recommendation API requires at least one positive example, we can use it only when the user has liked at least one dish. We could theoretically use the same trick as above and negate the disliked dishes, but it would be a bit weird, as Qdrant has that feature already built-in, and we can call it just once to do the job. It’s always better to perform the search server-side. Thus, in this case we just call the Qdrant server with a list of positive and negative examples, so it can find some points which are close to the positive examples and far from the negative ones.
response = client.recommend_groups(
settings.QDRANT_COLLECTION,
positive=search_query.positive,
negative=search_query.negative,
group_by=settings.GROUP_BY_FIELD,
limit=search_query.limit,
)
From the user perspective nothing changes comparing to the previous case.
Location-based search
Last but not least, location plays an important role in the food discovery process. You are definitely looking for something you can find nearby, not on the other side of the globe. Therefore, your current location can be toggled as a filtering condition. You can enable it by clicking on “Find near me” icon in the top right. This way you can find the best pizza in your neighborhood, not in the whole world. Qdrant geo radius filter is a perfect choice for this. It lets you filter the results by distance from a given point.
from qdrant_client import models
# Create a geo radius filter
query_filter = models.Filter(
must=[
models.FieldCondition(
key="cafe.location",
geo_radius=models.GeoRadius(
center=models.GeoPoint(
lon=location.longitude,
lat=location.latitude,
),
radius=location.radius_km * 1000,
),
)
]
)
Such a filter needs a payload index to work efficiently, and it was created on a collection we used to create the snapshot. When you import it into your instance, the index will be already there.
Using the demo
The Food Discovery Demo is available online, but if you prefer to run it locally, you can do it with Docker. The README describes all the steps more in detail, but here is a quick start:
git clone git@github.com:qdrant/demo-food-discovery.git
cd demo-food-discovery
# Create .env file based on .env.example
docker-compose up -d
The demo will be available at http://localhost:8001, but you won’t be able to search anything until you import the snapshot into your Qdrant
instance. If you don’t want to bother with hosting a local one, you can use the Qdrant
Cloud cluster. 4 GB RAM is enough to load all the 2 million entries.
Fork and reuse
Our demo is completely open-source. Feel free to fork it, update with your own dataset or adapt the application to your use case. Whether you’re looking to understand the mechanics of semantic search or to have a foundation to build a larger project, this demo can serve as a starting point. Check out the Food Discovery Demo repository to get started. If you have any questions, feel free to reach out through Discord.