A Complete Guide to Filtering in Vector Search
Sabrina Aquino, David Myriel
·September 10, 2024

Imagine you sell computer hardware. To help shoppers easily find products on your website, you need to have a user-friendly search engine.

If you’re selling computers and have extensive data on laptops, desktops, and accessories, your search feature should guide customers to the exact device they want - or at least a very similar match.
When storing data in Qdrant, each product is a point, consisting of an id, a vector and payload:
{
"id": 1,
"vector": [0.1, 0.2, 0.3, 0.4],
"payload": {
"price": 899.99,
"category": "laptop"
}
}
The id is a unique identifier for the point in your collection. The vector is a mathematical representation of similarity to other points in the collection.
Finally, the payload holds metadata that directly describes the point.
Though we may not be able to decipher the vector, we are able to derive additional information about the item from its metadata, In this specific case, we are looking at a data point for a laptop that costs $899.99.
What is filtering?
When searching for the perfect computer, your customers may end up with results that are mathematically similar to the search entry, but not exact. For example, if they are searching for laptops under $1000, a simple vector search without constraints might still show other laptops over $1000.
This is why semantic search alone may not be enough. In order to get the exact result, you would need to enforce a payload filter on the price. Only then can you be sure that the search results abide by the chosen characteristic.
This is called filtering and it is one of the key features of vector databases.
Here is how a filtered vector search looks behind the scenes. We’ll cover its mechanics in the following section.
POST /collections/online_store/points/search
{
"vector": [ 0.2, 0.1, 0.9, 0.7 ],
"filter": {
"must": [
{
"key": "category",
"match": { "value": "laptop" }
},
{
"key": "price",
"range": {
"gt": null,
"gte": null,
"lt": null,
"lte": 1000
}
}
]
},
"limit": 3,
"with_payload": true,
"with_vector": false
}
The filtered result will be a combination of the semantic search and the filtering conditions imposed upon the query. In the following pages, we will show that filtering is a key practice in vector search for two reasons:
- With filtering in Qdrant, you can dramatically increase search precision. More on this in the next section.
- Filtering helps control resources and reduce compute use. More on this in Payload Indexing.
What you will learn in this guide:
In vector search, filtering and sorting are more interdependent than they are in traditional databases. While databases like SQL use commands such as WHERE and ORDER BY, the interplay between these processes in vector search is a bit more complex.
Most people use default settings and build vector search apps that aren’t properly configured or even setup for precise retrieval. In this guide, we will show you how to use filtering to get the most out of vector search with some basic and advanced strategies that are easy to implement.
Remember to run all tutorial code in Qdrant’s Dashboard
The easiest way to reach that “Hello World” moment is to try filtering in a live cluster. Our interactive tutorial will show you how to create a cluster, add data and try some filtering clauses.
Qdrant’s approach to filtering
Qdrant follows a specific method of searching and filtering through dense vectors.
Let’s take a look at this 3-stage diagram. In this case, we are trying to find the nearest neighbour to the query vector (green). Your search journey starts at the bottom (orange).
By default, Qdrant connects all your data points within the vector index. After you introduce filters, some data points become disconnected. Vector search can’t cross the grayed out area and it won’t reach the nearest neighbor. How can we bridge this gap?
Figure 1: How Qdrant maintains a filterable vector index.
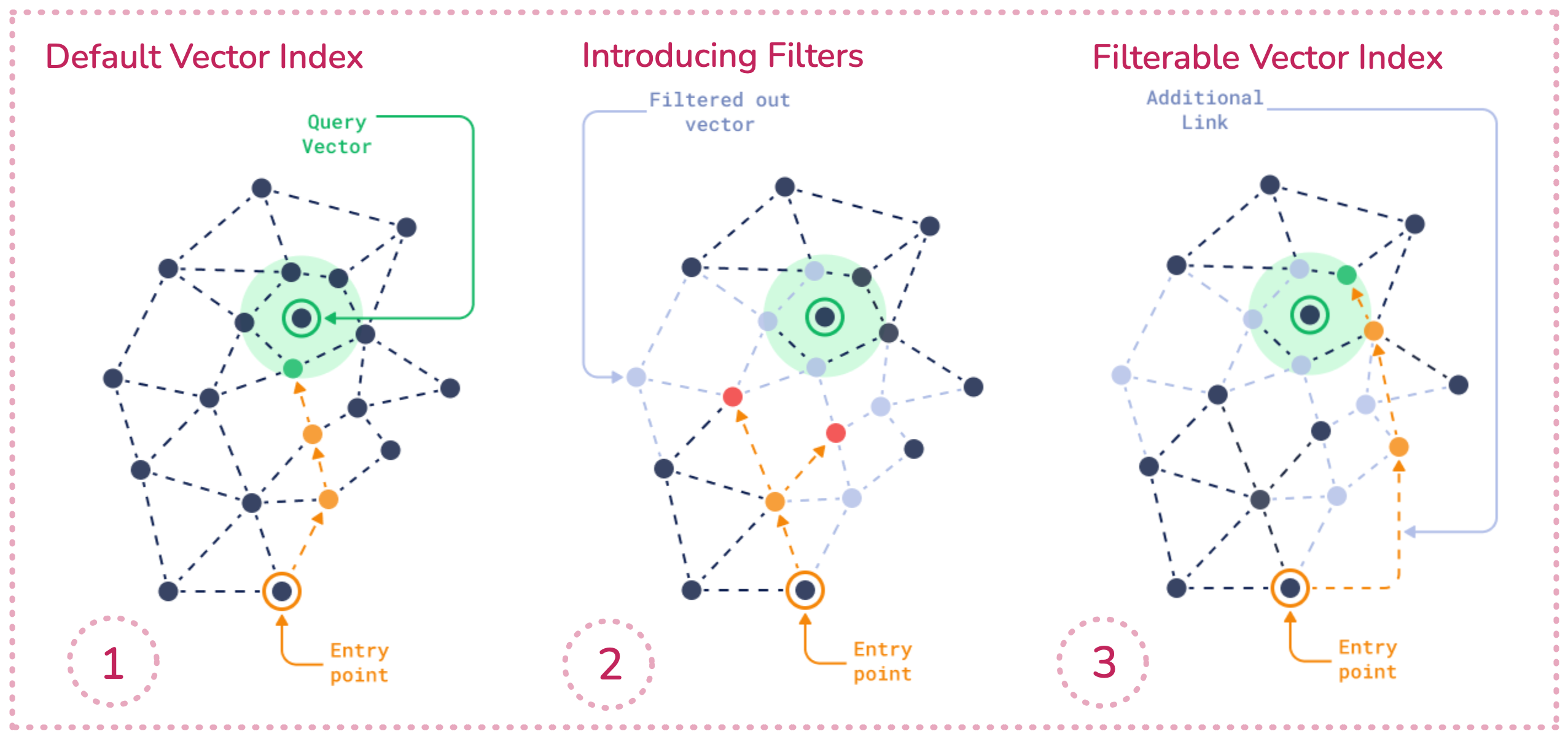
Filterable vector index: This technique builds additional links (orange) between leftover data points. The filtered points which stay behind are now traversible once again. Qdrant uses special category-based methods to connect these data points.
Qdrant’s approach vs traditional filtering methods

The filterable vector index is Qdrant’s solves pre and post-filtering problems by adding specialized links to the search graph. It aims to maintain the speed advantages of vector search while allowing for precise filtering, addressing the inefficiencies that can occur when applying filters after the vector search.
Pre-filtering
In pre-filtering, a search engine first narrows down the dataset based on chosen metadata values, and then searches within that filtered subset. This reduces unnecessary computation over a dataset that is potentially much larger.
The choice between pre-filtering and using the filterable HNSW index depends on filter cardinality. When metadata cardinality is too low, the filter becomes restrictive and it can disrupt the connections within the graph. This leads to fragmented search paths (as in Figure 1). When the semantic search process begins, it won’t be able to travel to those locations.
However, Qdrant still benefits from pre-filtering under certain conditions. In cases of low cardinality, Qdrant’s query planner stops using HNSW and switches over to the payload index alone. This makes the search process much cheaper and faster than if using HNSW.
Figure 2: On the user side, this is how filtering looks. We start with five products with different prices. First, the $1000 price filter is applied, narrowing down the selection of laptops. Then, a vector search finds the relevant results within this filtered set.
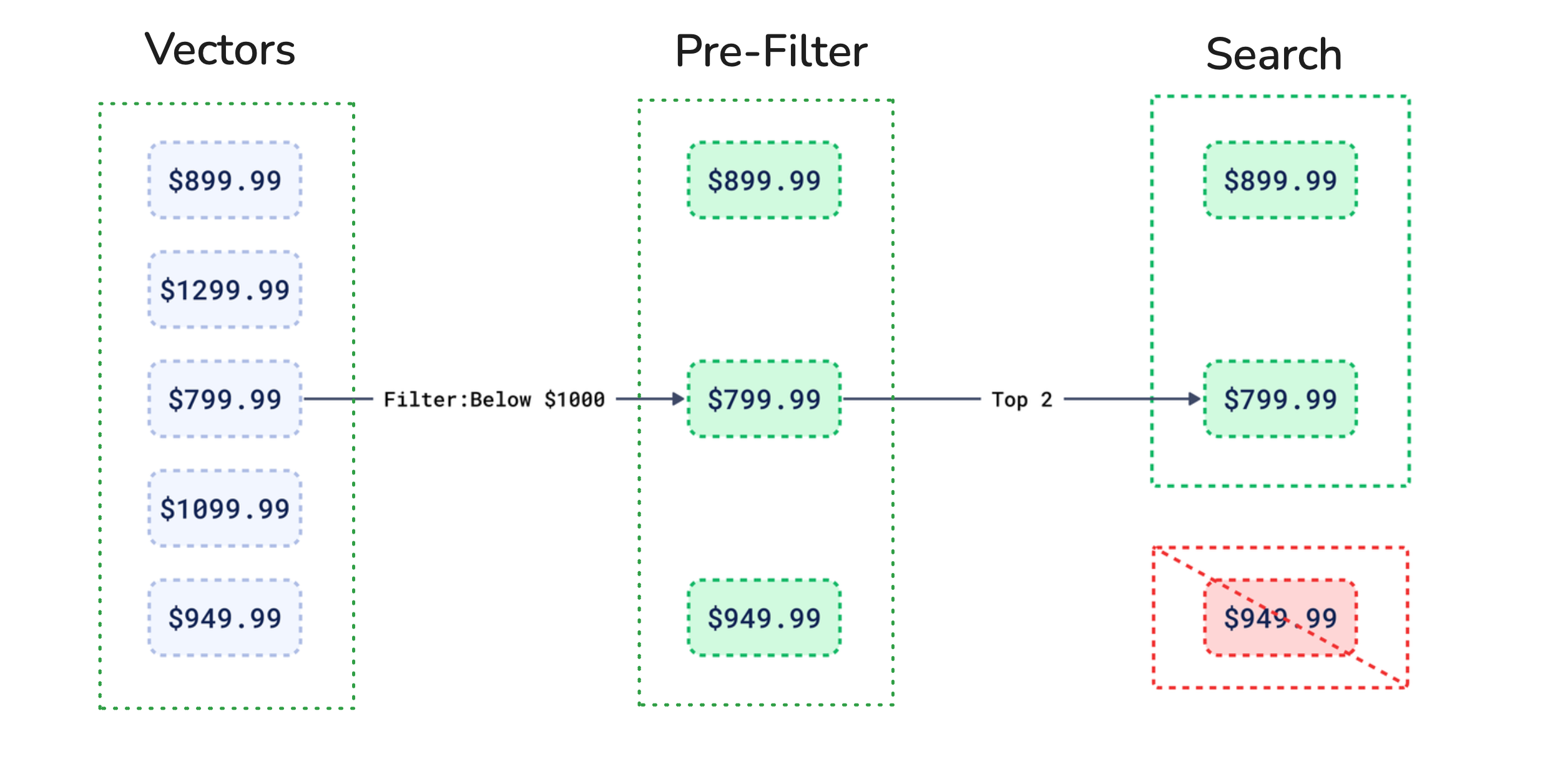
In conclusion, pre-filtering is efficient in specific cases when you use small datasets with low cardinality metadata. However, pre-filtering should not be used over large datasets as it breaks too many links in the HNSW graph, causing lower accuracy.
Post-filtering
In post-filtering, a search engine first looks for similar vectors and retrieves a larger set of results. Then, it applies filters to those results based on metadata. The problem with post-filtering becomes apparent when using low-cardinality filters.
When you apply a low-cardinality filter after performing a vector search, you often end up discarding a large portion of the results that the vector search returned.
Figure 3: In the same example, we have five laptops. First, the vector search finds the top two relevant results, but they may not meet the price match. When the $1000 price filter is applied, other potential results are discarded.
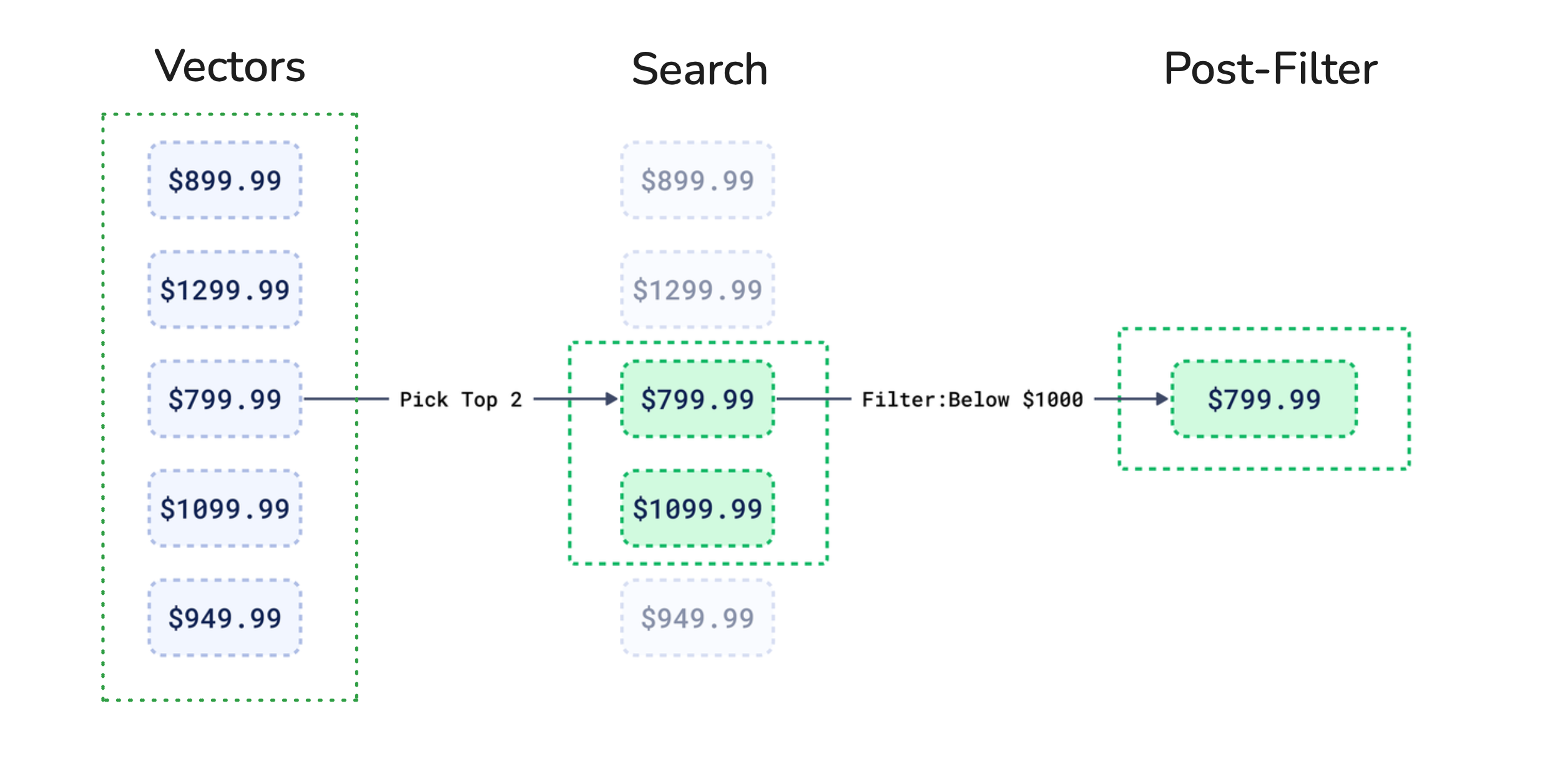
The system will waste computational resources by first finding similar vectors and then discarding many that don’t meet the filter criteria. You’re also limited to filtering only from the initial set of vector search results. If your desired items aren’t in this initial set, you won’t find them, even if they exist in the database.
Basic filtering example: ecommerce and laptops
We know that there are three possible laptops that suit our price point. Let’s see how Qdrant’s filterable vector index works and why it is the best method of capturing all available results.
First, add five new laptops to your online store. Here is a sample input:
laptops = [
(1, [0.1, 0.2, 0.3, 0.4], {"price": 899.99, "category": "laptop"}),
(2, [0.2, 0.3, 0.4, 0.5], {"price": 1299.99, "category": "laptop"}),
(3, [0.3, 0.4, 0.5, 0.6], {"price": 799.99, "category": "laptop"}),
(4, [0.4, 0.5, 0.6, 0.7], {"price": 1099.99, "category": "laptop"}),
(5, [0.5, 0.6, 0.7, 0.8], {"price": 949.99, "category": "laptop"})
]
The four-dimensional vector can represent features like laptop CPU, RAM or battery life, but that isn’t specified. The payload, however, specifies the exact price and product category.
Now, set the filter to “price is less than $1000”:
{
"key": "price",
"range": {
"gt": null,
"gte": null,
"lt": null,
"lte": 1000
}
}
When a price filter of equal/less than $1000 is applied, vector search returns the following results:
[
{
"id": 3,
"score": 0.9978443564622781,
"payload": {
"price": 799.99,
"category": "laptop"
}
},
{
"id": 1,
"score": 0.9938079894227599,
"payload": {
"price": 899.99,
"category": "laptop"
}
},
{
"id": 5,
"score": 0.9903751498208603,
"payload": {
"price": 949.99,
"category": "laptop"
}
}
]
As you can see, Qdrant’s filtering method has a greater chance of capturing all possible search results.
This specific example uses the range condition for filtering. Qdrant, however, offers many other possible ways to structure a filter
For detailed usage examples, filtering docs are the best resource.
Scrolling instead of searching
You don’t need to use our search and query APIs to filter through data. The scroll API is another option that lets you retrieve lists of points which meet the filters.
If you aren’t interested in finding similar points, you can simply list the ones that match a given filter. While search gives you the most similar points based on some query vector, scroll will give you all points matching your filter not considering similarity.
In Qdrant, scrolling is used to iteratively retrieve large sets of points from a collection. It is particularly useful when you’re dealing with a large number of points and don’t want to load them all at once. Instead, Qdrant provides a way to scroll through the points one page at a time.
You start by sending a scroll request to Qdrant with specific conditions like filtering by payload, vector search, or other criteria.
Let’s retrieve a list of top 10 laptops ordered by price in the store:
POST /collections/online_store/points/scroll
{
"filter": {
"must": [
{
"key": "category",
"match": {
"value": "laptop"
}
}
]
},
"limit": 10,
"with_payload": true,
"with_vector": false,
"order_by": [
{
"key": "price",
}
]
}
The response contains a batch of points that match the criteria and a reference (offset or next page token) to retrieve the next set of points.
Scrolling is designed to be efficient. It minimizes the load on the server and reduces memory consumption on the client side by returning only manageable chunks of data at a time.
Available filtering conditions
| Condition | Usage | Condition | Usage |
|---|---|---|---|
| Match | Exact value match. | Range | Filter by value range. |
| Match Any | Match multiple values. | Datetime Range | Filter by date range. |
| Match Except | Exclude specific values. | UUID Match | Filter by unique ID. |
| Nested Key | Filter by nested data. | Geo | Filter by location. |
| Nested Object | Filter by nested objects. | Values Count | Filter by element count. |
| Full Text Match | Search in text fields. | Is Empty | Filter empty fields. |
| Has ID | Filter by unique ID. | Is Null | Filter null values. |
All clauses and conditions are outlined in Qdrant’s filtering documentation.
Filtering clauses to remember
| Clause | Description | Clause | Description |
|---|---|---|---|
| Must | Includes items that meet the condition(similar to AND). | Should | Filters if at least one condition is met(similar to OR). |
| Must Not | Excludes items that meet the condition(similar to NOT). | Clauses Combination | Combines multiple clauses to refine filtering(similar to AND). |
Advanced filtering example: dinosaur diets

We can also use nested filtering to query arrays of objects within the payload. In this example, we have two points. They each represent a dinosaur with a list of food preferences (diet) that indicate what type of food they like or dislike:
[
{
"id": 1,
"dinosaur": "t-rex",
"diet": [
{ "food": "leaves", "likes": false},
{ "food": "meat", "likes": true}
]
},
{
"id": 2,
"dinosaur": "diplodocus",
"diet": [
{ "food": "leaves", "likes": true},
{ "food": "meat", "likes": false}
]
}
]
To ensure that both conditions are applied to the same array element (e.g., food = meat and likes = true must refer to the same diet item), you need to use a nested filter.
Nested filters are used to apply conditions within an array of objects. They ensure that the conditions are evaluated per array element, rather than across all elements.
POST /collections/dinosaurs/points/scroll
{
"filter": {
"must": [
{
"key": "diet[].food",
"match": {
"value": "meat"
}
},
{
"key": "diet[].likes",
"match": {
"value": true
}
}
]
}
}
client.scroll(
collection_name="dinosaurs",
scroll_filter=models.Filter(
must=[
models.FieldCondition(
key="diet[].food", match=models.MatchValue(value="meat")
),
models.FieldCondition(
key="diet[].likes", match=models.MatchValue(value=True)
),
],
),
)
client.scroll("dinosaurs", {
filter: {
must: [
{
key: "diet[].food",
match: { value: "meat" },
},
{
key: "diet[].likes",
match: { value: true },
},
],
},
});
use qdrant_client::qdrant::{Condition, Filter, ScrollPointsBuilder};
client
.scroll(
ScrollPointsBuilder::new("dinosaurs").filter(Filter::must([
Condition::matches("diet[].food", "meat".to_string()),
Condition::matches("diet[].likes", true),
])),
)
.await?;
import java.util.List;
import static io.qdrant.client.ConditionFactory.match;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Common.Filter;
import io.qdrant.client.grpc.Points.ScrollPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.scrollAsync(
ScrollPoints.newBuilder()
.setCollectionName("dinosaurs")
.setFilter(
Filter.newBuilder()
.addAllMust(
List.of(matchKeyword("diet[].food", "meat"), match("diet[].likes", true)))
.build())
.build())
.get();
using Qdrant.Client;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.ScrollAsync(
collectionName: "dinosaurs",
filter: MatchKeyword("diet[].food", "meat") & Match("diet[].likes", true)
);
This happens because both points are matching the two conditions:
- the “t-rex” matches food=meat on
diet[1].foodand likes=true ondiet[1].likes - the “diplodocus” matches food=meat on
diet[1].foodand likes=true ondiet[0].likes
To retrieve only the points where the conditions apply to a specific element within an array (such as the point with id 1 in this example), you need to use a nested object filter.
Nested object filters enable querying arrays of objects independently, ensuring conditions are checked within individual array elements.
This is done by using the nested condition type, which consists of a payload key that targets an array and a filter to apply. The key should reference an array of objects and can be written with or without bracket notation (e.g., “data” or “data[]”).
POST /collections/dinosaurs/points/scroll
{
"filter": {
"must": [{
"nested": {
"key": "diet",
"filter":{
"must": [
{
"key": "food",
"match": {
"value": "meat"
}
},
{
"key": "likes",
"match": {
"value": true
}
}
]
}
}
}]
}
}
client.scroll(
collection_name="dinosaurs",
scroll_filter=models.Filter(
must=[
models.NestedCondition(
nested=models.Nested(
key="diet",
filter=models.Filter(
must=[
models.FieldCondition(
key="food", match=models.MatchValue(value="meat")
),
models.FieldCondition(
key="likes", match=models.MatchValue(value=True)
),
]
),
)
)
],
),
)
client.scroll("dinosaurs", {
filter: {
must: [
{
nested: {
key: "diet",
filter: {
must: [
{
key: "food",
match: { value: "meat" },
},
{
key: "likes",
match: { value: true },
},
],
},
},
},
],
},
});
use qdrant_client::qdrant::{Condition, Filter, NestedCondition, ScrollPointsBuilder};
client
.scroll(
ScrollPointsBuilder::new("dinosaurs").filter(Filter::must([NestedCondition {
key: "diet".to_string(),
filter: Some(Filter::must([
Condition::matches("food", "meat".to_string()),
Condition::matches("likes", true),
])),
}
.into()])),
)
.await?;
import java.util.List;
import static io.qdrant.client.ConditionFactory.match;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import static io.qdrant.client.ConditionFactory.nested;
import io.qdrant.client.grpc.Common.Filter;
import io.qdrant.client.grpc.Points.ScrollPoints;
client
.scrollAsync(
ScrollPoints.newBuilder()
.setCollectionName("dinosaurs")
.setFilter(
Filter.newBuilder()
.addMust(
nested(
"diet",
Filter.newBuilder()
.addAllMust(
List.of(
matchKeyword("food", "meat"), match("likes", true)))
.build()))
.build())
.build())
.get();
using Qdrant.Client;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.ScrollAsync(
collectionName: "dinosaurs",
filter: Nested("diet", MatchKeyword("food", "meat") & Match("likes", true))
);
The matching logic is adjusted to operate at the level of individual elements within an array in the payload, rather than on all array elements together.
Nested filters function as though each element of the array is evaluated separately. The parent document will be considered a match if at least one array element satisfies all the nested filter conditions.
Other creative uses for filters
You can use filters to retrieve data points without knowing their id. You can search through data and manage it, solely by using filters. Let’s take a look at some creative uses for filters:
| Action | Description | Action | Description |
|---|---|---|---|
| Delete Points | Deletes all points matching the filter. | Set Payload | Adds payload fields to all points matching the filter. |
| Scroll Points | Lists all points matching the filter. | Update Payload | Updates payload fields for points matching the filter. |
| Order Points | Lists all points, sorted by the filter. | Delete Payload | Deletes fields for points matching the filter. |
| Count Points | Totals the points matching the filter. |
Filtering with the payload index

When you start working with Qdrant, your data is by default organized in a vector index. In addition to this, we recommend adding a secondary data structure - the payload index.
Just how the vector index organizes vectors, the payload index will structure your metadata.
Figure 4: The payload index is an additional data structure that supports vector search. A payload index (in green) organizes candidate results by cardinality, so that semantic search (in red) can traverse the vector index quickly.
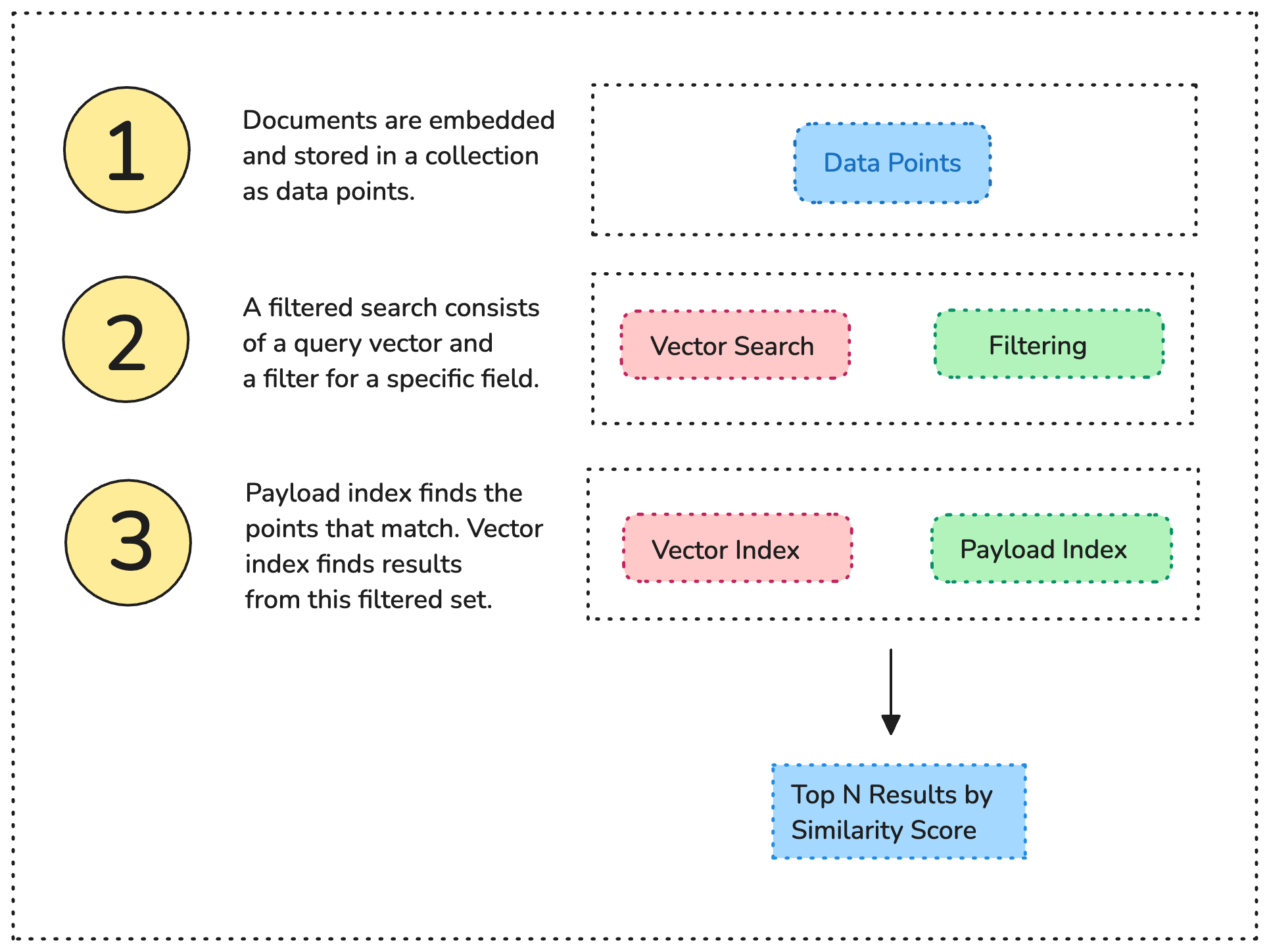
On its own, semantic searching over terabytes of data can take up lots of RAM. Filtering and Indexing are two easy strategies to reduce your compute usage and still get the best results. Remember, this is only a guide. For an exhaustive list of filtering options, you should read the filtering documentation.
Here is how you can create a single index for a metadata field “category”:
PUT /collections/computers/index
{
"field_name": "category",
"field_schema": "keyword"
}
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.create_payload_index(
collection_name="computers",
field_name="category",
field_schema="keyword",
)
Once you mark a field indexable, you don’t need to do anything else. Qdrant will handle all optimizations in the background.
Why should you index metadata?

The payload index acts as a secondary data structure that speeds up retrieval. Whenever you run vector search with a filter, Qdrant will consult a payload index - if there is one.
As your dataset grows in complexity, Qdrant takes up additional resources to go through all data points. Without a proper data structure, the search can take longer - or run out of resources.
Payload indexing helps evaluate the most restrictive filters
The payload index is also used to accurately estimate filter cardinality, which helps the query planning choose a search strategy. Filter cardinality refers to the number of distinct values that a filter can match within a dataset. Qdrant’s search strategy can switch from HNSW search to payload index-based search if the cardinality is too low.
How it affects your queries: Depending on the filter used in the search - there are several possible scenarios for query execution. Qdrant chooses one of the query execution options depending on the available indexes, the complexity of the conditions and the cardinality of the filtering result.
- The planner estimates the cardinality of a filtered result before selecting a strategy.
- Qdrant retrieves points using the payload index if cardinality is below threshold.
- Qdrant uses the filterable vector index if the cardinality is above a threshold
What happens if you don’t use payload indexes?
When using filters while querying, Qdrant needs to estimate cardinality of those filters to define a proper query plan. If you don’t create a payload index, Qdrant will not be able to do this. It may end up choosing a sub-optimal way of searching causing extremely slow search times or low accuracy results.
If you only rely on searching for the nearest vector, Qdrant will have to go through the entire vector index. It will calculate similarities against each vector in the collection, relevant or not. Alternatively, when you filter with the help of a payload index, the HSNW algorithm won’t have to evaluate every point. Furthermore, the payload index will help HNSW construct the graph with additional links.
How does the payload index look?
A payload index is similar to conventional document-oriented databases. It connects metadata fields with their corresponding point id’s for quick retrieval.
In this example, you are indexing all of your computer hardware inside of the computers collection. Let’s take a look at a sample payload index for the field category.
Payload Index by keyword:
+------------+-------------+
| category | id |
+------------+-------------+
| laptop | 1, 4, 7 |
| desktop | 2, 5, 9 |
| speakers | 3, 6, 8 |
| keyboard | 10, 11 |
+------------+-------------+
When fields are properly indexed, the search engine roughly knows where it can start its journey. It can start looking up points that contain relevant metadata, and it doesn’t need to scan the entire dataset. This reduces the engine’s workload by a lot. As a result, query results are faster and the system can easily scale.
You may create as many payload indexes as you want, and we recommend you do so for each field that you filter by.
If your users are often filtering by laptop when looking up a product category, indexing all computer metadata will speed up retrieval and make the results more precise.
Different types of payload indexes
| Index Type | Description |
|---|---|
| Full-text Index | Enables efficient text search in large datasets. |
| Tenant Index | For data isolation and retrieval efficiency in multi-tenant architectures. |
| Principal Index | Manages data based on primary entities like users or accounts. |
| On-Disk Index | Stores indexes on disk to manage large datasets without memory usage. |
| Parameterized Index | Allows for dynamic querying, where the index can adapt based on different parameters or conditions provided by the user. Useful for numeric data like prices or timestamps. |
Indexing payloads in multitenant setups
Some applications need to have data segregated, whereby different users need to see different data inside of the same program. When setting up storage for such a complex application, many users think they need multiple databases for segregated users.
We see this quite often. Users very frequently make the mistake of creating a separate collection for each tenant inside of the same cluster. This can quickly exhaust the cluster’s resources. Running vector search through too many collections can start using up too much RAM. You may start seeing out-of-memory (OOM) errors and degraded performance.
To mitigate this, we offer extensive support for multitenant systems, so that you can build an entire global application in one single Qdrant collection.
When creating or updating a collection, you can mark a metadata field as indexable. To mark user_id as a tenant in a shared collection, do the following:
PUT /collections/{collection_name}/index
{
"field_name": "user_id",
"field_schema": {
"type": "keyword",
"is_tenant": true
}
}
Additionally, we offer a way of organizing data efficiently by means of the tenant index. This is another variant of the payload index that makes tenant data more accessible. This time, the request will specify the field as a tenant. This means that you can mark various customer types and user id’s as is_tenant: true.
Read more about setting up tenant defragmentation in multitenant environments,
Key takeaways in filtering and indexing

Filtering with float-point (decimal) numbers
If you filter by the float data type, your search precision may be limited and inaccurate.
Float Datatype numbers have a decimal point and are 64 bits in size. Here is an example:
{
"price": 11.99
}
When you filter for a specific float number, such as 11.99, you may get a different result, like 11.98 or 12.00. With decimals, numbers are rounded differently, so logically identical values may appear different. Unfortunately, searching for exact matches can be unreliable in this case.
To avoid inaccuracies, use a different filtering method. We recommend that you try Range Based Filtering instead of exact matches. This method accounts for minor variations in data, and it boosts performance - especially with large datasets.
Here is a sample JSON range filter for values greater than or equal to 11.99 and less than or equal to the same number. This will retrieve any values within the range of 11.99, including those with additional decimal places.
{
"key": "price",
"range": {
"gt": null,
"gte": 11.99,
"lt": null,
"lte": 11.99
}
}
Working with pagination in queries
When you’re implementing pagination in filtered queries, indexing becomes even more critical. When paginating results, you often need to exclude items you’ve already seen. This is typically managed by applying filters that specify which IDs should not be included in the next set of results.
However, an interesting aspect of Qdrant’s data model is that a single point can have multiple values for the same field, such as different color options for a product. This means that during filtering, an ID might appear multiple times if it matches on different values of the same field.
Proper indexing ensures that these queries are efficient, preventing duplicate results and making pagination smoother.
Conclusion: Real-life use cases of filtering
Filtering in a vector database like Qdrant can significantly enhance search capabilities by enabling more precise and efficient retrieval of data.
As a conclusion to this guide, let’s look at some real-life use cases where filtering is crucial:
| Use Case | Vector Search | Filtering |
|---|---|---|
| E-Commerce Product Search | Search for products by style or visual similarity | Filter by price, color, brand, size, ratings |
| Recommendation Systems | Recommend similar content (e.g., movies, songs) | Filter by release date, genre, etc. (e.g., movies after 2020) |
| Geospatial Search in Ride-Sharing | Find similar drivers or delivery partners | Filter by rating, distance radius, vehicle type |
| Fraud & Anomaly Detection | Detect transactions similar to known fraud cases | Filter by amount, time, location |
Before you go - all the code is in Qdrant’s Dashboard
The easiest way to reach that “Hello World” moment is to try filtering in a live cluster. Our interactive tutorial will show you how to create a cluster, add data and try some filtering clauses.
It’s all in your free cluster!
