FastEmbed: Qdrant's Efficient Python Library for Embedding Generation
Nirant Kasliwal
·October 18, 2023

Data Science and Machine Learning practitioners often find themselves navigating through a labyrinth of models, libraries, and frameworks. Which model to choose, what embedding size, and how to approach tokenizing, are just some questions you are faced with when starting your work. We understood how many data scientists wanted an easier and more intuitive means to do their embedding work. This is why we built FastEmbed, a Python library engineered for speed, efficiency, and usability. We have created easy to use default workflows, handling the 80% use cases in NLP embedding.
Current State of Affairs for Generating Embeddings
Usually you make embedding by utilizing PyTorch or TensorFlow models under the hood. However, using these libraries comes at a cost in terms of ease of use and computational speed. This is at least in part because these are built for both: model inference and improvement e.g. via fine-tuning.
To tackle these problems we built a small library focused on the task of quickly and efficiently creating text embeddings. We also decided to start with only a small sample of best in class transformer models. By keeping it small and focused on a particular use case, we could make our library focused without all the extraneous dependencies. We ship with limited models, quantize the model weights and seamlessly integrate them with the ONNX Runtime. FastEmbed strikes a balance between inference time, resource utilization and performance (recall/accuracy).
Quick Embedding Text Document Example
Here is an example of how simple we have made embedding text documents:
documents: List[str] = [
"Hello, World!",
"fastembed is supported by and maintained by Qdrant."
]
embedding_model = DefaultEmbedding()
embeddings: List[np.ndarray] = list(embedding_model.embed(documents))
These 3 lines of code do a lot of heavy lifting for you: They download the quantized model, load it using ONNXRuntime, and then run a batched embedding creation of your documents.
Code Walkthrough
Let’s delve into a more advanced example code snippet line-by-line:
from fastembed.embedding import DefaultEmbedding
Here, we import the FlagEmbedding class from FastEmbed and alias it as Embedding. This is the core class responsible for generating embeddings based on your chosen text model. This is also the class which you can import directly as DefaultEmbedding which is BAAI/bge-small-en-v1.5
documents: List[str] = [
"passage: Hello, World!",
"query: How is the World?",
"passage: This is an example passage.",
"fastembed is supported by and maintained by Qdrant."
]
In this list called documents, we define four text strings that we want to convert into embeddings.
Note the use of prefixes “passage” and “query” to differentiate the types of embeddings to be generated. This is inherited from the cross-encoder implementation of the BAAI/bge series of models themselves. This is particularly useful for retrieval and we strongly recommend using this as well.
The use of text prefixes like “query” and “passage” isn’t merely syntactic sugar; it informs the algorithm on how to treat the text for embedding generation. A “query” prefix often triggers the model to generate embeddings that are optimized for similarity comparisons, while “passage” embeddings are fine-tuned for contextual understanding. If you omit the prefix, the default behavior is applied, although specifying it is recommended for more nuanced results.
Next, we initialize the Embedding model with the default model: BAAI/bge-small-en-v1.5.
embedding_model = DefaultEmbedding()
The default model and several other models have a context window of a maximum of 512 tokens. This maximum limit comes from the embedding model training and design itself. If you’d like to embed sequences larger than that, we’d recommend using some pooling strategy to get a single vector out of the sequence. For example, you can use the mean of the embeddings of different chunks of a document. This is also what the SBERT Paper recommends
This model strikes a balance between speed and accuracy, ideal for real-world applications.
embeddings: List[np.ndarray] = list(embedding_model.embed(documents))
Finally, we call the embed() method on our embedding_model object, passing in the documents list. The method returns a Python generator, so we convert it to a list to get all the embeddings. These embeddings are NumPy arrays, optimized for fast mathematical operations.
The embed() method returns a list of NumPy arrays, each corresponding to the embedding of a document in your original documents list. The dimensions of these arrays are determined by the model you chose e.g. for “BAAI/bge-small-en-v1.5” it’s a 384-dimensional vector.
You can easily parse these NumPy arrays for any downstream application—be it clustering, similarity comparison, or feeding them into a machine learning model for further analysis.
3 Key Features of FastEmbed
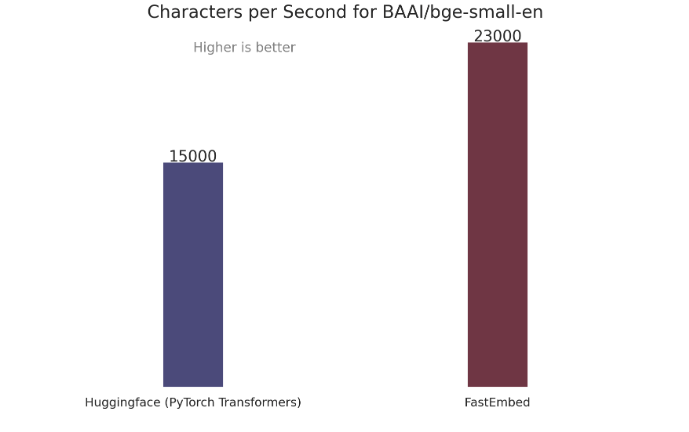
FastEmbed is built for inference speed, without sacrificing (too much) performance:
- 50% faster than PyTorch Transformers
- Better performance than Sentence Transformers and OpenAI Ada-002
- Cosine similarity of quantized and original model vectors is 0.92
We use BAAI/bge-small-en-v1.5 as our DefaultEmbedding, hence we’ve chosen that for comparison:
Under the Hood of FastEmbed
Quantized Models: We quantize the models for CPU (and Mac Metal) – giving you the best buck for your compute model. Our default model is so small, you can run this in AWS Lambda if you’d like!
Shout out to Huggingface’s Optimum – which made it easier to quantize models.
Reduced Installation Time:
FastEmbed sets itself apart by maintaining a low minimum RAM/Disk usage.
It’s designed to be agile and fast, useful for businesses looking to integrate text embedding for production usage. For FastEmbed, the list of dependencies is refreshingly brief:
- onnx: Version ^1.11 – We’ll try to drop this also in the future if we can!
- onnxruntime: Version ^1.15
- tqdm: Version ^4.65 – used only at Download
- requests: Version ^2.31 – used only at Download
- tokenizers: Version ^0.13
This minimized list serves two purposes. First, it significantly reduces the installation time, allowing for quicker deployments. Second, it limits the amount of disk space required, making it a viable option even for environments with storage limitations.
Notably absent from the dependency list are bulky libraries like PyTorch, and there’s no requirement for CUDA drivers. This is intentional. FastEmbed is engineered to deliver optimal performance right on your CPU, eliminating the need for specialized hardware or complex setups.
ONNXRuntime: The ONNXRuntime gives us the ability to support multiple providers. The quantization we do is limited for CPU (Intel), but we intend to support GPU versions of the same in the future as well. This allows for greater customization and optimization, further aligning with your specific performance and computational requirements.
Current Models
We’ve started with a small set of supported models:
All the models we support are quantized to enable even faster computation!
If you’re using FastEmbed and you’ve got ideas or need certain features, feel free to let us know. Just drop an issue on our GitHub page. That’s where we look first when we’re deciding what to work on next. Here’s where you can do it: FastEmbed GitHub Issues.
When it comes to FastEmbed’s DefaultEmbedding model, we’re committed to supporting the best Open Source models.
If anything changes, you’ll see a new version number pop up, like going from 0.0.6 to 0.1. So, it’s a good idea to lock in the FastEmbed version you’re using to avoid surprises.
Using FastEmbed with Qdrant
Qdrant is a Vector Store, offering comprehensive, efficient, and scalable enterprise solutions for modern machine learning and AI applications. Whether you are dealing with billions of data points, require a low latency performant vector database solution, or specialized quantization methods – Qdrant is engineered to meet those demands head-on.
The fusion of FastEmbed with Qdrant’s vector store capabilities enables a transparent workflow for seamless embedding generation, storage, and retrieval. This simplifies the API design — while still giving you the flexibility to make significant changes e.g. you can use FastEmbed to make your own embedding other than the DefaultEmbedding and use that with Qdrant.
Below is a detailed guide on how to get started with FastEmbed in conjunction with Qdrant.
Step 1: Installation
Before diving into the code, the initial step involves installing the Qdrant Client along with the FastEmbed library. This can be done using pip:
pip install qdrant-client[fastembed]
For those using zsh as their shell, you might encounter syntax issues. In such cases, wrap the package name in quotes:
pip install 'qdrant-client[fastembed]'
Step 2: Initializing the Qdrant Client
After successful installation, the next step involves initializing the Qdrant Client. This can be done either in-memory or by specifying a database path:
from qdrant_client import QdrantClient
# Initialize the client
client = QdrantClient(":memory:") # or QdrantClient(path="path/to/db")
Step 3: Preparing Documents, Metadata, and IDs
Once the client is initialized, prepare the text documents you wish to embed, along with any associated metadata and unique IDs:
docs = [
"Qdrant has Langchain integrations",
"Qdrant also has Llama Index integrations"
]
metadata = [
{"source": "Langchain-docs"},
{"source": "LlamaIndex-docs"},
]
ids = [42, 2]
Note that the add method we’ll use is overloaded: If you skip the ids, we’ll generate those for you. metadata is obviously optional. So, you can simply use this too:
docs = [
"Qdrant has Langchain integrations",
"Qdrant also has Llama Index integrations"
]
Step 4: Adding Documents to a Collection
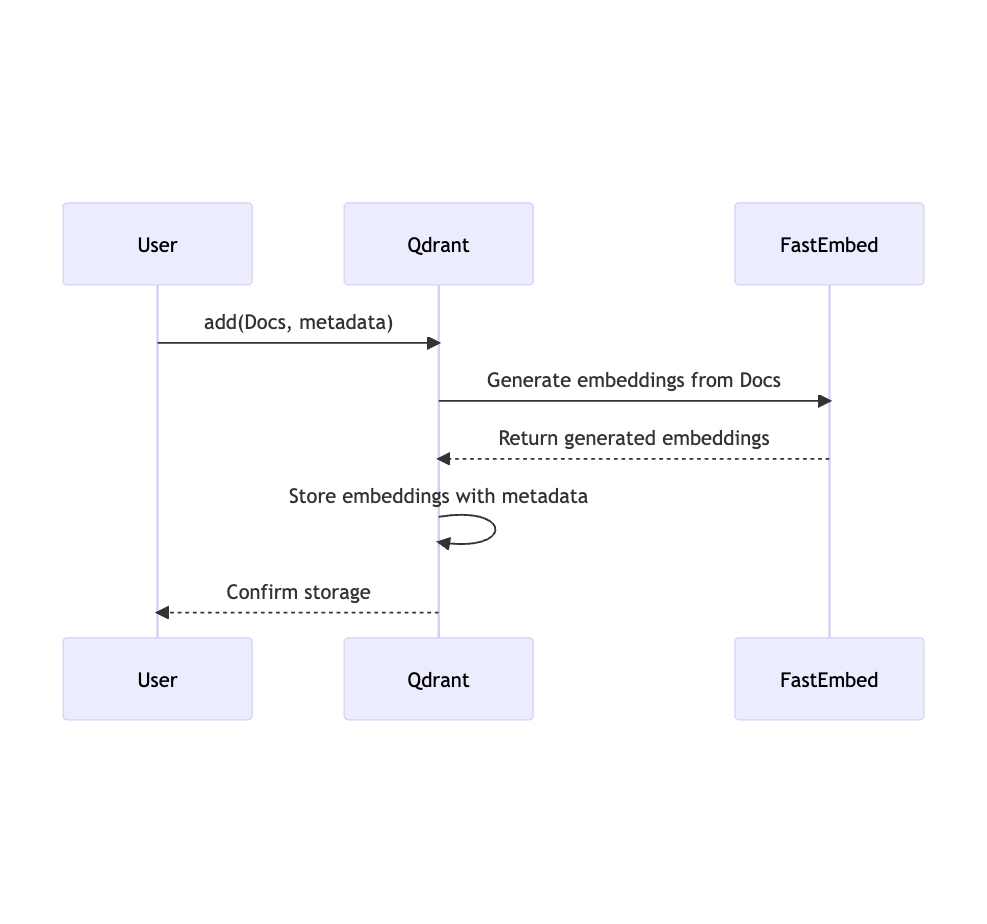
With your documents, metadata, and IDs ready, you can proceed to add these to a specified collection within Qdrant using the add method:
client.add(
collection_name="demo_collection",
documents=docs,
metadata=metadata,
ids=ids
)
Inside this function, Qdrant Client uses FastEmbed to make the text embedding, generate ids if they’re missing, and then add them to the index with metadata. This uses the DefaultEmbedding model: BAAI/bge-small-en-v1.5
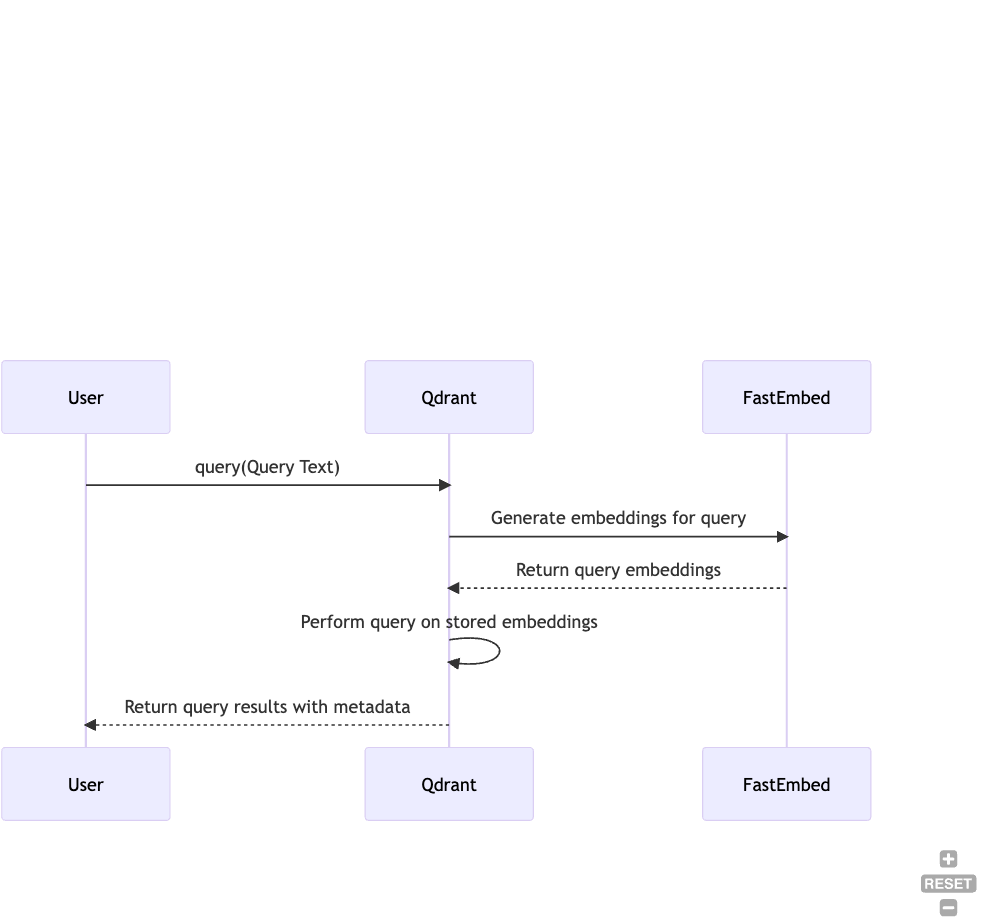
Step 5: Performing Queries
Finally, you can perform queries on your stored documents. Qdrant offers a robust querying capability, and the query results can be easily retrieved as follows:
search_result = client.query(
collection_name="demo_collection",
query_text="This is a query document"
)
print(search_result)
Behind the scenes, we first convert the query_text to the embedding and use that to query the vector index.
By following these steps, you effectively utilize the combined capabilities of FastEmbed and Qdrant, thereby streamlining your embedding generation and retrieval tasks.
Qdrant is designed to handle large-scale datasets with billions of data points. Its architecture employs techniques like binary quantization and scalar quantization for efficient storage and retrieval. When you inject FastEmbed’s CPU-first design and lightweight nature into this equation, you end up with a system that can scale seamlessly while maintaining low latency.
Summary
If you’re curious about how FastEmbed and Qdrant can make your search tasks a breeze, why not take it for a spin? You get a real feel for what it can do. Here are two easy ways to get started:
Cloud: Get started with a free plan on the Qdrant Cloud.
Docker Container: If you’re the DIY type, you can set everything up on your own machine. Here’s a quick guide to help you out: Quick Start with Docker.
So, go ahead, take it for a test drive. We’re excited to hear what you think!
Lastly, If you find FastEmbed useful and want to keep up with what we’re doing, giving our GitHub repo a star would mean a lot to us. Here’s the link to star the repository.
If you ever have questions about FastEmbed, please ask them on the Qdrant Discord: https://discord.gg/Qy6HCJK9Dc