Why Vector Search Needs a Dedicated Database
Evgeniya Sukhodolskaya & Andrey Vasnetsov
·February 17, 2025

Any problem with even a bit of complexity requires a specialized solution. You can use a Swiss Army knife to open a bottle or poke a hole in a cardboard box, but you will need an axe to chop wood — the same goes for software.
In this article, we will describe the unique challenges vector search poses and why a dedicated solution is the best way to tackle them.
Vectors

Let’s look at the central concept of vector databases — vectors.
Vectors (also known as embeddings) are high-dimensional representations of various data points — texts, images, videos, etc. Many state-of-the-art (SOTA) embedding models generate representations of over 1,500 dimensions. When it comes to state-of-the-art PDF retrieval, the representations can reach over 100,000 dimensions per page.
This brings us to the first challenge of vector search — vectors are heavy.
Vectors are Heavy
To put this in perspective, consider one million records stored in a relational database. It’s a relatively small amount of data for modern databases, which a free tier of many cloud providers could easily handle.
Now, generate a 1536-dimensional embedding with OpenAI’s text-embedding-ada-002 model from each record, and you are looking at around 6GB of storage. As a result, vector search workloads, especially if not optimized, will quickly dominate the main use cases of a non-vector database.
Having vectors as a part of a main database is a potential issue for another reason — vectors are always a transformation of other data.
Vectors are a Transformation
Vectors are obtained from some other source-of-truth data. They can be restored if lost with the same embedding model previously used. At the same time, even small changes in that model can shift the geometry of the vector space, so if you update or change the embedding model, you need to update and reindex all the data to maintain accurate vector comparisons.
If coupled with the main database, this update process can lead to significant complications and even unavailability of the whole system.
However, vectors have positive properties as well. One of the most important is that vectors are fixed-size.
Vectors are Fixed-Size
Embedding models are designed to produce vectors of a fixed size. We have to use it to our advantage.
For fast search, vectors need to be instantly accessible. Whether in RAM or disk, vectors should be stored in a format that allows quick access and comparison. This is essential, as vector comparison is a very hot operation in vector search workloads. It is often performed thousands of times per search query, so even a small overhead can lead to a significant slowdown.
For dedicated storage, vectors’ fixed size comes as a blessing. Knowing how much space one data point needs, we don’t have to deal with the usual overhead of locating data — the location of elements in storage is straightforward to calculate.
Everything becomes far less intuitive if vectors are stored together with other data types, for example, texts or JSONs. The size of a single data point is not fixed anymore, so accessing it becomes non-trivial, especially if data is added, updated, and deleted over time.
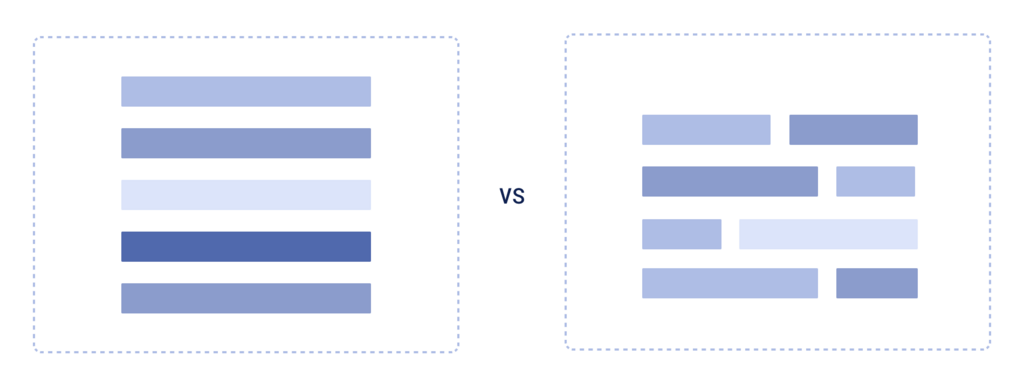
Fixed size columns VS Variable length table
Storing vectors together with other types of data, we lose all the benefits of their characteristics; however, we fully “enjoy” their drawbacks, polluting the storage with an extremely heavy transformation of data already existing in that storage.
Vector Search

Unlike traditional databases that serve as data stores, vector databases are more like search engines. They are designed to be scalable, always available, and capable of delivering high-speed search results even under heavy loads. Just as Google or Bing can handle billions of queries at once, vector databases are designed for scenarios where rapid, high-throughput, low-latency retrieval is a must.
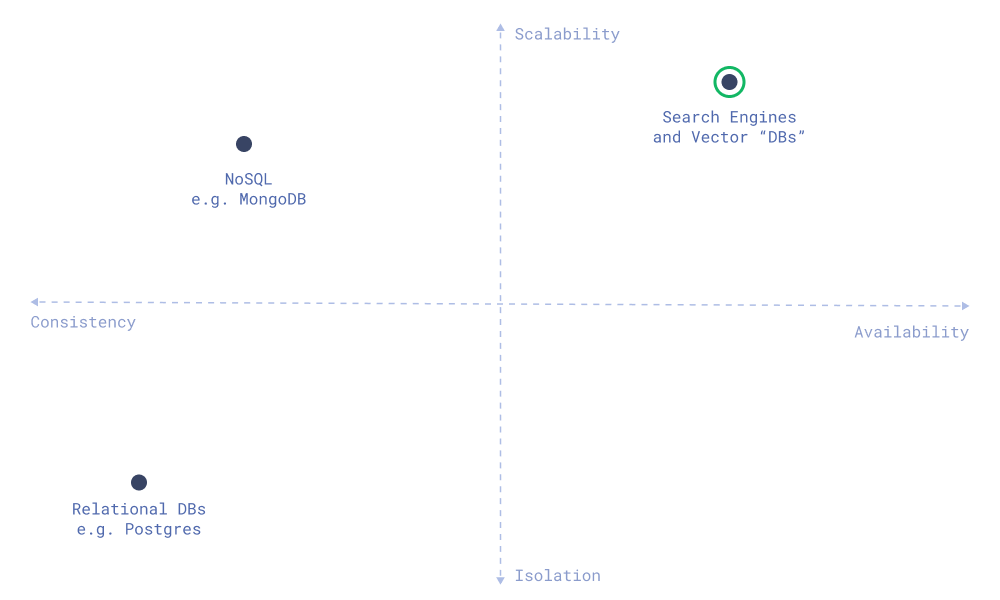
Database Compass
Pick Any Two
Distributed systems are perfect for scalability — horizontal scaling in these systems allows you to add more machines as needed. In the world of distributed systems, one well-known principle — the CAP theorem — illustrates that you cannot have it all. The theorem states that a distributed system can guarantee only two out of three properties: Consistency, Availability, and Partition Tolerance.
As network partitions are inevitable in any real-world distributed system, all modern distributed databases are designed with partition tolerance in mind, forcing a trade-off between consistency (providing the most up-to-date data) and availability (remaining responsive).
There are two main design philosophies for databases in this context:
ACID: Prioritizing Consistency
The ACID model ensures that every transaction (a group of operations treated as a single unit, such as transferring money between accounts) is executed fully or not at all (reverted), leaving the database in a valid state. When a system is distributed, achieving ACID properties requires complex coordination between nodes. Each node must communicate and agree on the state of a transaction, which can limit system availability — if a node is uncertain about the state of another, it may refuse to process a transaction until consistency is assured. This coordination also makes scaling more challenging.
Financial institutions use ACID-compliant databases when dealing with money transfers, where even a momentary discrepancy in an account balance is unacceptable.
BASE: Prioritizing Availability
On the other hand, the BASE model favors high availability and partition tolerance. BASE systems distribute data and workload across multiple nodes, enabling them to respond to read and write requests immediately. They operate under the principle of eventual consistency — although data may be temporarily out-of-date, the system will converge on a consistent state given time.
Social media platforms, streaming services, and search engines all benefit from the BASE approach. For these applications, having immediate responsiveness is more critical than strict consistency.
BASEd Vector Search
Considering the specifics of vector search — its nature demanding availability & scalability — it should be served on BASE-oriented architecture. This choice is made due to the need for horizontal scaling, high availability, low latency, and high throughput. For example, having BASE-focused architecture allows us to easily manage resharding.
A strictly consistent transactional approach also loses its attractiveness when we remember that vectors are heavy transformations of data at our disposal — what’s the point in limiting data protection mechanisms if we can always restore vectorized data through a transformation?
Vector Index

Vector search relies on high-dimensional vector mathematics, making it computationally heavy at scale. A brute-force similarity search would require comparing a query against every vector in the database. In a database with 100 million 1536-dimensional vectors, performing 100 million comparisons per one query is unfeasible for production scenarios. Instead of a brute-force approach, vector databases have specialized approximate nearest neighbour (ANN) indexes that balance search precision and speed. These indexes require carefully designed architectures to make their maintenance in production feasible.
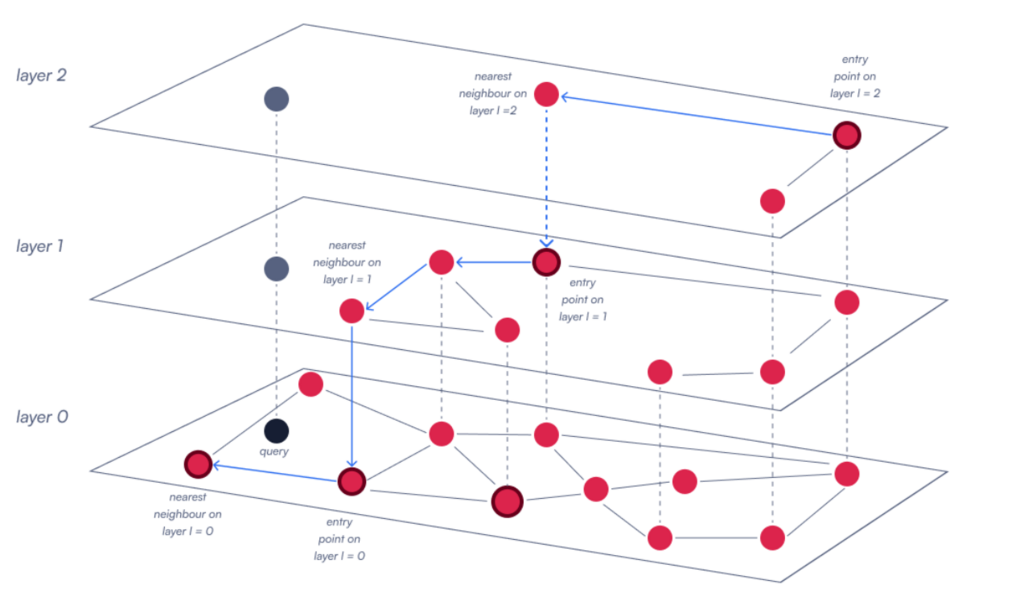
HNSW Index
One of the most popular vector indexes is HNSW (Hierarchical Navigable Small World), which we picked for its capability to provide simultaneously high search speed and accuracy. High performance came with a cost — implementing it in production is untrivial due to several challenges, so to make it shine all the system’s architecture has to be structured around it, serving the capricious index.
Index Complexity
HNSW is structured as a multi-layered graph. With a new data point inserted, the algorithm must compare it to existing nodes across several layers to index it. As the number of vectors grows, these comparisons will noticeably slow down the construction process, making updates increasingly time-consuming. The indexing operation can quickly become the bottleneck in the system, slowing down search requests.
Building an HNSW monolith means limiting the scalability of your solution — its size has to be capped, as its construction time scales non-linearly with the number of elements. To keep the construction process feasible and ensure it doesn’t affect the search time, we came up with a layered architecture that breaks down all data management into small units called segments.
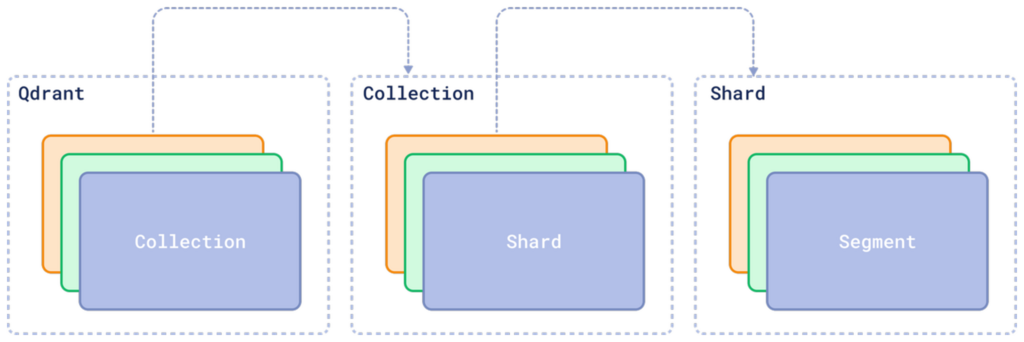
Storage structure
Each segment isolates a subset of vectorized corpora and supports all collection-level operations on it, from searching to indexing, for example segments build their own index on the subset of data available to them. For users working on a collection level, the specifics of segmentation are unnoticeable. The search results they get span the whole collection, as sub-results are gathered from segments and then merged & deduplicated.
By balancing between size and number of segments, we can ensure the right balance between search speed and indexing time, making the system flexible for different workloads.
Immutability
With index maintenance divided between segments, Qdrant can ensure high performance even during heavy load, and additional optimizations secure that further. These optimizations come from an idea that working with immutable structures introduces plenty of benefits: the possibility of using internally fixed sized lists (so no dynamic updates), ordering stored data accordingly to access patterns (so no unpredictable random accesses). With this in mind, to optimize search speed and memory management further, we use a strategy that combines and manages mutable and immutable segments.
| Mutable Segments | These are used for quickly ingesting new data and handling changes (updates) to existing data. |
| Immutable Segments | Once a mutable segment reaches a certain size, an optimization process converts it into an immutable segment, constructing an HNSW index – you could read about these optimizers here in detail. This immutability trick allowed us, for example, to ensure effective tenant isolation. |
Immutable segments are an implementation detail transparent for users — they can delete vectors at any time, while additions and updates are applied to a mutable segment instead. This combination of mutability and immutability allows search and indexing to smoothly run simultaneously, even under heavy loads. This approach minimizes the performance impact of indexing time and allows on-the-fly configuration changes on a collection level (such as enabling or disabling data quantization) without downtimes.
Filterable Index
Vector search wasn’t historically designed for filtering — imposing strict constraints on results. It’s inherently fuzzy; every document is, to some extent, both similar and dissimilar to any query — there’s no binary “fits/doesn’t fit” segregation. As a result, vector search algorithms weren’t originally built with filtering in mind.
At the same time, filtering is unavoidable in many vector search applications, such as e-commerce search/recommendations. Searching for a Christmas present, you might want to filter out everything over 100 euros while still benefiting from the vector search’s semantic nature.
In many vector search solutions, filtering is approached in two ways: pre-filtering (computes a binary mask for all vectors fitting the condition before running HNSW search) or post-filtering (running HNSW as usual and then filtering the results).
| ❌ | Pre-filtering | Has the linear complexity of computing the vector mask and becomes a bottleneck for large datasets. |
| ❌ | Post-filtering | The problem with post-filtering is tied to vector search “everything fits and doesn’t at the same time” nature: imagine a low-cardinality filter that leaves only a few matching elements in the database. If none of them are similar enough to the query to appear in the top-X retrieved results, they’ll all be filtered out. |
Qdrant took filtering in vector search further, recognizing the limitations of pre-filtering & post-filtering strategies. We developed an adaptation of HNSW — filterable HNSW — that also enables in-place filtering during graph traversal. To make this possible, we condition HNSW index construction on possible filtering conditions reflected by payload indexes (inverted indexes built on vectors’ metadata).
Qdrant was designed with a vector index being a central component of the system. That made it possible to organize optimizers, payload indexes and other components around the vector index, unlocking the possibility of building a filterable HNSW.
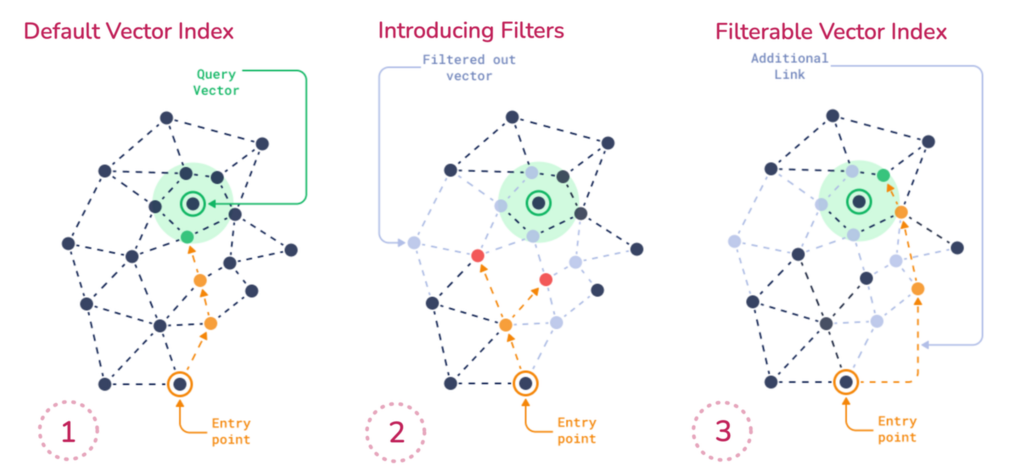
Filterable Vector Index
In general, optimizing vector search requires a custom, finely tuned approach to data and index management that secures high performance even as data grows and changes dynamically. This specialized architecture is the key reason why dedicated vector databases will always outperform general-purpose databases in production settings.
Vector Search Beyond RAG
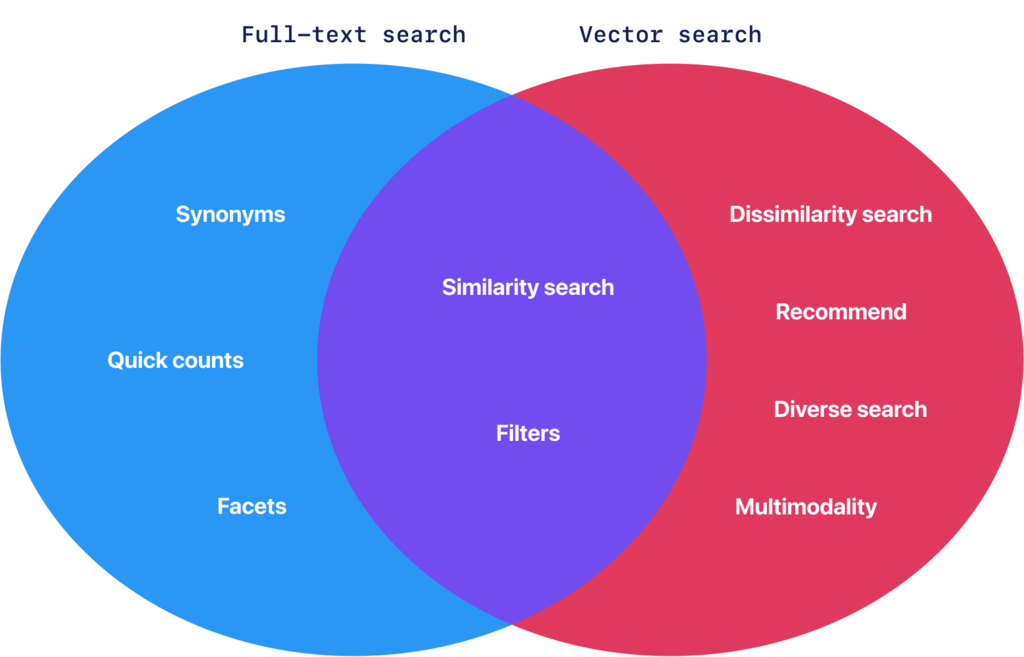
Vector Search is not Text Search Extension
Many discussions about the purpose of vector databases focus on Retrieval-Augmented Generation (RAG) — or its more advanced variant, agentic RAG — where vector databases are used as a knowledge source to retrieve context for large language models (LLMs). This is a legitimate use case, however, the hype wave of RAG solutions has overshadowed the broader potential of vector search, which goes beyond augmenting generative AI.
Discovery
The strength of vector search lies in its ability to facilitate discovery. Vector search allows you to refine your choices as you search rather than starting with a fixed query. Say, you’re ordering food not knowing exactly what you want — just that it should contain meat & not a burger, or that it should be meat with cheese & not tacos. Instead of searching for a specific dish, vector search helps you navigate options based on similarity and dissimilarity, guiding you toward something that matches your taste without requiring you to define it upfront.
Recommendations
Vector search is perfect for recommendations. Imagine browsing for a new book or movie. Instead of searching for an exact match, you might look for stories that capture a certain mood or theme but differ in key aspects from what you already know. For example, you may want a film featuring wizards without the familiar feel of the “Harry Potter” series. This flexibility is possible because vector search is not tied to the binary “match/not match” concept but operates on distances in a vector space.
Big Unstructured Data Analysis
Vector search nature makes it also ideal for big unstructured data analysis, for instance, anomaly detection. In large, unstructured, and often unlabelled datasets, vector search can help identify clusters and outliers by analyzing distance relationships between data points.
Fundamentally Different
Vector search beyond RAG isn’t just another feature — it’s a fundamental shift in how we interact with data. Dedicated solutions integrate these capabilities natively and are designed from the ground up to handle high-dimensional math and (dis-)similarity-based retrieval. In contrast, databases with vector extensions are built around a different data paradigm, making it impossible to efficiently support advanced vector search capabilities.
Even if you want to retrofit these capabilities, it’s not just a matter of adding a new feature — it’s a structural problem. Supporting advanced vector search requires dedicated interfaces that enable flexible usage of vector search from multi-stage filtering to dynamic exploration of high-dimensional spaces.
When the underlying architecture wasn’t initially designed for this kind of interaction, integrating interfaces is a software engineering team nightmare. You end up breaking existing assumptions, forcing inefficient workarounds, and often introducing backwards-compatibility problems. It’s why attempts to patch vector search onto traditional databases won’t match the efficiency of purpose-built systems.
Making Vector Search State-of-the-Art

Now, let’s shift focus to another key advantage of dedicated solutions — their ability to keep up with state-of-the-art solutions in the field.
Vector databases are purpose-built for vector retrieval, and as a result, they offer cutting-edge features that are often critical for AI businesses relying on vector search. Vector database engineers invest significant time and effort into researching and implementing the most optimal ways to perform vector search. Many of these innovations come naturally to vector-native architectures, while general-purpose databases with added vector capabilities may struggle to adapt and replicate these benefits efficiently.
Consider some of the advanced features implemented in Qdrant:
GPU-Accelerated Indexing
By offloading index construction tasks to the GPU, Qdrant can significantly speed up the process of data indexing while keeping costs low. This becomes especially valuable when working with large datasets in hot data scenarios.GPU acceleration in Qdrant is a custom solution developed by an enthusiast from our core team. It’s vendor-free and natively supports all Qdrant’s unique architectural features, from FIlterable HNSW to multivectors.
Multivectors
Some modern embedding models produce an entire matrix (a list of vectors) as output rather than a single vector. Qdrant supports multivectors natively.This feature is critical when using state-of-the-art retrieval models such as ColBERT, ColPali, or ColQwen. For instance, ColPali and ColQwen produce multivector outputs, and supporting them natively is crucial for state-of-the-art (SOTA) PDF-retrieval.
In addition to that, we continuously look for improvements in:
| Memory Efficiency & Compression | Techniques such as quantization and HNSW compression to reduce storage requirements |
| Retrieval Algorithms | Support for the latest retrieval algorithms, including sparse neural retrieval, hybrid search methods, and re-rankers. |
| Vector Data Analysis & Visualization | Tools like the distance matrix API provide insights into vectorized data, and a Web UI allows for intuitive exploration of data. |
| Search Speed & Scalability | Includes optimizations for multi-tenant environments to ensure efficient and scalable search. |
These advancements are not just incremental improvements — they define the difference between a system optimized for vector search and one that accommodates it.
Staying at the cutting edge of vector search is not just about performance — it’s also about keeping pace with an evolving AI landscape.
Summing up

When it comes to vector search, there’s a clear distinction between using a dedicated vector search solution and extending a database to support vector operations.
For small-scale applications or prototypes handling up to a million data points, a non-optimized architecture might suffice. However, as the volume of vectors grows, an unoptimized solution will quickly become a bottleneck — slowing down search operations and limiting scalability. Dedicated vector search solutions are engineered from the ground up to handle massive amounts of high-dimensional data efficiently.
State-of-the-art (SOTA) vector search evolves rapidly. If you plan to build on the latest advances, using a vector extension will eventually hold you back. Dedicated vector search solutions integrate these features natively, ensuring that you benefit from continuous innovations without compromising performance.
The power of vector search extends into areas such as big data analysis, recommendation systems, and discovery-based applications, and to support these vector search capabilities, a dedicated solution is needed.
When to Choose a Dedicated Database over an Extension:
- High-Volume, Real-Time Search: Ideal for applications with many simultaneous users who require fast, continuous access to search results—think search engines, e-commerce recommendations, social media, or media streaming services.
- Dynamic, Unstructured Data: Perfect for scenarios where data is continuously evolving and where the goal is to discover insights from data patterns.
- Innovative Applications: If you’re looking to implement advanced use cases such as recommendation engines, hybrid search solutions, or exploratory data analysis where traditional exact or token-based searches hold short.
Investing in a dedicated vector search engine will deliver the performance and flexibility necessary for success if your application relies on vector search at scale, keeps up with trends, or requires more than just a simple small-scale similarity search.