Qdrant 1.8.0: Enhanced Search Capabilities for Better Results
David Myriel, Mike Jang
·March 06, 2024

Unlocking Next-Level Search: Exploring Qdrant 1.8.0’s Advanced Search Capabilities
Qdrant 1.8.0 is out!. This time around, we have focused on Qdrant’s internals. Our goal was to optimize performance so that your existing setup can run faster and save on compute. Here is what we’ve been up to:
- Faster sparse vectors: Hybrid search is up to 16x faster now!
- CPU resource management: You can allocate CPU threads for faster indexing.
- Better indexing performance: We optimized text indexing on the backend.
Faster search with sparse vectors
Search throughput is now up to 16 times faster for sparse vectors. If you are using Qdrant for hybrid search, this means that you can now handle up to sixteen times as many queries. This improvement comes from extensive backend optimizations aimed at increasing efficiency and capacity.
What this means for your setup:
- Query speed: The time it takes to run a search query has been significantly reduced.
- Search capacity: Qdrant can now handle a much larger volume of search requests.
- User experience: Results will appear faster, leading to a smoother experience for the user.
- Scalability: You can easily accommodate rapidly growing users or an expanding dataset.
Sparse vectors benchmark
Performance results are publicly available for you to test. Qdrant’s R&D developed a dedicated open-source benchmarking tool just to test sparse vector performance.
A real-life simulation of sparse vector queries was run against the NeurIPS 2023 dataset. All tests were done on an 8 CPU machine on Azure.
Latency (y-axis) has dropped significantly for queries. You can see the before/after here:
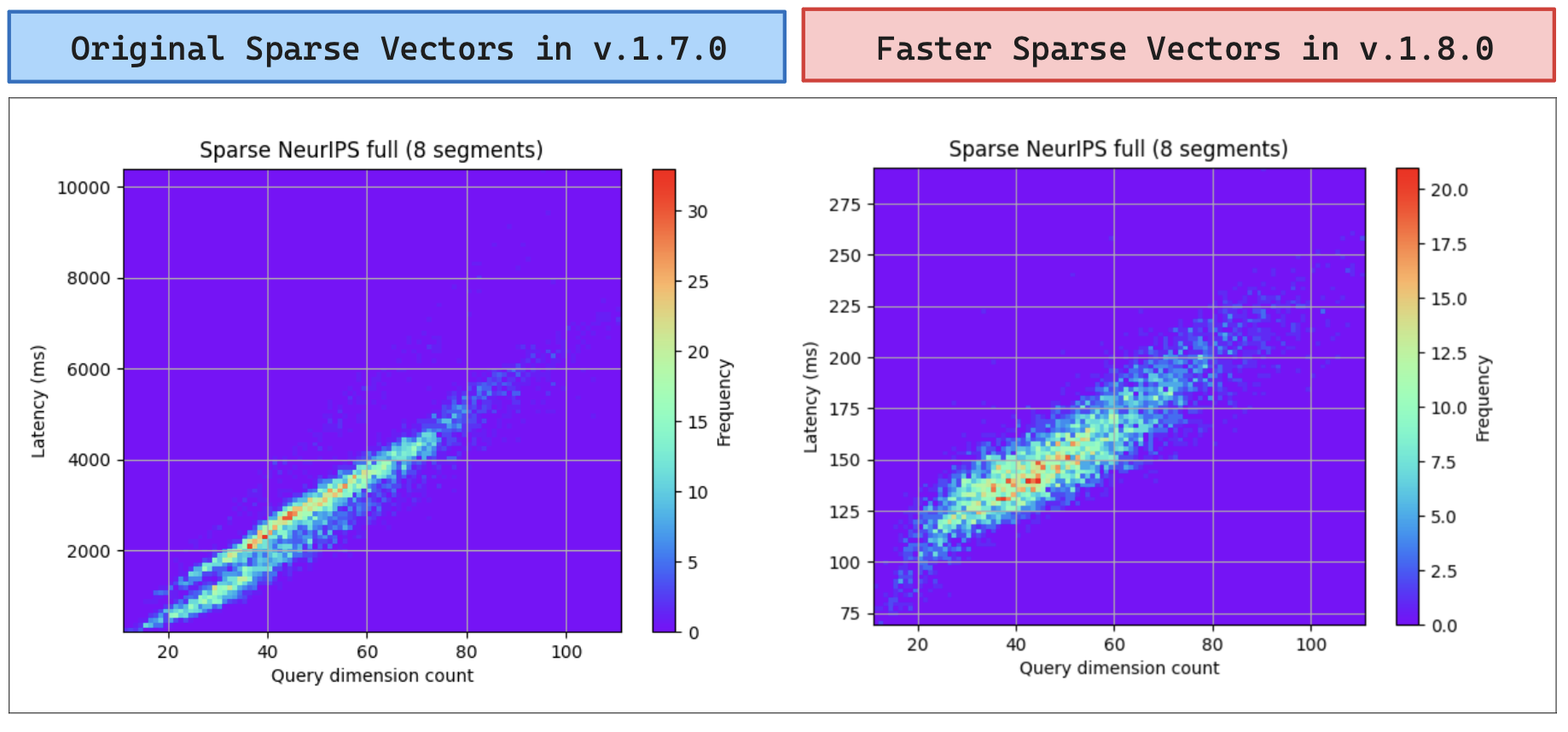 Figure 1: Dropping latency in sparse vector search queries across versions 1.7-1.8.
Figure 1: Dropping latency in sparse vector search queries across versions 1.7-1.8.
The colors within both scatter plots show the frequency of results. The red dots show that the highest concentration is around 2200ms (before) and 135ms (after). This tells us that latency for sparse vector queries dropped by about a factor of 16. Therefore, the time it takes to retrieve an answer with Qdrant is that much shorter.
This performance increase can have a dramatic effect on hybrid search implementations. Read more about how to set this up.
FYI, sparse vectors were released in Qdrant v.1.7.0. They are stored using a different index, so first check out the documentation if you want to try an implementation.
CPU resource management
Indexing is Qdrant’s most resource-intensive process. Now you can account for this by allocating compute use specifically to indexing. You can assign a number CPU resources towards indexing and leave the rest for search. As a result, indexes will build faster, and search quality will remain unaffected.
This isn’t mandatory, as Qdrant is by default tuned to strike the right balance between indexing and search. However, if you wish to define specific CPU usage, you will need to do so from config.yaml.
This version introduces a optimizer_cpu_budget parameter to control the maximum number of CPUs used for indexing.
Read more about
config.yamlin the configuration file.
# CPU budget, how many CPUs (threads) to allocate for an optimization job.
optimizer_cpu_budget: 0
- If left at 0, Qdrant will keep 1 or more CPUs unallocated - depending on CPU size.
- If the setting is positive, Qdrant will use this exact number of CPUs for indexing.
- If the setting is negative, Qdrant will subtract this number of CPUs from the available CPUs for indexing.
For most users, the default optimizer_cpu_budget setting will work well. We only recommend you use this if your indexing load is significant.
Our backend leverages dynamic CPU saturation to increase indexing speed. For that reason, the impact on search query performance ends up being minimal. Ultimately, you will be able to strike the best possible balance between indexing times and search performance.
This configuration can be done at any time, but it requires a restart of Qdrant. Changing it affects both existing and new collections.
Note: This feature is not configurable on Qdrant Cloud.
Better indexing for text data
In order to minimize your RAM expenditure, we have developed a new way to index specific types of data. Please keep in mind that this is a backend improvement, and you won’t need to configure anything.
Going forward, if you are indexing immutable text fields, we estimate a 10% reduction in RAM loads. Our benchmark result is based on a system that uses 64GB of RAM. If you are using less RAM, this reduction might be higher than 10%.
Immutable text fields are static and do not change once they are added to Qdrant. These entries usually represent some type of attribute, description or tag. Vectors associated with them can be indexed more efficiently, since you don’t need to re-index them anymore. Conversely, mutable fields are dynamic and can be modified after their initial creation. Please keep in mind that they will continue to require additional RAM.
This approach ensures stability in the vector search index, with faster and more consistent operations. We achieved this by setting up a field index which helps minimize what is stored. To improve search performance we have also optimized the way we load documents for searches with a text field index. Now our backend loads documents mostly sequentially and in increasing order.
Minor improvements and new features
Beyond these enhancements, Qdrant v1.8.0 adds and improves on several smaller features:
- Order points by payload: In addition to searching for semantic results, you might want to retrieve results by specific metadata (such as price). You can now use Scroll API to order points by payload key.
- Datetime support: We have implemented datetime support for the payload index. Prior to this, if you wanted to search for a specific datetime range, you would have had to convert dates to UNIX timestamps. (PR#3320)
- Check collection existence: You can check whether a collection exists via the
/existsendpoint to the/collections/{collection_name}. You will get a true/false response. (PR#3472). - Find points whose payloads match more than the minimal amount of conditions. We included the
min_shouldmatch feature for a condition to betrue(PR#3331). - Modify nested fields: We have improved the
set_payloadAPI, adding the ability to update nested fields (PR#3548).
Experience the Power of Qdrant 1.8.0
Ready to experience the enhanced performance of Qdrant 1.8.0? Upgrade now and explore the major improvements, from faster sparse vectors to optimized CPU resource management and better indexing for text data. Take your search capabilities to the next level with Qdrant’s latest version. Try a demo today and see the difference firsthand!
Release notes
For more information, see our release notes. Qdrant is an open-source project. We welcome your contributions; raise issues, or contribute via pull requests!