Multivector Representations for Reranking in Qdrant
| Time: 30 min | Level: Intermediate |
|---|
Multivector Representations are one of the most powerful features of Qdrant. However, most people don’t use them effectively, resulting in massive RAM overhead, slow inserts, and wasted compute.
In this tutorial, you’ll discover how to effectively use multivector representations in Qdrant.
What are Multivector Representations?
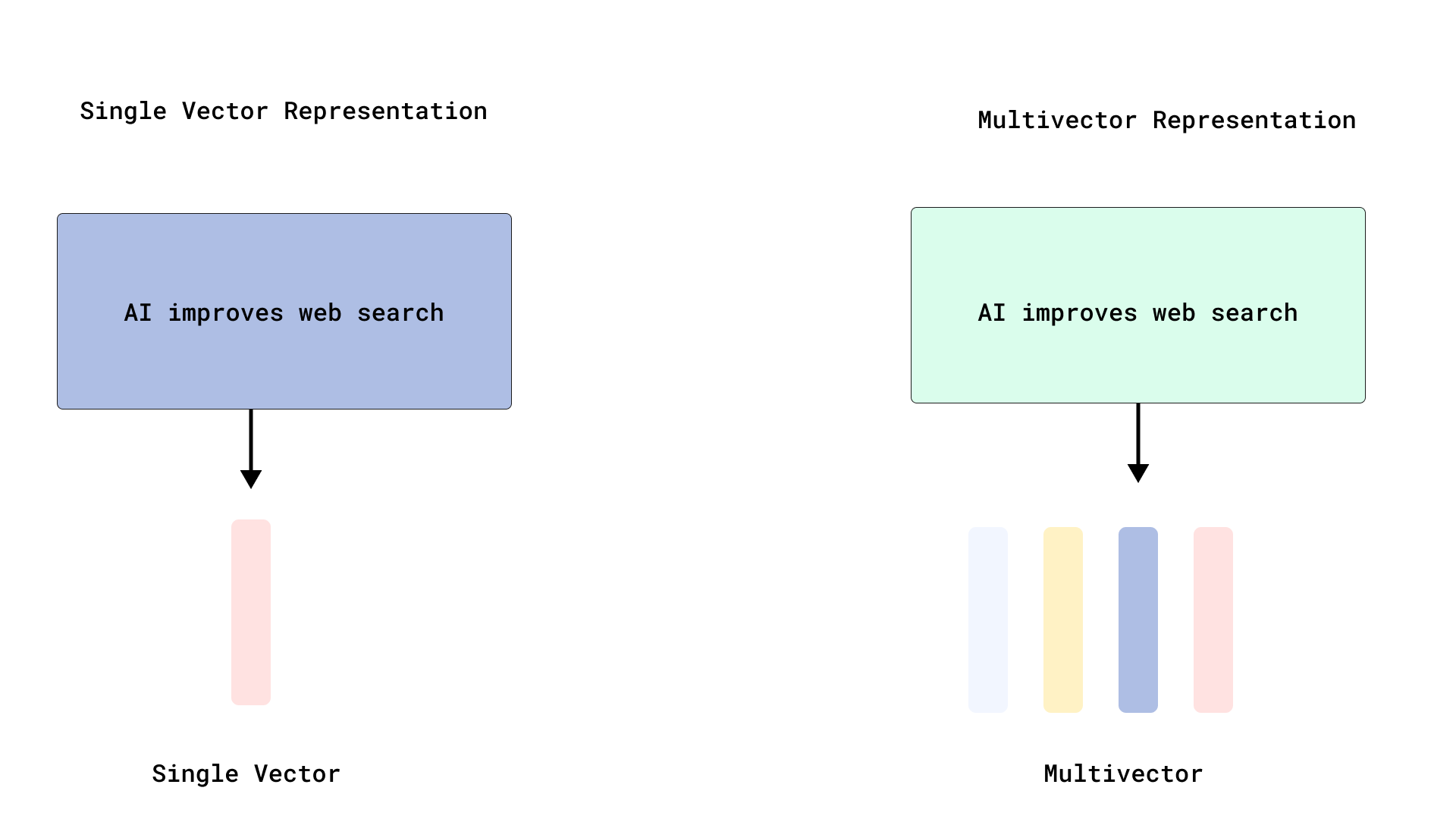
In most vector engines, each document is represented by a single vector - an approach that works well for short texts but often struggles with longer documents. Single vector representations perform pooling of the token-level embeddings, which obviously leads to losing some information.
Multivector representations offer a more fine-grained alternative where a single document is represented using multiple vectors, often at the token or phrase level. This enables more precise matching between specific query terms and relevant parts of the document. Matching is especially effective in Late Interaction models like ColBERT, which retain token-level embeddings and perform interaction during query time leading to relevance scoring.
As you will see later in the tutorial, Qdrant supports multivectors and thus late interaction models natively.
Why Token-level Vectors are Useful
With token-level vectors, models like ColBERT can match specific query tokens to the most relevant parts of a document, enabling high-accuracy retrieval through Late Interaction.
In late interaction, each document is converted into multiple token-level vectors instead of a single vector. The query is also tokenized and embedded into various vectors. Then, the query and document vectors are matched using a similarity function: MaxSim. You can see how it is calculated here.
In traditional retrieval, the query and document are converted into single embeddings, after which similarity is computed. This is an early interaction because the information is compressed before retrieval.
What is Rescoring, and Why is it Used?
Rescoring is two-fold:
- Retrieve relevant documents using a fast model.
- Rerank them using a more accurate but slower model such as ColBERT.
Why Indexing Every Vector by Default is a Problem
In multivector representations (such as those used by Late Interaction models like ColBERT), a single logical document results in hundreds of token-level vectors. Indexing each of these vectors individually with HNSW in Qdrant can lead to:
- High RAM usage
- Slow insert times due to the complexity of maintaining the HNSW graph
However, because multivectors are typically used in the reranking stage (after a first-pass retrieval using dense vectors), there’s often no need to index these token-level vectors with HNSW.
Instead, they can be stored as multi-vector fields (without HNSW indexing) and used at query-time for reranking, which reduces resource overhead and improves performance.
For more on this, check out Qdrant’s detailed breakdown in our Scaling PDF Retrieval with Qdrant tutorial.
With Qdrant, you have full control of how indexing works. You can disable indexing by setting the HNSW m parameter to 0:
from qdrant_client import QdrantClient, models
client = QdrantClient("http://localhost:6333")
collection_name = "dense_multivector_demo"
client.create_collection(
collection_name=collection_name,
vectors_config={
"dense": models.VectorParams(
size=384,
distance=models.Distance.COSINE
# Leave HNSW indexing ON for dense
),
"colbert": models.VectorParams(
size=128,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
hnsw_config=models.HnswConfigDiff(m=0) # Disable HNSW for reranking
)
}
)
By disabling HNSW on multivectors, you:
- Save compute.
- Reduce memory usage.
- Speed up vector uploads.
How to Generate Multivectors Using FastEmbed
Let’s demonstrate how to effectively use multivectors using FastEmbed, which wraps ColBERT into a simple API.
Install FastEmbed and Qdrant:
pip install qdrant-client[fastembed]>=1.14.2
Step-by-Step: ColBERT + Qdrant Setup
Ensure that Qdrant is running and create a client:
from qdrant_client import QdrantClient, models
# 1. Connect to Qdrant server
client = QdrantClient("http://localhost:6333")
1. Encode Documents
Next, encode your documents:
from fastembed import TextEmbedding, LateInteractionTextEmbedding
# Example documents and query
documents = [
"Artificial intelligence is used in hospitals for cancer diagnosis and treatment.",
"Self-driving cars use AI to detect obstacles and make driving decisions.",
"AI is transforming customer service through chatbots and automation.",
# ...
]
query_text = "How does AI help in medicine?"
dense_documents = [
models.Document(text=doc, model="BAAI/bge-small-en")
for doc in documents
]
dense_query = models.Document(text=query_text, model="BAAI/bge-small-en")
colbert_documents = [
models.Document(text=doc, model="colbert-ir/colbertv2.0")
for doc in documents
]
colbert_query = models.Document(text=query_text, model="colbert-ir/colbertv2.0")
2. Create a Qdrant collection
Then create a Qdrant collection with both vector types. Note that we leave indexing on for the dense vector but turn it off for the colbert vector that will be used for reranking.
collection_name = "dense_multivector_demo"
client.create_collection(
collection_name=collection_name,
vectors_config={
"dense": models.VectorParams(
size=384,
distance=models.Distance.COSINE
# Leave HNSW indexing ON for dense
),
"colbert": models.VectorParams(
size=128,
distance=models.Distance.COSINE,
multivector_config=models.MultiVectorConfig(
comparator=models.MultiVectorComparator.MAX_SIM
),
hnsw_config=models.HnswConfigDiff(m=0) # Disable HNSW for reranking
)
}
)
3. Upload Documents (Dense + Multivector)
Now upload the vectors, with batch_size=8. We do not have many documents, but batching is always recommended.
points = [
models.PointStruct(
id=i,
vector={
"dense": dense_documents[i],
"colbert": colbert_documents[i]
},
payload={"text": documents[i]}
) for i in range(len(documents))
]
client.upload_points(
collection_name="dense_multivector_demo",
points=points,
batch_size=8
)
Query with Retrieval + Reranking in One Call
Now let’s run a search:
results = client.query_points(
collection_name="dense_multivector_demo",
prefetch=models.Prefetch(
query=dense_query,
using="dense",
),
query=colbert_query,
using="colbert",
limit=3,
with_payload=True
)
- The dense vector retrieves the top candidates quickly.
- The Colbert multivector reranks them using token-level
MaxSimwith fine-grained precision. - Returns the top 3 results.
Conclusion
Multivector search is one of the most powerful features of a vector database when used correctly. With this functionality in Qdrant, you can:
- Store token-level embeddings natively.
- Disable indexing to reduce overhead.
- Run fast retrieval and accurate reranking in one API call.
- Efficiently scale late interaction.
Combining FastEmbed and Qdrant leads to a production-ready pipeline for ColBERT-style reranking without wasting resources. You can do this locally or use Qdrant Cloud. Qdrant offers an easy-to-use API to get started with your search engine, so if you’re ready to dive in, sign up for free at Qdrant Cloud and start building.