Similarity search
Searching for the nearest vectors is at the core of many representational learning applications. Modern neural networks are trained to transform objects into vectors so that objects close in the real world appear close in vector space. It could be, for example, texts with similar meanings, visually similar pictures, or songs of the same genre.
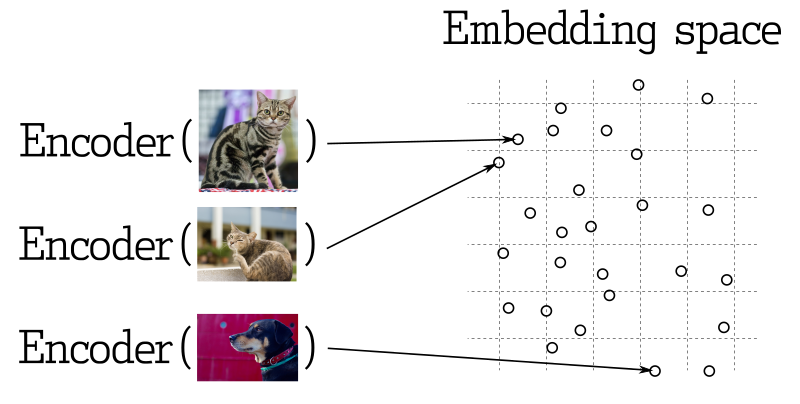
This is how vector similarity works
Query API
Available as of v1.10.0
Qdrant provides a single interface for all kinds of search and exploration requests - the Query API.
Here is a reference list of what kind of queries you can perform with the Query API in Qdrant:
Depending on the query parameter, Qdrant might prefer different strategies for the search.
| Nearest Neighbors Search | Vector Similarity Search, also known as k-NN |
| Search By Id | Search by an already stored vector - skip embedding model inference |
| Recommendations | Provide positive and negative examples |
| Discovery Search | Guide the search using context as a one-shot training set |
| Scroll | Get all points with optional filtering |
| Grouping | Group results by a certain field |
| Order By | Order points by payload key |
| Hybrid Search | Combine multiple queries to get better results |
| Multi-Stage Search | Optimize performance for large embeddings |
| Random Sampling | Get random points from the collection |
Nearest Neighbors Search
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.7] // <--- Dense vector
}
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7], # <--- Dense vector
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7], // <--- Dense vector
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{Query, QueryPointsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(Query::new_nearest(vec![0.2, 0.1, 0.9, 0.7]))
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.List;
QdrantClient client = new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(QueryPoints.newBuilder()
.setCollectionName("{collectionName}")
.setQuery(nearest(List.of(0.2f, 0.1f, 0.9f, 0.7f)))
.build()).get();
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f }
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
})
Search By Id
POST /collections/{collection_name}/points/query
{
"query": "43cf51e2-8777-4f52-bc74-c2cbde0c8b04" // <--- point id
}
client.query_points(
collection_name="{collection_name}",
query="43cf51e2-8777-4f52-bc74-c2cbde0c8b04", # <--- point id
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: '43cf51e2-8777-4f52-bc74-c2cbde0c8b04', // <--- point id
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{PointId, Query, QueryPointsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(Query::new_nearest(PointId::from("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")))
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.UUID;
QdrantClient client = new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(QueryPoints.newBuilder()
.setCollectionName("{collectionName}")
.setQuery(nearest(UUID.fromString("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")))
.build()).get();
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: Guid.Parse("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQueryID(qdrant.NewID("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")),
})
Metrics
There are many ways to estimate the similarity of vectors with each other. In Qdrant terms, these ways are called metrics. The choice of metric depends on the vectors obtained and, in particular, on the neural network encoder training method.
Qdrant supports these most popular types of metrics:
- Dot product:
Dot- https://en.wikipedia.org/wiki/Dot_product - Cosine similarity:
Cosine- https://en.wikipedia.org/wiki/Cosine_similarity - Euclidean distance:
Euclid- https://en.wikipedia.org/wiki/Euclidean_distance - Manhattan distance:
Manhattan*- https://en.wikipedia.org/wiki/Taxicab_geometry *Available as of v1.7
The most typical metric used in similarity learning models is the cosine metric.
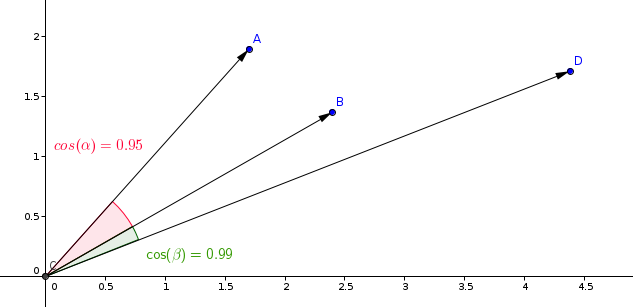
Qdrant counts this metric in 2 steps, due to which a higher search speed is achieved. The first step is to normalize the vector when adding it to the collection. It happens only once for each vector.
The second step is the comparison of vectors. In this case, it becomes equivalent to dot production - a very fast operation due to SIMD.
Depending on the query configuration, Qdrant might prefer different strategies for the search. Read more about it in the query planning section.
Search API
Let’s look at an example of a search query.
REST API - API Schema definition is available here
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.79],
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"limit": 3
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
query_filter=models.Filter(
must=[
models.FieldCondition(
key="city",
match=models.MatchValue(
value="London",
),
)
]
),
search_params=models.SearchParams(hnsw_ef=128, exact=False),
limit=3,
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
filter: {
must: [
{
key: "city",
match: {
value: "London",
},
},
],
},
params: {
hnsw_ef: 128,
exact: false,
},
limit: 3,
});
use qdrant_client::qdrant::{Condition, Filter, QueryPointsBuilder, SearchParamsBuilder};
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(3)
.filter(Filter::must([Condition::matches(
"city",
"London".to_string(),
)]))
.params(SearchParamsBuilder::default().hnsw_ef(128).exact(false)),
)
.await?;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Common.Filter;
import io.qdrant.client.grpc.Points.QueryPoints;
import io.qdrant.client.grpc.Points.SearchParams;
import java.util.List;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setFilter(Filter.newBuilder().addMust(matchKeyword("city", "London")).build())
.setParams(SearchParams.newBuilder().setExact(false).setHnswEf(128).build())
.setLimit(3)
.build()).get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
filter: MatchKeyword("city", "London"),
searchParams: new SearchParams { Exact = false, HnswEf = 128 },
limit: 3
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
Filter: &qdrant.Filter{
Must: []*qdrant.Condition{
qdrant.NewMatch("city", "London"),
},
},
Params: &qdrant.SearchParams{
Exact: qdrant.PtrOf(false),
HnswEf: qdrant.PtrOf(uint64(128)),
},
})
In this example, we are looking for vectors similar to vector [0.2, 0.1, 0.9, 0.7].
Parameter limit (or its alias - top) specifies the amount of most similar results we would like to retrieve.
Values under the key params specify custom parameters for the search.
Currently, it could be:
hnsw_ef- value that specifiesefparameter of the HNSW algorithm.exact- option to not use the approximate search (ANN). If set to true, the search may run for a long as it performs a full scan to retrieve exact results.indexed_only- With this option you can disable the search in those segments where vector index is not built yet. This may be useful if you want to minimize the impact to the search performance whilst the collection is also being updated. Using this option may lead to a partial result if the collection is not fully indexed yet, consider using it only if eventual consistency is acceptable for your use case.quantization- parameters related to quantization. See Searching with Quantization guide.acorn- parameters related to the ACORN search algorithm.
Since the filter parameter is specified, the search is performed only among those points that satisfy the filter condition.
See details of possible filters and their work in the filtering section.
Example result of this API would be
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
The result contains ordered by score list of found point ids.
Note that payload and vector data is missing in these results by default. See payload and vector in the result on how to include it.
If the collection was created with multiple vectors, the name of the vector to use for searching should be provided:
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.7],
"using": "image",
"limit": 3
}
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
using="image",
limit=3,
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
using: "image",
limit: 3,
});
use qdrant_client::qdrant::QueryPointsBuilder;
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(3)
.using("image"),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.List;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setUsing("image")
.setLimit(3)
.build()).get();
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
usingVector: "image",
limit: 3
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
Using: qdrant.PtrOf("image"),
})
Search is processing only among vectors with the same name.
If the collection was created with sparse vectors, the name of the sparse vector to use for searching should be provided:
You can still use payload filtering and other features of the search API with sparse vectors.
There are however important differences between dense and sparse vector search:
| Index | Sparse Query | Dense Query |
|---|---|---|
| Scoring Metric | Default is Dot product, no need to specify it | Distance has supported metrics e.g. Dot, Cosine |
| Search Type | Always exact in Qdrant | HNSW is an approximate NN |
| Return Behaviour | Returns only vectors with non-zero values in the same indices as the query vector | Returns limit vectors |
In general, the speed of the search is proportional to the number of non-zero values in the query vector.
POST /collections/{collection_name}/points/query
{
"query": {
"indices": [1, 3, 5, 7],
"values": [0.1, 0.2, 0.3, 0.4]
},
"using": "text"
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
result = client.query_points(
collection_name="{collection_name}",
query=models.SparseVector(indices=[1, 3, 5, 7], values=[0.1, 0.2, 0.3, 0.4]),
using="text",
).points
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: {
indices: [1, 3, 5, 7],
values: [0.1, 0.2, 0.3, 0.4]
},
using: "text",
limit: 3,
});
use qdrant_client::qdrant::QueryPointsBuilder;
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![(1, 0.2), (3, 0.1), (5, 0.9), (7, 0.7)])
.limit(10)
.using("text"),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.List;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setUsing("text")
.setQuery(nearest(List.of(0.1f, 0.2f, 0.3f, 0.4f), List.of(1, 3, 5, 7)))
.setLimit(3)
.build())
.get();
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new (float, uint)[] {(0.1f, 1), (0.2f, 3), (0.3f, 5), (0.4f, 7)},
usingVector: "text",
limit: 3
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuerySparse(
[]uint32{1, 3, 5, 7},
[]float32{0.1, 0.2, 0.3, 0.4}),
Using: qdrant.PtrOf("text"),
})
Filtering results by score
In addition to payload filtering, it might be useful to filter out results with a low similarity score.
For example, if you know the minimal acceptance score for your model and do not want any results which are less similar than the threshold.
In this case, you can use score_threshold parameter of the search query.
It will exclude all results with a score worse than the given.
Payload and vector in the result
By default, retrieval methods do not return any stored information such as
payload and vectors. Additional parameters with_vectors and with_payload
alter this behavior.
Example:
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
with_vectors=True,
with_payload=True,
)
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
with_vector: true,
with_payload: true,
});
use qdrant_client::qdrant::QueryPointsBuilder;
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(3)
.with_payload(true)
.with_vectors(true),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import static io.qdrant.client.WithPayloadSelectorFactory.enable;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.WithVectorsSelectorFactory;
import io.qdrant.client.grpc.Points.QueryPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setWithPayload(enable(true))
.setWithVectors(WithVectorsSelectorFactory.enable(true))
.setLimit(3)
.build())
.get();
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
payloadSelector: true,
vectorsSelector: true,
limit: 3
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
WithPayload: qdrant.NewWithPayload(true),
WithVectors: qdrant.NewWithVectors(true),
})
You can use with_payload to scope to or filter a specific payload subset.
You can even specify an array of items to include, such as city,
village, and town:
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.7],
"with_payload": ["city", "village", "town"]
}
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
with_payload=["city", "village", "town"],
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
with_payload: ["city", "village", "town"],
});
use qdrant_client::qdrant::{with_payload_selector::SelectorOptions, QueryPointsBuilder};
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(3)
.with_payload(SelectorOptions::Include(
vec![
"city".to_string(),
"village".to_string(),
"town".to_string(),
]
.into(),
))
.with_vectors(true),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import static io.qdrant.client.WithPayloadSelectorFactory.include;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.List;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setWithPayload(include(List.of("city", "village", "town")))
.setLimit(3)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
payloadSelector: new WithPayloadSelector
{
Include = new PayloadIncludeSelector
{
Fields = { new string[] { "city", "village", "town" } }
}
},
limit: 3
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
WithPayload: qdrant.NewWithPayloadInclude("city", "village", "town"),
})
Or use include or exclude explicitly. For example, to exclude city:
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
with_payload=models.PayloadSelectorExclude(
exclude=["city"],
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
with_payload: {
exclude: ["city"],
},
});
use qdrant_client::qdrant::{with_payload_selector::SelectorOptions, QueryPointsBuilder};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(3)
.with_payload(SelectorOptions::Exclude(vec!["city".to_string()].into()))
.with_vectors(true),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import static io.qdrant.client.WithPayloadSelectorFactory.exclude;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.List;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setWithPayload(exclude(List.of("city")))
.setLimit(3)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
payloadSelector: new WithPayloadSelector
{
Exclude = new PayloadExcludeSelector { Fields = { new string[] { "city" } } }
},
limit: 3
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
WithPayload: qdrant.NewWithPayloadExclude("city"),
})
It is possible to target nested fields using a dot notation:
payload.nested_field- for a nested fieldpayload.nested_array[].sub_field- for projecting nested fields within an array
Accessing array elements by index is currently not supported.
ACORN Search Algorithm
Available as of v1.16.0
For filtered vector search, you are recommended to create a payload index for the fields you want to filter by. During the search, Qdrant will use a combined filterable index. However, when combining multiple strict payload filters, this mechanism might not provide sufficient accuracy. In such cases, you can use the ACORN search algorithm.
It is an extension to the regular HNSW search algorithm, based on the ACORN-1 algorithm described in the paper ACORN: Performant and Predicate-Agnostic Search Over Vector Embeddings and Structured Data. During graph traversal, it explores not just direct neighbors (first hop), but also neighbors of neighbors (second hop) when direct neighbors are filtered out. This improves search accuracy at the cost of performance.
Enable it as follows:
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.7],
"params": {
"acorn": {
"enable": true,
"max_selectivity": 0.4
}
},
"limit": 10
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
search_params=models.SearchParams(
acorn=models.AcornSearchParams(
enable=True,
max_selectivity=0.4,
)
),
limit=10,
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
params: {
acorn: {
enable: true,
max_selectivity: 0.4,
},
},
limit: 10,
});
use qdrant_client::qdrant::{
AcornSearchParamsBuilder, QueryPointsBuilder, SearchParamsBuilder,
};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(10)
.params(
SearchParamsBuilder::default().acorn(
AcornSearchParamsBuilder::new(true)
.max_selectivity(0.4),
),
),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.AcornSearchParams;
import io.qdrant.client.grpc.Points.QueryPoints;
import io.qdrant.client.grpc.Points.SearchParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setParams(
SearchParams.newBuilder()
.setAcorn(
AcornSearchParams.newBuilder()
.setEnable(true)
.setMaxSelectivity(0.4)
.build())
.build())
.setLimit(10)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
searchParams: new SearchParams
{
Acorn = new AcornSearchParams
{
Enable = true,
MaxSelectivity = 0.4
}
},
limit: 10
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
Params: &qdrant.SearchParams{
Acorn: &qdrant.AcornSearchParams{
Enable: qdrant.PtrOf(true),
MaxSelectivity: qdrant.PtrOf(0.4),
},
},
})
ACORN is disabled by default.
Once enabled via the enable flag, it activates conditionally when estimated filter selectivity is below the threshold.
The optional max_selectivity value controls this threshold;
0.0 means ACORN will never be used, 1.0 means it will always be used. The default value is 0.4.
Selectivity is estimated as:
Batch search API
The batch search API enables to perform multiple search requests via a single request.
Its semantic is straightforward, n batched search requests are equivalent to n singular search requests.
This approach has several advantages. Logically, fewer network connections are required which can be very beneficial on its own.
More importantly, batched requests will be efficiently processed via the query planner which can detect and optimize requests if they have the same filter.
This can have a great effect on latency for non trivial filters as the intermediary results can be shared among the request.
In order to use it, simply pack together your search requests. All the regular attributes of a search request are of course available.
POST /collections/{collection_name}/points/query/batch
{
"searches": [
{
"query": [0.2, 0.1, 0.9, 0.7],
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"limit": 3
},
{
"query": [0.5, 0.3, 0.2, 0.3],
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"limit": 3
}
]
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
filter_ = models.Filter(
must=[
models.FieldCondition(
key="city",
match=models.MatchValue(
value="London",
),
)
]
)
search_queries = [
models.QueryRequest(query=[0.2, 0.1, 0.9, 0.7], filter=filter_, limit=3),
models.QueryRequest(query=[0.5, 0.3, 0.2, 0.3], filter=filter_, limit=3),
]
client.query_batch_points(collection_name="{collection_name}", requests=search_queries)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
const filter = {
must: [
{
key: "city",
match: {
value: "London",
},
},
],
};
const searches = [
{
query: [0.2, 0.1, 0.9, 0.7],
filter,
limit: 3,
},
{
query: [0.5, 0.3, 0.2, 0.3],
filter,
limit: 3,
},
];
client.queryBatch("{collection_name}", {
searches,
});
use qdrant_client::qdrant::{Condition, Filter, QueryBatchPointsBuilder, QueryPointsBuilder};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
let filter = Filter::must([Condition::matches("city", "London".to_string())]);
let searches = vec![
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.1, 0.2, 0.3, 0.4])
.limit(3)
.filter(filter.clone())
.build(),
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.5, 0.3, 0.2, 0.3])
.limit(3)
.filter(filter)
.build(),
];
client
.query_batch(QueryBatchPointsBuilder::new("{collection_name}", searches))
.await?;
import static io.qdrant.client.ConditionFactory.matchKeyword;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Common.Filter;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.List;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
Filter filter = Filter.newBuilder().addMust(matchKeyword("city", "London")).build();
List<QueryPoints> searches = List.of(
QueryPoints.newBuilder()
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setFilter(filter)
.setLimit(3)
.build(),
QueryPoints.newBuilder()
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setFilter(filter)
.setLimit(3)
.build());
client.queryBatchAsync("{collection_name}", searches).get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
var filter = MatchKeyword("city", "London");
var queries = new List<QueryPoints>
{
new()
{
CollectionName = "{collection_name}",
Query = new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
Filter = filter,
Limit = 3
},
new()
{
CollectionName = "{collection_name}",
Query = new float[] { 0.5f, 0.3f, 0.2f, 0.3f },
Filter = filter,
Limit = 3
}
};
await client.QueryBatchAsync(collectionName: "{collection_name}", queries: queries);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
filter := qdrant.Filter{
Must: []*qdrant.Condition{
qdrant.NewMatch("city", "London"),
},
}
client.QueryBatch(context.Background(), &qdrant.QueryBatchPoints{
CollectionName: "{collection_name}",
QueryPoints: []*qdrant.QueryPoints{
{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
Filter: &filter,
},
{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.5, 0.3, 0.2, 0.3),
Filter: &filter,
},
},
})
The result of this API contains one array per search requests.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Query by ID
Whenever you need to use a vector as an input, you can always use a point ID instead.
POST /collections/{collection_name}/points/query
{
"query": "43cf51e2-8777-4f52-bc74-c2cbde0c8b04" // <--- point id
}
client.query_points(
collection_name="{collection_name}",
query="43cf51e2-8777-4f52-bc74-c2cbde0c8b04", # <--- point id
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: '43cf51e2-8777-4f52-bc74-c2cbde0c8b04', // <--- point id
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{PointId, Query, QueryPointsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(Query::new_nearest(PointId::from("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")))
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.UUID;
QdrantClient client = new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(QueryPoints.newBuilder()
.setCollectionName("{collectionName}")
.setQuery(nearest(UUID.fromString("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")))
.build()).get();
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: Guid.Parse("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQueryID(qdrant.NewID("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")),
})
The above example will fetch the default vector from the point with this id, and use it as the query vector.
If the using parameter is also specified, Qdrant will use the vector with that name.
It is also possible to reference an ID from a different collection, by setting the lookup_from parameter.
POST /collections/{collection_name}/points/query
{
"query": "43cf51e2-8777-4f52-bc74-c2cbde0c8b04", // <--- point id
"using": "512d-vector",
"lookup_from": {
"collection": "another_collection", // <--- other collection name
"vector": "image-512" // <--- vector name in the other collection
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query="43cf51e2-8777-4f52-bc74-c2cbde0c8b04", # <--- point id
using="512d-vector",
lookup_from=models.LookupLocation(
collection="another_collection", # <--- other collection name
vector="image-512", # <--- vector name in the other collection
)
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: '43cf51e2-8777-4f52-bc74-c2cbde0c8b04', // <--- point id
using: '512d-vector',
lookup_from: {
collection: 'another_collection', // <--- other collection name
vector: 'image-512', // <--- vector name in the other collection
}
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{LookupLocationBuilder, Query, QueryPointsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.query(
QueryPointsBuilder::new("{collection_name}")
.query(Query::new_nearest("43cf51e2-8777-4f52-bc74-c2cbde0c8b04"))
.using("512d-vector")
.lookup_from(
LookupLocationBuilder::new("another_collection")
.vector_name("image-512")
)
).await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.LookupLocation;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.UUID;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(UUID.fromString("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")))
.setUsing("512d-vector")
.setLookupFrom(
LookupLocation.newBuilder()
.setCollectionName("another_collection")
.setVectorName("image-512")
.build())
.build())
.get();
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: Guid.Parse("43cf51e2-8777-4f52-bc74-c2cbde0c8b04"), // <--- point id
usingVector: "512d-vector",
lookupFrom: new() {
CollectionName = "another_collection", // <--- other collection name
VectorName = "image-512" // <--- vector name in the other collection
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQueryID(qdrant.NewID("43cf51e2-8777-4f52-bc74-c2cbde0c8b04")),
Using: qdrant.PtrOf("512d-vector"),
LookupFrom: &qdrant.LookupLocation{
CollectionName: "another_collection",
VectorName: qdrant.PtrOf("image-512"),
},
})
In the case above, Qdrant will fetch the "image-512" vector from the specified point id in the
collection another_collection.
Pagination
Search and recommendation APIs allow to skip first results of the search and return only the result starting from some specified offset:
Example:
POST /collections/{collection_name}/points/query
{
"query": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
with_vectors=True,
with_payload=True,
limit=10,
offset=100,
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
query: [0.2, 0.1, 0.9, 0.7],
with_vector: true,
with_payload: true,
limit: 10,
offset: 100,
});
use qdrant_client::qdrant::QueryPointsBuilder;
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(vec![0.2, 0.1, 0.9, 0.7])
.with_payload(true)
.with_vectors(true)
.limit(10)
.offset(100),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import static io.qdrant.client.WithPayloadSelectorFactory.enable;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.WithVectorsSelectorFactory;
import io.qdrant.client.grpc.Points.QueryPoints;
import java.util.List;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setWithPayload(enable(true))
.setWithVectors(WithVectorsSelectorFactory.enable(true))
.setLimit(10)
.setOffset(100)
.build())
.get();
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
payloadSelector: true,
vectorsSelector: true,
limit: 10,
offset: 100
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
WithPayload: qdrant.NewWithPayload(true),
WithVectors: qdrant.NewWithVectors(true),
Offset: qdrant.PtrOf(uint64(100)),
})
Is equivalent to retrieving the 11th page with 10 records per page.
Vector-based retrieval in general and HNSW index in particular, are not designed to be paginated. It is impossible to retrieve Nth closest vector without retrieving the first N vectors first.
However, using the offset parameter saves the resources by reducing network traffic and the number of times the storage is accessed.
Using an offset parameter, will require to internally retrieve offset + limit points, but only access payload and vector from the storage those points which are going to be actually returned.
Grouping API
It is possible to group results by a certain field. This is useful when you have multiple points for the same item, and you want to avoid redundancy of the same item in the results.
For example, if you have a large document split into multiple chunks, and you want to search or recommend on a per-document basis, you can group the results by the document ID.
Consider having points with the following payloads:
[
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a"
},
"vector": [0.91]
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"]
},
"vector": [0.8]
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a"
},
"vector": [0.2]
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123
},
"vector": [0.79]
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123
},
"vector": [0.75]
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10
},
"vector": [0.6]
}
]
With the groups API, you will be able to get the best N points for each document, assuming that the payload of the points contains the document ID. Of course there will be times where the best N points cannot be fulfilled due to lack of points or a big distance with respect to the query. In every case, the group_size is a best-effort parameter, akin to the limit parameter.
Search groups
REST API (Schema):
POST /collections/{collection_name}/points/query/groups
{
// Same as in the regular query API
"query": [1.1],
// Grouping parameters
"group_by": "document_id", // Path of the field to group by
"limit": 4, // Max amount of groups
"group_size": 2 // Max amount of points per group
}
client.query_points_groups(
collection_name="{collection_name}",
# Same as in the regular query_points() API
query=[1.1],
# Grouping parameters
group_by="document_id", # Path of the field to group by
limit=4, # Max amount of groups
group_size=2, # Max amount of points per group
)
client.queryGroups("{collection_name}", {
query: [1.1],
group_by: "document_id",
limit: 4,
group_size: 2,
});
use qdrant_client::qdrant::QueryPointGroupsBuilder;
client
.query_groups(
QueryPointGroupsBuilder::new("{collection_name}", "document_id")
.query(vec![0.2, 0.1, 0.9, 0.7])
.group_size(2u64)
.with_payload(true)
.with_vectors(true)
.limit(4u64),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.grpc.Points.QueryPointGroups;
import io.qdrant.client.grpc.Points.SearchPointGroups;
import java.util.List;
client.queryGroupsAsync(
QueryPointGroups.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setGroupBy("document_id")
.setLimit(4)
.setGroupSize(2)
.build())
.get();
using Qdrant.Client;
var client = new QdrantClient("localhost", 6334);
await client.QueryGroupsAsync(
collectionName: "{collection_name}",
query: new float[] { 0.2f, 0.1f, 0.9f, 0.7f },
groupBy: "document_id",
limit: 4,
groupSize: 2
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.QueryGroups(context.Background(), &qdrant.QueryPointGroups{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
GroupBy: "document_id",
GroupSize: qdrant.PtrOf(uint64(2)),
})
The output of a groups call looks like this:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
The groups are ordered by the score of the top point in the group. Inside each group the points are sorted too.
If the group_by field of a point is an array (e.g. "document_id": ["a", "b"]), the point can be included in multiple groups (e.g. "document_id": "a" and document_id: "b").
Limitations:
- Only keyword and integer payload values are supported for the
group_byparameter. Payload values with other types will be ignored. - At the moment, pagination is not enabled when using groups, so the
offsetparameter is not allowed.
Lookup in groups
Having multiple points for parts of the same item often introduces redundancy in the stored data. Which may be fine if the information shared by the points is small, but it can become a problem if the payload is large, because it multiplies the storage space needed to store the points by a factor of the amount of points we have per group.
One way of optimizing storage when using groups is to store the information shared by the points with the same group id in a single point in another collection. Then, when using the groups API, add the with_lookup parameter to bring the information from those points into each group.
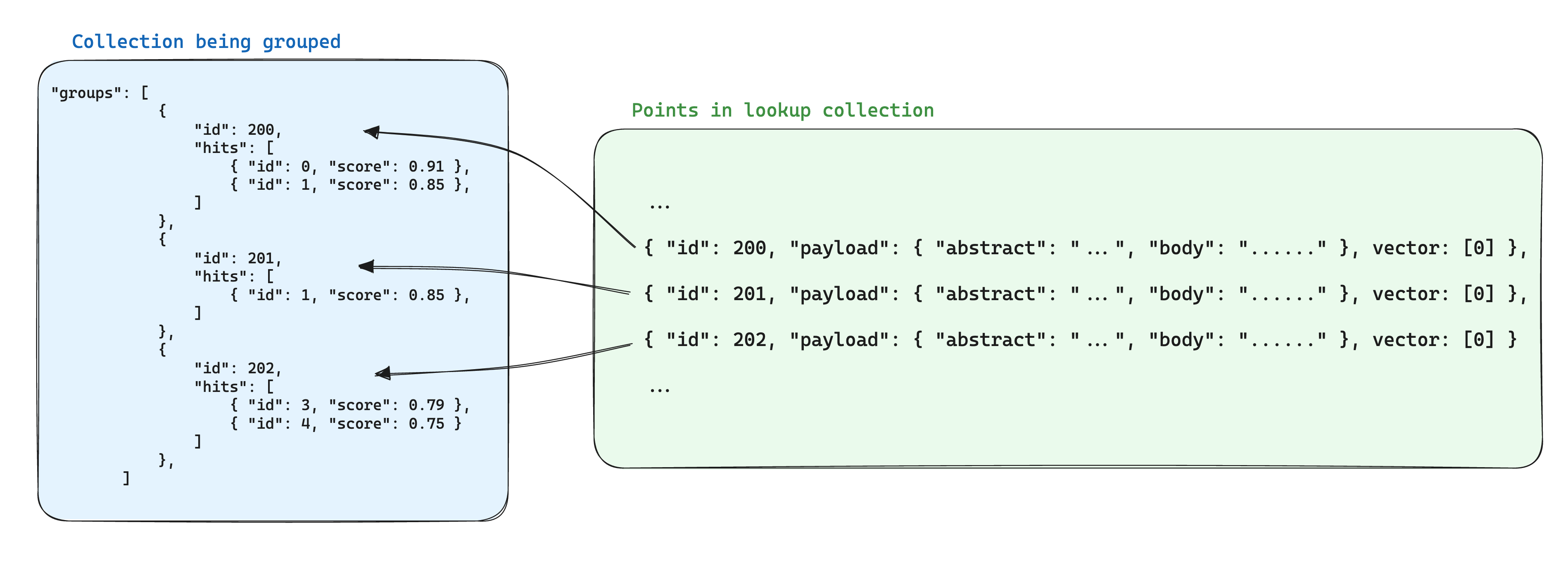
This has the extra benefit of having a single point to update when the information shared by the points in a group changes.
For example, if you have a collection of documents, you may want to chunk them and store the points for the chunks in a separate collection, making sure that you store the point id from the document it belongs in the payload of the chunk point.
In this case, to bring the information from the documents into the chunks grouped by the document id, you can use the with_lookup parameter:
POST /collections/chunks/points/query/groups
{
// Same as in the regular query API
"query": [1.1],
// Grouping parameters
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Lookup parameters
"with_lookup": {
// Name of the collection to look up points in
"collection": "documents",
// Options for specifying what to bring from the payload
// of the looked up point, true by default
"with_payload": ["title", "text"],
// Options for specifying what to bring from the vector(s)
// of the looked up point, true by default
"with_vectors": false
}
}
client.query_points_groups(
collection_name="chunks",
# Same as in the regular search() API
query=[1.1],
# Grouping parameters
group_by="document_id", # Path of the field to group by
limit=2, # Max amount of groups
group_size=2, # Max amount of points per group
# Lookup parameters
with_lookup=models.WithLookup(
# Name of the collection to look up points in
collection="documents",
# Options for specifying what to bring from the payload
# of the looked up point, True by default
with_payload=["title", "text"],
# Options for specifying what to bring from the vector(s)
# of the looked up point, True by default
with_vectors=False,
),
)
client.queryGroups("{collection_name}", {
query: [1.1],
group_by: "document_id",
limit: 2,
group_size: 2,
with_lookup: {
collection: "documents",
with_payload: ["title", "text"],
with_vectors: false,
},
});
use qdrant_client::qdrant::{with_payload_selector::SelectorOptions, QueryPointGroupsBuilder, WithLookupBuilder};
client
.query_groups(
QueryPointGroupsBuilder::new("{collection_name}", "document_id")
.query(vec![0.2, 0.1, 0.9, 0.7])
.limit(2u64)
.limit(2u64)
.with_lookup(
WithLookupBuilder::new("documents")
.with_payload(SelectorOptions::Include(
vec!["title".to_string(), "text".to_string()].into(),
))
.with_vectors(false),
),
)
.await?;
import static io.qdrant.client.QueryFactory.nearest;
import static io.qdrant.client.WithPayloadSelectorFactory.include;
import static io.qdrant.client.WithVectorsSelectorFactory.enable;
import io.qdrant.client.grpc.Points.QueryPointGroups;
import io.qdrant.client.grpc.Points.WithLookup;
import java.util.List;
client.queryGroupsAsync(
QueryPointGroups.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(nearest(0.2f, 0.1f, 0.9f, 0.7f))
.setGroupBy("document_id")
.setLimit(2)
.setGroupSize(2)
.setWithLookup(
WithLookup.newBuilder()
.setCollection("documents")
.setWithPayload(include(List.of("title", "text")))
.setWithVectors(enable(false))
.build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.SearchGroupsAsync(
collectionName: "{collection_name}",
vector: new float[] { 0.2f, 0.1f, 0.9f, 0.7f},
groupBy: "document_id",
limit: 2,
groupSize: 2,
withLookup: new WithLookup
{
Collection = "documents",
WithPayload = new WithPayloadSelector
{
Include = new PayloadIncludeSelector { Fields = { new string[] { "title", "text" } } }
},
WithVectors = false
}
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.QueryGroups(context.Background(), &qdrant.QueryPointGroups{
CollectionName: "{collection_name}",
Query: qdrant.NewQuery(0.2, 0.1, 0.9, 0.7),
GroupBy: "document_id",
GroupSize: qdrant.PtrOf(uint64(2)),
WithLookup: &qdrant.WithLookup{
Collection: "documents",
WithPayload: qdrant.NewWithPayloadInclude("title", "text"),
},
})
For the with_lookup parameter, you can also use the shorthand with_lookup="documents" to bring the whole payload and vector(s) without explicitly specifying it.
The looked up result will show up under lookup in each group.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Document A",
"text": "This is document A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Document B",
"text": "This is document B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
Since the lookup is done by matching directly with the point id, the lookup collection must be pre-populated with points where the id matches the group_by value (e.g., document_id) from your primary collection.
Any group id that is not an existing (and valid) point id in the lookup collection will be ignored, and the lookup field will be empty.
Random Sampling
Available as of v1.11.0
In some cases it might be useful to retrieve a random sample of points from the collection. This can be useful for debugging, testing, or for providing entry points for exploration.
Random sampling API is a part of Universal Query API and can be used in the same way as regular search API.
POST /collections/{collection_name}/points/query
{
"query": {
"sample": "random"
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
sampled = client.query_points(
collection_name="{collection_name}",
query=models.SampleQuery(sample=models.Sample.RANDOM)
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
const sampled = await client.query("{collection_name}", {
query: {
sample: "random",
},
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{Query, QueryPointsBuilder, Sample};
let client = Qdrant::from_url("http://localhost:6334").build()?;
let sampled = client
.query(
QueryPointsBuilder::new("{collection_name}")
.query(Query::new_sample(Sample::Random))
)
.await?;
import static io.qdrant.client.QueryFactory.sample;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.QueryPoints;
import io.qdrant.client.grpc.Points.Sample;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.setQuery(sample(Sample.Random))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(collectionName: "{collection_name}", query: Sample.Random);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.QueryGroups(context.Background(), &qdrant.QueryPointGroups{
CollectionName: "{collection_name}",
Query: qdrant.NewQuerySample(qdrant.Sample_Random),
})
Query planning
Depending on the filter used in the search - there are several possible scenarios for query execution. Qdrant chooses one of the query execution options depending on the available indexes, the complexity of the conditions and the cardinality of the filtering result. This process is called query planning.
The strategy selection process relies heavily on heuristics and can vary from release to release. However, the general principles are:
- planning is performed for each segment independently (see storage for more information about segments)
- prefer a full scan if the amount of points is below a threshold
- estimate the cardinality of a filtered result before selecting a strategy
- retrieve points using payload index (see indexing) if cardinality is below threshold
- use filterable vector index if the cardinality is above a threshold
- use ACORN when the selectivity (ratio) is low, but the cardinality (an amount) is still high
You can adjust the threshold using a configuration file, as well as independently for each collection.