































Empowering QA.tech’s Testing Agents with Real-Time Precision and Scale
Qdrant
·November 21, 2024
On this page:

QA.tech, a company specializing in AI-driven automated testing solutions, found that building and fully testing web applications, especially end-to-end, can be complex and time-consuming. Unlike unit tests, end-to-end tests reveal what’s actually happening in the browser, often uncovering issues that other methods miss.
Traditional solutions like hard-coded tests are not only labor-intensive to set up but also challenging to maintain over time. Alternatively, hiring QA testers can be a solution, but for startups, it quickly becomes a bottleneck. With every release, more testers are needed, and if testing is outsourced, managing timelines and ensuring quality becomes even harder.
To address this, QA.tech has developed testing agents that perform tasks on the browser just like a user would - for example, purchasing a ticket on a travel app. These agents navigate the entire booking process, from searching for flights to completing the purchase, all while assessing their success. They document errors, record the process, and flag issues for developers to review. With access to console logs and network calls, developers can easily analyze each step, quickly understanding and debugging any issues that arise.
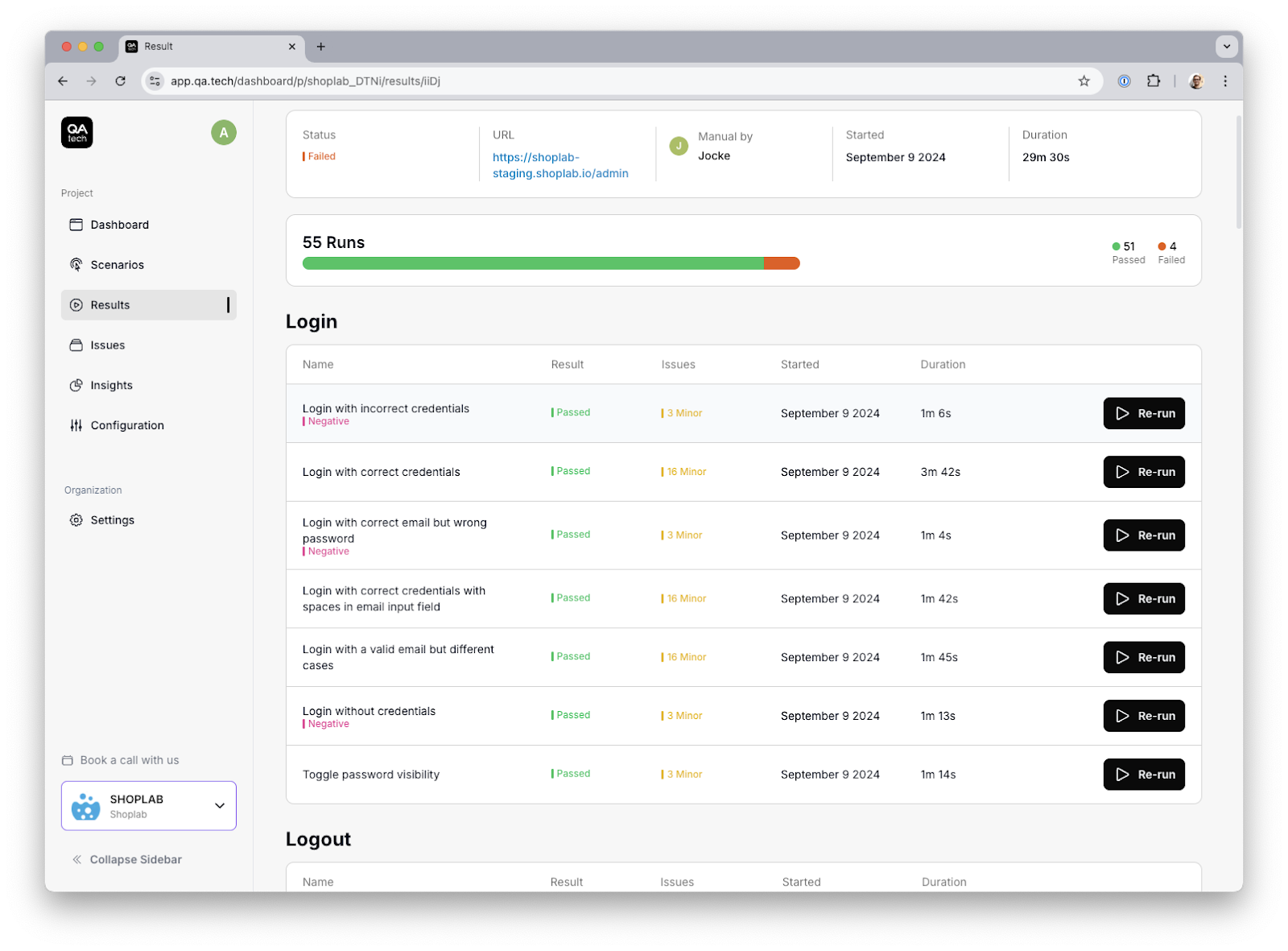
Output from a QA.tech AI agent
What prompted QA.tech to use a vector database?
QA.tech initially used pgvector for simpler vector use cases but encountered scalability limitations as their requirements grew, prompting them to adopt Qdrant. They needed a vector database capable of handling high-velocity, real-time analysis to support their AI agents, which operate within an analysis layer that observes and interprets actions across web pages. This analysis layer relies heavily on multimodal models and substantial subprocessing to enable the AI agent to make informed, real-time decisions.
In some web interfaces, hundreds of actions can occur, and processing them in real time - especially with each click - can be slow. Dynamic web elements and changing identifiers further complicate this, making traditional methods unreliable. To address these challenges, QA.tech trained custom embeddings on specific actions, which significantly accelerates decision-making.
This setup requires frequent embedding lookups, generating a high volume of database calls for each interaction. As Vilhelm von Ehrenheim from QA.tech explained:
“You get a lot of embeddings, a lot of calls, a lot of lookups towards the database for every click, and that needs to scale nicely.”
Qdrant’s fast, scalable vector search enables QA.tech to handle these high-velocity lookups seamlessly, ensuring that the agent remains responsive and capable of making quick, accurate decisions in real time.
Why QA.tech chose Qdrant for its AI Agent platform
QA.tech’s AI Agents handle high-velocity web actions, requiring efficient real-time operations and scalable infrastructure. The team faced challenges with managing network overhead, CPU load, and the need to store multiple embeddings for different use cases. Qdrant provided the solution to address these issues.
Reducing Network Overhead with Batch Operations
Handling hundreds of simultaneous actions on a web interface individually created significant network overhead. Von Ehrenheim explained that “doing all of those in separate calls creates a lot of network overhead.” Qdrant’s batch operations allowed QA.tech to process multiple actions at once, reducing network traffic and improving efficiency. This capability is essential for AI Agents, where real-time responsiveness is critical.
Optimizing CPU Load for Embedding Processing
PostgreSQL’s transaction guarantees resulted in high CPU usage when processing embeddings, especially at scale. Von Ehrenheim noted that adding many new embeddings “requires much more CPU,” which led to performance bottlenecks. Qdrant’s architecture efficiently handled large-scale embeddings, preventing CPU overload and ensuring smooth, uninterrupted performance, a key requirement for AI Agents.
Managing Multiple Embeddings for Different Use Cases
AI Agents need flexibility in handling both real-time actions and context-aware tasks. QA.tech required different embeddings for immediate action processing and deeper semantic searches. Von Ehrenheim mentioned, “We use one embedding for high-velocity actions, but I also want to store other types of embeddings for analytical purposes.”
Qdrant’s ability to store multiple embeddings per data point allowed QA.tech to meet these diverse needs without added complexity.
How QA.tech Overcame Key Challenges in AI Agent Development
Building reliable AI agents presents unique complexities, particularly as workflows grow more multi-step and dynamic.
“The more steps you ask an agent to take, the harder it becomes to ensure consistent performance,” Vilhelm von Ehrenheim, Co-Founder of QA.tech.
Each additional action adds layers of interdependent variables, creating pathways that can easily lead to errors if not managed carefully.
Von Ehrenheim also points out the limitations of current large language models (LLMs), noting that “LLMs are getting more powerful, but they still struggle with multi-step reasoning and for example handling subtle visual changes like dark mode or adaptive UIs.” These challenges make it essential for agents to have precise planning capabilities and context awareness, which QA.tech has addressed by implementing custom embeddings and multimodal models.
“This is where scalable, adaptable infrastructure becomes crucial,” von Ehrenheim adds. Qdrant has been instrumental for QA.tech, providing stable, high-performance vector search to support the demanding workflows. “With Qdrant, we’re able to handle these complex, high-velocity tasks without compromising on reliability.”
