
























Qdrant 1.10 - Universal Query, Built-in IDF & ColBERT Support
David Myriel
·July 01, 2024

On this page:
Qdrant 1.10.0 is out! This version introduces some major changes, so let’s dive right in:
Universal Query API: All search APIs, including Hybrid Search, are now in one Query endpoint.
Built-in IDF: We added the IDF mechanism to Qdrant’s core search and indexing processes.
Multivector Support: Native support for late interaction ColBERT is accessible via Query API.
One Endpoint for All Queries
Query API will consolidate all search APIs into a single request. Previously, you had to work outside of the API to combine different search requests. Now these approaches are reduced to parameters of a single request, so you can avoid merging individual results.
You can now configure the Query API request with the following parameters:
| Parameter | Description |
|---|---|
| no parameter | Returns points by id |
nearest | Queries nearest neighbors (Search) |
fusion | Fuses sparse/dense prefetch queries (Hybrid Search) |
discover | Queries target with added context (Discovery) |
context | No target with context only (Context) |
recommend | Queries against positive/negative examples. (Recommendation) |
order_by | Orders results by payload field |
For example, you can configure Query API to run Discovery search. Let’s see how that looks:
POST collections/{collection_name}/points/query
{
"query": {
"discover": {
"target": <vector_input>,
"context": [
{
"positive": <vector_input>,
"negative": <vector_input>
}
]
}
}
}
We will be publishing code samples in docs and our new API specification.
If you need additional support with this new method, our Discord on-call engineers can help you.
Native Hybrid Search Support
Query API now also natively supports sparse/dense fusion. Up to this point, you had to combine the results of sparse and dense searches on your own. This is now sorted on the back-end, and you only have to configure them as basic parameters for Query API.
POST /collections/{collection_name}/points/query
{
"prefetch": [
{
"query": {
"indices": [1, 42], // <┐
"values": [0.22, 0.8] // <┴─sparse vector
},
"using": "sparse",
"limit": 20
},
{
"query": [0.01, 0.45, 0.67, ...], // <-- dense vector
"using": "dense",
"limit": 20
}
],
"query": { "fusion": "rrf" }, // <--- reciprocal rank fusion
"limit": 10
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
prefetch=[
models.Prefetch(
query=models.SparseVector(indices=[1, 42], values=[0.22, 0.8]),
using="sparse",
limit=20,
),
models.Prefetch(
query=[0.01, 0.45, 0.67],
using="dense",
limit=20,
),
],
query=models.FusionQuery(fusion=models.Fusion.RRF),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
prefetch: [
{
query: {
values: [0.22, 0.8],
indices: [1, 42],
},
using: 'sparse',
limit: 20,
},
{
query: [0.01, 0.45, 0.67],
using: 'dense',
limit: 20,
},
],
query: {
fusion: 'rrf',
},
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{Fusion, PrefetchQueryBuilder, Query, QueryPointsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.query(
QueryPointsBuilder::new("{collection_name}")
.add_prefetch(PrefetchQueryBuilder::default()
.query(Query::new_nearest([(1, 0.22), (42, 0.8)].as_slice()))
.using("sparse")
.limit(20u64)
)
.add_prefetch(PrefetchQueryBuilder::default()
.query(Query::new_nearest(vec![0.01, 0.45, 0.67]))
.using("dense")
.limit(20u64)
)
.query(Query::new_fusion(Fusion::Rrf))
).await?;
import static io.qdrant.client.QueryFactory.nearest;
import java.util.List;
import static io.qdrant.client.QueryFactory.fusion;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.Fusion;
import io.qdrant.client.grpc.Points.PrefetchQuery;
import io.qdrant.client.grpc.Points.QueryPoints;
QdrantClient client = new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.addPrefetch(PrefetchQuery.newBuilder()
.setQuery(nearest(List.of(0.22f, 0.8f), List.of(1, 42)))
.setUsing("sparse")
.setLimit(20)
.build())
.addPrefetch(PrefetchQuery.newBuilder()
.setQuery(nearest(List.of(0.01f, 0.45f, 0.67f)))
.setUsing("dense")
.setLimit(20)
.build())
.setQuery(fusion(Fusion.RRF))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
prefetch: new List < PrefetchQuery > {
new() {
Query = new(float, uint)[] {
(0.22f, 1), (0.8f, 42),
},
Using = "sparse",
Limit = 20
},
new() {
Query = new float[] {
0.01f, 0.45f, 0.67f
},
Using = "dense",
Limit = 20
}
},
query: Fusion.Rrf
);
Query API can now pre-fetch vectors for requests, which means you can run queries sequentially within the same API call. There are a lot of options here, so you will need to define a strategy to merge these requests using new parameters. For example, you can now include rescoring within Hybrid Search, which can open the door to strategies like iterative refinement via matryoshka embeddings.
To learn more about this, read the Query API documentation.
Inverse Document Frequency [IDF]
IDF is a critical component of the TF-IDF (Term Frequency-Inverse Document Frequency) weighting scheme used to evaluate the importance of a word in a document relative to a collection of documents (corpus). There are various ways in which IDF might be calculated, but the most commonly used formula is:
Where:N is the total number of documents in the collection.n is the number of documents containing non-zero values for the given vector.
This variant is also used in BM25, whose support was heavily requested by our users. We decided to move the IDF calculation into the Qdrant engine itself. This type of separation allows streaming updates of the sparse embeddings while keeping the IDF calculation up-to-date.
The values of IDF previously had to be calculated using all the documents on the client side. However, now that Qdrant does it out of the box, you won’t need to implement it anywhere else and recompute the value if some documents are removed or newly added.
You can enable the IDF modifier in the collection configuration:
PUT /collections/{collection_name}
{
"sparse_vectors": {
"text": {
"modifier": "idf"
}
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
sparse_vectors={
"text": models.SparseVectorParams(
modifier=models.Modifier.IDF,
),
},
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
sparse_vectors: {
"text": {
modifier: "idf"
}
}
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{CreateCollectionBuilder, sparse_vectors_config::SparseVectorsConfigBuilder, Modifier, SparseVectorParamsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
let mut config = SparseVectorsConfigBuilder::default();
config.add_named_vector_params(
"text",
SparseVectorParamsBuilder::default().modifier(Modifier::Idf),
);
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.sparse_vectors_config(config),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Modifier;
import io.qdrant.client.grpc.Collections.SparseVectorConfig;
import io.qdrant.client.grpc.Collections.SparseVectorParams;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setSparseVectorsConfig(
SparseVectorConfig.newBuilder()
.putMap("text", SparseVectorParams.newBuilder().setModifier(Modifier.Idf).build()))
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
sparseVectorsConfig: ("text", new SparseVectorParams {
Modifier = Modifier.Idf,
})
);
IDF as Part of BM42
This quarter, Qdrant also introduced BM42, a novel algorithm that combines the IDF element of BM25 with transformer-based attention matrices to improve text retrieval. It utilizes attention matrices from your embedding model to determine the importance of each token in the document based on the attention value it receives.
We’ve prepared the standard all-MiniLM-L6-v2 Sentence Transformer so it outputs the attention values. Still, you can use virtually any model of your choice, as long as you have access to its parameters. This is just another reason to stick with open source technologies over proprietary systems.
In practical terms, the BM42 method addresses the tokenization issues and computational costs associated with SPLADE. The model is both efficient and effective across different document types and lengths, offering enhanced search performance by leveraging the strengths of both BM25 and modern transformer techniques.
To learn more about IDF and BM42, read our dedicated technical article.
You can expect BM42 to excel in scalable RAG-based scenarios where short texts are more common. Document inference speed is much higher with BM42, which is critical for large-scale applications such as search engines, recommendation systems, and real-time decision-making systems.
Multivector Support
We are adding native support for multivector search that is compatible, e.g., with the late-interaction ColBERT model. If you are working with high-dimensional similarity searches, ColBERT is highly recommended as a reranking step in the Universal Query search. You will experience better quality vector retrieval since ColBERT’s approach allows for deeper semantic understanding.
This model retains contextual information during query-document interaction, leading to better relevance scoring. In terms of efficiency and scalability benefits, documents and queries will be encoded separately, which gives an opportunity for pre-computation and storage of document embeddings for faster retrieval.
Note: This feature supports all the original quantization compression methods, just the same as the regular search method.
Run a query with ColBERT vectors:
Query API can handle exceedingly complex requests. The following example prefetches 1000 entries most similar to the given query using the mrl_byte named vector, then reranks them to get the best 100 matches with full named vector and eventually reranks them again to extract the top 10 results with the named vector called colbert. A single API call can now implement complex reranking schemes.
POST /collections/{collection_name}/points/query
{
"prefetch": {
"prefetch": {
"query": [1, 23, 45, 67], // <------ small byte vector
"using": "mrl_byte",
"limit": 1000
},
"query": [0.01, 0.45, 0.67, ...], // <-- full dense vector
"using": "full",
"limit": 100
},
"query": [ // <─┐
[0.1, 0.2, ...], // < │
[0.2, 0.1, ...], // < ├─ multi-vector
[0.8, 0.9, ...] // < │
], // <─┘
"using": "colbert",
"limit": 10
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
prefetch=models.Prefetch(
prefetch=models.Prefetch(query=[1, 23, 45, 67], using="mrl_byte", limit=1000),
query=[0.01, 0.45, 0.67],
using="full",
limit=100,
),
query=[
[0.1, 0.2],
[0.2, 0.1],
[0.8, 0.9],
],
using="colbert",
limit=10,
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.query("{collection_name}", {
prefetch: {
prefetch: {
query: [1, 23, 45, 67],
using: 'mrl_byte',
limit: 1000
},
query: [0.01, 0.45, 0.67],
using: 'full',
limit: 100,
},
query: [
[0.1, 0.2],
[0.2, 0.1],
[0.8, 0.9],
],
using: 'colbert',
limit: 10,
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{PrefetchQueryBuilder, Query, QueryPointsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client.query(
QueryPointsBuilder::new("{collection_name}")
.add_prefetch(PrefetchQueryBuilder::default()
.add_prefetch(PrefetchQueryBuilder::default()
.query(Query::new_nearest(vec![1.0, 23.0, 45.0, 67.0]))
.using("mrl_byte")
.limit(1000u64)
)
.query(Query::new_nearest(vec![0.01, 0.45, 0.67]))
.using("full")
.limit(100u64)
)
.query(Query::new_nearest(vec![
vec![0.1, 0.2],
vec![0.2, 0.1],
vec![0.8, 0.9],
]))
.using("colbert")
.limit(10u64)
).await?;
import static io.qdrant.client.QueryFactory.nearest;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Points.PrefetchQuery;
import io.qdrant.client.grpc.Points.QueryPoints;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.queryAsync(
QueryPoints.newBuilder()
.setCollectionName("{collection_name}")
.addPrefetch(
PrefetchQuery.newBuilder()
.addPrefetch(
PrefetchQuery.newBuilder()
.setQuery(nearest(1, 23, 45, 67)) // <------------- small byte vector
.setUsing("mrl_byte")
.setLimit(1000)
.build())
.setQuery(nearest(0.01f, 0.45f, 0.67f)) // <-- dense vector
.setUsing("full")
.setLimit(100)
.build())
.setQuery(
nearest(
new float[][] {
{0.1f, 0.2f}, // <─┐
{0.2f, 0.1f}, // < ├─ multi-vector
{0.8f, 0.9f} // < ┘
}))
.setUsing("colbert")
.setLimit(10)
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.QueryAsync(
collectionName: "{collection_name}",
prefetch: new List <PrefetchQuery> {
new() {
Prefetch = {
new List <PrefetchQuery> {
new() {
Query = new float[] { 1, 23, 45, 67 }, // <------------- small byte vector
Using = "mrl_byte",
Limit = 1000
},
}
},
Query = new float[] {0.01f, 0.45f, 0.67f}, // <-- dense vector
Using = "full",
Limit = 100
}
},
query: new float[][] {
[0.1f, 0.2f], // <─┐
[0.2f, 0.1f], // < ├─ multi-vector
[0.8f, 0.9f] // < ┘
},
usingVector: "colbert",
limit: 10
);
Note: The multivector feature is not only useful for ColBERT; it can also be used in other ways.
For instance, in e-commerce, you can use multi-vector to store multiple images of the same item. This serves as an alternative to the group-by method.
Sparse Vectors Compression
In version 1.9, we introduced the uint8 vector datatype for sparse vectors, in order to support pre-quantized embeddings from companies like JinaAI and Cohere.
This time, we are introducing a new datatype for both sparse and dense vectors, as well as a different way of storing these vectors.
Datatype: Sparse and dense vectors were previously represented in larger float32 values, but now they can be turned to the float16. float16 vectors have a lower precision compared to float32, which means that there is less numerical accuracy in the vector values - but this is negligible for practical use cases.
These vectors will use half the memory of regular vectors, which can significantly reduce the footprint of large vector datasets. Operations can be faster due to reduced memory bandwidth requirements and better cache utilization. This can lead to faster vector search operations, especially in memory-bound scenarios.
When creating a collection, you need to specify the datatype upfront:
PUT /collections/{collection_name}
{
"vectors": {
"size": 1024,
"distance": "Cosine",
"datatype": "float16"
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
"{collection_name}",
vectors_config=models.VectorParams(
size=1024, distance=models.Distance.COSINE, datatype=models.Datatype.FLOAT16
),
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
vectors: {
size: 1024,
distance: "Cosine",
datatype: "float16"
}
});
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.Datatype;
import io.qdrant.client.grpc.Collections.Distance;
import io.qdrant.client.grpc.Collections.VectorParams;
import io.qdrant.client.grpc.Collections.VectorsConfig;
QdrantClient client = new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setVectorsConfig(VectorsConfig.newBuilder()
.setParams(VectorParams.newBuilder()
.setSize(1024)
.setDistance(Distance.Cosine)
.setDatatype(Datatype.Float16)
.build())
.build())
.build())
.get();
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{CreateCollectionBuilder, Datatype, Distance, VectorParamsBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}").vectors_config(
VectorParamsBuilder::new(1024, Distance::Cosine).datatype(Datatype::Float16),
),
)
.await?;
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
vectorsConfig: new VectorParams {
Size = 1024,
Distance = Distance.Cosine,
Datatype = Datatype.Float16
}
);
Storage: On the backend, we implemented bit packing to minimize the bits needed to store data, crucial for handling sparse vectors in applications like machine learning and data compression. For sparse vectors with mostly zeros, this focuses on storing only the indices and values of non-zero elements.
You will benefit from a more compact storage and higher processing efficiency. This can also lead to reduced dataset sizes for faster processing and lower storage costs in data compression.
New Rust Client
Qdrant’s Rust client has been fully reshaped. It is now more accessible and easier to use. We have focused on putting together a minimalistic API interface. All operations and their types now use the builder pattern, providing an easy and extensible interface, preventing breakage with future updates. See the Rust ColBERT query as great example. Additionally, Rust supports safe concurrent execution, which is crucial for handling multiple simultaneous requests efficiently.
Documentation got a significant improvement as well. It is much better organized and provides usage examples across the board. Everything links back to our main documentation, making it easier to navigate and find the information you need.
Visit our client and operations documentation
S3 Snapshot Storage
Qdrant Collections, Shards and Storage can be backed up with Snapshots and saved in case of data loss or other data transfer purposes. These snapshots can be quite large and the resources required to maintain them can result in higher costs. AWS S3 and other S3-compatible implementations like min.io is a great low-cost alternative that can hold snapshots without incurring high costs. It is globally reliable, scalable and resistant to data loss.
You can configure S3 storage settings in the config.yaml, specifically with snapshots_storage.
For example, to use AWS S3:
storage:
snapshots_config:
# Use 's3' to store snapshots on S3
snapshots_storage: s3
s3_config:
# Bucket name
bucket: your_bucket_here
# Bucket region (e.g. eu-central-1)
region: your_bucket_region_here
# Storage access key
# Can be specified either here or in the `AWS_ACCESS_KEY_ID` environment variable.
access_key: your_access_key_here
# Storage secret key
# Can be specified either here or in the `AWS_SECRET_ACCESS_KEY` environment variable.
secret_key: your_secret_key_here
Read more about S3 snapshot storage and configuration.
This integration allows for a more convenient distribution of snapshots. Users of any S3-compatible object storage can now benefit from other platform services, such as automated workflows and disaster recovery options. S3’s encryption and access control ensure secure storage and regulatory compliance. Additionally, S3 supports performance optimization through various storage classes and efficient data transfer methods, enabling quick and effective snapshot retrieval and management.
Issues API
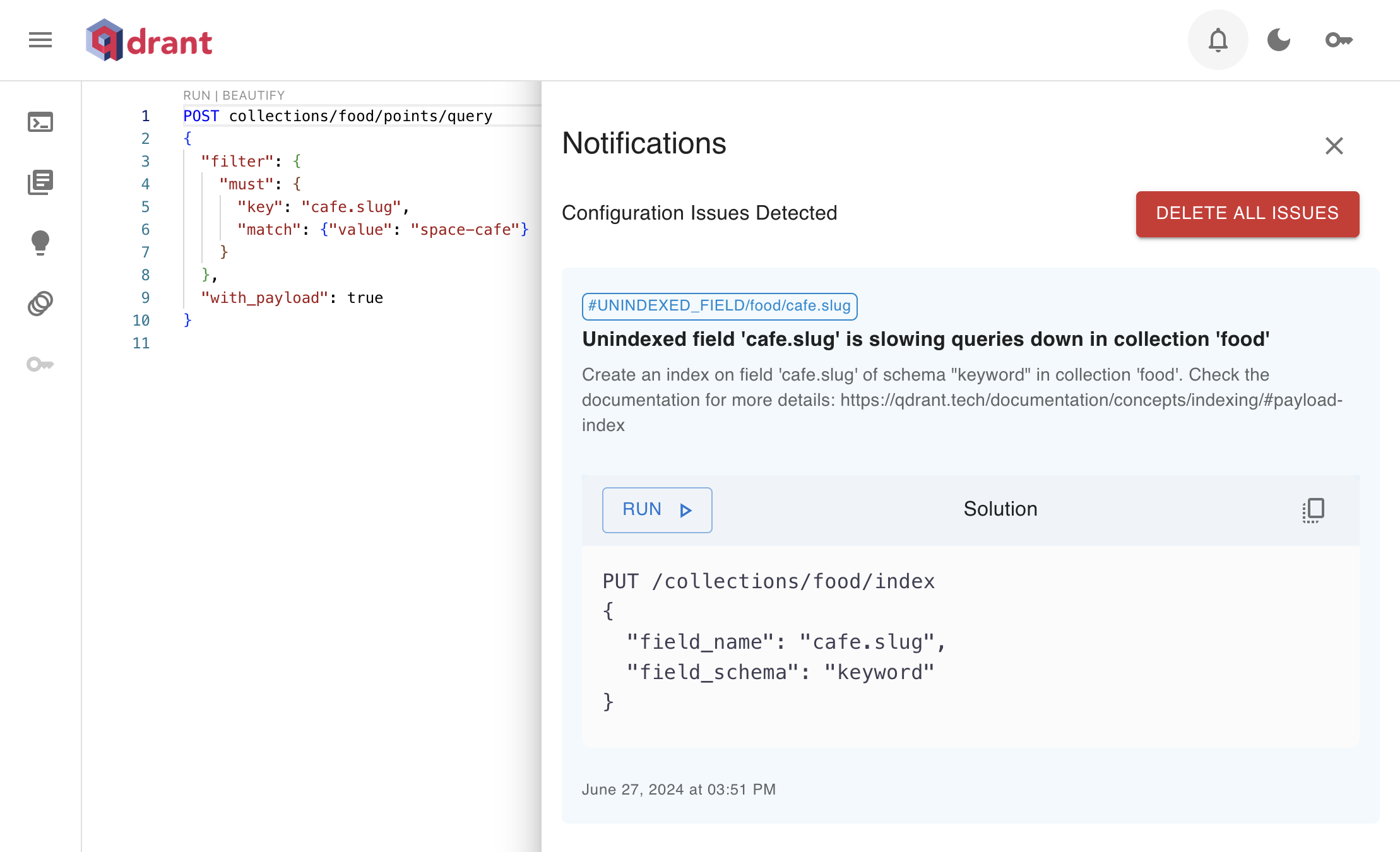
Issues API notifies you about potential performance issues and misconfigurations. This powerful new feature allows users (such as database admins) to efficiently manage and track issues directly within the system, ensuring smoother operations and quicker resolutions.
You can find the Issues button in the top right. When you click the bell icon, a sidebar will open to show ongoing issues.
Minor Improvements
Pre-configure collection parameters; quantization, vector storage & replication factor - #4299
Overwrite global optimizer configuration for collections. Lets you separate roles for indexing and searching within the single qdrant cluster - #4317
Delta encoding and bitpacking compression for sparse vectors reduces memory consumption for sparse vectors by up to 75% - #4253, #4350
