































Introducing Qdrant Cloud Inference
Daniel Azoulai
·July 15, 2025
On this page:
Introducing Qdrant Cloud Inference
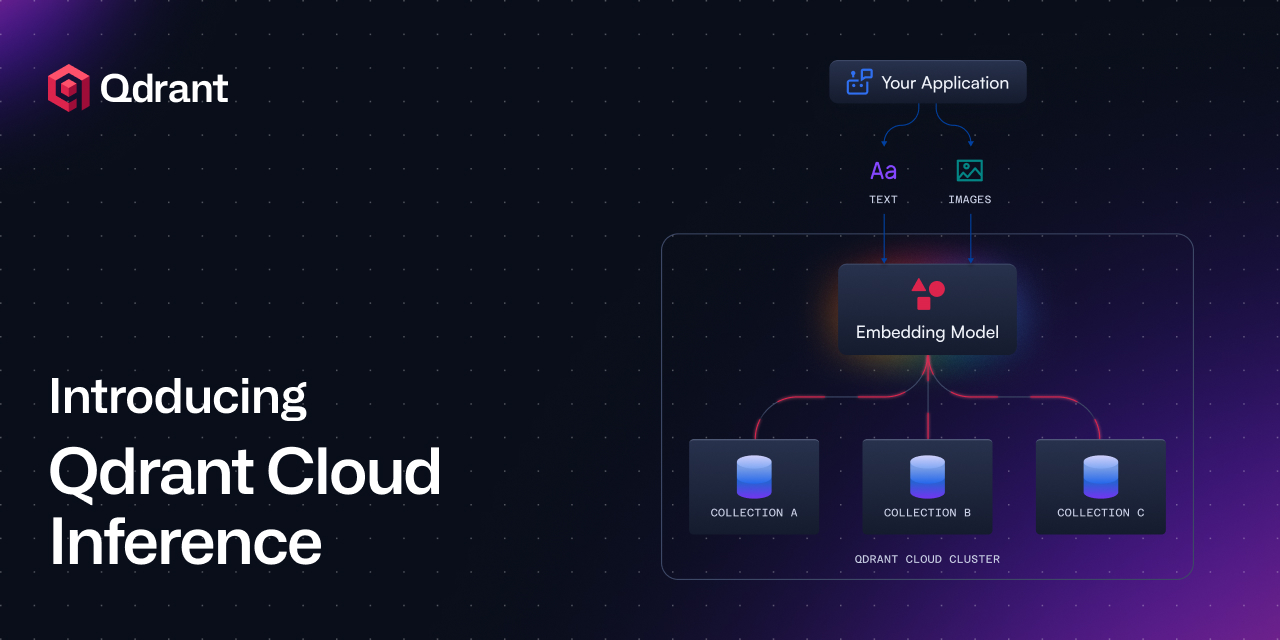
Today, we’re announcing the launch of Qdrant Cloud Inference (get started in your cluster). With Qdrant Cloud Inference, users can generate, store and index embeddings in a single API call, turning unstructured text and images into search-ready vectors in a single environment. Directly integrating model inference into Qdrant Cloud removes the need for separate inference infrastructure, manual pipelines, and redundant data transfers.
This simplifies workflows, accelerates development cycles, and eliminates unnecessary network hops for developers. With a single API call, you can now embed, store, and index your data more quickly and more simply. This speeds up application development for RAG, Multimodal, Hybrid search, and more.
Unify embedding and search
Traditionally, building application data pipelines means juggling separate embedding services and a vector database, introducing unnecessary complexity, latency, and network costs. Qdrant Cloud Inference brings everything into one system. Embeddings are generated inside the network of your cluster, which removes external API overhead, resulting in lower latency and faster response times. Additionally, you can now track vector database and inference costs in one place.
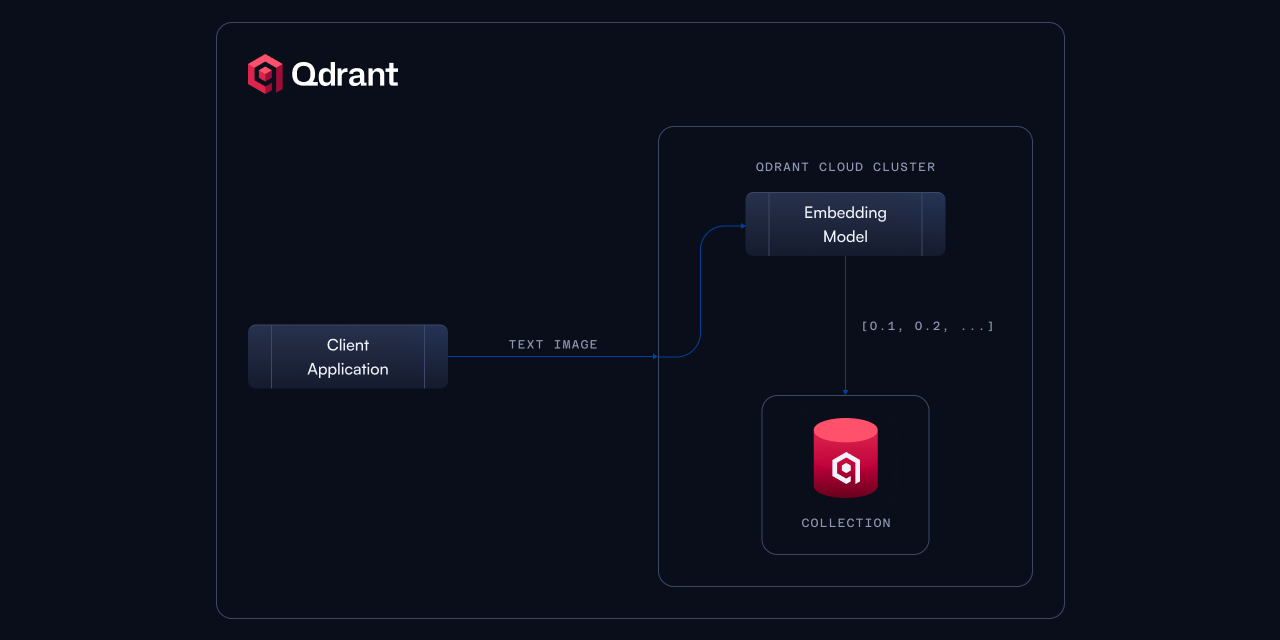
Supported Models for Multimodal and Hybrid Search Applications
At launch, Qdrant Cloud Inference includes six curated models to start with. Choose from dense models like all-MiniLM-L6-v2 for fast semantic matching, mxbai/embed-large-v1 for richer understanding, or sparse models like splade-pp-en-v1 and bm25 (Check out this hybrid search tutorial to see it in action). For multimodal workloads, Qdrant uniquely supports OpenAI CLIP-style models for both text and images.
Want to request a different model to integrate? You can do this at https://support.qdrant.io/.
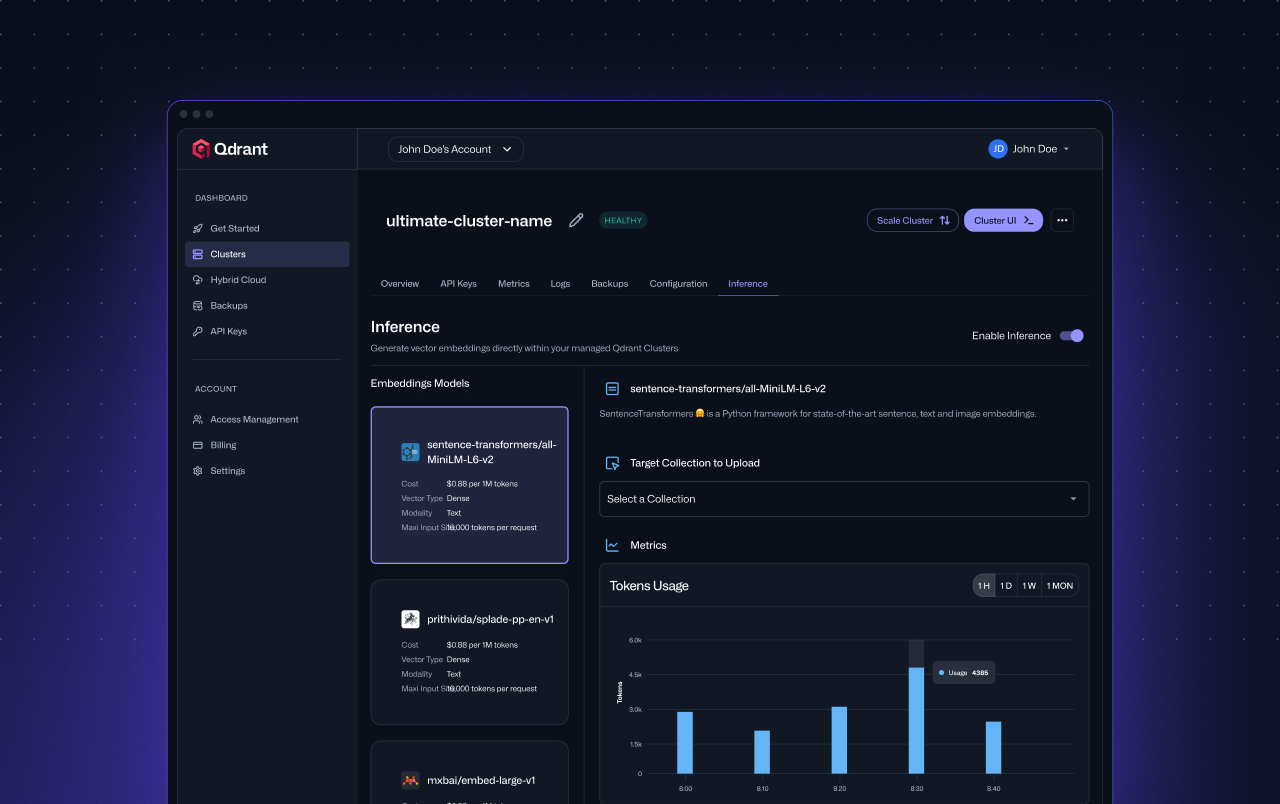
Get up to 5M free tokens per model per month, and unlimited BM25 tokens
To make onboarding even easier, we’re offering 5 million free tokens per text model, 1 million for our image model, and unlimited for bm25 to all paid Qdrant Cloud users. These token allowances renew monthly so long as you have a paid Qdrant Cloud cluster. These free monthly tokens are perfect for development, staging, or even running initial production workloads without added cost.
Inference is automatically enabled for paid accounts
Getting started is easy. Inference is automatically enabled for any new paid clusters with version 1.14.0 or higher. It can be activated for existing clusters with a click on the inference tab on the Cluster Detail page in the Qdrant Cloud console. You will see examples of how to use inference with our different Qdrant SDKs.
Start Embedding Today
You can get started now by logging into Qdrant Cloud, selecting a model, and embedding your data directly. No extra APIs. No new tools. Just faster, simpler AI application development.
How to Build a Multimodal Search Stack with One API
Embed, Store, Search: A Hands-On Guide to Qdrant Cloud Inference
Kacper Łukawski, Senior Developer Advocate, hosted a live session showing how to:
- Generate embeddings for text or images using pre-integrated models
- Store and search embeddings in the same Qdrant Cloud environment
- Power multimodal (an industry first) and hybrid search with just one API
- Reduce network egress fees and simplify your AI stack
Watch now:
