































How to Build Intelligent Agentic RAG with CrewAI and Qdrant
Kacper Łukawski
·January 24, 2025

On this page:
In a recent live session, we teamed up with CrewAI, a framework for building intelligent, multi-agent applications. If you missed it, Kacper Łukawski from Qdrant and Tony Kipkemboi from CrewAI gave an insightful overview of CrewAI’s capabilities and demonstrated how to leverage Qdrant for creating an agentic RAG (Retrieval-Augmented Generation) system. The focus was on semi-automating email communication, using Obsidian as the knowledge base.
In this article, we’ll guide you through the process of setting up an AI-powered system that connects directly to your email inbox and knowledge base, enabling it to analyze incoming messages and existing content to generate contextually relevant response suggestions.
Background agents
Although we got used to LLM-based apps that usually have a chat-like interface, even if it’s not a real UI but a CLI tool, plenty of day-to-day tasks can be automated in the background without explicit human action firing the process. This concept is also known as ambient agents, where the agent is always there, waiting for a trigger to act.
The basic concepts of CrewAI
Thanks for Tony’s participation, we could learn more about CrewAI, and understand the basic concepts of the framework. He introduced the concepts of agents and crews, and how they can be used to build intelligent multi-agent applications. Moreover, Tony described different types of memory that CrewAI applications can use.
When it comes to Qdrant role in CrewAI applications, it can be used as short-term, or entity memory, as both components are based on RAG and vector embeddings. If you’d like to know more about memory in CrewAI, please visit the CrewAI concepts.
Tony made an interesting analogy. He compared crews to different departments in a company, where each department has its own responsibilities, but they all work together to achieve the company’s goals.
Email automation with CrewAI, Qdrant, and Obsidian notes
Our webinar focused on building an agentic RAG system that would semi-automate email communication. RAG is an essential component of such a system, as you don’t want to take responsibility for responses that cannot be grounded. The system would monitor your Gmail inbox, analyze the incoming emails, and prepare response drafts if it detects that the email is not spam, newsletter, or notification.
On the other hand, the system would also monitor the Obsidian notes, by watching any changes in the local file system. When a file is created, modified, or deleted, the system would automatically move these changes to the Qdrant collection, so the knowledge base is always up-to-date. Obsidian uses Markdown files to store notes, so complex parsing is not required.
Here is a simplified diagram presenting the target architecture of the system:
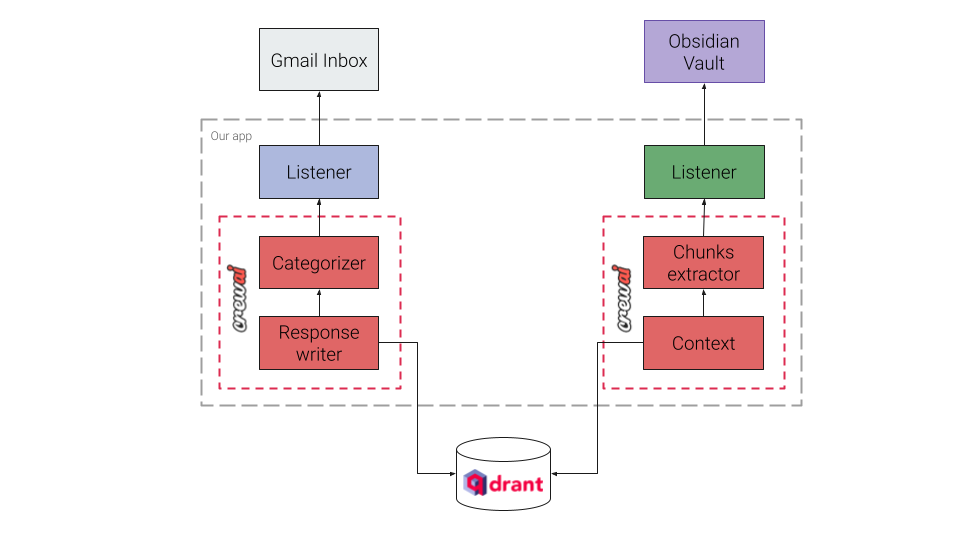
Qdrant acts as a knowledge base, storing the embeddings of the Obsidian notes.
Implementing the system
Since our system integrates with two external APIs - Gmail and filesystem. We won’t go into details of how to work with these APIs, as it’s out of the scope of this webinar. Instead, we will focus on the CrewAI and Qdrant integration, and CrewAI agents’ implementation.
CrewAI <> Qdrant integration
Since there is no official integration between CrewAI and Qdrant yet, we created a custom implementation of the
RAGStorage class, which has a pretty straightforward interface.
from typing import Optional
from crewai.memory.storage.rag_storage import RAGStorage
class QdrantStorage(RAGStorage):
"""
Extends Storage to handle embeddings for memory entries
using Qdrant.
"""
...
def search(self,
query: str,
limit: int = 3,
filter: Optional[dict] = None,
score_threshold: float = 0,
) -> list[dict]:
...
def reset(self) -> None:
...
Full implementation might be found in the GitHub repository. You can use it for your own projects, or as a reference for your custom implementation. If you want to set up a crew that uses Qdrant as both entity and short memory layers, you can do it like this:
from crewai import Crew, Process
from crewai.memory import EntityMemory, ShortTermMemory
from email_assistant.storage import QdrantStorage
qdrant_location= "http://localhost:6333"
qdrant_api_key = "your-secret-api-key"
embedder_config = {...}
crew = Crew(
agents=[...],
tasks=[...], # Automatically created by the @task decorator
process=Process.sequential,
memory=True,
entity_memory=EntityMemory(
storage=QdrantStorage(
type="entity-memory",
embedder_config=embedder_config,
qdrant_location=qdrant_location,
qdrant_api_key=qdrant_api_key,
),
),
short_term_memory=ShortTermMemory(
storage=QdrantStorage(
type="short-term-memory",
embedder_config=embedder_config,
qdrant_location=qdrant_location,
qdrant_api_key=qdrant_api_key,
),
),
embedder=embedder_config,
verbose=True,
)
Both types of memory will use different collection names in Qdrant, so you can easily distinguish between them, and the data won’t be mixed up.
We are planning to release a CrewAI tool for Qdrant integration in the near future, so stay tuned!
Loading the Obsidian notes to Qdrant
For the sake of the demo, we decided to simply scrape the documentation of both CrewAI and Qdrant, and store it in the Obsidian notes. That’s easy with Obsidian Web Clipper, as it allows you to save the web page as a Markdown file.
Assuming we detected a change in the Obsidian notes, such as new note creation or modification, we would like to load the changes to Qdrant. We could possibly use some chunking methods, starting from basic fixed-size chunks, or go straight to semantic chunking. However, LLMs are also well-known for their ability to divide the text into meaningful parts, so we decided to try them out. Moreover, standard chunking is enough in many cases, but we also wanted to test the Contextual Retrieval concept introduced by Anthropic. In a nutshell, the idea is to use LLMs to generate a short context for each chunk, so it situates the chunk in the context of the whole document.
It turns out, implementing such a crew in CrewAI is quite straightforward. There are two actors in the crew - one chunking the text and the other one generating the context. Both might be defined in YAML files like this:
chunks_extractor:
role: >
Semantic chunks extractor
goal: >
Parse Markdown to extract digestible pieces of information which are
semantically meaningful and can be easily understood by a human.
backstory: >
You are a search expert building a search engine for Markdown files.
Once you receive a Markdown file, you divide it into meaningful semantic
chunks, so each chunk is about a certain topic or concept. You're known
for your ability to extract relevant information from large documents and
present it in a structured and easy-to-understand format, that increases
the searchability of the content and results quality.
contextualizer:
role: >
Bringing context to the extracted chunks
goal: >
Add context to the extracted chunks to make them more meaningful and
understandable. This context should help the reader understand the
significance of the information and how it relates to the broader topic.
backstory: >
You are a knowledge curator who specializes in making information more
accessible and understandable. You take the extracted chunks and provide
additional context to make them more meaningful by bringing in relevant
information about the whole document or the topic at hand.
CrewAI makes it very easy to define such agents, and even a non-tech person can understand and modify the YAML files.
Another YAML file defines the tasks that the agents should perform:
extract_chunks:
description: >
Review the document you got and extract the chunks from it. Each
chunk should be a separate piece of information that can be easily understood
by a human and is semantically meaningful. If there are two or more chunks that
are closely related, but not put next to each other, you can merge them into
a single chunk. It is important to cover all the important information in the
document and make sure that the chunks are logically structured and coherent.
<document>{document}</document>
expected_output: >
A list of semantic chunks with succinct context of information extracted from
the document.
agent: chunks_extractor
contextualize_chunks:
description: >
You have the chunks we want to situate within the whole document.
Please give a short succinct context to situate this chunk within the overall
document for the purposes of improving search retrieval of the chunk. Answer
only with the succinct context and nothing else.
expected_output: >
A short succinct context to situate the chunk within the overall document, along
with the chunk itself.
agent: contextualizer
YAML is not enough to make the agents work, so we need to implement them in Python. The role, goal, and backstory of the agent, as well as the task description and expected output, are used to build a prompt sent to the LLM. However, the code defines which LLM to use, and some other parameters of the interaction, like structured output. We heavily rely on Pydantic models to define the output of the task, so the responses might be easily processed by the application, for example, to store them in Qdrant.
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
from email_assistant import models
...
@CrewBase
class KnowledgeOrganizingCrew(BaseCrew):
"""
A crew responsible for processing raw text data and converting it into structured knowledge.
"""
agents_config = "config/knowledge/agents.yaml"
tasks_config = "config/knowledge/tasks.yaml"
@agent
def chunks_extractor(self) -> Agent:
return Agent(
config=self.agents_config["chunks_extractor"],
verbose=True,
llm="anthropic/claude-3-5-sonnet-20241022",
)
...
@task
def contextualize_chunks(self) -> Task:
# The task description is borrowed from the Anthropic Contextual Retrieval
# See: https://www.anthropic.com/news/contextual-retrieval/
return Task(
config=self.tasks_config["contextualize_chunks"],
output_pydantic=models.ContextualizedChunks,
)
...
@crew
def crew(self) -> Crew:
"""Creates the KnowledgeOrganizingCrew crew"""
return Crew(
agents=self.agents, # Automatically created by the @agent decorator
tasks=self.tasks, # Automatically created by the @task decorator
process=Process.sequential,
memory=True,
entity_memory=self.entity_memory(),
short_term_memory=self.short_term_memory(),
embedder=self.embedder_config,
verbose=True,
)
Full implementation might again be found in the GitHub repository.
Drafting emails in Gmail Inbox
At this point we already have our notes stored in Qdrant, and we can write emails in Gmail Inbox using the notes as a ground truth. The system would monitor the Gmail inbox, and if it detects an email that is not spam, newsletter, or notification, it would draft a response based on the knowledge base stored in Qdrant. Again, that means we need to use two agents - one for detecting the kind of the incoming email, and the other one for drafting the response.
The YAML files for these agents might look like this:
categorizer:
role: >
Email threads categorizer
goal: >
Automatically categorize email threads based on their content.
backstory: >
You're a virtual assistant with a knack for organizing information.
You're known for your ability to quickly and accurately categorize email
threads, so that your clients know which ones are important to answer
and which ones are spam, newsletters, or other types of messages that
do not require attention.
Available categories: QUESTION, NOTIFICATION, NEWSLETTER, SPAM. Do not make
up new categories.
response_writer:
role: >
Email response writer
goal: >
Write clear and concise responses to an email thread. Try to help the
sender. Use the external knowledge base to provide relevant information.
backstory: >
You are a professional writer with a talent for crafting concise and
informative responses. You're known for your ability to quickly understand
the context of an email thread and provide a helpful and relevant response
that addresses the sender's needs. You always rely on your knowledge base
to provide accurate and up-to-date information.
The set of categories is predefined, so the categorizer should not invent new categories. The task definitions are as follows:
categorization_task:
description: >
Review the content of the following email thread and categorize it
into the appropriate category. There might be multiple categories that
apply to the email thread.
<messages>{messages}</messages>
expected_output: >
A list of all the categories that the email threads can be classified into.
agent: categorizer
response_writing_task:
description: >
Write a response to the following email thread. The response should be
clear, concise, and helpful to the sender. Always rely on the Qdrant search
tool, so you can get the most relevant information to craft your response.
Please try to include the source URLs of the information you provide.
Only focus on the real question asked by the sender and do not try to
address any other issues that are not directly related to the sender's needs.
Do not try to provide a response if the context is not clear enough.
<messages>{messages}</messages>
expected_output: >
A well-crafted response to the email thread that addresses the sender's needs.
Please use simple HTML formatting to make the response more readable.
Do not include greetings or signatures in your response, but provide the footnotes
with the source URLs of the information you used, if possible.
If the provided context does not give you enough information to write a response,
you must admit that you cannot provide a response and write "I cannot provide a response.".
agent: response_writer
We specifically asked the agents to include the source URLs of the information they provide, so both the sender and the recipient can verify the information.
Working system
We have both crews defined, and the application is ready to run. The only thing left is to monitor the Gmail inbox and
the Obsidian notes for changes. We use the watchdog library to monitor the filesystem, and the google-api-python-client
to monitor the Gmail inbox, but we won’t go into details of how to use these libraries, as the integration code would
make this blog post too long.
If you open the main file of the application, you will see that it is quite simple. It runs two separate threads, one for monitoring the Gmail inbox, and the other one for monitoring the Obsidian notes. If there is any event detected, the application will run the appropriate crew to process the data, and the resulting response will be sent back to the email thread, or Qdrant collection, respectively. No UI is required, as your ambient agents are working in the background.
Results
The system is now ready to run, and it can semi-automate email communication, and keep the knowledge base up-to-date. If you set it up properly, you can expect the system to draft responses to emails that are not spam, newsletter, or notification, so your email inbox may look like this, even when you sleep:
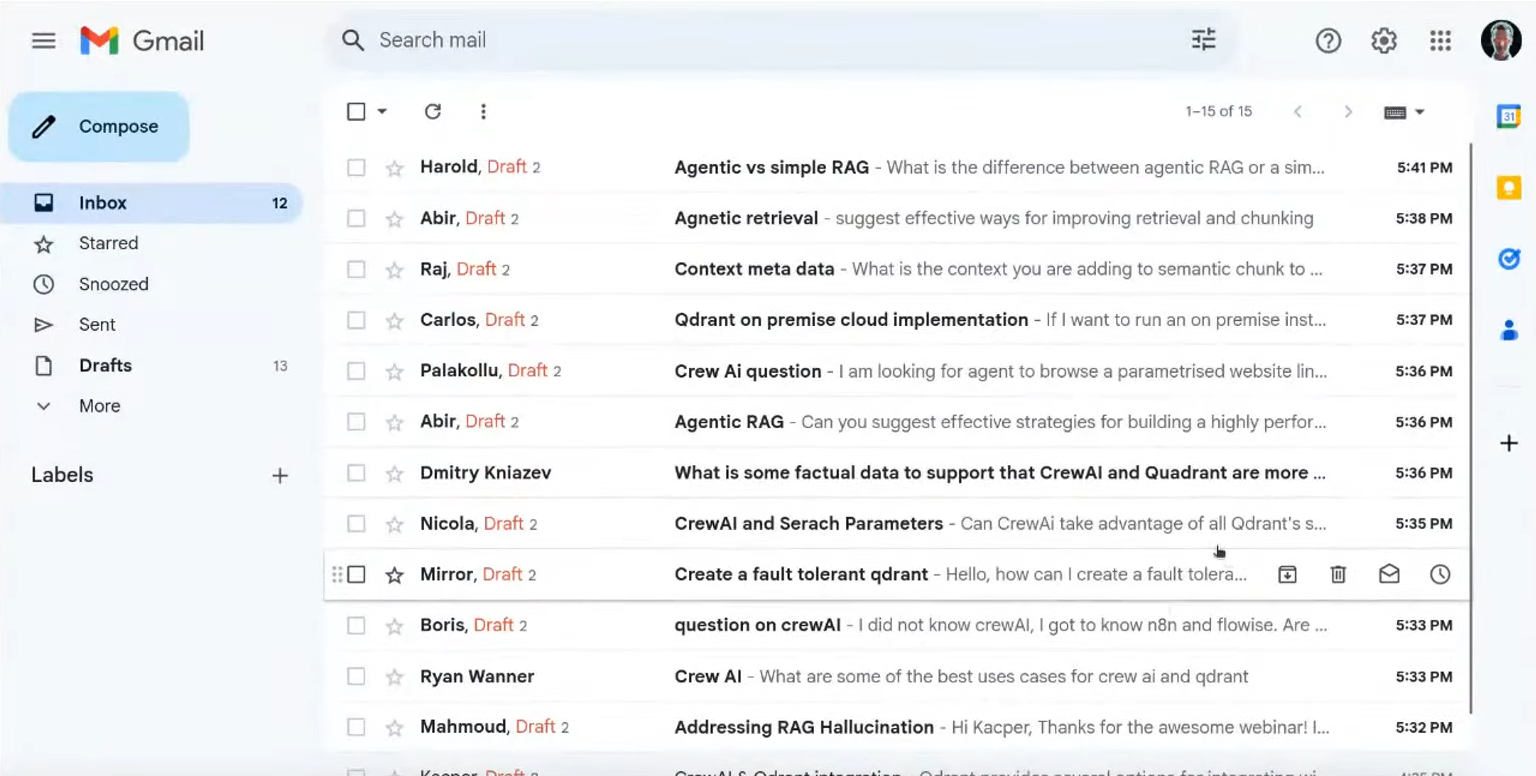
Materials
As usual, we prepared a video recording of the webinar, so you can watch it at your convenience:
The source code of the demo is available on GitHub, so if you would like to try it out yourself, feel free to clone or fork the repository and follow the instructions in the README file.
Are you building agentic RAG applications using CrewAI and Qdrant? Please join our Discord community and share your experience!
