- Products
- Solutions
- Developers
- Resources
- Company
































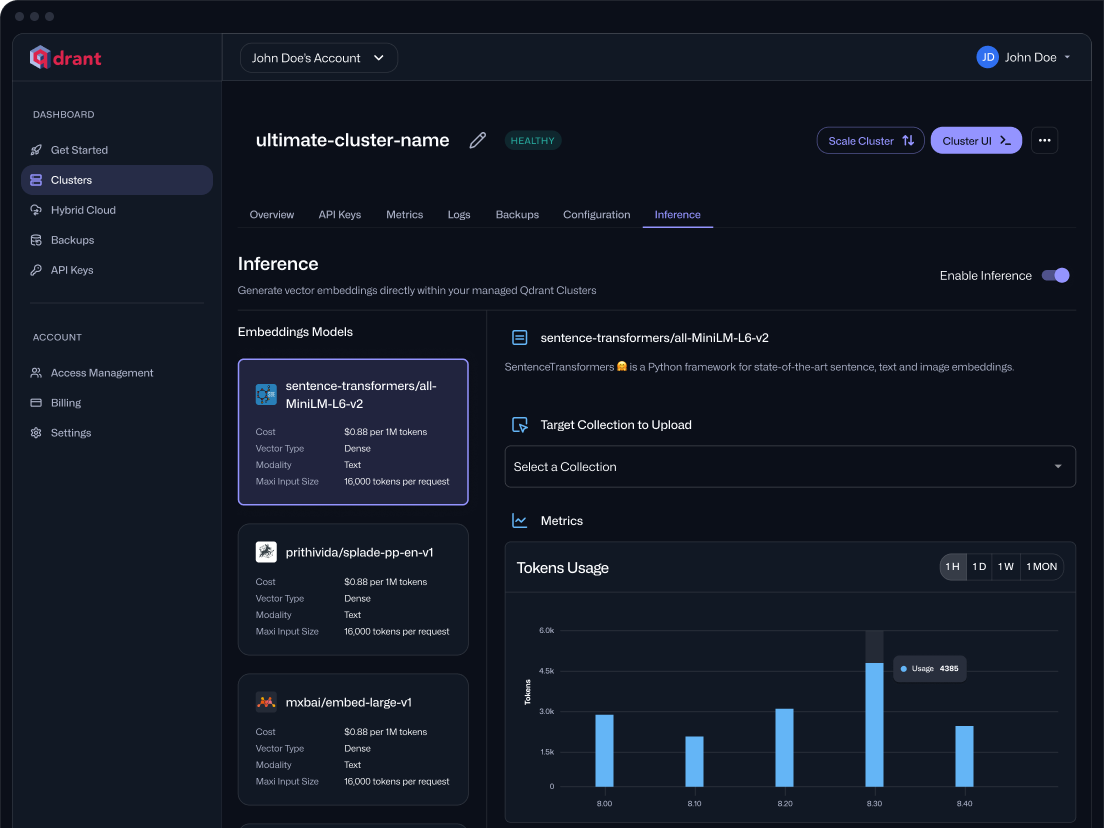
Qdrant Cloud Inference
Run Inferencing Natively in Qdrant Cloud
Qdrant Cloud Inference lets you generate and store text and image embeddings directly within your managed Qdrant Cloud cluster, eliminating external pipelines and supporting multimodal and hybrid search from a single API.

Embed faster. Query faster. Go hybrid or multimodal.

Vector search with built-in embeddings
Generate embeddings inside the network of your Qdrant Cloud cluster. No separate model server or pipeline needed.

In-cluster inference, lower latency
Generate embeddings and run search in-region on AWS, Azure, or GCP (US only). No external hops, no extra egress. Ideal for real-time apps that can’t afford delays or data transfer overhead.

Supports Dense, Sparse & Image Models
Build vector search the way you need. Use dense models like all-MiniLM-L6-v2 for fast semantic match, sparse models like splade-pp-en-v1 or bm25 for keyword recall, or CLIP-style models for image and text. Need Hybrid and/or multimodal search? Covered.
Qdrant Cloud Inference Documentation
Read the Documentation
FAQs
Is Qdrant Cloud Inference available on free clusters?
What kinds of data can I embed?
Where are the embeddings generated?
How much does it cost?
How do I get started?
Will there be options for other embedding models?
Run Inferencing Natively in Qdrant Cloud
Get Started