Building Performant, Scaled Agentic Vector Search with Qdrant
Thierry Damiba
·October 26, 2025

Overview
AI agents have grown from simple Q&A chatbots into systems that can independently plan, retrieve, act, and verify tasks. As developers work to recreate real-life workflows with agents, a common starting point is to give your agent access to a search API.
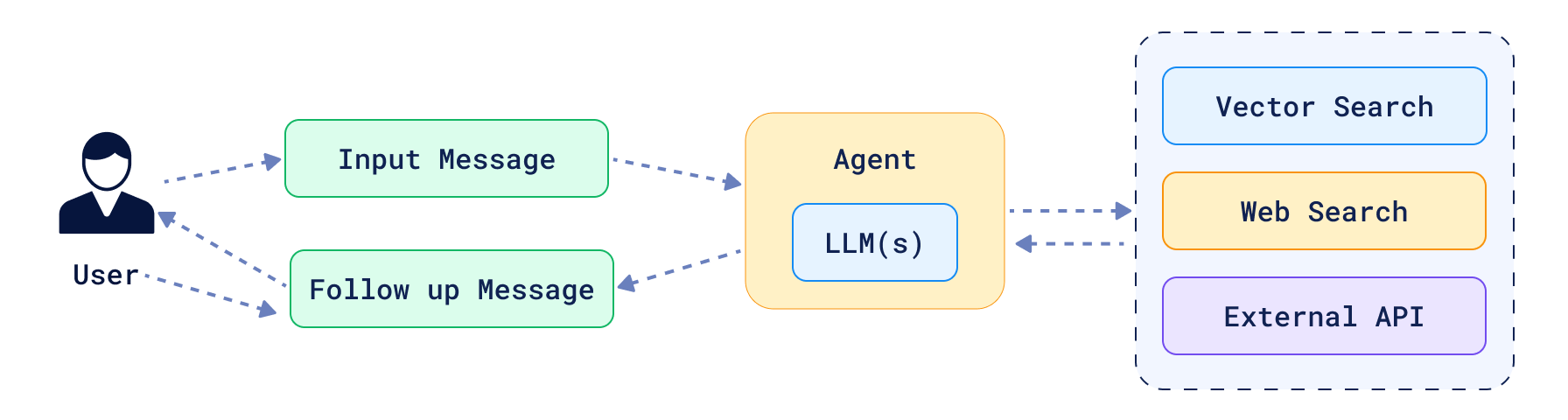
The Limitations of Agents
While agents have proven they can create incredible impact, they still face serious limitations without the right tools. This is where a simple search box isn’t enough, and agents often fail when they move from prototype to production in three key areas:
Memory Loss: Agents struggle to retain context. Without working memory, they can repeat themselves or lose track of multi-step workflows. Without short and long-term memory, they can’t learn from past interactions, adapt to user preferences, or improve over time.
Fragmented Knowledge: Agents live in a world of siloed data: documents, APIs, images, conversations, and more. Most can only reach one slice at a time, often text. This means they fail when asked to integrate across formats, or when the right answer depends on combining structured data, unstructured text, and multimodal data.
Fragile at Scale: What works in a demo breaks in production. Agents that rely on brittle retrieval pipelines slow down under the weight of thousands of calls per workflow. Latency compounds, precision drops, and the experience degrades just when reliability matters most.
Why Vector Search Helps
Imagine a user asking an AI agent to plan a weekend trip to Berlin, in the last week of June. The user has specific needs: The hotel must have a pool, be dog-friendly, and cost no more than $200 a day.
A travel agent with a basic search tool might search for “hotels in Berlin.” The search returns 10 results for hotels in Berlin. What next?
Your agent cannot refine the search by asking questions like, “Which hotels have a pool and cost under $200 a day? Only show me results that have a review in the past 30 days and are available to book.” The AI agent is forced to ingest the entire blob of text and attempt to parse it for the relevant details. This process is slow, uses a lot of tokens, and lends itself to frequent errors and hallucinations.
Reliable agentic workflows require a clear plan executed with precise tools. A vector search engine like Qdrant helps address the flaws of keyword search with various tools:
- Real-time memory layer: fast access to prior steps, actions, and knowledge
- Multimodal support: text, image, videos, audio, and code
- Hybrid search: combining dense + sparse vectors
- Advanced filtering: semantic + metadata + keyword constraints
- Millisecond vector retrieval: Fast retrieval at >billion vector scale
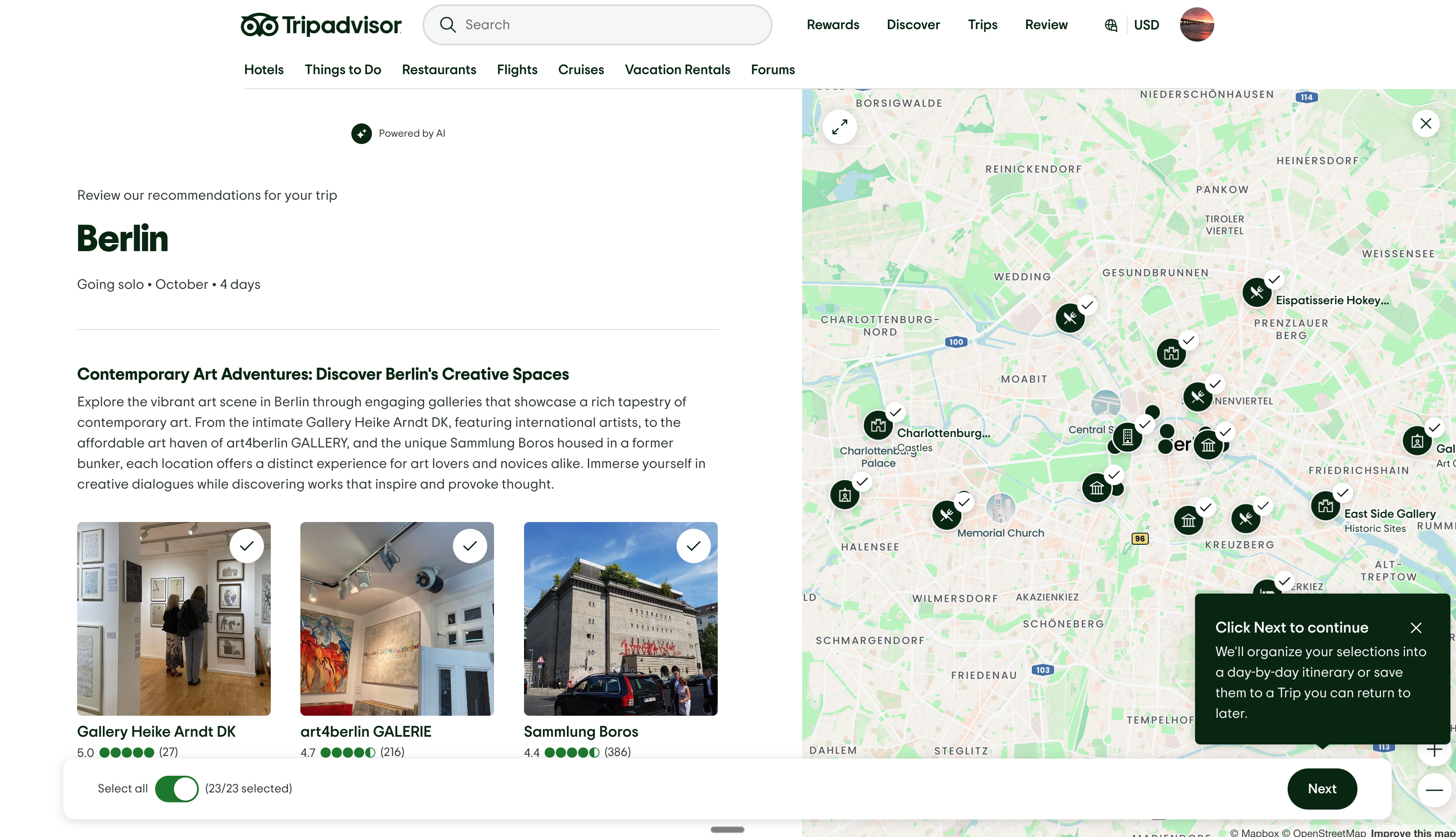
Throughout this article, we’ll use TripAdvisor’s TripBuilder to illustrate how each of the four concepts above is critical for building and deploying agentic search at scale.
The Strategic Role of Memory in AI Agents
For your agent to give the end-user the best results, it needs to remember a few things. It must recall context for continuity across individual conversations, personalize results based on user history and preferences, and operate efficiently at scale.
Vector search engines provide storage and retrieval by meaning, plus by keywords through hybrid search, while also allowing you to apply metadata filters to narrow down results. This combination returns relevant results for complex queries like the one about the hotel. Vector search excels at understanding the subjective meaning of the query, like a “fun” hotel, while filters enforce the factual requirements, such as being “dog-friendly” and costing under $200 a day.
When your agent has to design the itinerary for the trip to Berlin, TripBuilder can inspect memory to see if any similar trips have been planned. This similarity can take into account dates, user preferences, and reviews.
Why Speed Matters in Agentic Retrieval
Agents may run thousands of searches to answer a single complex question. Sometimes those searches are run in parallel, but sometimes they’re run sequentially. For those sequential searches, each millisecond saved compounds. That’s when Qdrant’s Rust-based HNSW indexing, which enables millisecond-level retrieval at scale, becomes a differentiator.
Let’s imagine that you see a 75ms retrieval performance gain with Qdrant. On its own, that might not make a demonstrable difference in the search experience. But if an agent performs four sequential searches, that 300ms starts to have a user experience impact. With that delay, a user can quickly get bored or distracted, leading to frustration. With agentic AI, the retrieval speed optimizations are compounded.
TripBuilder moved from LLM-based (giving the entire text to an LLM and allowing it to make recommendations) to vector-based recommendations using similarity and filters and cut latency by 85%, while improving the perceived quality of results by 30%.
Flexible, Multimodal Retrieval
Giving your agent the context to give users the right results isn’t just about text. You need to be able to search and remember images, video, audio. This enables you to search for exactly what you’re looking for by combining any modality in the same search, and then further improve accuracy with weighted fusion.
You also need the ability to re-rank candidates for diversity, user preferences, or even custom metrics.
Consider search without reranking. It’s like asking a librarian for material on “climate change” and receiving a stack of a dozen books. They’re all on-topic, but the pile is unsorted: a fictional story is on top, an essay is in the middle, and a scientific study is at the bottom. The information you need is there, but you have to dig for it.
Reranking transforms that librarian into an expert curator. They understand you’re likely looking for the most impactful scientific work first. They hand you the same set of books, but now they’re intelligently ordered, with the groundbreaking study right on top. This is the difference between a simple data dump and a guided discovery, ensuring the most valuable results are always the first ones you see.
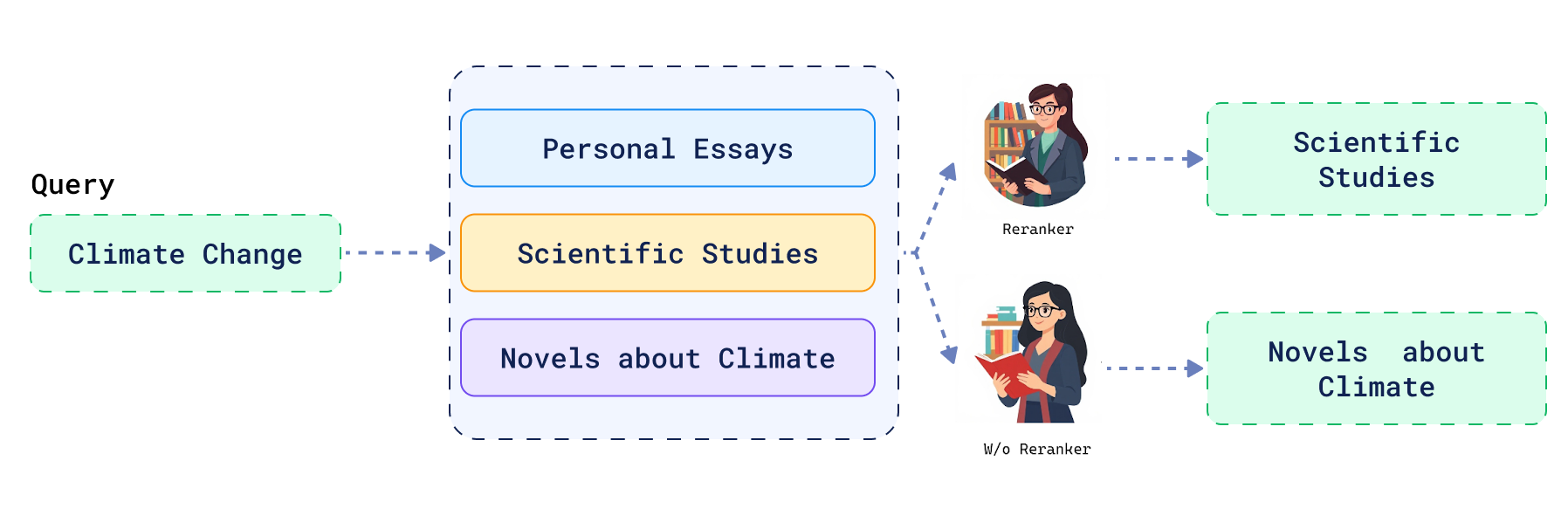
For an agent like TripBuilder, this might mean prioritizing results based on subjective qualities that go beyond simple filters like bed size. For example, if a user wants a hotel with an “exceptional breakfast”, a quality often derived from user reviews, the agent can start by retrieving relevant hotels for their trip to Berlin. Then, it can re-rank the results to boost the ones with the best breakfast reviews, ensuring the user sees the most relevant hotels first.
Context Engineering with Filtering
Combining semantic search, metadata, and keyword filters allows you to specify features like price, date, or location while still searching based on similarity. If your user is looking for a “fun restaurant to end the trip with a Michelin star,” you can specify that your agent search for locations that are open on Sunday, and it can filter based on the user’s past preferences to give them the perfect result.
Real-Time Memory Layer for Agents
Users expect agents to remember the details of their conversation. Your agent’s memory must be updated every time it gets new information, not just at the start of each session. Qdrant supports real-time upserts, giving your agent access to the freshest data for short-term memory and long-term memory.
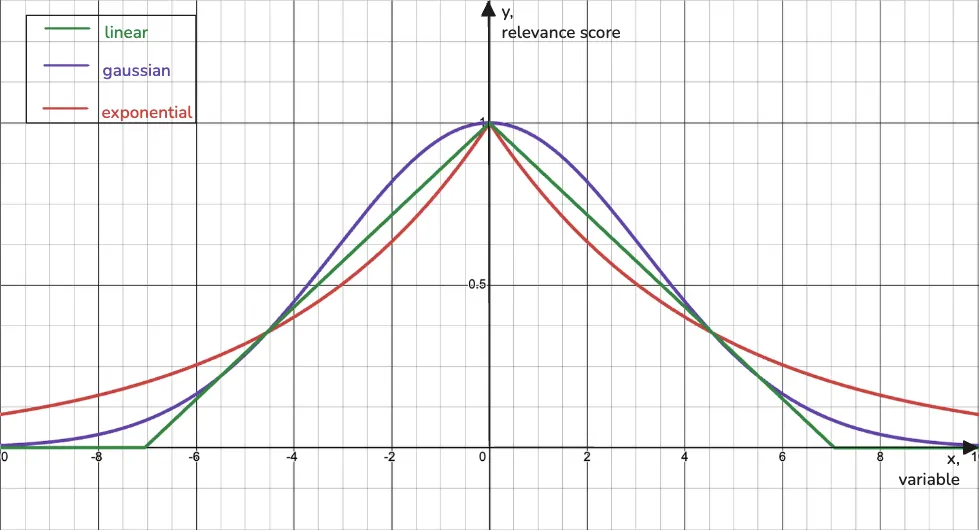
Not all information is timeless. For an agent, knowing what’s recent is as important as knowing what’s relevant. This is where decay functions come in, acting as a “recency boost” during a search.
For example, in a news feed, readers expect the latest headlines to be at the top. At the moment of a search, your agent can apply a scoring bonus to items with a more recent timestamp, pushing them higher in the results.
This is a reranking tool, not a memory system that “forgets” old content so the original data is never altered. Instead, your agent gains an important capability: the ability to effectively decide when “newest” means “best” for a user query."
Integration with Agentic Memory and Evaluation
Agentic Memory
An agent is only as good as the tools it has access to. For the memory and retrieval layers to work effectively, they must integrate reliably and easily with the broader agentic ecosystem. Qdrant is plug-and-play for the most-used agentic memory and agentic builder frameworks. The integration means developers spend less time writing custom code to plug pipes together and more time perfecting their workflow.
Agentic memory systems like mem0 or Cognee are designed to give agents out-of-the-box long-term and short-term memory capabilities. You can easily drop in Qdrant as the vector search engine to power these systems. Qdrant powers the indexing, storing, and retrieval of data, letting the memory system focus on edits, summaries, and deciding what information to remember and what information can be forgotten.
Agentic builders like CrewAI, Dust, Voiceflow, Lyzr, n8n, and Cognigy allow you to orchestrate your agentic flow. With these tools you can define multi-step, multi-agent workflows, and by adding Qdrant they gain a tool for grounding responses with your data, recalling past interactions, and searching multimodal knowledge. Qdrant provides the speed and precision needed for your workflow to be trustworthy as it scales.
Evaluation Frameworks
Once you’ve built a fast, accurate, secure, and scalable agent, how do you know if it is actually working? How does it handle edge cases? What happens when things go wrong? You can’t improve what you don’t measure, which is where evaluations come in.
Retrieval Quality
Your agent’s ability to complete complex tasks is only as good as the context it can retrieve. It is crucial to closely and continuously monitor the agent’s performance with grounding checks to spot and prevent hallucinations, recall@k to ensure relevance in search, and MMR parameters for diversity.
Performance-Cost Tradeoff
In production agents, efficiency is one of, if not the, most important metric to track. First, in enterprise environments you must meet strict latency budgets. Evaluations also let you track the cost per task by tracking token usage and end-to-end compute time. Finally, you can track the effectiveness of your memory layer by monitoring cache hit rates for your memory banks.
Guardrails & Fallbacks
Just like humans, agents aren’t perfect. A production agentic system should expect and anticipate failures and have guardrails to handle them gracefully. You can also use a human in the loop when confidence scores are below a chosen threshold or the query touches on a high-stakes or sensitive topic. To handle a wide range of queries, your agent should use hybrid search. Hybrid search combines the power of semantic search for understanding meaning with the precision of keyword search for exact matches, giving you the best of both worlds.
Effectively Scaling Your Search Agent
The same agent that speeds through a toy dataset with 10,000 points will become sluggish when you scale to millions and billions of points. Qdrant is built with scaling capabilities in mind to make sure that your agent stays fast, reliable, and cheap even as your data grows.
We’ll talk about three concepts you can take advantage of to improve your scale, but if you want even more information on how to scale, check out this article on large scale search.
As your dataset and traffic grow, Qdrant Cloud offers a suite of features to ensure your system can scale effectively. Horizontal scaling is achieved through sharding, which splits your collection across multiple nodes to distribute the load and improve performance. For high availability and fault tolerance, Qdrant supports replication, creating copies of your shards across the cluster.
Qdrant provides robust tools for resource and cost optimization. Vector quantization compresses your data, significantly reducing its memory footprint and speeding up search.
To further manage costs as your dataset expands, on-disk storage allows you to keep the full vectors on more affordable SSDs while the necessary index data remains in RAM. This hybrid approach enables searches over billions of vectors without the high cost of keeping all data in memory.
To enhance the relevance and precision of search queries, Qdrant natively supports hybrid search, which combines traditional keyword-based search with semantic vector search. By doing so, your application can find documents that match exact terms, such as product codes or names, while also discovering documents that are semantically similar in meaning. This ensures that you can find the most relevant information, even in massive and complex datasets.
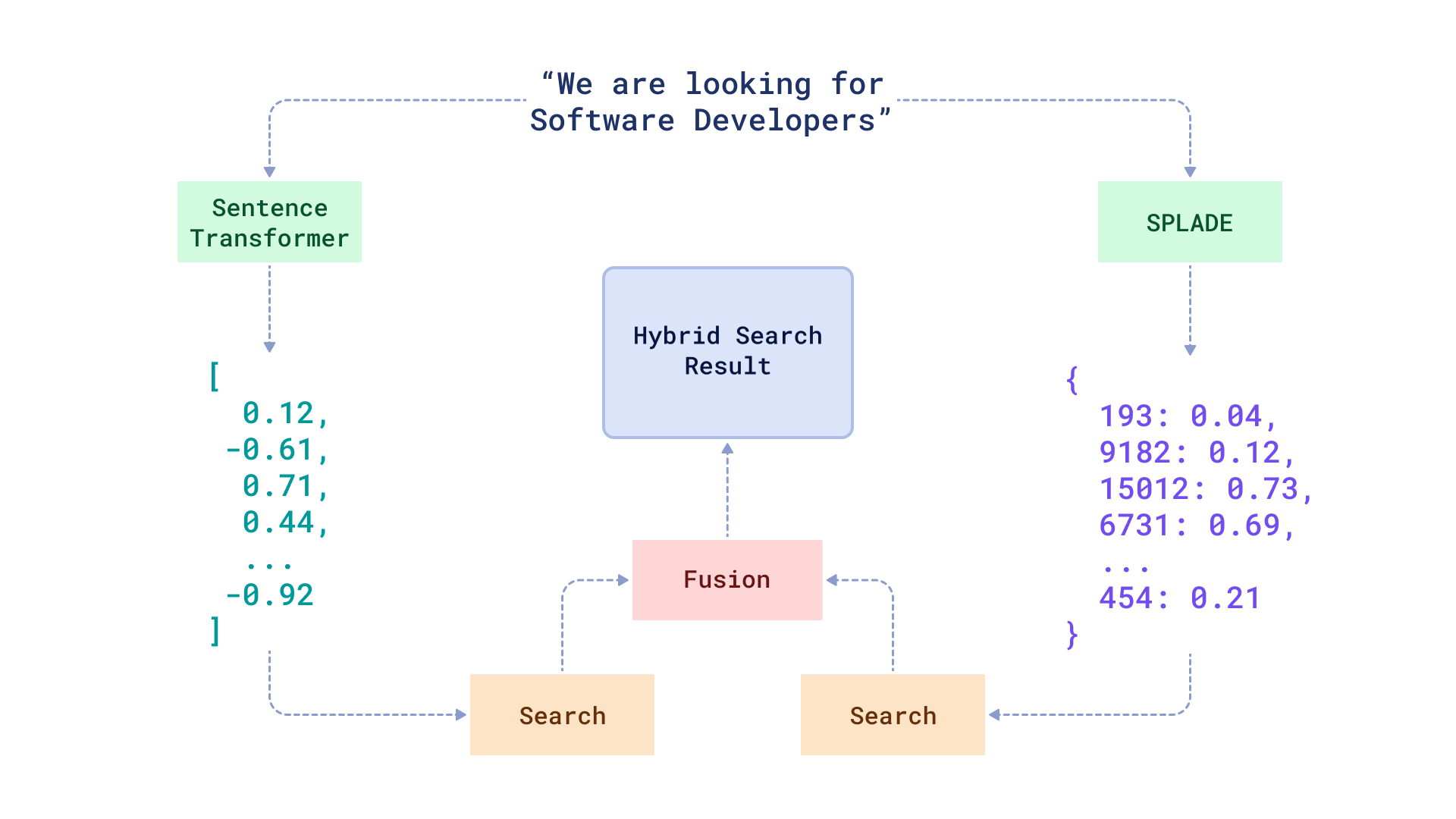
Best Practices for Security in Production
Workflows that are effective for a single user or a handful of users in a development environment where everyone has root access fall apart when you add more users. Your agent needs to know what actions it has permission to take and what information it has access to. It also needs to have the ability to run fast searches even as your data and queries grow.
Qdrant provides production-grade authorization and authentication via API keys, multitenancy, and Role-Based Access Control (RBAC) to make sure your agent doesn’t go rogue.
Authentication for agents is handled by API keys. With Qdrant, API keys are more than just a password. They act as smart credentials that also carry the details of the authorization rules that are enforced once the agent’s identity is confirmed. These keys can be dynamically created as temporary credentials for each user session, making access limited to the session and secure.
Note: Qdrant also supports concurrent queries, so your search won’t slow down as more users are writing queries simultaneously.
Authorization is handled by RBAC and multitenancy, which work hand-in-hand to define and enforce permissions specific to the agent. RBAC is a set of rules that defines the allowed permissions inlcuding read-only, read-write, and admin controls. It answers the question, “What is this agent allowed to do?” For instance, can it only search for hotels (read-only), or can it also add, update, and delete them (read-write)?
A hotel_search_agent that only retrieves information would be restricted to read-only access. In contrast, a hotel_update_agent that adds new user reviews or scrapes new hotel data would require read-write access. A memory_organization_agent might have admin access to create and delete entire collections.
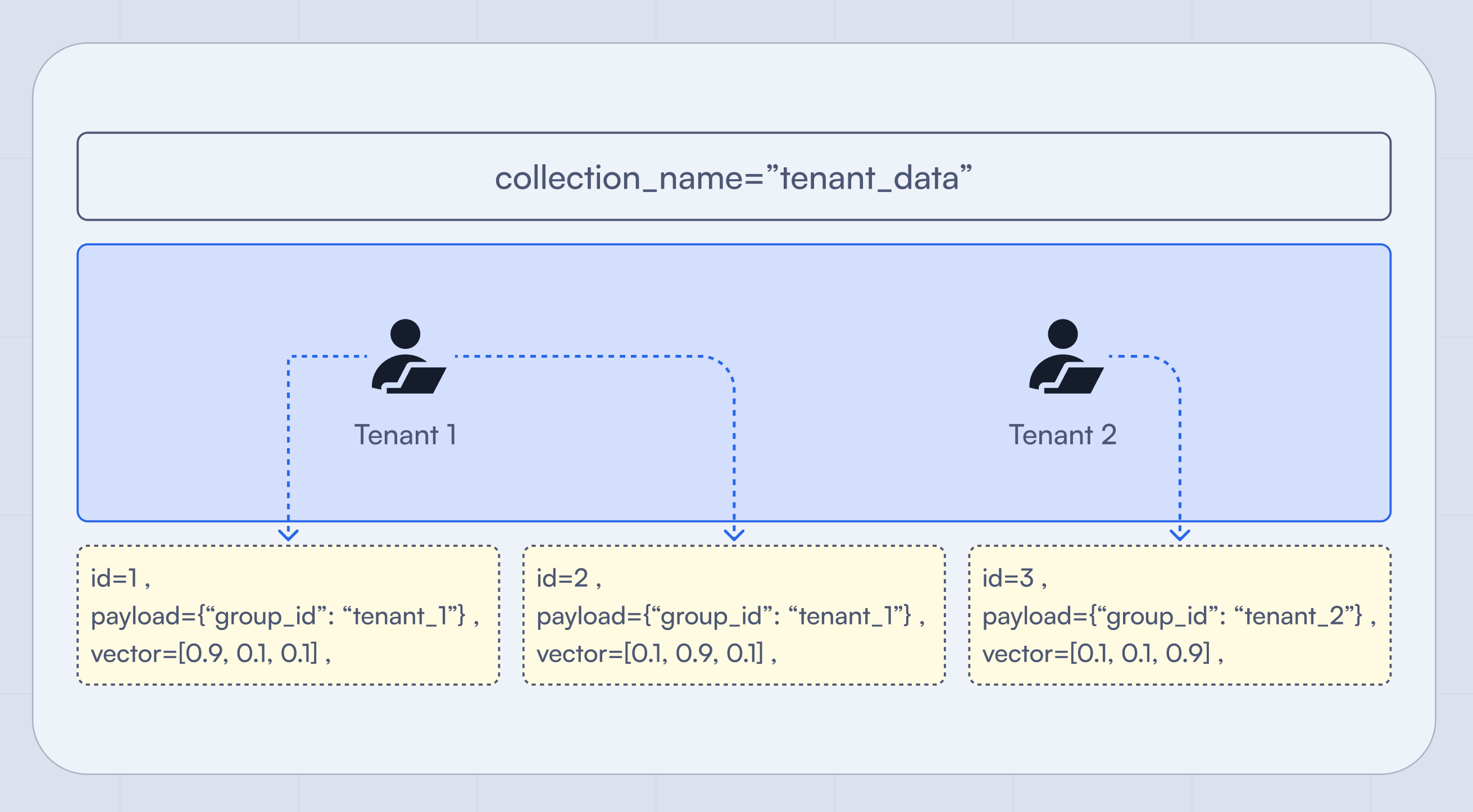
Multitenancy works with RBAC to find out “What specific points can this agent see?” This makes sure that there is no data leakage between users so that user_a isn’t able to access the search history or preferences of user_b.
From a performance and scalability perspective, the best way to implement security is by using a single collection for all your users. Points inside of a collection are designed to scale to billions of entries, while adding a billion collections to one cluster will result in slow retrieval. To make sure that your searches don’t slow down, create a payload index on the tenant ID field so Qdrant can instantly find the right user before running the search.
By combining these security layers, you get a robust system that first ensures the agent’s identity (this agent comes from TripBuilder), checks general permissions with RBAC (this agent can search for hotels), and restricts the search to a subset of data using multitenancy (this agent can only search for hotels it has access to).
Deployment Flexibility
Your AI agent needs to be able to run without issues wherever your users are running their queries. Qdrant offers a few different deployment options that can be toggled with a few lines of code so you don’t have to rebuild your entire system when you are ready to go from prototype to production.
Qdrant lets you deploy in a variety of ways so you can build the system that best fits your use case. You can deploy via the cloud or self host on Docker or your own machine. Read more below:
From Infrastructure to Intelligence
In this article, we explored why a vector search engine is a critical component for building production-grade AI agents. Your agent needs an architecture that supports millisecond retrieval, real-time memory, flexible multimodal retrieval, and precise results with metadata filtering. To thrive in real-world production environments, you need to solidify your agent with authentication and authorization, easy integration with the agentic ecosystem, and trustworthy evaluation and observability.
You can observe this process by looking at TripBuilder, which evolved from TripAdvisor’s travel search tool into a full-fledged agent that can plan a personalized itinerary for users with a few clicks. This demonstrates how, with the right infrastructure, Q&A bots can become human-esque assistants that can handle complex tasks that require multiple agents and steps.
For builders looking to take their agents from prototype to production, Qdrant is the dedicated vector search engine that can make sure your agent is ready for the big leagues. Qdrant provides the memory and retrieval at scale that AI needs to act less like a party trick and more like a trusted team member.