































How Data Graphs Built a True Hybrid Graph RAG Platform
Daniel Azoulai
·April 22, 2026

On this page:

Data Graphs is a UK-based platform company that provides a knowledge graph-as-a-service polystore, built on a proprietary, high-performance graph database engine. Co-founded by Paul Wilton over 10 years ago as a consultancy, Data Graphs has evolved into a platform that serves industries ranging from sports media and publishing to GLAM (galleries, libraries, archives, museums), Agri-Tech, and Regulatory Technology.
The Data Graphs platform combines a proprietary graph database, full-text search, vector embeddings, workflow automation, and an Agentic AI layer into a single, unified backbone for enterprise data. For organizations managing complex, highly connected data, the platform acts as both the system of record and the context layer that reasons across it.
The Hard Truth about RAG: Vector Alone isn’t Enough
When AI-powered retrieval started gaining traction, the Data Graphs team saw the same pattern play out across the industry: vendors and teams claiming to do Graph RAG, but in practice running little more than vector retrieval dressed up with a different name.
The Microsoft Graph RAG pattern, which generated significant community excitement, reinforced this problem. It took unstructured text, extracted entities and relationships, and organized them into communities, but it lacked a structured domain model, offered no empirical query capability, and added complexity without meaningful improvement over standard vector retrieval.
“It had all the same challenges of vector. It wasn’t doing much more. It was taking unstructured text and trying to build a graph of entities and relationships within the unstructured content. But the graph that it creates has no schema associated with it. There’s no structured data conforming to your own domain model. It seemed to offer little or no value over using vector.”
— Paul Wilton, CEO/Co-Founder, Data Graphs
For the Data Graphs team, the real problem was harder: how do you combine structured, empirical data retrieval (where graphs excel) with semantic similarity retrieval from unstructured content (where vector excels), and let an AI agent dynamically choose the best retrieval path for each prompt?
Vector search handles semantic similarity brilliantly. But it can’t do negation, date range filtering, or mathematical operations on empirical data. Ask a vector-only system to find “all artworks created between 1861 and 1865 by American artists influenced by the Hudson River School,” and it will struggle with the precision required. Graph queries handle those constraints natively.
Why Qdrant: Hybrid Cloud, Payload Filtering, and Infra Automation
When evaluating vector search engines, the Data Graphs team tested several options, including Chroma and others. Qdrant stood out for specific, practical reasons.
Hybrid Cloud was the first deciding factor. Data Graphs runs its entire stack in its own AWS environment. Qdrant’s Hybrid Cloud deployment lets them keep vector search colocated with the rest of their infrastructure, maintaining the security and privacy posture their customers require.
The second factor was payload filtering. Qdrant lets you attach structured metadata to embedded documents and filter on that metadata using a DSL that closely matches OpenSearch’s query language. For a team that already had deeply structured JSON-LD data in the graph and OpenSearch full-text filtering patterns in place, this made Qdrant a natural fit. Common metadata structures could be shared across OpenSearch, the knowledge graph, and Qdrant’s payload filters without translation.
“What swung it for us on Qdrant was the Hybrid Cloud, so we could have all of our tech stack running in our own AWS environments. And also the ability to attach structured metadata to embedded documents in exactly the same way we do with OpenSearch and use the same DSL for filtering.”
— Paul Wilton, CEO/Co-Founder, Data Graphs
Infrastructure automation sealed the deal. Terraform support, automated deployments, and developer-friendly tooling meant the engineering team could integrate Qdrant into their existing CI/CD and infrastructure-as-code workflows without friction.
How the True Hybrid Retrieval Pattern Works
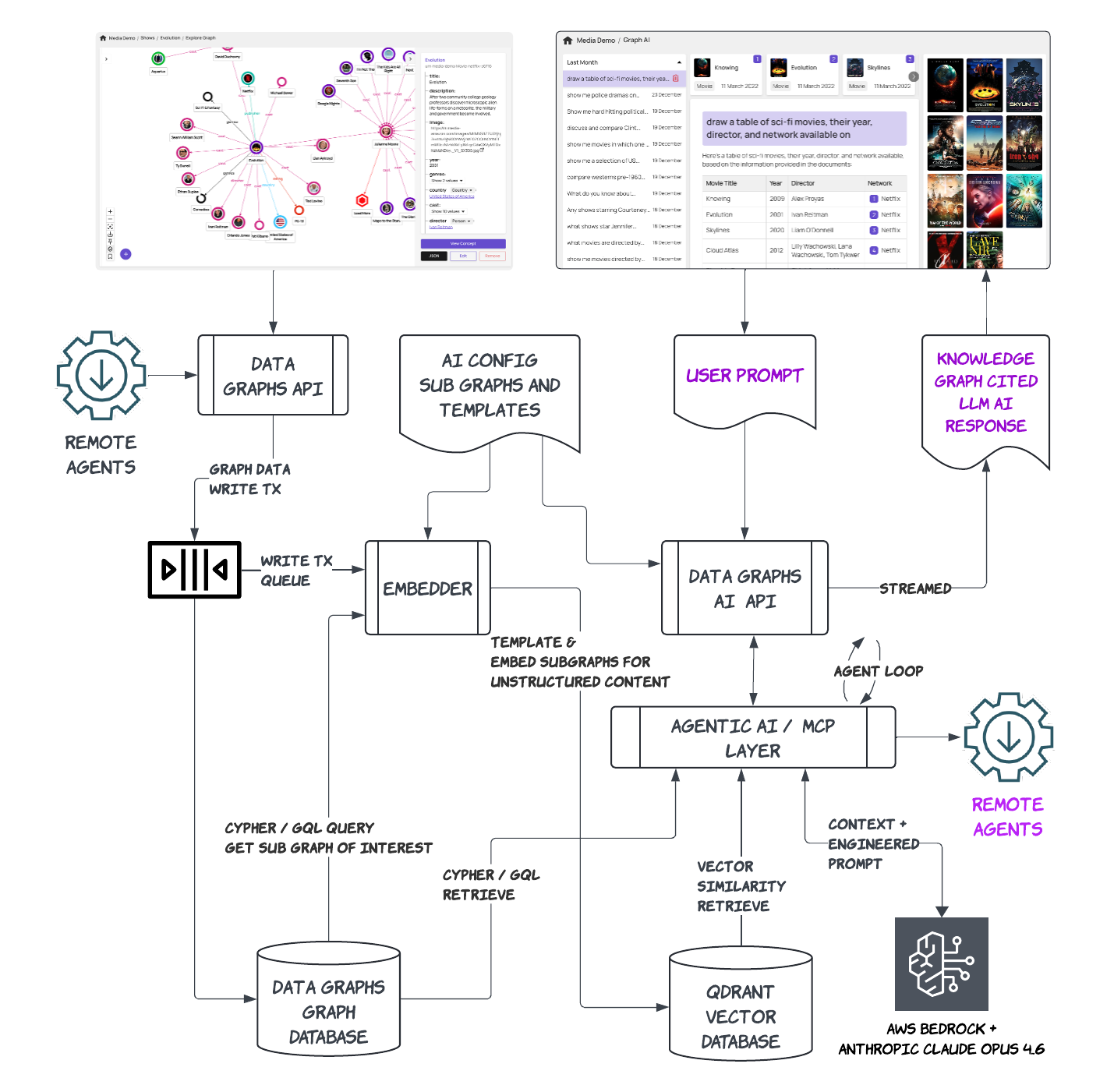
Data Graphs built a retrieval architecture that goes beyond standard RAG. The system uses Qdrant and the proprietary GQL/Cypher graph engine as complementary retrieval layers, orchestrated by an Agentic AI pump.
Real-time embedding from the graph. As data is written into the knowledge graph (via streams or APIs), Data Graphs embeds selected (unstructured) properties on the fly through queuing. The embedding configuration is template-driven: for each use case, the team specifies which parts of the graph to embed and how. Embedded documents land in separate Qdrant collections with rich metadata attached for filtering.
Schema-first retrieval. Every retrieval session begins with the AI agent pulling the graph’s schema, the full cohesive model of entity classes, relationships, and property types. This step gives the LLM a complete understanding of the data domain, so it can make informed decisions about how to retrieve.
Agentic Decisions. Once the model is retrieved the Data Graphs internal agent has skills to determine how best to retrieve data and content to respond to the prompt. The cohesive schema is key here. By analysing the prompt questions against the schema, the Agent can decide whether to write a GQL (or Cypher) query against the graph to retrieve, whether it needs to find relevant unstructured content from Qdrant , or potentially both.
Blended retrieval and reasoning. The agent then executes graph queries for structured, empirical data and vector retrieval from Qdrant for semantic, unstructured content in parallel. Once retrieval has occurred, the Agent decides if it has enough data and content in context to make an informed answer. If not it may make subsequent requests to Qdrant and the Graph to pull more data in. Results are blended, passed back to the LLM for reasoning, and every data point is cited back to its source in the knowledge graph, providing verifiable provenance.
“I see them as really complementary technologies. Vector excels at unstructured retrieval, and the graph excels at highly connected structured and empirical data empirical data retrieval. And when you combine the two with a very rich cohesive semantic model and expose that to the Agentic AI, it’s almost like a sweet spot.”
— Paul Wilton, CEO/Co-Founder, Data Graphs
Qdrant in Production: Stability and Developer Experience
After 18 months of running Qdrant in production, the Data Graphs team reports zero significant issues. The infrastructure patterns around Hybrid Cloud deployment and the Terraform-based automation pipeline made operational management straightforward from the start.
“We’ve had no real issues at all with Qdrant. We’ve loved working with it. One of the big wins was the infrastructure patterns around the Hybrid Cloud. Really nice for us. Along with developer support for Terraform and deployment automation.”
— Paul Wilton, Co-Founder, Data Graphs
The platform currently runs on AWS Bedrock using a proprietary Agent pump with Claude Opus 4.6.
What’s Next: Agentic-first, Machine-first
Data Graphs is moving toward a future where machines, not humans, are the primary consumers of the platform. The visual tools built for human users will remain, but the team sees agentic interactions as the dominant access pattern.
Plans include deeper integration with the Claude SDK, expanding the MCP tooling layer. Qdrant will remain central to the retrieval stack, with both its role, and the graph’s role expanding as the agentic layer grows.
From Vector-only RAG to True Hybrid Intelligence
Data Graphs demonstrates what becomes possible when vector search and graph retrieval work as genuine partners rather than competitors. By using Qdrant for what it does best (fast semantic similarity search with rich metadata filtering) and combining it with a structured graph database engine for empirical, relationship-driven retrieval, the team built a platform that delivers accurate, cited, domain-aware AI responses across industries.
For teams building beyond basic RAG, the lesson is clear: the retrieval layer determines the ceiling of your AI’s intelligence. Choosing the right components and composing them well makes the difference. True Hybrid RAG delivers the ideal context layer.
