































How TrustGraph built enterprise-grade agentic AI with Qdrant
Daniel Azoulai
·October 10, 2025

On this page:

TrustGraph + Qdrant: A Technical Deep Dive
When teams first experiment with agentic AI, the journey often starts with a slick demo: a few APIs stitched together, a large language model answering questions, and just enough smoke and mirrors to impress stakeholders.
But as soon as those demos face enterprise requirements (constant data ingestion, compliance, thousands of users, 24×7 uptime), the illusion breaks. Services stall at the first failure, query reliability plummets, and regulatory guardrails are nowhere to be found. What worked in a five-minute demo becomes impossible to maintain in production.
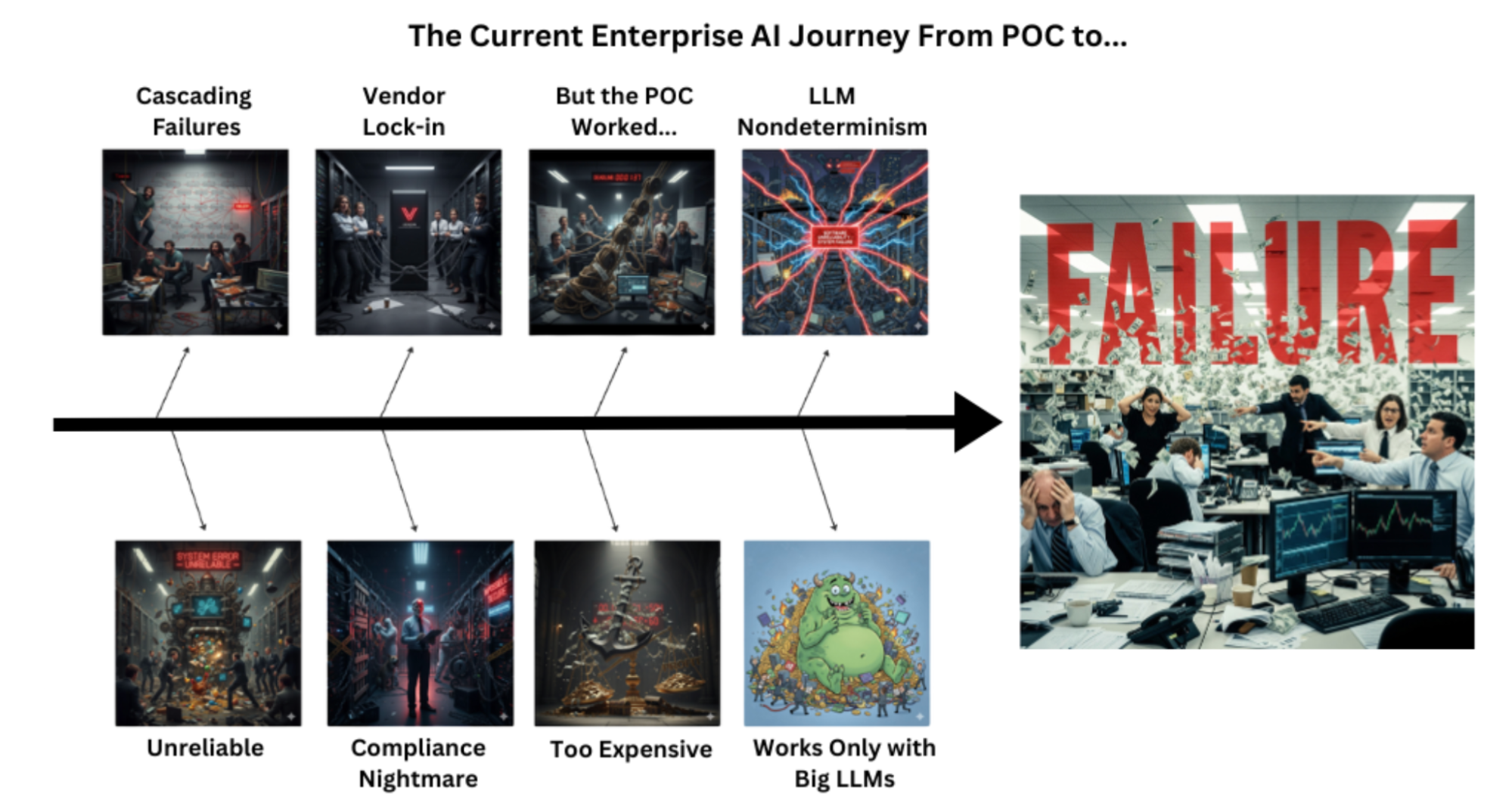 Failure mode map: “From POC to production.”
Failure mode map: “From POC to production.”
This is exactly the gap TrustGraph set out to close. From day one, they designed their platform for availability, determinism, and scale with Qdrant as a core piece of the architecture.
Building for Production, Not Demos
TrustGraph’s architecture is fully containerized, modular, and deployable across cloud, virtualized, or bare-metal environments.
At its core are three pillars:
A streaming spine with Apache Pulsar. Persistent queues, schema evolution, and replayability provide resilience. If a process fails, it automatically restarts and resumes without data loss.
Graph-native semantics. Knowledge is modeled in Resource Description Framework (RDF), with SPARQL templates guiding retrieval. This reduces dependence on brittle, model-generated queries and ensures answers are precise and auditable.
Qdrant vector search. Entities are embedded and stored in Qdrant, enabling fast, reliable similarity search that integrates into the graph-driven workflow.
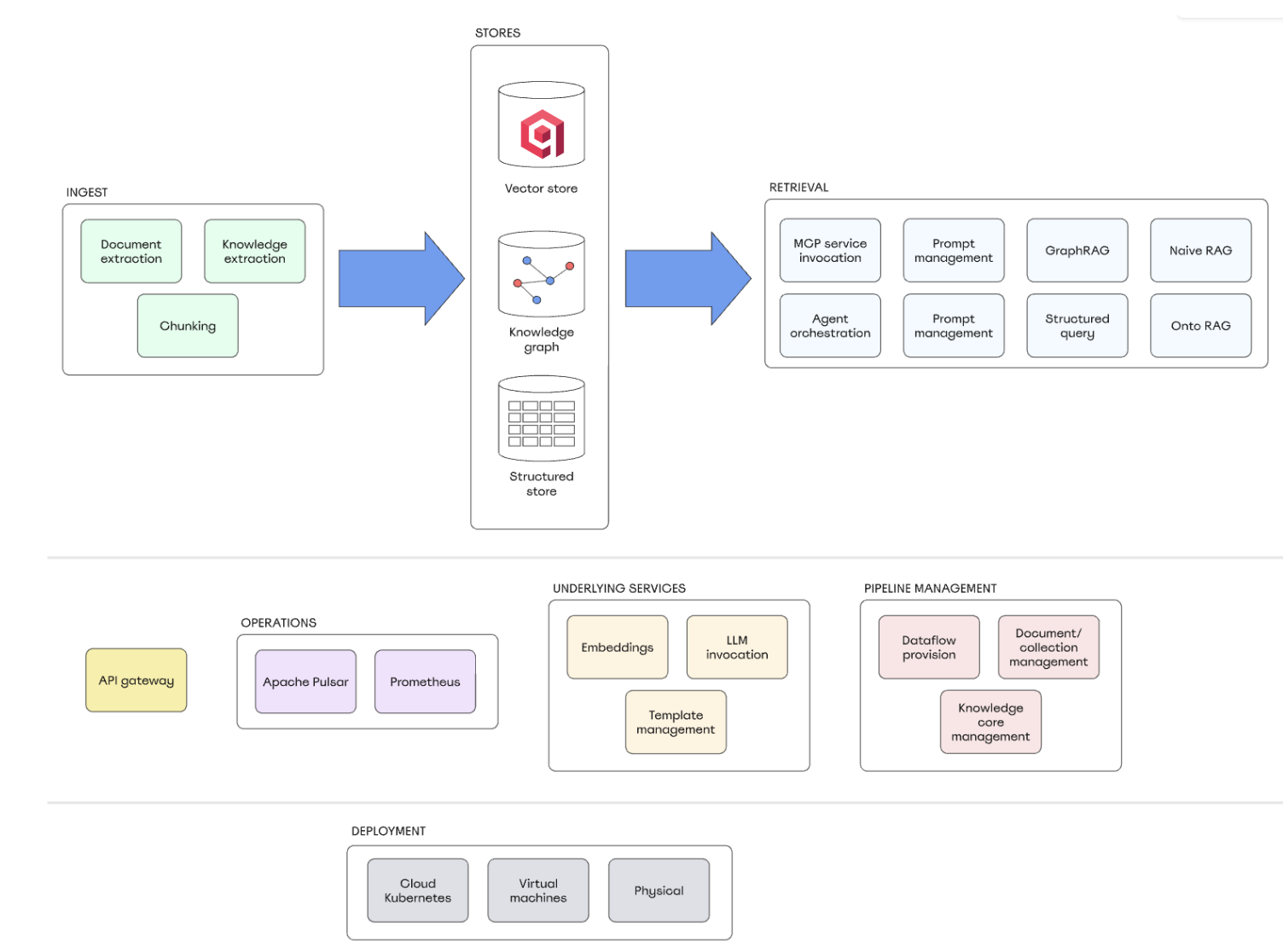 Architecture overview
Architecture overview
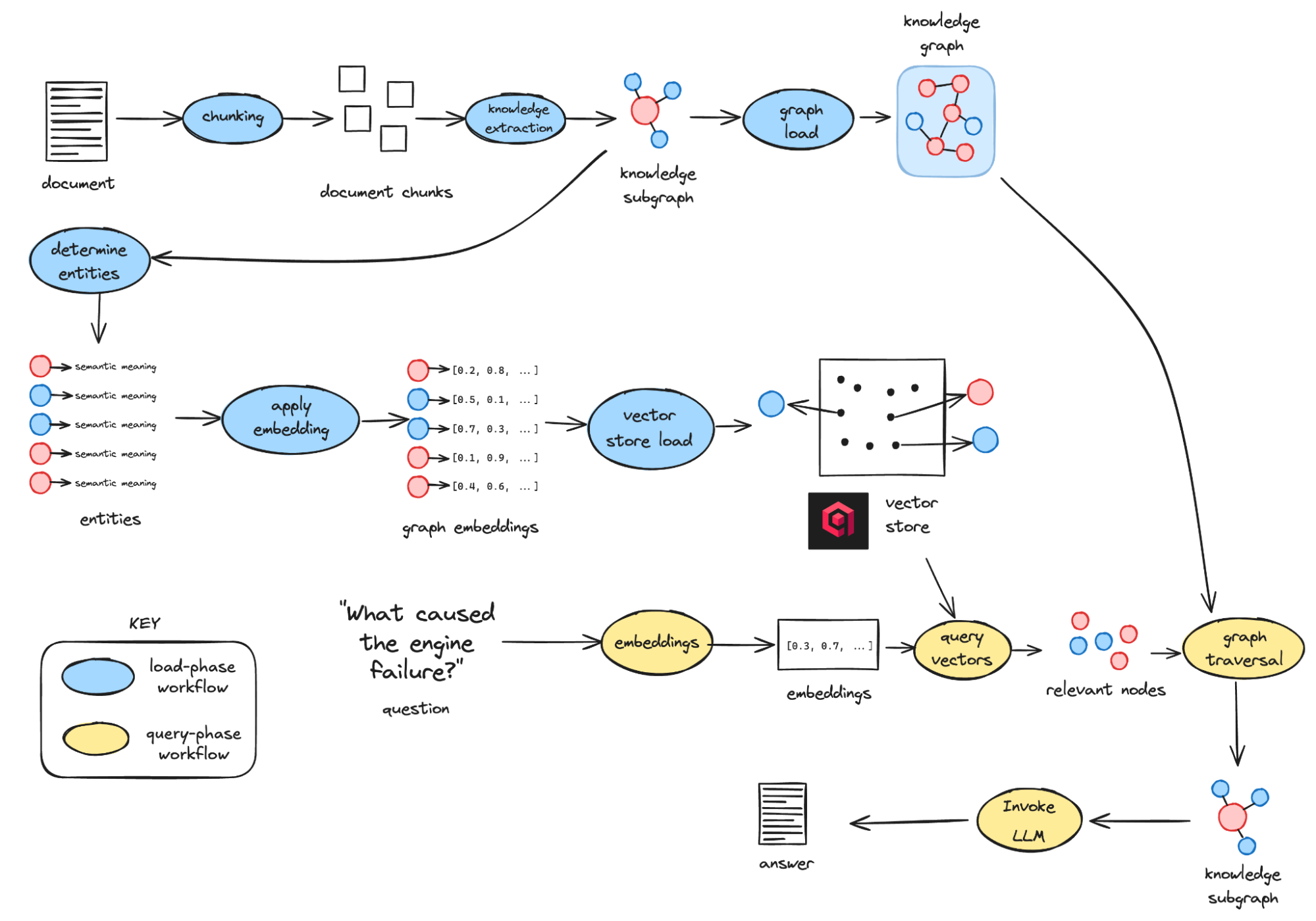
From Documents to Knowledge
Instead of breaking documents into chunks, TrustGraph extracts facts. An LLM identifies entities and relationships, assembling them into a knowledge graph. In parallel, embeddings of entities are stored in Qdrant.
This dual representation allows queries to ground themselves in both semantic similarity and graph structure. For example, asking “Tell me about Alice” retrieves the “Alice” entity via Qdrant and maps it to her connections in the graph, rather than just surfacing sentences that happen to contain her name.
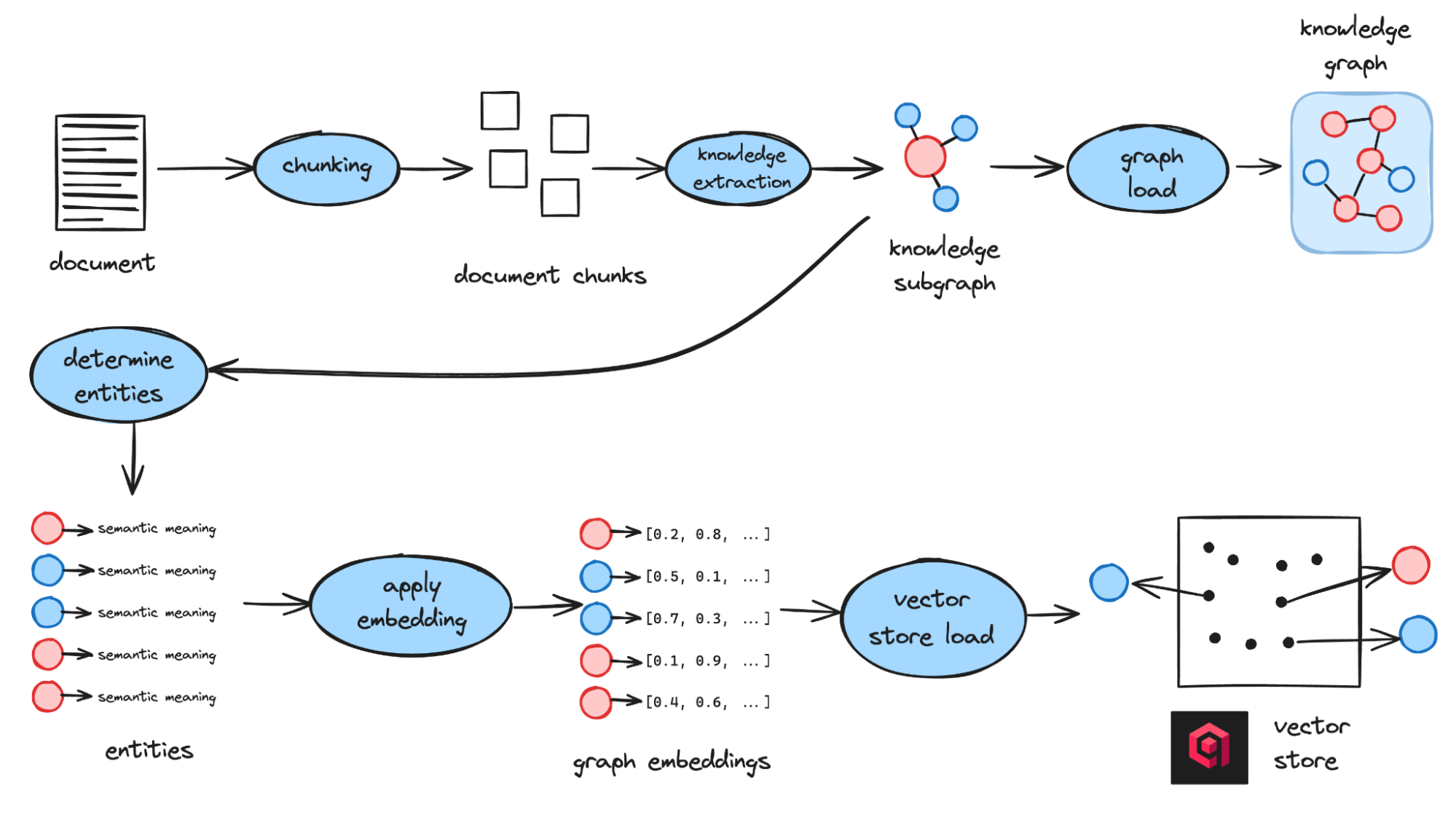 Ingestion process
Ingestion process
Retrieval That Goes Beyond RAG
When a query enters the system, it follows a deterministic path:
The query is embedded into vectors.
Qdrant retrieves the nearest entities.
Those entities expand into a subgraph of related facts.
The subgraph is passed to the LLM, which answers strictly from that curated context.
This approach surpasses traditional RAG, which stops at semantically similar chunks. Graph-anchored retrieval allows TrustGraph to surface causal or related knowledge. For example, “Why did the engine fail?” doesn’t just find mentions of “engine” and “failure”, it also uncovers related causes like metal fatigue or coolant leaks through graph connections.
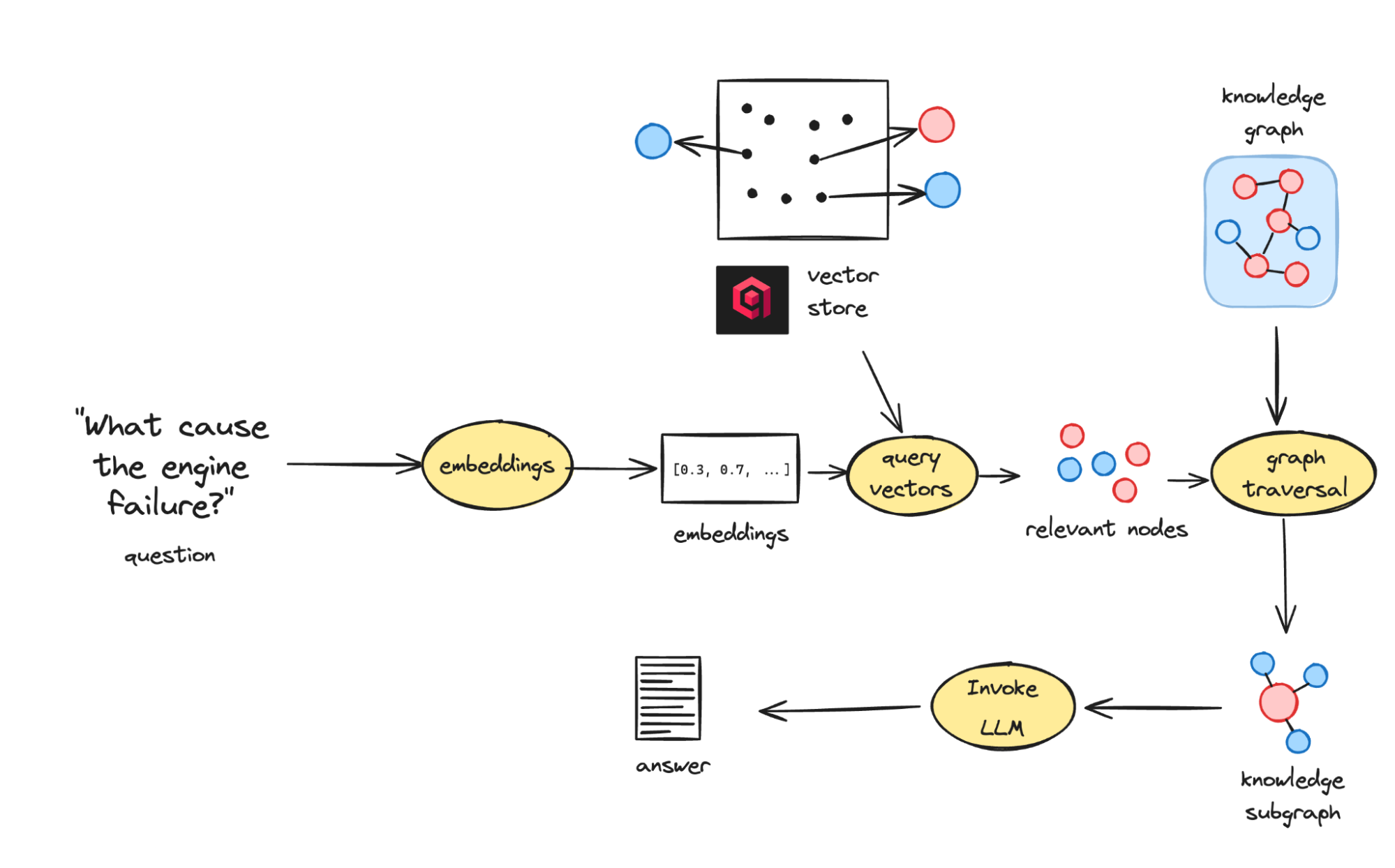 Query process
Query process
Agentic AI at Scale
TrustGraph’s retrieval capabilities sit within a broader agentic AI framework. Developers can orchestrate pipelines that combine:
GraphRAG for structured fact retrieval
Template-driven queries for determinism
MCP tool invocation for external actions
NLPR - Natural Language Precision Retrieval (experimental), which uses ontologies to drive specialized extraction
This enables enterprises to build retrieval pipelines that integrate internal knowledge graphs with external data sources, while maintaining reliability and control.
 Ingestion & querying process
Ingestion & querying process
Outcomes That Matter in Production
By combining a resilient streaming backbone, graph-native semantics, and Qdrant-powered retrieval, TrustGraph delivers production-grade architectural outcomes:
Determinism — Template-driven SPARQL and Qdrant similarity search eliminate fragile query synthesis.
Resilience — Pulsar pipelines replay and recover automatically, keeping systems responsive during failures or rolling updates.
Scalability & Sovereignty — The platform runs on diverse hardware stacks, including non-NVIDIA GPUs, and supports strict European data sovereignty requirements.
Developer Simplicity — Qdrant’s open-source, containerized design makes scaling straightforward and reduces operational friction.
“We haven’t had a reason to revisit alternatives. Qdrant checks the boxes for speed, reliability, and simplicity—and it keeps doing so.”
— Daniel Davis, Co-founder, TrustGraph
From Demos to Durable Infrastructure
TrustGraph shows how agentic AI can evolve from flashy demos into mission-critical enterprise software. By grounding retrieval in graph semantics and Qdrant’s vector engine, they push non-determinism to the edges while maintaining uptime, auditability, and sovereignty.
