Qdrant 1.13 - GPU Indexing, Strict Mode & New Storage Engine
David Myriel
·January 23, 2025

On this page:
Qdrant 1.13.0 is out! Let’s look at the main features for this version:
GPU Accelerated Indexing: Fast HNSW indexing with architecture-free GPU support.
Strict Mode: Enforce operation restrictions on collections for enhanced control.
HNSW Graph Compression: Reduce storage use via HNSW Delta Encoding.
Named Vector Filtering: New has_vector filtering condition for named vectors.
Custom Storage: For constant-time reads/writes of payloads and sparse vectors.
GPU Accelerated Indexing

We are making it easier for you to handle even the most demanding workloads.
Qdrant now supports GPU-accelerated HNSW indexing on all major GPU vendors, including NVIDIA, AMD and Intel. This new feature reduces indexing times, making it a game-changer for projects where speed truly matters.
Indexing over GPU now delivers speeds up to 10x faster than CPU-based methods for the equivalent hardware price.
Our custom implementation of GPU-accelerated HNSW indexing is built entirely in-house. Unlike solutions that depend on third-party libraries, our approach is vendor-agnostic, meaning it works seamlessly with any modern GPU that supports Vulkan API. This ensures broad compatibility and flexibility for a wide range of systems.
Here is a picture of us, running Qdrant with GPU support on a SteamDeck (AMD Van Gogh GPU):
Qdrant on SteamDeck with integrated AMD GPU
This experiment didn’t require any changes to the codebase, and everything worked right out of the box with our AMD Docker image.
As of right now this solution supports only on-premises deployments, but we will introduce support for Qdrant Cloud shortly.
Benchmarks on Common GPUs
Qdrant doesn’t require high-end GPUs to achieve significant performance improvements. The table below compares indexing times and instance costs for 1 million vectors (1536-dimensional) across common GPU machines:
| Configuration | Indexing time (s) | Price per Instance (USD/month) |
|---|---|---|
| AMD Radeon Pro V520 | 33.1 | $394.20 (CPU + GPU) |
| Nvidia T4 | 19.1 | $277.40 (CPU) + $255.50(GPU) = $532.90 |
| Nvidia L4 | 12.4 | $214.32 (CPU) + $408.83(GPU) = $624.15 |
| 8 CPU Cores | 97.5 | $195.67 |
| 4 CPU Cores | 221.9 | $107.16 |
Quoted prices are from Google Cloud Platform (NVIDIA) and AWS (AMD)
Additional Benefits:
- Multi-GPU Support: Index segments concurrently to handle large-scale workloads.
- Hardware Flexibility: Doesn’t require high-end GPUs to achieve significant performance improvements.
- Full Feature Support: GPU indexing supports all quantization options and datatypes implemented in Qdrant.
- Large-Scale Benefits: Fast indexing unlocks larger size of segments, which leads to higher RPS on the same hardware.
Instructions & Documentation
The setup is simple, with pre-configured Docker images (check Docker Registry) for GPU environments like NVIDIA and AMD. We’ve made it so you can enable GPU indexing with minimal configuration changes.
Note: Logs will clearly indicate GPU detection and usage for transparency.
Read more about this feature in the GPU Indexing Documentation
Interview With the Creator of GPU Indexing
We interviewed Qdrant’s own Ivan Pleshkov from the Core development team. Ivan created the new GPU indexing feature with an innovative approach he brings from the gaming industry. Listen in to hear about his vision and challenges while building the feature.
Strict Mode for Operational Control

Strict Mode ensures consistent performance in distributed deployments by enforcing operational controls. It limits computationally intensive operations like unindexed filtering, batch sizes, and search parameters (hnsw_ef, oversampling) This prevents inefficient usage that could overload your system.
Additional safeguards, including limits on payload sizes, filter conditions, and timeouts, keep high-demand applications fast and reliable. This feature is configured via strict_mode_config, and it allows collection-level customization while maintaining backward compatibility.
New collections will default to Strict Mode, ensuring compliance by design and balancing workloads across tenants.
This feature also enhances usability by providing detailed error messages when requests exceed defined limits. The system will give you clear guidance on resolution steps.
Strict Mode solves the “noisy neighbor” problem and optimizes resource allocation, making multi-tenancy work nicely in serverless mode.
Enable Strict Mode
To configure Strict Mode, refer to the schema definitions for all available strict_mode_config parameters.
When a defined limit is crossed, Qdrant responds with a client-side error that includes details about the specific limit exceeded. This can make troubleshooting much simpler.
The
enabledfield in the configuration acts as a dynamic toggle, allowing you to activate or deactivate Strict Mode as needed.
In this example we enable Strict Mode when creating a collection to activate the unindexed_filtering_retrieve limit:
PUT /collections/{collection_name}
{
"strict_mode_config": {
"enabled": true,
"unindexed_filtering_retrieve": true
}
}
curl -X PUT http://localhost:6333/collections/{collection_name} \
-H 'Content-Type: application/json' \
--data-raw '{
"strict_mode_config": {
"enabled":" true,
"unindexed_filtering_retrieve": true
}
}'
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
strict_mode_config=models.SparseVectorParams{ enabled=True, unindexed_filtering_retrieve=True },
)
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({ host: "localhost", port: 6333 });
client.createCollection("{collection_name}", {
strict_mode_config: {
enabled: true,
unindexed_filtering_retrieve: true,
},
});
use qdrant_client::Qdrant;
use qdrant_client::qdrant::{CreateCollectionBuilder, StrictModeConfigBuilder};
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.create_collection(
CreateCollectionBuilder::new("{collection_name}")
.strict_config_mode(StrictModeConfigBuilder::default().enabled(true).unindexed_filtering_retrieve(true)),
)
.await?;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import io.qdrant.client.grpc.Collections.CreateCollection;
import io.qdrant.client.grpc.Collections.StrictModeCOnfig;
QdrantClient client =
new QdrantClient(QdrantGrpcClient.newBuilder("localhost", 6334, false).build());
client
.createCollectionAsync(
CreateCollection.newBuilder()
.setCollectionName("{collection_name}")
.setStrictModeConfig(
StrictModeConfig.newBuilder().setEnabled(true).setUnindexedFilteringRetrieve(true).build())
.build())
.get();
using Qdrant.Client;
using Qdrant.Client.Grpc;
var client = new QdrantClient("localhost", 6334);
await client.CreateCollectionAsync(
collectionName: "{collection_name}",
strictModeConfig: new StrictModeConfig { enabled = true, unindexed_filtering_retrieve = true }
);
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: "{collection_name}",
StrictModeConfig: &qdrant.StrictModeConfig{
Enabled: qdrant.PtrOf(true),
IndexingThreshold: qdrant.PtrOf(true),
},
})
You may also use the
PATCHrequest to enable Strict Mode on an existing collection.
Read more about Strict Mode in the Database Administration Guide
HNSW Graph Compression

We’re always looking for ways to make your search experience faster and more efficient. That’s why we are introducing a new optimization method for our HNSW graph technology: Delta Encoding. This improvement makes your searches lighter on memory without sacrificing speed.
Delta Encoding is a clever way to compress data by storing only the differences (or “deltas”) between values. It’s commonly used in search engines (for the classical inverted index) to save space and improve performance. We’ve now adapted this technique for the HNSW graph structure that powers Qdrant’s search.
In contrast with traditional compression algorithms, like gzip or lz4, Delta Encoding requires very little CPU overhead for decompression, which makes it a perfect fit for the HNSW graph links.
Our experiments didn’t observe any measurable performance degradation. However, the memory footprint of the HNSW graph was reduced by up to 30%.
For more general info, read about Indexing and Data Structures in Qdrant
Filter by Named Vectors

In Qdrant, you can store multiple vectors of different sizes and types in a single data point. This is useful when you have to representing data with multiple embeddings, such as image, text, or video features.
We previously introduced this feature as Named Vectors. Now, you can filter points by checking if a specific named vector exists.
This makes it easy to search for points based on the presence of specific vectors. For example, if your collection includes image and text vectors, you can filter for points that only have the image vector defined.
Create a Collection with Named Vectors
Upon collection creation, you define named vector types, such as image or text:
PUT /collections/{collection_name}
{
"vectors": {
"image": {
"size": 4,
"distance": "Dot"
},
"text": {
"size": 8,
"distance": "Cosine"
}
},
"sparse_vectors": {
"sparse-image": {},
"sparse-text": {},
},
}
Sample Request
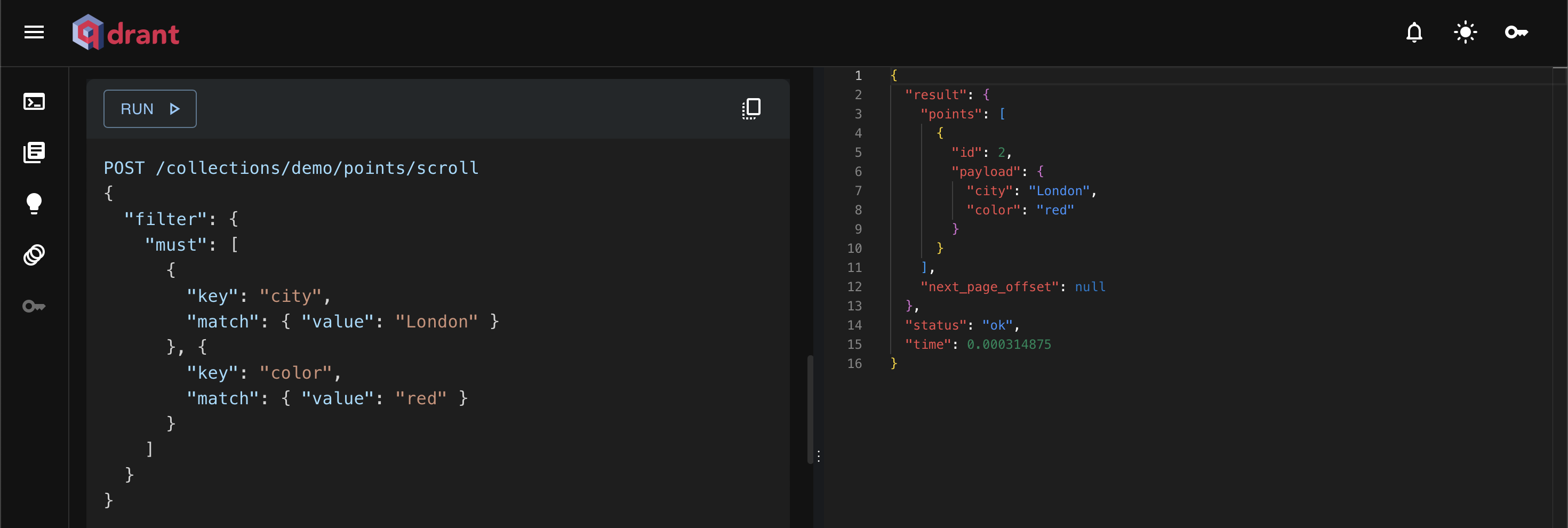
Some points might include both image and text vectors, while others might include just one. With this new feature, you can easily filter for points that specifically have the image vector defined.
POST /collections/{collection_name}/points/scroll
{
"filter": {
"must": [
{ "has_vector": "image" }
]
}
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.scroll(
collection_name="{collection_name}",
scroll_filter=models.Filter(
must=[
models.HasVectorCondition(has_vector="image"),
],
),
)
client.scroll("{collection_name}", {
filter: {
must: [
{
has_vector: "image",
},
],
},
});
use qdrant_client::qdrant::{Condition, Filter, ScrollPointsBuilder};
use qdrant_client::Qdrant;
let client = Qdrant::from_url("http://localhost:6334").build()?;
client
.scroll(
ScrollPointsBuilder::new("{collection_name}")
.filter(Filter::must([Condition::has_vector("image")])),
)
.await?;
import java.util.List;
import static io.qdrant.client.ConditionFactory.hasVector;
import static io.qdrant.client.PointIdFactory.id;
import io.qdrant.client.grpc.Common.Filter;
import io.qdrant.client.grpc.Points.ScrollPoints;
client
.scrollAsync(
ScrollPoints.newBuilder()
.setCollectionName("{collection_name}")
.setFilter(
Filter.newBuilder()
.addMust(hasVector("image"))
.build())
.build())
.get();
using Qdrant.Client;
using static Qdrant.Client.Grpc.Conditions;
var client = new QdrantClient("localhost", 6334);
await client.ScrollAsync(collectionName: "{collection_name}", filter: HasVector("image"));
import (
"context"
"github.com/qdrant/go-client/qdrant"
)
client, err := qdrant.NewClient(&qdrant.Config{
Host: "localhost",
Port: 6334,
})
client.Scroll(context.Background(), &qdrant.ScrollPoints{
CollectionName: "{collection_name}",
Filter: &qdrant.Filter{
Must: []*qdrant.Condition{
qdrant.NewHasVector(
"image",
),
},
},
})
This feature makes it easier to manage and query collections with heterogeneous data. It will give you more flexibility and control over your vector search workflows.
To dive deeper into filtering by named vectors, check out the Filtering Documentation
Custom Storage Engine

When Qdrant started, we used RocksDB as the storage backend for payloads and sparse vectors. RocksDB, known for its versatility and ability to handle random reads and writes, seemed like a solid choice. But as our needs evolved, its “general-purpose” design began to show cracks.
RocksDB is built to handle arbitrary keys and values of any size, but this flexibility comes at a cost.
A key example is compaction, a process that reorganizes data on disk to maintain performance. Under heavy write loads, compaction can become a bottleneck, causing significant slowdowns. For Qdrant, this meant huge latency spikes at random moments causing timeout errors during large uploads—a frustrating roadblock.
To solve this, we built a custom storage backend optimized for our specific use case. Unlike RocksDB, our system delivers consistent performance by ensuring reads and writes require a constant number of disk operations, regardless of data size. As a result, you will get faster and reliable performance - free from latency-spikes.
Our New Storage Architecture
There are four elements: the Data Layer, Mask Layer, the Region and Tracker Layer.
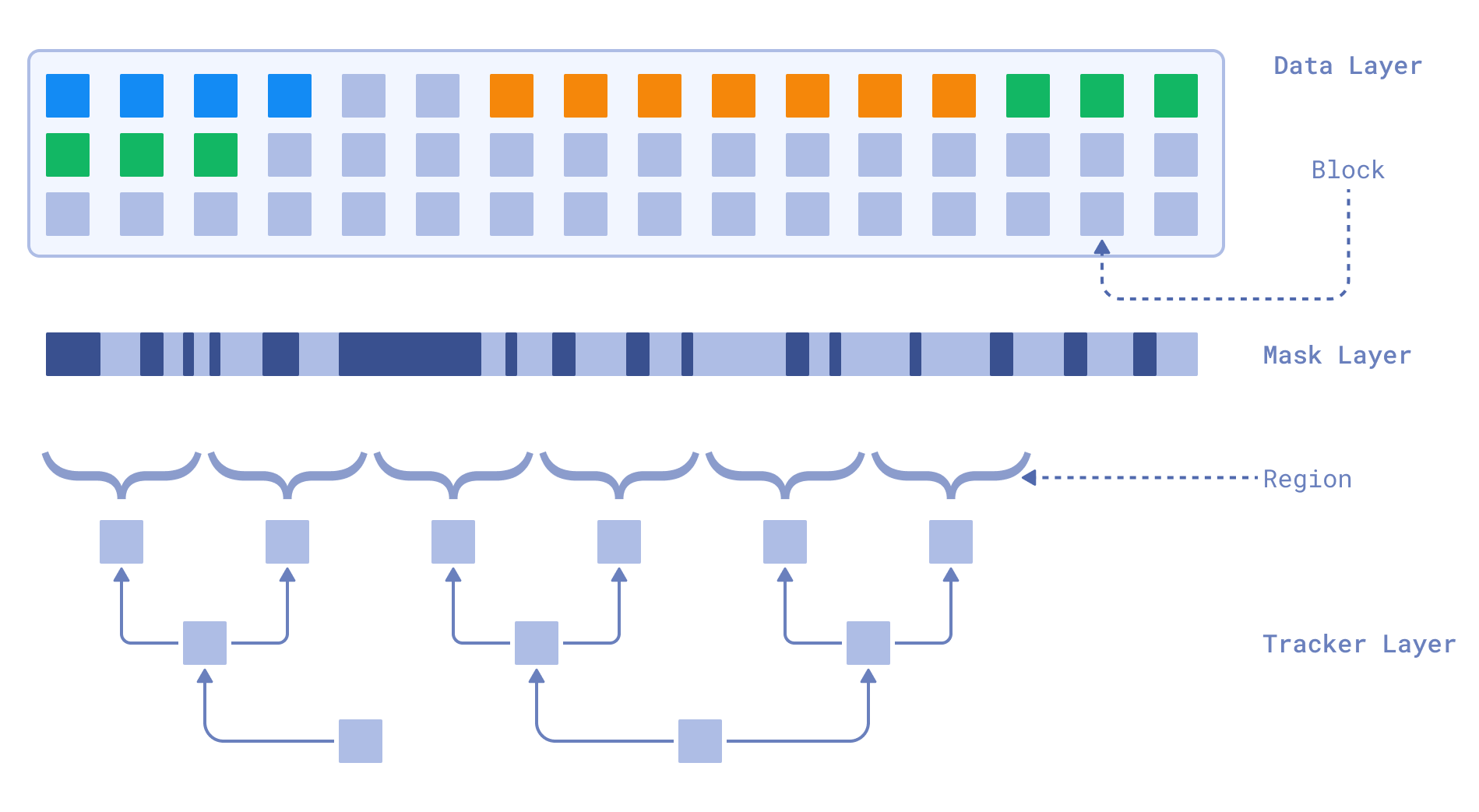
Qdrant’s New Storage Backend
The Data Layer consists of fixed-size blocks that store the actual data. The block size is a configurable parameter that can be adjusted based on the workload. Each record occupies the required number of blocks. If the data size exceeds the block size, it is split into multiple blocks. If the data size is smaller than the block size, it still occupies an entire block.
The Mask Layer contains a bitmask that indicates which blocks are occupied and which are free. The size of the mask corresponds to the number of blocks in the Data Layer. For instance, if we have 64 blocks of 128 bytes each, the bitmask will allocate 1 bit for every block in the Data Layer resulting in 8 bytes. This results in an overhead of 1/1024 of the Data Layer size, because each byte in the mask covers 1024 bytes of blocked storage. The bitmask is stored on disk and does not need to be loaded into memory.
The Region is an additional structure which tracks gaps in regions of the bitmask. This is to get an even smaller overhead against the data, which can be loaded into memory easily. Each region summarizes 1KB of bits in the bitmask, which represents a millionth scale of the Data Layer size, or 6 KB of RAM per GB of data.
The Tracker Layer is in charge of fast lookups, it directly links the IDs of the points to the place where the data is located.
Get Started with Qdrant

The easiest way to reach that Hello World moment is to try vector search in a live cluster. Our interactive tutorial will show you how to create a cluster, add data and try some filtering clauses.
New features, like named vector filtering, can be tested in the Qdrant Dashboard: