
























Qdrant 1.14 - Reranking Support & Extensive Resource Optimizations
David Myriel
·April 22, 2025

On this page:
Qdrant 1.14.0 is out! Let’s look at the main features for this version:
Score-Boosting Reranker: Blend vector similarity with custom rules and context.
Improved Resource Utilization: CPU and disk IO optimization for faster processing.
Incremental HNSW Indexing: Build indexes gradually as data arrives.
Batch Search: Optimized parallel processing for batch queries.
Memory Optimization: Reduced usage for large datasets with improved ID tracking.
Score-Boosting Reranker

When integrating vector search into specific applications, you can now tweak the final result list using domain or business logic. For example, if you are building a chatbot or search on website content, you can rank results with title metadata higher than body_text in your results.
In e-commerce you may want to boost products from a specific manufacturer—perhaps because you have a promotion or need to clear inventory. With this update, you can easily influence ranking using metadata like brand or stock_status.
The Score-Boosting Reranker allows you to combine vector-based similarity with business or domain-specific logic by applying a rescoring step on top of the standard semantic or distance-based ranking.
As you structure the query, you can define a formula that references both existing scores (like cosine similarities) and additional payload data (e.g., timestamps, location info, numeric attributes). Let’s take a look at some examples:
Idea 1: Prioritizing Website Content
Let’s say you are trying to improve the search feature for a documentation site, such as our Developer Portal. You would chunk and vectorize all your documentation and store it in a Qdrant collection.
Figure 1: Any time someone types in hybrid queries, you want to show them the most relevant result at the top.
Reranking can help you prioritize the best results based on user intent.
Your website collection can have vectors for titles, paragraphs, and code snippet sections of your documentation. You can create a tag payload field that indicates whether a point is a title, paragraph, or snippet. Then, to give more weight to titles and paragraphs, you might do something like:
score = score + (is_title * 0.5) + (is_paragraph * 0.25)
Above is just sample logic - but here is the actual Qdrant API request:
POST /collections/{collection_name}/points/query
{
"prefetch": {
"query": [0.2, 0.8, ...], // <-- dense vector for the query
"limit": 50
},
"query": {
"formula": {
"sum": [
"$score", // Semantic score
{
"mult": [
0.5, // weight for title
{ // Filter for title
"key": "tag",
"match": { "any": ["h1","h2","h3","h4"] }
}
]
},
{
"mult": [
0.25, // weight for paragraph
{ // Filter for paragraph
"key": "tag",
"match": { "any": ["p","li"] }
}
]
}
]
}
}
}
Idea 2: Reranking Most Recent Results
One of the most important advancements is the ability to prioritize recency. In many scenarios, such as in news or job listings, users want to see the most recent results first. Until now, this wasn’t possible without additional work: you had to fetch all the data and manually filter for the latest entries on your side.
Now, the similarity score doesn’t have to rely solely on cosine distance. It can also take into account how recent the data is, allowing for much more dynamic and context-aware ranking.
With the Score-Boosting Reranker, simply add a
datetimepayload field and factor it into your formula so fresher data rises to the top.
Example Query:
POST /collections/{collection_name}/points/query
{
"prefetch": { ... },
"query": {
"formula": {
"sum": [
"$score",
{
"gauss_decay":
"target": { "datetime": <todays date> },
"x": { "datetime_key": <payload key> },
"scale": <1 week in seconds>
}
]
}
}
}
Idea 3: Factor in Geographical Proximity
Let’s say you’re searching for a restaurant serving Currywurst. Sure, Berlin has some of the best, but you probably don’t want to spend two days traveling for a sausage covered in magical seasoning. The best match is the one that balances the distance in the vector space with a real-world geographical distance. You want your users see relevant and conveniently located options.
This feature introduces a multi-objective optimization: combining semantic similarity with geographical proximity. Suppose each point has a geo.location payload field (latitude, longitude). You can use a gauss_decay function to clamp the distance into a 0–1 range and add that to your similarity score:
score = $score + gauss_decay(distance)
Example Query:
POST /collections/{collection_name}/points/query
{
"prefetch": {
"query": [0.2, 0.8, ...],
"limit": 50
},
"query": {
"formula": {
"sum": [
"$score",
{
"gauss_decay": {
"scale": 5000, // e.g. 5 km
"x": {
"geo_distance": {
"origin": { // Berlin
"lat": 52.504043,
"lon": 13.393236
},
"to": "geo.location"
}
}
}
}
]
},
"defaults": {
"geo.location": { // Munich
"lat": 48.137154,
"lon": 11.576124
}
}
}
}
You can tweak parameters like target, scale, and midpoint to shape how quickly the score decays over distance. This is extremely useful for local search scenarios, where location is a major factor but not the only factor.
This is a very powerful feature that allows for extensive customization. Read more about this feature in the Hybrid Queries Documentation
Incremental HNSW Indexing

Rebuilding an entire HNSW graph every time new data is added can be computationally expensive. With this release, Qdrant now supports incremental HNSW indexing—an approach that extends existing HNSW graphs rather than recreating them from scratch.
This feature is designed to make indexing faster and more efficient when you’re only adding new points. It reuses the existing structure of the HNSW graph and appends the new data directly onto it.
That means much less time spent building and more time searching. Although this initial implementation currently only support upserts, it lays the groundwork for a more dynamic and performance-friendly indexing process. Especially for collections with frequent updates to payload values or growing datasets, incremental HNSW is a big step forward.
Note that deletes and updates will still trigger a full rebuild. Check out the indexing documentation to learn more.
Faster Batch Queries

In this release, Qdrant introduces a major performance boost for batch query operations. Until now, the query batch API used a single thread per segment, which worked well—unless you had just one segment and a large batch of queries in a single request. In such cases, everything was processed on a single thread, significantly slowing things down. This scenario was especially common when using our Python client, which is single-threaded by default.
The new optimization changes that. Large query batches are now split into chunks, and each chunk is processed on a separate thread.
This allows Qdrant to execute queries concurrently, even when operating over a single segment with a limited number of requests.
You will get much faster response times for large batches of queries. If you’re working with high-volume query workloads, you should notice a significant improvement in latency. Benchmark results show just how dramatic the difference can be.
As a basic test, we populated a 1-segment collection using our bfb benchmarking tool, and ran a request of 240 batch queries.
Initially, this process only saturated a single CPU and took 11 seconds:

After, it saturated 23 CPUs (search threads = CPU count - 1) and took 4.5 seconds:

We ran the same test of large queries for the following configurations:
| Configuration | Segments | Shards | Indexing Threshold | Before | After | Improvement |
|---|---|---|---|---|---|---|
| Single Segment | 1 | 1 | 20k | 10.5s | 4.5s | 57% |
| Multi Segment | 10 | 1 | 20k | 5.5s | 5.1s | 7% |
| Single Segment, Multi Shard | 1 | 4 | 20k | 5.2s | 4.6s | 12% |
| Multi Everything | 10 | 4 | 1k | 5.1s | 4.5s | 12% |
| High Shard, Single Segment | 1 | 16 | 1k | 5.2s | 3.7s | 29% |
| High Shard, Multi Segment | 10 | 16 | 1k | 2.5s | 1.7s | 32% |
As you can see, the improvement is most significant (57%) in single-segment configurations where parallelization was previously limited. Even in already-optimized multi-shard setups, we still see good gains of 12-32%.
For more on batch queries, check out the Search documentation.
Improved Resource Use During Segment Optimization

Qdrant now saturates CPU and disk IO more effectively in parallel when optimizing segments. This helps reduce the “sawtooth” usage pattern—where CPU or disk often sat idle while waiting on the other resource.
This leads to faster optimizations, which are specially noticeable on large machines handling big data movement. It also gives you predictable performance, as there are fewer sudden spikes or slowdowns during indexing and merging operations.
Figure 2: Indexing 400 million vectors - CPU and disk usage profiles. Previous Qdrant version on the left, new Qdrant version on the right.
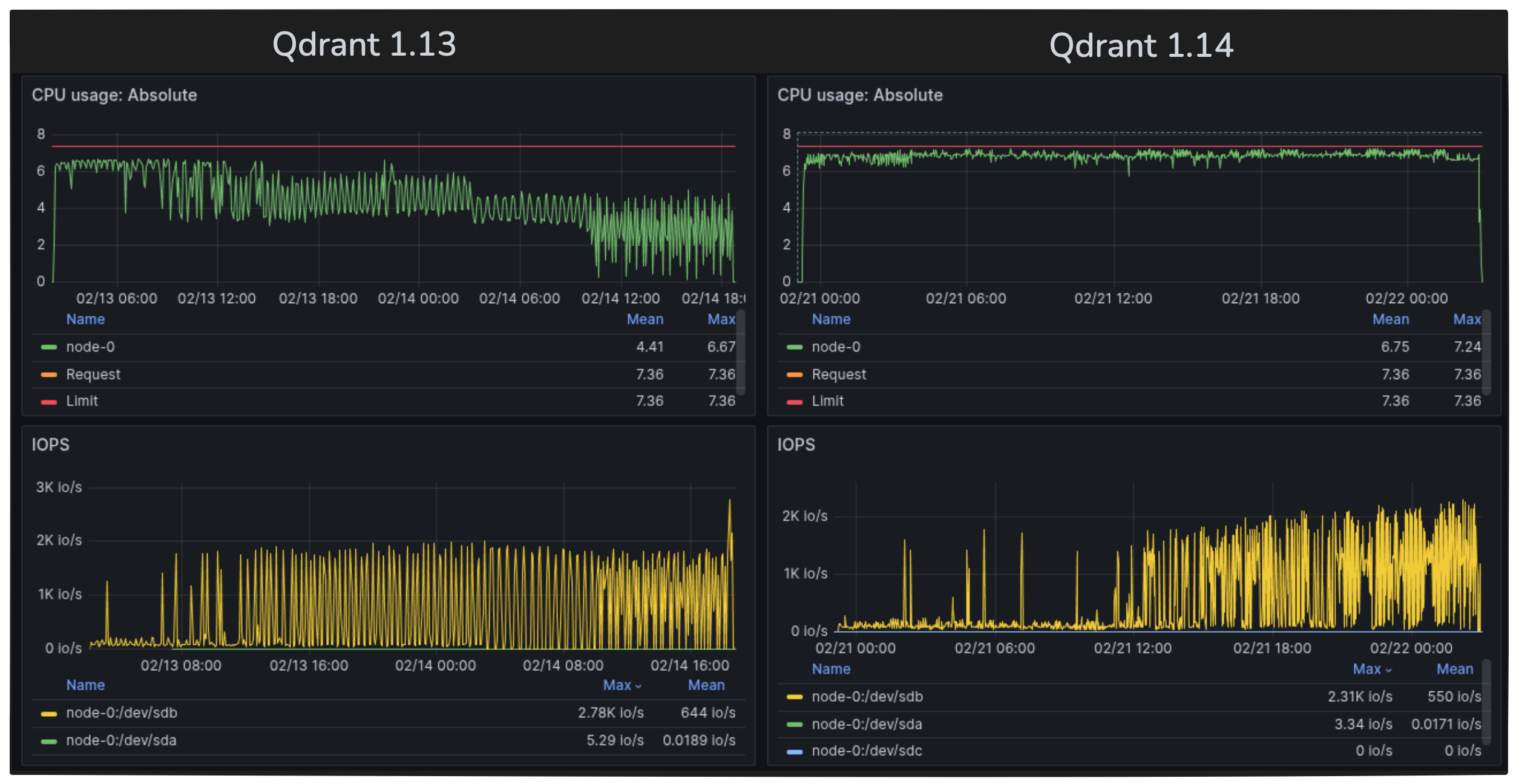
Observed Results: The new version on the right clearly shows much better CPU saturation across the full process. The improvement is especially noticeable during large-scale indexing.
In our experiment, we indexed 400 million 512-dimensional vectors. The previous version of Qdrant took around 40 hours on an 8-core machine, while the new version with this change completed the task in just 28 hours.
Tutorial: If you want to work with a large number of vectors, we can show you how. Learn how to upload and search large collections efficiently.
Optimized Memory Usage in Immutable Segments

We revamped how the ID tracker and related metadata structures store data in memory. This can result in a notable RAM reduction for very large datasets (hundreds of millions of vectors).
This causes much lower overhead, where memory savings let you store more vectors on the same hardware. Also, improved scalability is a major benefit. If your workload was near the RAM limit, this might let you push further without using additional servers.
Upgrading to Version 1.14
With Qdrant 1.14, all client libraries remain fully compatible. If you do not need custom payload-based ranking, your existing workflows remain unchanged.
Upgrading from earlier versions is straightforward — no major API or index-breaking changes.
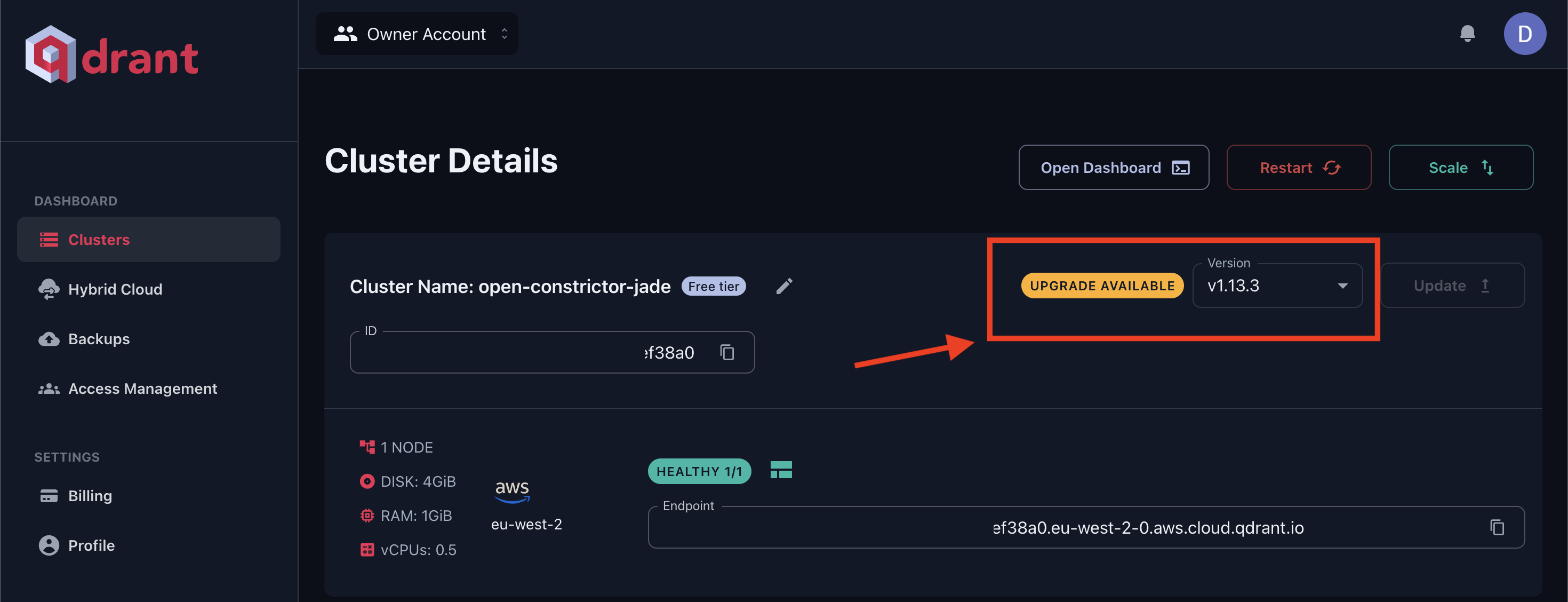
In Qdrant Cloud, simply go to your Cluster Details screen and select Version 1.14 from the dropdown. The upgrade may take a few moments.
Figure 3: Updating to the latest software version from Qdrant Cloud dashboard.
Documentation: For a full list of formula expressions, conditions, decay functions, and usage examples, see the official Qdrant documentation and the API reference. This includes detailed code snippets for popular languages and a variety of advanced reranking examples.
Watch the Features in Action!
Want to see these updates working in a real-world setup?
In our latest Qdrant Office Hours, we demoed the new Score-Boosting Reranker, walked through Incremental HNSW Indexing, and tested the impact of the new multi-threaded batch queries.
Watch the full recording here:
Join the Discussion!
We’d love to hear your feedback: If you have questions or want to share your experience, join our Discord or open an issue on GitHub.

