































Qdrant Updated Benchmarks 2024
Sabrina Aquino
·January 15, 2024

On this page:
It’s time for an update to Qdrant’s benchmarks!
We’ve compared how Qdrant performs against the other vector search engines to give you a thorough performance analysis. Let’s get into what’s new and what remains the same in our approach.
What’s Changed?
All engines have improved
Since the last time we ran our benchmarks, we received a bunch of suggestions on how to run other engines more efficiently, and we applied them.
This has resulted in significant improvements across all engines. As a result, we have achieved an impressive improvement of nearly four times in certain cases. You can view the previous benchmark results here.
Introducing a New Dataset
To ensure our benchmark aligns with the requirements of serving RAG applications at scale, the current most common use-case of vector databases, we have introduced a new dataset consisting of 1 million OpenAI embeddings.
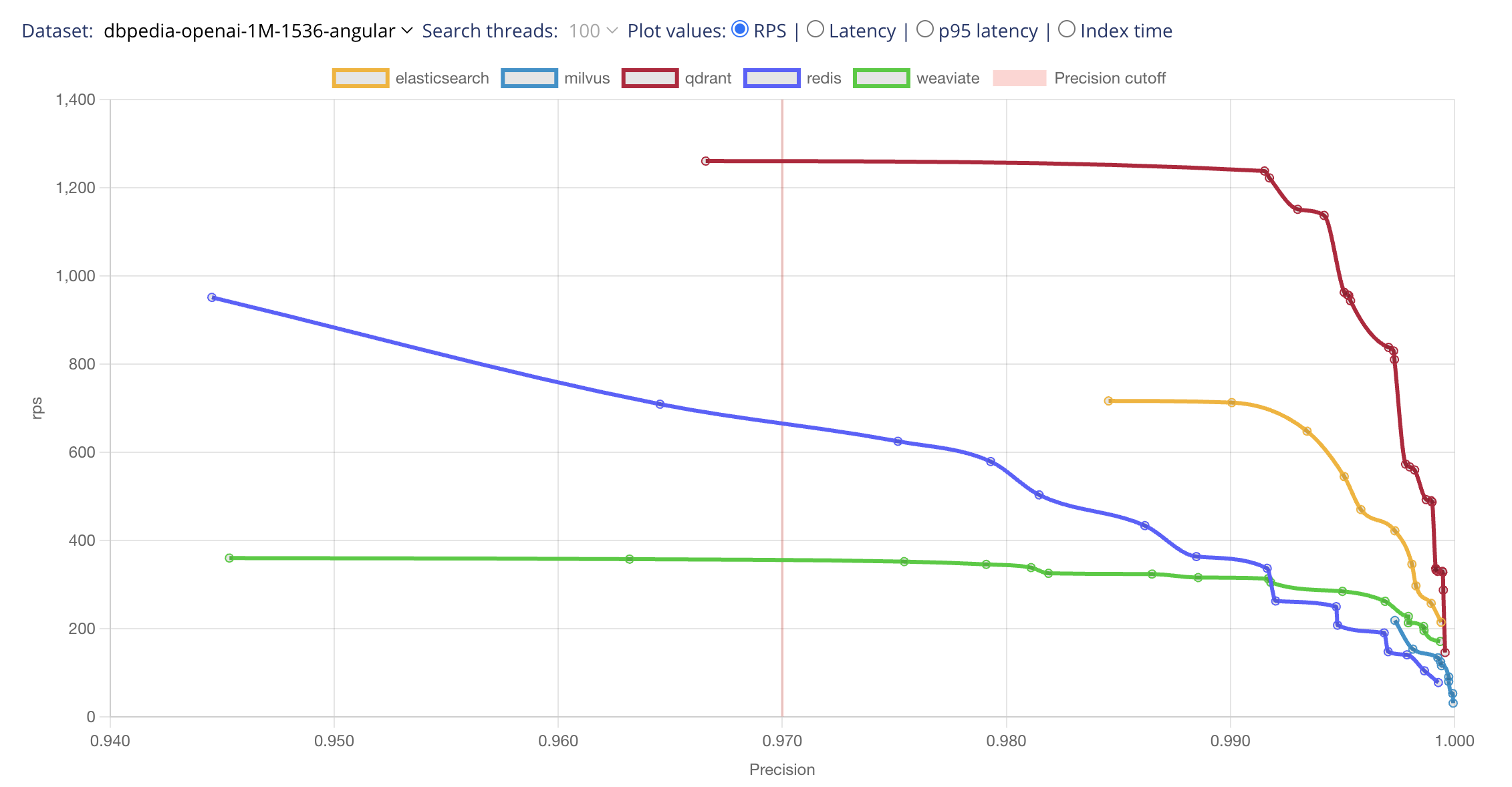
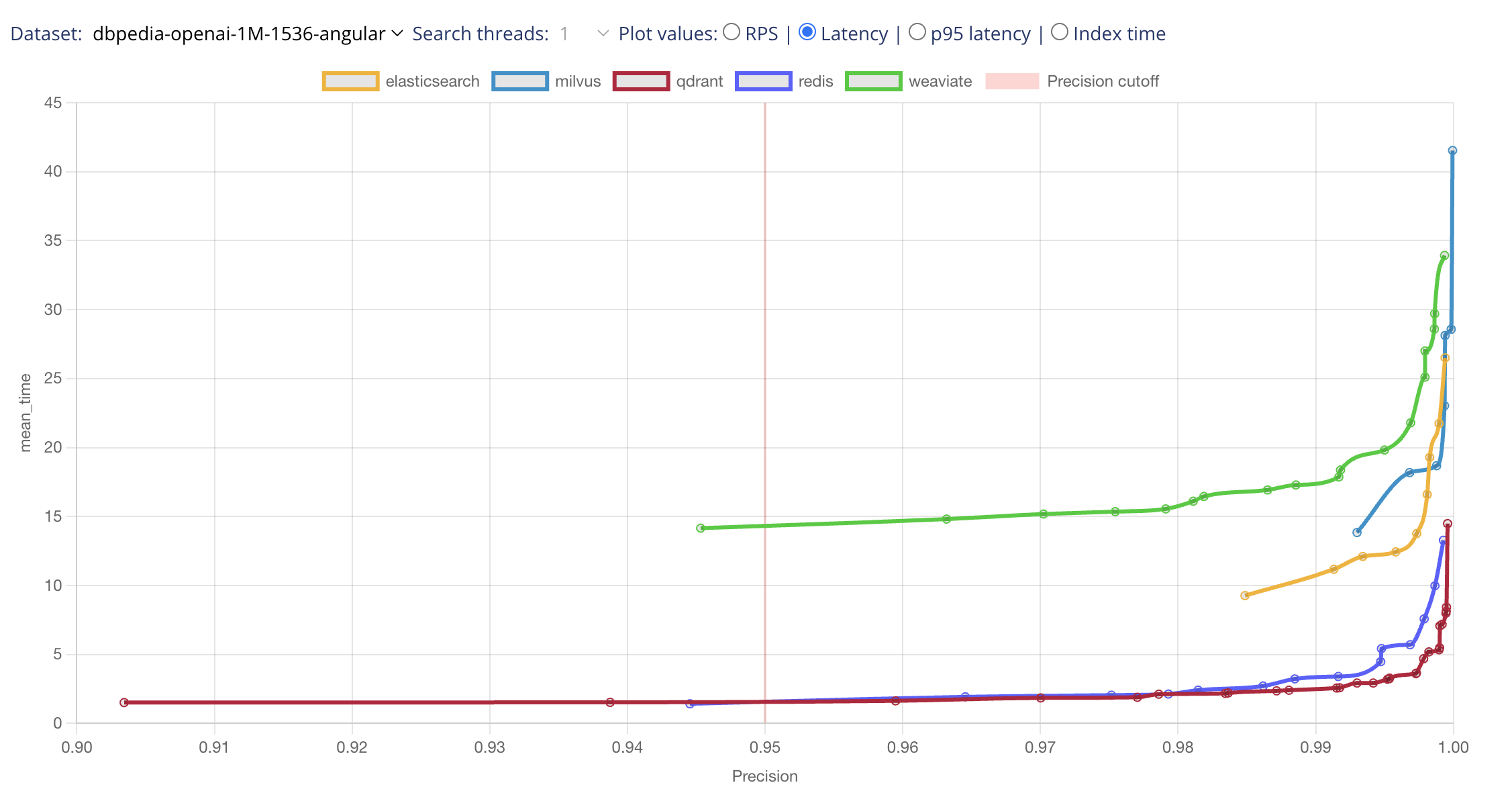
Separation of Latency vs RPS Cases
Different applications have distinct requirements when it comes to performance. To address this, we have made a clear separation between latency and requests-per-second (RPS) cases.
For example, a self-driving car’s object recognition system aims to process requests as quickly as possible, while a web server focuses on serving multiple clients simultaneously. By simulating both scenarios and allowing configurations for 1 or 100 parallel readers, our benchmark provides a more accurate evaluation of search engine performance.
What Hasn’t Changed?
Our Principles of Benchmarking
At Qdrant all code stays open-source. We ensure our benchmarks are accessible for everyone, allowing you to run them on your own hardware. Your input matters to us, and contributions and sharing of best practices are welcome!
Our benchmarks are strictly limited to open-source solutions, ensuring hardware parity and avoiding biases from external cloud components.
We deliberately don’t include libraries or algorithm implementations in our comparisons because our focus is squarely on vector databases.
Why?
Because libraries like FAISS, while useful for experiments, don’t fully address the complexities of real-world production environments. They lack features like real-time updates, CRUD operations, high availability, scalability, and concurrent access – essentials in production scenarios. A vector search engine is not only its indexing algorithm, but its overall performance in production.
We use the same benchmark datasets as the ann-benchmarks project so you can compare our performance and accuracy against it.
Detailed Report and Access
For an in-depth look at our latest benchmark results, we invite you to read the detailed report.
If you’re interested in testing the benchmark yourself or want to contribute to its development, head over to our benchmark repository. We appreciate your support and involvement in improving the performance of vector databases.
