Migrate to a New Embedding Model with Zero Downtime in Qdrant
| Time: 40 min | Level: Intermediate |
|---|
When building a semantic search application, you need to choose an embedding model. Over time, you may want to switch to a different model for better quality or cost-effectiveness. If your application is in production, this must be done with zero downtime to avoid disrupting users. Switching models requires re-embedding all vectors in your collection, which can take time. If your data doesn’t change, you can re-embed everything and switch to the new embeddings. However, in systems with frequent updates, stopping the search service to re-embed is not an option.
This tutorial will guide you step-by-step through the process of migrating to a new model, including the changes you have to make in your project. The examples all use the Python SDK, but the same principles apply to other languages as well.
The Solution
Switching the embedding model with zero downtime is possible by using a blue-green deployment with two collections. The first collection contains the old embeddings, and the second one is used to store the new embeddings. A migration process copies the data from the old collection to the new one, re-embedding vectors using the new model. During the migration, you keep searching the old collection while writing any data updates to both collections. Once all vectors are re-embedded, switch the search to use the new collection.
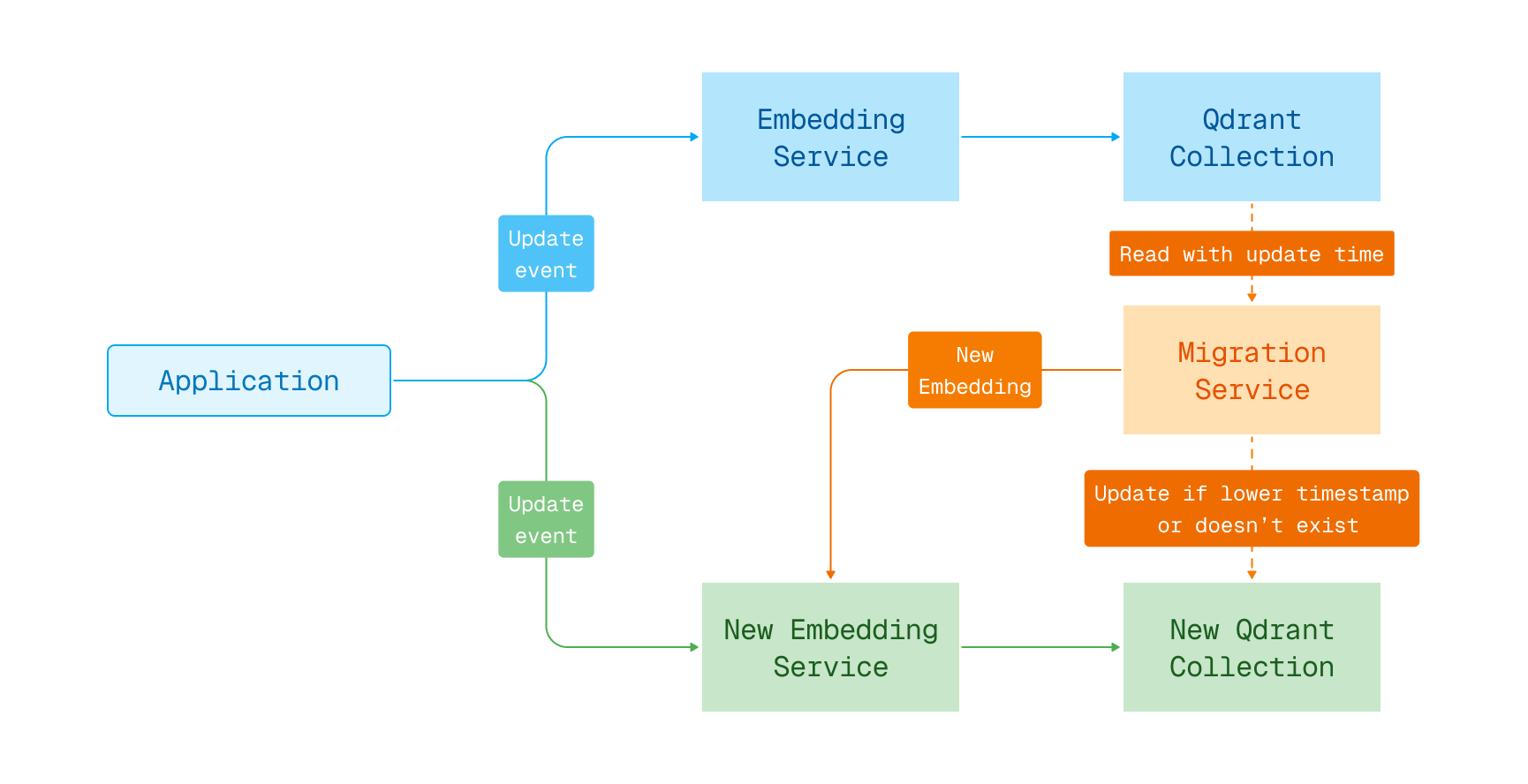
Embedding model migration in blue-green deployment
Re-embedding requires access to the original data used to create the embeddings. This data can come from a primary database, or it may be stored in the payloads of the points in Qdrant. This tutorial assumes that the necessary data is stored in the payloads. This is usually the case, as the payload often contains the text or other data that was used to generate the embeddings.
The solution outlined in this tutorial only works for upsert operations. If you use deletes or partial updates, it is necessary to pause those operations during the migration or implement additional logic to handle them.
This tutorial assumes you use Qdrant Cloud Inference to generate vector embeddings. If you manage your own embedding infrastructure, you can apply the same principles, but you will need to adapt the code examples to use your embedding service.
Step 1: Create a New Collection
The first step is to create a new collection in Qdrant that will be used to store the new embeddings, compatible with the new model in terms of vector size and similarity function.
client.create_collection(
collection_name=NEW_COLLECTION,
vectors_config=(
models.VectorParams(
size=512, # Size of the new embedding vectors
distance=models.Distance.COSINE # Similarity function for the new model
)
)
)
await client.createCollection(NEW_COLLECTION, {
vectors: {
size: 512, // Size of the new embedding vectors
distance: "Cosine", // Similarity function for the new model
},
});
client
.create_collection(
CreateCollectionBuilder::new(new_collection)
.vectors_config(VectorParamsBuilder::new(512, Distance::Cosine)), // Size of the new embedding vectors
)
.await?;
client.createCollectionAsync(NEW_COLLECTION,
VectorParams.newBuilder()
.setSize(512) // Size of the new embedding vectors
.setDistance(Distance.Cosine) // Similarity function for the new model
.build()).get();
await client.CreateCollectionAsync(
collectionName: NEW_COLLECTION,
vectorsConfig: new VectorParams { Size = 512, Distance = Distance.Cosine }
);
client.CreateCollection(context.Background(), &qdrant.CreateCollection{
CollectionName: NEW_COLLECTION,
VectorsConfig: qdrant.NewVectorsConfig(&qdrant.VectorParams{
Size: 512, // Size of the new embedding vectors
Distance: qdrant.Distance_Cosine,
}),
})
Now is also a good moment to consider changing any other settings for the collection, like custom sharding, replication factor, etc. Switching the model may be a good opportunity to improve the performance of your search.
The newly created collection is empty and ready to be used for storing the new embeddings.
Step 2: Enable Dual Writes
To ensure that both collections are kept up-to-date during the migration, you need to write any changes to both collections simultaneously. This way, any new data or updates to existing data are reflected in both collections.
Ideally, the data in Qdrant is updated by an update service reading from an update queue. This service is responsible for embedding the documents and writing them to Qdrant. It uses code similar to this:
client.upsert(
collection_name=OLD_COLLECTION,
points=[
models.PointStruct(
id=1,
vector=models.Document(
text="Example document",
model=OLD_MODEL,
),
payload={"text": "Example document"}
)
]
)
await client.upsert(OLD_COLLECTION, {
points: [
{
id: 1,
vector: {
text: "Example document",
model: OLD_MODEL,
},
payload: { text: "Example document" },
},
],
});
client
.upsert_points(UpsertPointsBuilder::new(
old_collection,
vec![PointStruct::new(
1,
Document::new("Example document", old_model),
[("text", "Example document".into())],
)],
))
.await?;
client.upsertAsync(OLD_COLLECTION, List.of(
PointStruct.newBuilder()
.setId(id(1))
.setVectors(
vectors(
vector(
Document.newBuilder()
.setText("Example document")
.setModel(OLD_MODEL)
.build())))
.putAllPayload(Map.of("text", value("Example document")))
.build())).get();
await client.UpsertAsync(
collectionName: OLD_COLLECTION,
points: new List<PointStruct>
{
new()
{
Id = 1,
Vectors = new Document
{
Text = "Example document",
Model = OLD_MODEL
},
Payload = { ["text"] = "Example document" }
}
}
);
client.Upsert(context.Background(), &qdrant.UpsertPoints{
CollectionName: OLD_COLLECTION,
Points: []*qdrant.PointStruct{
{
Id: qdrant.NewIDNum(1),
Vectors: qdrant.NewVectorsDocument(&qdrant.Document{
Text: "Example document",
Model: OLD_MODEL,
}),
Payload: qdrant.NewValueMap(map[string]any{"text": "Example document"}),
},
},
})
To update the new collection, deploy a second service that updates the new collection in parallel with the existing one. This service uses the new embedding model to encode the documents and writes them to the new collection:
client.upsert(
collection_name=NEW_COLLECTION,
points=[
models.PointStruct(
id=1,
# Use the new embedding model to encode the document
vector=models.Document(
text="Example document",
model=NEW_MODEL,
),
payload={"text": "Example document"}
)
]
)
await client.upsert(NEW_COLLECTION, {
points: [
{
id: 1,
// Use the new embedding model to encode the document
vector: {
text: "Example document",
model: NEW_MODEL,
},
payload: { text: "Example document" },
},
],
});
client
.upsert_points(UpsertPointsBuilder::new(
new_collection,
vec![PointStruct::new(
1,
// Use the new embedding model to encode the document
Document::new("Example document", new_model),
[("text", "Example document".into())],
)],
))
.await?;
client.upsertAsync(NEW_COLLECTION, List.of(
PointStruct.newBuilder()
.setId(id(1))
// Use the new embedding model to encode the document
.setVectors(
vectors(
vector(
Document.newBuilder()
.setText("Example document")
.setModel(NEW_MODEL)
.build())))
.putAllPayload(Map.of("text", value("Example document")))
.build())).get();
await client.UpsertAsync(
collectionName: NEW_COLLECTION,
points: new List<PointStruct>
{
new()
{
Id = 1,
// Use the new embedding model to encode the document
Vectors = new Document
{
Text = "Example document",
Model = NEW_MODEL
},
Payload = { ["text"] = "Example document" }
}
}
);
client.Upsert(context.Background(), &qdrant.UpsertPoints{
CollectionName: NEW_COLLECTION,
Points: []*qdrant.PointStruct{
{
Id: qdrant.NewIDNum(1),
// Use the new embedding model to encode the document
Vectors: qdrant.NewVectorsDocument(&qdrant.Document{
Text: "Example document",
Model: NEW_MODEL,
}),
Payload: qdrant.NewValueMap(map[string]any{"text": "Example document"}),
},
},
})
A good practice is to always ensure that both operations succeed. Any errors need to be handled on the client side. You could store errors in a log or “dead letter queue” for later processing. Transient errors can be retried at a later time. Other errors need to be analyzed and addressed accordingly.
If instead of update services, you have a monolithic application, you need to modify your application code to write to both collections simultaneously during the transition period. In your code, where you handle the embedding of the documents, you should add the logic to write to both collections.
Note that the method outlined in this tutorial only works for upsert operations. For example, a delete operation would fail on the new collection if a point does not exist yet, and that point would later be erroneously added by the migration process. If you use one of the following methods to modify points in your collection, you will need to pause those operations during the migration or implement additional logic to handle them:
.delete- removing specified points from the collection.update_vectors- updating specified vectors on points.delete_vectors- deleting specified vectors from points.set_payload- setting payload values for specified points.overwrite_payload- overwriting the entire payload of a specified point with a new payload.delete_payload- deleting a specified key payload for points.clear_payload- removing the entire payload for specified points.batch_update_points- making batch updates to points, including their respective vectors and payloads
Please refer to the documentation of the SDK you are using, or the HTTP/gRPC definitions, for the exact method names, as they may vary between languages.
After making these changes, you will be in a dual-write mode, where any change is written to both the old and new collection. This allows you to keep both collections up-to-date during the migration process.
Step 3: Migrate the Existing Points into the New Collection
Now that you’re in dual-write mode, it is time to migrate the existing points from the old collection to the new one. This can be done in a separate process that runs in parallel with the regular upsert services.
The migration process reads the points from the old collection, re-embeds them using the new model, and writes them to the new collection, making sure not to overwrite existing points inserted by the update service. Here’s an example of what the code for such a migration process could look like:
last_offset = None
batch_size = 100 # Number of points to read in each batch
reached_end = False
while not reached_end:
# Get the next batch of points from the old collection
records, last_offset = client.scroll(
collection_name=OLD_COLLECTION,
limit=batch_size,
offset=last_offset,
# Include payloads in the response, as we need them to re-embed the vectors
with_payload=True,
# We don't need the old vectors, so let's save on the bandwidth
with_vectors=False,
)
# Re-embed the points using the new model
points = [
models.PointStruct(
# Keep the original ID to ensure consistency
id=record.id,
# Use the new embedding model to encode the text from the payload,
# assuming that was the original source of the embedding
vector=models.Document(
text=(record.payload or {}).get("text", ""),
model=NEW_MODEL,
),
# Keep the original payload
payload=record.payload
)
for record in records
]
# Upsert the re-embedded points into the new collection
client.upsert(
collection_name=NEW_COLLECTION,
points=points,
# Only insert the point if a point with this ID does not already exist.
update_mode=models.UpdateMode.INSERT_ONLY
)
# Check if we reached the end of the collection
reached_end = (last_offset == None)
let lastOffset: number | string | undefined = undefined;
const batchSize = 100; // Number of points to read in each batch
let reachedEnd = false;
while (!reachedEnd) {
// Get the next batch of points from the old collection
const scrollResult = await client.scroll(OLD_COLLECTION, {
limit: batchSize,
offset: lastOffset,
// Include payloads in the response, as we need them to re-embed the vectors
with_payload: true,
// We don't need the old vectors, so let's save on the bandwidth
with_vector: false,
});
const records = scrollResult.points;
lastOffset = scrollResult.next_page_offset as number | string | undefined;
// Re-embed the points using the new model
const points = records.map((record) => ({
// Keep the original ID to ensure consistency
id: record.id,
// Use the new embedding model to encode the text from the payload,
// assuming that was the original source of the embedding
vector: {
text: ((record.payload?.text as string) ?? ""),
model: NEW_MODEL,
},
// Keep the original payload
payload: record.payload,
}));
// Upsert the re-embedded points into the new collection
await client.upsert(NEW_COLLECTION, {
points,
// Only insert the point if a point with this ID does not already exist.
update_mode: "insert_only" as const,
});
// Check if we reached the end of the collection
reachedEnd = lastOffset == null;
}
let mut last_offset = None;
let batch_size = 100; // Number of points to read in each batch
loop {
// Get the next batch of points from the old collection
let mut scroll_builder = ScrollPointsBuilder::new(old_collection)
.limit(batch_size)
// Include payloads in the response, as we need them to re-embed the vectors
.with_payload(true)
// We don't need the old vectors, so let's save on the bandwidth
.with_vectors(false);
if let Some(offset) = last_offset {
scroll_builder = scroll_builder.offset(offset);
}
let scroll_result = client.scroll(scroll_builder).await?;
let records = scroll_result.result;
last_offset = scroll_result.next_page_offset;
// Re-embed the points using the new model
let points: Vec<PointStruct> = records
.iter()
.map(|record| {
PointStruct::new(
// Keep the original ID to ensure consistency
record.id.clone().unwrap(),
// Use the new embedding model to encode the text from the payload,
// assuming that was the original source of the embedding
Document::new(
record.payload.get("text")
.and_then(|v| v.as_str())
.map_or("", |v| v),
new_model,
),
// Keep the original payload
record.payload.clone(),
)
})
.collect();
// Upsert the re-embedded points into the new collection
client
.upsert_points(
// Only insert the point if a point with this ID does not already exist.
UpsertPointsBuilder::new(new_collection, points)
.update_mode(UpdateMode::InsertOnly),
)
.await?;
// Check if we reached the end of the collection
if last_offset.is_none() {
break;
}
}
int batchSize = 100; // Number of points to read in each batch
boolean reachedEnd = false;
// Get the next batch of points from the old collection
var scrollBuilder = ScrollPoints.newBuilder()
.setCollectionName(OLD_COLLECTION)
.setLimit(batchSize)
// Include payloads in the response, as we need them to re-embed the vectors
.setWithPayload(WithPayloadSelectorFactory.enable(true))
// We don't need the old vectors, so let's save on the bandwidth
.setWithVectors(WithVectorsSelectorFactory.enable(false));
while (!reachedEnd) {
var scrollResult = client.scrollAsync(scrollBuilder.build()).get();
var records = scrollResult.getResultList();
// Re-embed the points using the new model
List<PointStruct> points = new ArrayList<>();
for (var record : records) {
String text = record.getPayloadMap().containsKey("text")
? record.getPayloadMap().get("text").getStringValue()
: "";
points.add(
PointStruct.newBuilder()
// Keep the original ID to ensure consistency
.setId(record.getId())
// Use the new embedding model to encode the text from the payload,
// assuming that was the original source of the embedding
.setVectors(
vectors(
vector(
Document.newBuilder()
.setText(text)
.setModel(NEW_MODEL)
.build())))
// Keep the original payload
.putAllPayload(record.getPayloadMap())
.build());
}
// Upsert the re-embedded points into the new collection
client.upsertAsync(
UpsertPoints.newBuilder()
.setCollectionName(NEW_COLLECTION)
.addAllPoints(points)
// Only insert the point if a point with this ID does not already exist.
.setUpdateMode(UpdateMode.InsertOnly)
.build()).get();
// Check if we reached the end of the collection
if (scrollResult.hasNextPageOffset()) {
scrollBuilder.setOffset(scrollResult.getNextPageOffset());
} else {
reachedEnd = true;
}
}
PointId? lastOffset = null;
uint limit = 100; // Number of points to read in each batch
bool reachedEnd = false;
while (!reachedEnd)
{
// Get the next batch of points from the old collection
var scrollResult = await client.ScrollAsync(
collectionName: OLD_COLLECTION,
limit: limit,
offset: lastOffset,
// Include payloads in the response, as we need them to re-embed the vectors
payloadSelector: true,
// We don't need the old vectors, so let's save on the bandwidth
vectorsSelector: false
);
var records = scrollResult.Result;
lastOffset = scrollResult.NextPageOffset;
// Re-embed the points using the new model
var points = new List<PointStruct>();
foreach (var record in records)
{
var text = record.Payload.ContainsKey("text")
? record.Payload["text"].StringValue
: "";
points.Add(new PointStruct
{
// Keep the original ID to ensure consistency
Id = record.Id,
// Use the new embedding model to encode the text from the payload,
// assuming that was the original source of the embedding
Vectors = new Document
{
Text = text,
Model = NEW_MODEL
},
// Keep the original payload
Payload = { record.Payload }
});
}
// Upsert the re-embedded points into the new collection
await client.UpsertAsync(
new()
{
CollectionName = NEW_COLLECTION,
Points = { points },
// Only insert the point if a point with this ID does not already exist.
UpdateMode = UpdateMode.InsertOnly
}
);
// Check if we reached the end of the collection
reachedEnd = (lastOffset == null);
}
var lastOffset *qdrant.PointId
batchSize := uint32(100) // Number of points to read in each batch
reachedEnd := false
for !reachedEnd {
// Get the next batch of points from the old collection
scrollResult, err := client.Scroll(context.Background(), &qdrant.ScrollPoints{
CollectionName: OLD_COLLECTION,
Limit: qdrant.PtrOf(batchSize),
Offset: lastOffset,
// Include payloads in the response, as we need them to re-embed the vectors
WithPayload: qdrant.NewWithPayload(true),
// We don't need the old vectors, so let's save on the bandwidth
WithVectors: qdrant.NewWithVectors(false),
})
records := scrollResult
// Re-embed the points using the new model
points := make([]*qdrant.PointStruct, len(records))
for idx, record := range records {
text := ""
if val, ok := record.Payload["text"]; ok {
text = val.GetStringValue()
}
points[idx] = &qdrant.PointStruct{
// Keep the original ID to ensure consistency
Id: record.Id,
// Use the new embedding model to encode the text from the payload,
// assuming that was the original source of the embedding
Vectors: qdrant.NewVectorsDocument(&qdrant.Document{
Text: text,
Model: NEW_MODEL,
}),
// Keep the original payload
Payload: record.Payload,
}
}
// Upsert the re-embedded points into the new collection
client.Upsert(context.Background(), &qdrant.UpsertPoints{
CollectionName: NEW_COLLECTION,
Points: points,
// Only insert the point if a point with this ID does not already exist.
UpdateMode: qdrant.UpdateMode_InsertOnly.Enum(),
})
// Check if we reached the end of the collection
reachedEnd = (lastOffset == nil)
}
Breaking down this code step by step:
- Data is read from the old collection in batches of 100 points using a scroll. The
last_offsetvariable keeps track of the scroll position in the collection. - For each batch of points, the process re-embeds the vectors using the new embedding model. It assumes that the original text used for embedding is stored in the payload under the key
text. - With the re-embedded vectors, it upserts the points into the new collection, keeping the original IDs and payloads. The upserts use insert-only mode to ensure that a point is only inserted if it does not already exist in the new collection. This prevents overwriting newer updates from the regular update service.
This kind of migration process can take some time, and the offset can be stored in a persistent way, so you can resume the migration process in case of a failure. You can use a database, a file, or any other persistent storage to keep track of the last offset. Having said that, because the conditional upserts would not overwrite any points in the new collection, you could safely restart the migration process from the beginning if needed.
Step 4: Change the Collection and Embedding Model for Searches
Once the migration process is complete, and all the points from the old collection are re-embedded and stored in the new collection, you can roll out a configuration change of the backend application. There are two key changes you have to make:
- The collection name. Switch this from the old collection to the new collection. If you’re using a collection alias, switch the alias to point to the new collection.
- The embedding model. Switch this from the old embedding model to the new embedding model.
If these values are hardcoded in your application, you will need to change them directly in the code and deploy a new version of your application. For example, if your current search code looks like this:
results = client.query_points(
collection_name=OLD_COLLECTION,
query=models.Document(text="my query", model=OLD_MODEL),
limit=10,
)
const results = await client.query(OLD_COLLECTION, {
query: {
text: "my query",
model: OLD_MODEL,
},
limit: 10,
});
let results = client
.query(
QueryPointsBuilder::new(old_collection)
.query(Query::new_nearest(Document::new("my query", old_model)))
.limit(10),
)
.await?;
QueryPoints oldRequest =
QueryPoints.newBuilder()
.setCollectionName(OLD_COLLECTION)
.setQuery(
nearest(
Document.newBuilder()
.setText("my query")
.setModel(OLD_MODEL)
.build()))
.setLimit(10)
.build();
var results = client.queryAsync(oldRequest).get();
var results = await client.QueryAsync(
collectionName: OLD_COLLECTION,
query: new Document
{
Text = "my query",
Model = OLD_MODEL
},
limit: 10
);
results, err := client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: OLD_COLLECTION,
Query: qdrant.NewQueryDocument(&qdrant.Document{
Text: "my query",
Model: OLD_MODEL,
}),
Limit: qdrant.PtrOf(uint64(10)),
})
You need to change it in the following way:
results = client.query_points(
collection_name=NEW_COLLECTION,
query=models.Document(text="my query", model=NEW_MODEL),
limit=10,
)
const resultsNew = await client.query(NEW_COLLECTION, {
query: {
text: "my query",
model: NEW_MODEL,
},
limit: 10,
});
let results = client
.query(
QueryPointsBuilder::new(new_collection)
.query(Query::new_nearest(Document::new("my query", new_model)))
.limit(10),
)
.await?;
QueryPoints newRequest =
QueryPoints.newBuilder()
.setCollectionName(NEW_COLLECTION)
.setQuery(
nearest(
Document.newBuilder()
.setText("my query")
.setModel(NEW_MODEL)
.build()))
.setLimit(10)
.build();
results = client.queryAsync(newRequest).get();
results = await client.QueryAsync(
collectionName: NEW_COLLECTION,
query: new Document
{
Text = "my query",
Model = NEW_MODEL
},
limit: 10
);
results, err = client.Query(context.Background(), &qdrant.QueryPoints{
CollectionName: NEW_COLLECTION,
Query: qdrant.NewQueryDocument(&qdrant.Document{
Text: "my query",
Model: NEW_MODEL,
}),
Limit: qdrant.PtrOf(uint64(10)),
})
Step 5: Wrapping Up
Once your application has switched to the new collection, disable the dual-write mode you implemented in Step 2. From now on, the application should only write to the new collection.
All searches are now performed using the new embeddings. If the old collection is no longer needed, you can safely delete it. To ensure you can roll back if necessary, keep a snapshot of the old collection.