GraphRAG: How Lettria Unlocked 20% Accuracy Gains with Qdrant and Neo4j
Daniel Azoulai
·June 17, 2025

On this page:
Scaled Vector & Graph Retrieval: How Lettria Unlocked 20% Accuracy Gains with Qdrant & Neo4j

Why Complex Document Intelligence Needs More Than Just Vector Search
In regulated industries where precision, auditability, and accuracy are paramount, leveraging Large Language Models (LLMs) effectively often requires going beyond traditional Retrieval-Augmented Generation (RAG). Lettria, a leader in document intelligence platforms, recognized that complex, highly regulated data sets like pharmaceutical research, legal compliance, and aerospace documentation demanded superior accuracy and more explainable outputs than vector-only RAG systems could provide. To achieve the expected level of performance, the team has focused its effort on building a very robust document parsing engine designed for complex pdf (with tables, diagrams, charts etc.), an automatic ontology builder and an ingestion pipeline covering vectors and graph enrichment
By integrating vector search capabilities from Qdrant with knowledge graphs powered by Neo4j, Lettria created a hybrid graph RAG system that significantly boosted accuracy and enriched the context provided to LLMs. This case study explores Lettria’s innovative solution, technical challenges overcome, and measurable results achieved.
Why Traditional RAG Fell Short in High-Stakes Use Cases
Enterprises in regulated sectors deal with extensive, complex documentation featuring structured and semi-structured data such as intricate tables, multi-layered diagrams, and specialized terminology. Standard vector search methods achieved around 70% accuracy, which is insufficient for industries where precision is non-negotiable. Additionally, understanding and auditing LLM outputs based on complex documentation posed significant hurdles.
Why Qdrant stood out as a vector database
One component of the build was the vector database. Lettria evaluated Weaviate, Milvus, and Qdrant based on their hybrid search capability, deployment simplicity (Docker, Kubernetes), and search performance (latency, RAM usage).
Ultimately, Lettria chose Qdrant. First, it had a simple Kubernetes deployment, superior latency and lower memory footprint in competitive benchmarks. Additionally, there were unique features, such as the grouping API and detailed payload indexing, that made Qdrant stand out.
Building the document understanding and extraction pipeline
The core of Lettria’s high accuracy solution lies in merging vector embeddings (stored in Qdrant) with graph-based semantic understanding (Neo4j). Here’s an overview of their pipeline:
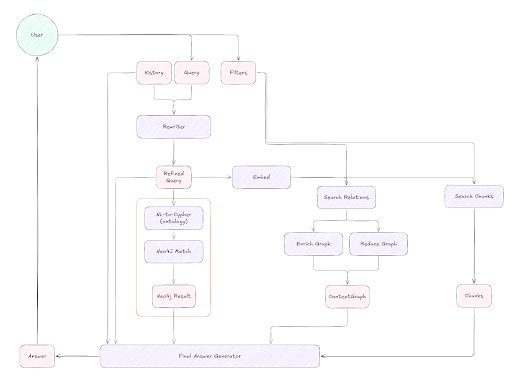
- Ingestion: Complex PDFs are parsed, and data is transformed into dual representations: dense vector embeddings and semantic triples (stored in Neo4j and indexed in Qdrant). As shown in the diagram below, the ingestion pipeline extracts layout and content structure, splits text into meaningful chunks, and routes them into both vector and graph representations. Each chunk maintains lineage metadata, linking it back to its exact position in the source document—critical for traceability.
![]()
Diagram: Ingestion Transaction Mechanism
Ontology Generation: Lettria automatically generates ontologies using LLMs, ensuring scalability and adaptability. This step ensures that only semantically meaningful relationships are extracted—reducing noise and enabling structured querying downstream.
Vector-Driven Graph Expansion: Queries begin with fast vector search in Qdrant, identifying nodes and relationships as text embeddings. These seed points are then used to expand a contextual subgraph in Neo4j, which is combined with chunk data and passed to the LLM for answer generation.
The ingest transaction mechanism: keeping Neo4j and Qdrant in sync
Keeping Qdrant and Neo4j in sync is challenging, as they take fundamentally different approaches to data operations. Neo4j is a transactional database, meaning it can group changes into atomic units that are either fully committed or entirely rolled back. In contrast, Qdrant is a vector search engine designed to processes each update immediately without transactional semantics. This distinction is important: transactional support is typical for databases, while search engines like Qdrant prioritize low-latency ingestion and retrieval over rollback capabilities.
This fundamental mismatch creates complexity. So if a transaction in Neo4j fails after data has already been written to Qdrant, the two databases can quickly fall out of alignment.
To ensure atomicity between Qdrant (non-transactional) and Neo4j (transactional), Lettria built a custom ingest mechanism that guarantees consistent writes across both systems. The process begins by preparing the write as a transactional batch in Neo4j—if Neo4j accepts the changes, they’re committed and saved. Before updating Qdrant, a snapshot of each affected point is taken. Then, Qdrant is updated optimistically. If the Neo4j commit succeeds, the operation completes. But if it fails, Lettria’s system uses the earlier snapshot to rollback Qdrant to its previous state, ensuring no partial writes remain in either database.
The challenge arises in concurrent environments where multiple ingest processes may interact with the same data points. To handle this, Lettria implemented a conflict resolution function that compares three states for each point: the original snapshot, the changes proposed by the current process, and the current state in Qdrant. If a conflict is detected—such as another process modifying the point in the meantime—the resolver merges changes intelligently to preserve valid updates while rolling back only the failed batch. This strategy, combined with small batch sizes, minimizes the risk window and ensures high reliability even at scale.
Pseudocode example: ingest_graph_attempt
def ing est_graph_attempt(graph_data, qdrant, neo4j):
"""
Attempts to ingest graph data into Qdrant and Neo4j consistently.
If Neo4j write fails, Qdrant changes are rolled back.
This mimics a "try Qdrant, then try Neo4j; if Neo4j fails, undo Qdrant" strategy.
"""
BEGIN_TRANSACTION
neo4j.begin_transaction()
points = graph_data.get_triplets()
# Merge points in Neo4j (non blocking)
neo4j.upsert(points)
# Load current points from Qdrant
snapshot = qdrant.get([point.id for point in points])
# Update points in Qdrant
qdrant.upsert(points)
neo4j.commit()
TRANSACTION_ROLLBACK
# Load current points state
current_points = qdrant.get([point.id for point in points])
# Build snapshot of the current state
resolved_snapshot = resolve_conflicts(points, current_points, snapshot)
# Rollback Qdrant changes
qdrant.upsert(resolved_snapshot)
TRANSACTION_SUCCESS
total_points = len(points)
added_points, updated_points = diff(points, snapshot)
Log(f"Successfully ingested {total_points} points into Qdrant and Neo4j.")
Log(f"Added {added_points} points and updated {updated_points} points.")
Consistent querying and indexing through payload flattening
To ensure consistent query behavior and indexing performance across both Qdrant and Neo4j, Lettria adopted a payload flattening strategy. While Qdrant supports nested JSON-like structures in its payloads, Neo4j requires flat key–value pairs for properties on nodes and relationships. This structural mismatch made it difficult to apply consistent filters or indexing logic across both databases. Lettria resolved this by flattening all nested fields during ingestion—for example, converting { "author": { "name": "Jane" } } to { "author_name": "Jane" }. This approach allowed seamless reuse of the same metadata structure in Neo4j, simplifying hybrid search and enforcing schema compatibility across their dual-database architecture.
Scaling to >100M vectors at <200ms P95 retrieval
Lettria scaled its Qdrant deployment to over 100 million vectors while maintaining 95th percentile retrieval latency under 200ms, even in production-like load tests. This performance was made possible through a combination of careful payload index design and disk-based cache collections for infrequently accessed vectors. Initially, lack of indexing led to full collection scans, which significantly degraded performance. After adding indexes on frequently filtered payload fields (e.g. doc_type, client_id, chunk_source), latency dropped sharply and stabilized. To further reduce memory pressure, Lettria separated hot and cold data—keeping active chunks in memory and offloading less-used vectors to on-disk storage, allowing for finer memory tuning without sacrificing accuracy. This approach provided both speed and cost control at scale, supporting hybrid retrieval across dense and sparse modalities without excessive resource overhead.
Outcome: >20% accuracy improvement
Lettria’s graph-enhanced RAG system achieved a substantial accuracy improvement over pure vector solutions:
- 20-25% accuracy uplift in verticals like finance, aerospace, pharmaceuticals, and legal.
- Enhanced explainability and lineage tracking from document ingestion to query response.
- Robust, audit-grade accuracy accepted by clients with manageable latency (1-2 seconds per query).
Ultimately, Lettria beat the accuracy of traditional RAG
Being the first production-ready GraphRAG platform has helped Lettria stand out from competition vs. traditional RAG players. Creating agents has become easier with GraphRAG, helping Lettria build new document intelligence features quickly (e.g. gap analysis between multiple documents). This has led to them securing high-value contracts in sectors demanding high accuracy, and increasing customer trust due to transparent, auditable outputs.
“Qdrant has become a critical part of our GenAI infrastructure. It delivers the performance, flexibility, and reliability we need to build production-grade GraphRAG systems for clients in aerospace, finance, and pharma—where accuracy isn’t optional.”
— Jérémie Basso, Engineering Lead, Lettria
Further reading
Ingest transaction mechanism
Lettria must maintain consistency between the data in Neo4J and in Qdrant. The inference (RAG) pipeline uses Qdrant for vector and payload search then falls back on Neo4J to gather relevant triplets from the graph structure. If some points fail to be inserted into Neo4J but are present in the Qdrant collection, the final output graph will be inconsistent.
To prevent this, Lettria uses a transaction mechanism where the Neo4J commit acts as the final gate for overall success. This mechanism is designed to be idempotent and safe for concurrent ingestion scenarios.
Transaction mechanism
The process, outlined in the ingest_graph_attempt pseudocode, can be summarized as follows:
Neo4J Transaction & Tentative Write:
- An explicit Neo4J transaction begins (neo4j.begin_transaction()).
- Data is prepared and upserted into Neo4J within this transaction (neo4j.upsert(points)). These changes are not yet permanent.
Qdrant Snapshot & Update:
- Before altering Qdrant, a snapshot of the relevant points’ current state is taken (qdrant.get(…)).
- Qdrant is then updated with the new data (qdrant.upsert(points)).
Neo4J Commit (Decisive Point):
- The system attempts to commit the Neo4J transaction (neo4j.commit()).
On Success (TRANSACTION_SUCCESS): Neo4J changes are permanent. Qdrant was already updated, so both systems are consistent
On Failure (TRANSACTION_ROLLBACK):
- Neo4J automatically rolls back its pending changes.
- To restore consistency, Qdrant is rolled back.
Qdrant Rollback
When a Neo4j commit fails, and they need to roll back Qdrant, a simple revert to the snapshot might not be sufficient or correct due to concurrent operations. Another ingestion process might have successfully updated some of the same points in Qdrant after a current (failing) transaction took its snapshot but before the current transaction attempts to roll back.
The resolve_conflicts function aims to make an intelligent decision about what each point’s state in Qdrant should be after the rollback. It considers three states for each point involved:
- snapshot: state of the point before the current update
- points: updates of the current state
- current_points: current state of the points in qdrant
Here is a minimal example:
snapshot = {
"id": "my_point_id_123",
"name": "my_point", # Original name
"foo": "bar" # Original foo
}
point = {
"id": "my_point_id_123",
"name": "my_point_v2", # Our transaction intended to change the name
"bar": "baz" # Our transaction intended to add a new key "bar"
}
current = {
"id": "my_point_id_123",
"name": "my_point_v2", # Matches our intended name change (our change "stuck" so far)
"foo": "qux", # another transaction changed this!
"bar": "baz", # Matches our intended new key "bar"
"baz": "quux" # NEW key - another transaction added this!
}
resolved = {
"id": "my_point_id_123",
"name": "my_point", # Reverted: Our transaction changed this, so undo.
"foo": "qux", # Preserved: Another transaction changed this, respect it.
"baz": "quux" # Preserved: Another transaction added this, respect it.
# bar is Removed: Our transaction added this, so undo by removing.
}
Pseudocode example:
def ingest_graph_attempt(graph_data, qdrant, neo4j):
"""
Attempts to ingest graph data into Qdrant and Neo4j consistently.
If Neo4j write fails, Qdrant changes are rolled back.
This mimics a "try Qdrant, then try Neo4j; if Neo4j fails, undo Qdrant" strategy.
"""
BEGIN_TRANSACTION
neo4j.begin_transaction()
points = graph_data.get_triplets()
# Merge points in Neo4j (non blocking)
neo4j.upsert(points)
# Load current points from Qdrant
snapshot = qdrant.get([point.id for point in points])
# Update points in Qdrant
qdrant.upsert(points)
neo4j.commit()
TRANSACTION_ROLLBACK
# Load current points state
current_points = qdrant.get([point.id for point in points])
# Build snapshot of the current state
resolved_snapshot = resolve_conflicts(points, current_points, snapshot)
# Rollback Qdrant changes
qdrant.upsert(resolved_snapshot)
TRANSACTION_SUCCESS
total_points = len(points)
added_points, updated_points = diff(points, snapshot)
Log(f"Successfully ingested {total_points} points into Qdrant and Neo4j.")
Log(f"Added {added_points} points and updated {updated_points} points.")
Known limits
Lettria might revert changes from another transaction if they are strictly identical to the current one. There’s a very brief window of vulnerability during the Qdrant rollback process. It occurs after Lettria has read the current qdrant points (to decide how to roll back) but before they execute the actual rollback upsert (qdrant.upsert(resolved_snapshot)). If another concurrent transaction successfully updates a point in Qdrant within this tiny window, their subsequent rollback operation might unintentionally overwrite that very recent, legitimate update.
Mitigation – Small, Iterative Batches:
- They mitigate this risk by processing data ingestion (and any potential rollbacks) in small, iterative batches.
- By doing so, the time duration between fetching current_qdrant_point and performing the rollback upsert for any given point is minimized.
- A shorter window significantly reduces the probability that a conflicting concurrent update to the same points will occur precisely within that critical, narrow timeframe. While not a perfect guarantee, it makes such an event statistically less likely.
Payload Flattening
Each client assistant lives in its own Qdrant collection.
Lettria defines the point id of each element as a generated UUID on the client side. This allows them to preserve the same indexed ids in Neo4J and Qdrant. Those UUIDs are generated with a hash of the string id of an element:
- For chunks, the string id is the id of the chunk defined as a combination of the source (pdf) id, section (used for text-to-graph) id and the order int of the chunk.
- For relation, they use a generated UUID6 as each relation is considered unique.
- For nodes, they use the node IRI (http://example.org/resource/France) and the client assistant namespace.
def create_uuid_from_string(string_id: str, namespace: str):
"""Create uuid from string."""
hex_string = hashlib.md5(
f"{namespace}:{string_id}".encode("UTF-8"),
usedforsecurity=False
).hexdigest()
return uuid.UUID(hex=hex_string, version=4)
It also ensures that re-ingestion of the same document will update chunks (as ids will be identical). And nodes with the same IRI are considered merged in a specific assistant.
Flattening
Nodes and relations are saved in Qdrant AND Neo4J. Node and relation payload’s follow a nested structure that looks like this:
{
"properties": {
"rdfs:label": {
"@en": "House",
"@fr": "Maison"
},
"onto:surface": 250
},
"metadata": {
"origin_ids": ["001", "002"],
"client_id": "8FKZ78"
}
}
Lettria has two major levels: properties (semanticly rich information about the object) and metadata (system information).
Moreover, string properties might have an extra level for the language variants. As stated in Neo4J docs, they cannot add nested properties to nodes and relations. Therefore, they flatten such payload in Neo4J:
{
"properties.rdfs:label": "House",
"properties.rdfs:label@en": "House",
"properties.rdfs:label@fr": "Maison",
"properties.onto:surface": 250,
"metadata.origin_ids": ["001", "002"],
"metadata.client_id": "8FKZ78"
}
Note that they duplicate the english tags for string properties as they are considered a default. The language tags are not flattened with a dot to prevent ambiguity between nested properties and language variants when unflattening data retrieved from the database.
Filtering
based on a filter definition. Lettria flattens properties on Neo4J so that they can use similar filters. The nested structure (more on that here) {“foo”: { “bar”: “qux” }} is kept in Qdrant and dot separated in NeoJ: foo.bar=qux so that they can perform match queries with similar keys from Qdrant. This introduces some complexity as they need to be careful in the handling of url and other ‘dot rich’ values in properties.
If they want to filter based on the onto:surface value, the same keys are used in Qdrant and Neo4J:
MATCH (n:Node)
WHERE
n."properties.onto:surface" > 100
RETURN n;
POST /collections/{collection_name}/points/scroll
{
"filter": {
"should": [
{
"key": "properties.onto:surface",
"match": {
"range": {"gt": 100, "lt": null}
}
}
]
}
}
Parsing conceptual visualization
Source document
An example two column document with title, text, table, image and footnotes.

Layout
They isolate components on the page.

Extraction and structuration
They extract content of each component and structure the content based on the computed reading order.

Enrichment
They remove some components (footnotes, pages, etc.) and clean the content (fix numbered and bullet point lists, merge multipage tables, textualize images etc.)

Inference Process Overview