































How Lyzr Supercharged AI Agent Performance with Qdrant
Daniel Azoulai
·April 15, 2025

On this page:
How Lyzr Supercharged AI Agent Performance with Qdrant

Scaling Intelligent Agents: How Lyzr Supercharged Performance with Qdrant
As AI agents become more capable and pervasive, the infrastructure behind them must evolve to handle rising concurrency, low-latency demands, and ever-growing knowledge bases. At Lyzr Agent Studio—where over 100 agents are deployed across industries—these challenges arrived quickly and at scale.
When their existing vector database infrastructure began to buckle under pressure, the engineering team needed a solution that could do more than just keep up. It had to accelerate them forward.
This is how they rethought their stack and adopted Qdrant as the foundation for fast, scalable agent performance.
The Scaling Limits of Early Stack Choices
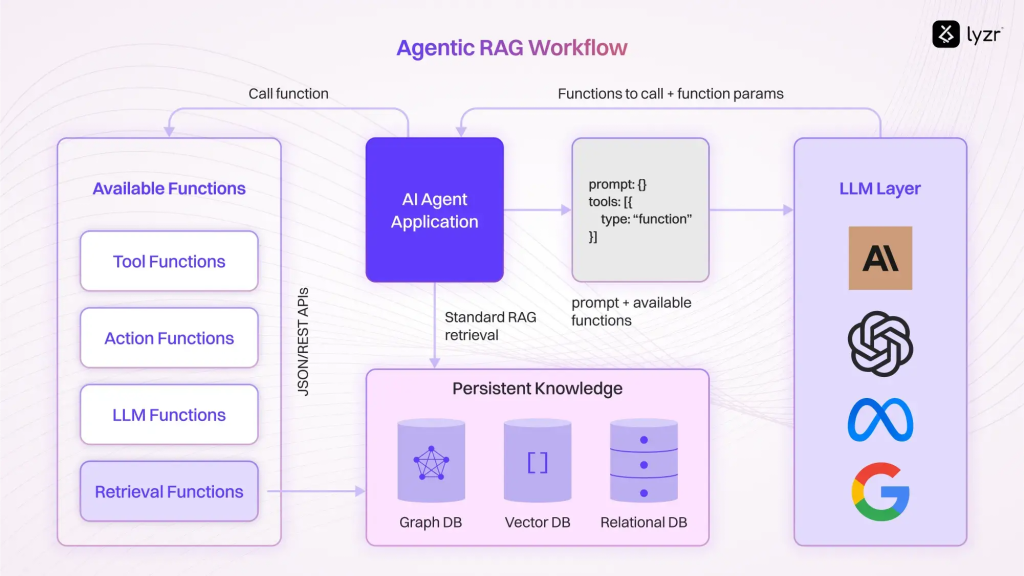
Lyzr’s architecture used Weaviate, with additional benchmarking on Pinecone. Initially, this setup was fine for development and controlled testing. The system managed around 1,500 vector entries, with a small number of agents issuing moderate query loads in a steady pattern.
Initial setup:
| Parameter | Details |
|---|---|
| Deployment Type | Single-node or small-cluster (Weaviate and other vector db) |
| Embedding Model | Sentence-transformer (768 dimensions) |
| Concurrent Agents | 10 to 20 knowledge search agents |
| Query Rate per Agent | 5-10 queries per minute |
| Traffic Pattern | Steady, no significant spikes |
Under these conditions, both databases performed adequately. Query latency hovered between 80 and 150 milliseconds. Indexing operations completed within a few hours. Overall performance was predictable and stable.
But as the platform expanded—with a larger corpus, more complex workflows, and significantly more concurrency—these systems began to falter.
Growth Brings Latency, Timeouts, and Resource Bottlenecks
Once the knowledge base exceeded 2,500 entries and live agent concurrency grew past 100, the platform began to strain.
Query latency increased nearly 4x to 300-500 milliseconds. During peak usage, agents sometimes timed out waiting for vector results, which impacted downstream decision logic. Indexing operations slowed as well, consuming excess CPU and memory, and introducing bottlenecks during data updates.
These issues created real friction in production environments—and made it clear that a more scalable, performant vector database was needed.
Evaluation of Alternative Vector Databases
With growing data volume and rising agent concurrency, Lyzr needed a more scalable and efficient vector database.
They needed something that could handle heavier loads while maintaining fast response times and reducing operational overhead. They evaluated alternatives based on the below criteria:
| Criteria | Focus Area | Impact on System |
|---|---|---|
| Scalability & Distributed Computing | Horizontal scaling, clustering | Support growing datasets and high agent concurrency |
| Indexing Performance | Ingestion speed, update efficiency | Reduce downtime and enable faster bulk data updates |
| Query Latency & Throughput | Search response under load | Ensure agents maintain fast, real-time responses |
| Consistency & Reliability | Handling concurrency & failures | Avoid timeouts and failed queries during peak usage |
| Resource Efficiency | CPU, memory, and storage usage | Optimize infrastructure costs while scaling workload |
| Benchmark Results | Real-world load simulation | Validate sustained performance under >1,000 QPM loads |
Qdrant speeds up queries by >90%, indexes 2x faster, and reduces infra costs by 30%.
That shift came with Qdrant, which quickly surpassed expectations across every critical metric.
With Qdrant, query latency dropped to just 20–50 milliseconds, a >90% improvement over Weaviate and Pinecone. Even with hundreds of concurrent agents generating over 1,000 queries per minute, performance remained consistent.
Indexing operations improved dramatically. Ingestion times for large datasets were 2x faster, and the system required significantly fewer compute and memory resources to complete them. This enabled the team to reduce infrastructure costs by approximately 30%.
Qdrant also demonstrated greater consistency. While Weaviate and Pinecone both encountered performance degradation at scale, Qdrant remained stable under 1,000+ queries per minute—supporting over 100 concurrent agents without latency spikes or slowdowns. Most notably, Lyzr sustained throughput of more than 250 queries per second, across distributed agents, without compromising speed or stability.
| Metric | Weaviate | Pinecone | Qdrant |
|---|---|---|---|
| Avg Query Latency at 100 agents (ms) | 300-500 | 250-450 | 20-50 (P99) |
| Indexing Hours (2,500+ entries) | ~3 | ~2.5 | ~1.5 |
| Query Throughput (QPS) | ~80 | ~100 | >250 |
| Resource Utilization (CPU/Memory) | High | Medium-High | Low-Medium |
| Horizontal Scalability | Moderate | Moderate | Highly Scalable |
Qdrant’s HNSW-based indexing allowed the system to handle live updates without downtime or reindexing—eliminating one of the biggest sources of friction in the previous setup.
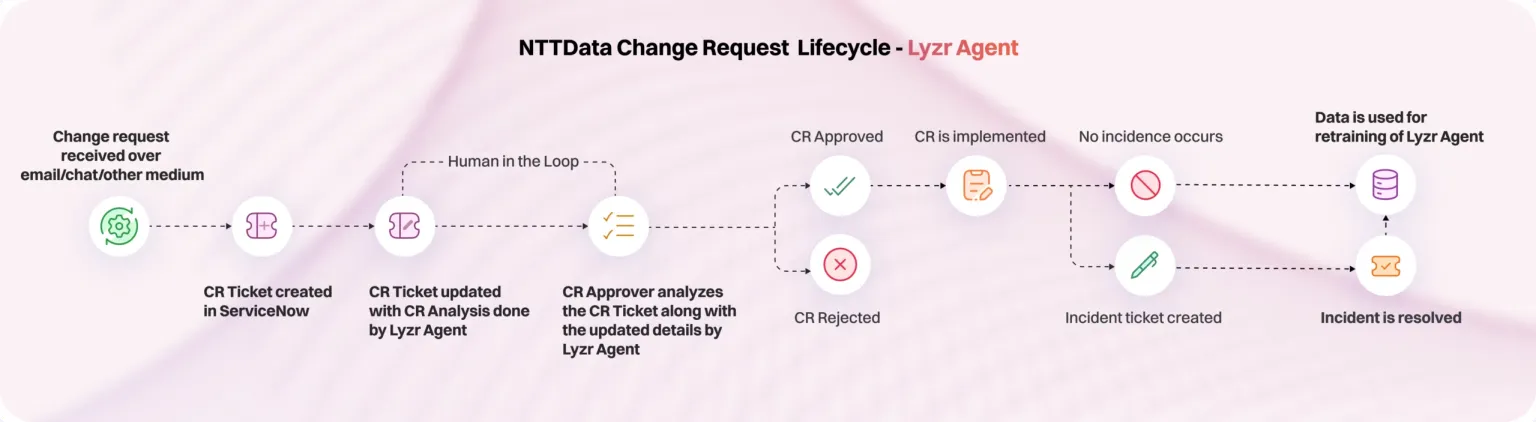
Use Case Spotlight: NTT Data improves retrieval accuracy
One deployment, built for NTT Data, focused on automating IT change request workflows. The agent initially ran on Cosmos DB within Azure. While integration was smooth, vector search performance was limited. Indexing precision was inadequate, and the system struggled to surface relevant results as data volume grew.
After migrating to Qdrant, the difference was immediate. Retrieval accuracy improved substantially, even for long-tail queries. The system maintained high responsiveness under concurrent loads, and horizontal scaling became simpler—ensuring consistent performance as project demands evolved.
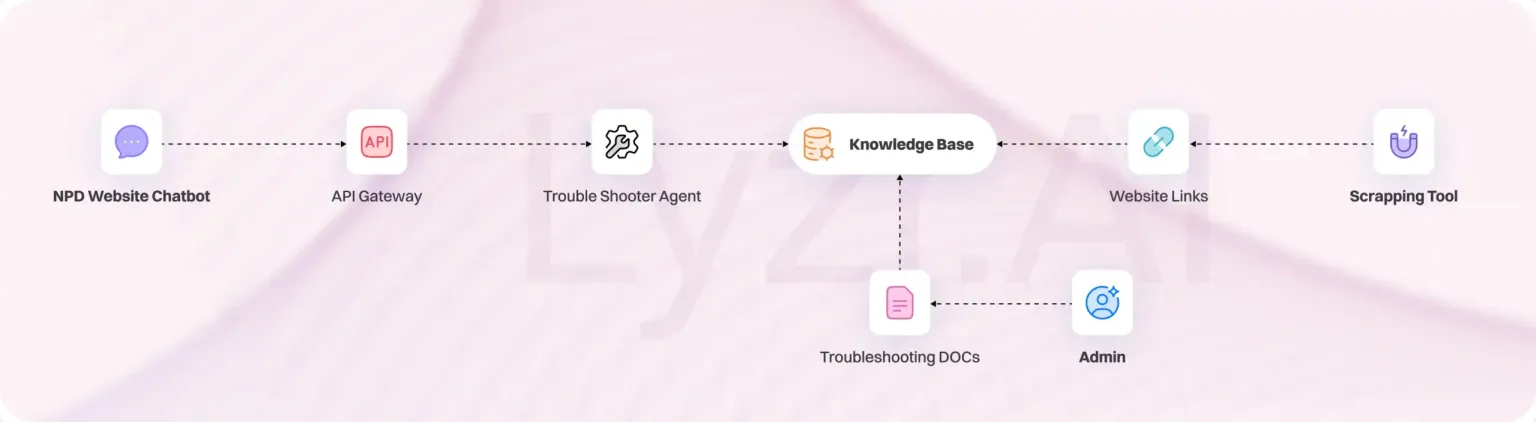
Use Case Spotlight: NPD supports accurate, low-latency retrieval for Agents
Another example involved NPD, which deployed customer-facing agents across six websites. These agents were tasked with answering product questions and guiding users to the correct URLs based on a dynamic, site-wide knowledge base.
Qdrant’s vector search enabled accurate, low-latency retrieval across thousands of entries. Even under increasing user traffic, the platform delivered consistent performance, eliminating the latency spikes experienced with previous solutions.
Final Thoughts
The lesson from Lyzr’s experience is clear: a production-grade AI platform demands a production-grade vector database.
Qdrant delivered on that requirement. It allowed Lyzr to dramatically reduce latency, scale query throughput, simplify data ingestion, and lower infrastructure costs—all while maintaining system stability at scale.
As the AI ecosystem evolves, the performance of the vector database will increasingly dictate the performance of the agent itself. With Qdrant, Lyzr gained the infrastructure it needed to keep its agents fast, intelligent, and reliable—even under real-world production loads.
Want to see how Lyzr Agent Studio and Qdrant can work in your stack?
Explore Lyzr Agent Studio or learn more about Qdrant.
