































How Sprinklr Leverages Qdrant to Enhance AI-Driven Customer Experience Solutions
Qdrant
·October 17, 2024
On this page:

Sprinklr, a leader in unified customer experience management (Unified-CXM), helps global brands engage customers meaningfully across more than 30 digital channels. To achieve this, Sprinklr needed a scalable solution for AI-powered search to support their AI applications, particularly in handling the vast data requirements of customer interactions.
Raghav Sonavane, Associate Director of Machine Learning Engineering at Sprinklr, leads the Applied AI team, focusing on Generative AI (GenAI) and Retrieval-Augmented Generation (RAG). His team is responsible for training and fine-tuning in-house models and deploying advanced retrieval and generation systems for customer-facing applications like FAQ bots and other GenAI-driven services. The team provides all of these capabilities in a centralized platform to the Sprinklr product engineering teams.
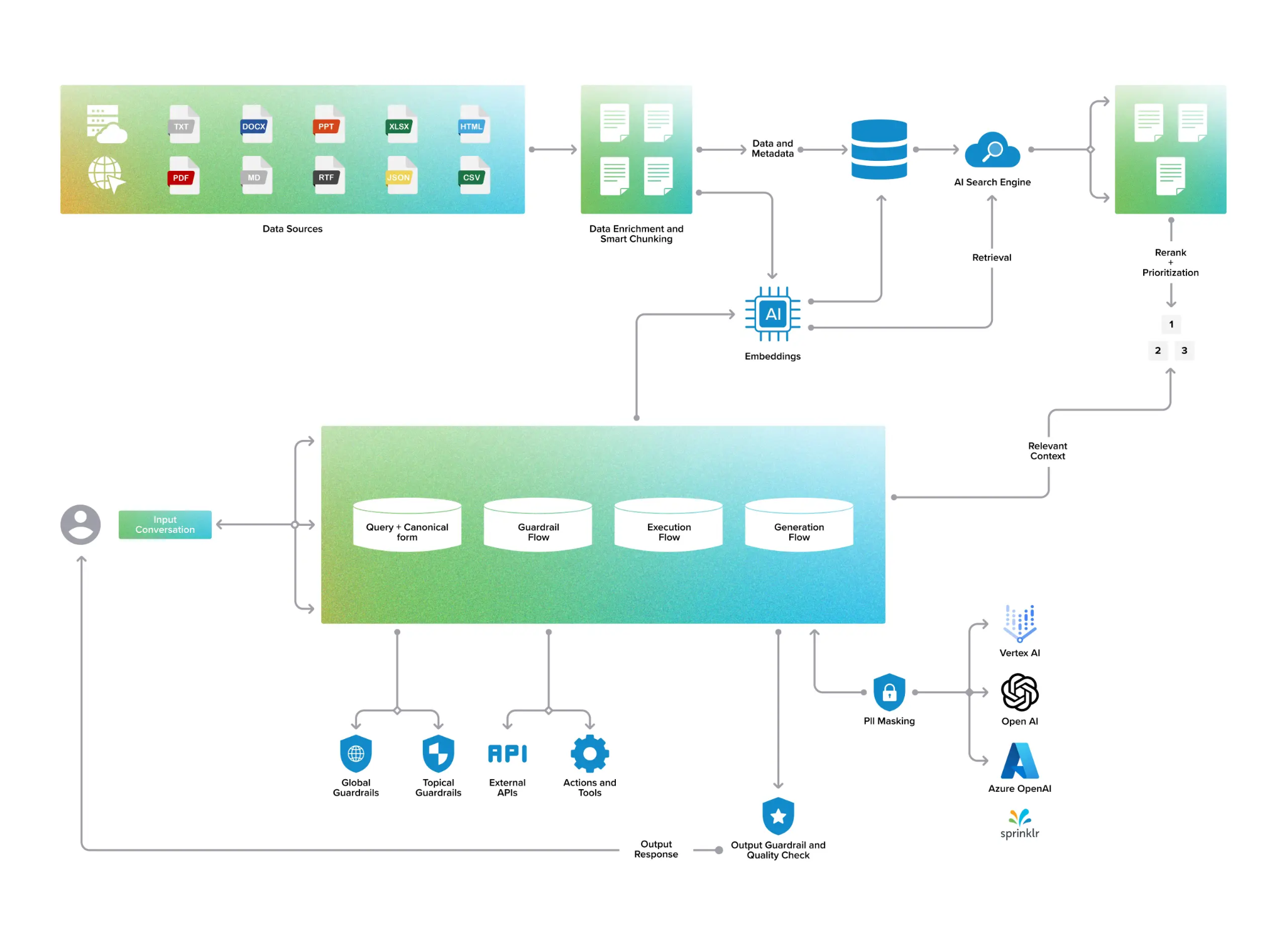
Figure: Sprinklr’s RAG architecture
Sprinklr’s platform is composed of four key product suites - Sprinklr Service, Sprinklr Marketing, Sprinklr Social, and Sprinklr Insights. Each suite is embedded with AI-first features such as assist agents, post-call analysis, and real-time analytics, which are crucial for managing large-scale contact center operations. “These AI-driven capabilities, supported by Qdrant’s advanced vector search, enhance Sprinklr’s customer-facing tools such as FAQ bots, transactional bots, conversational services, and product recommendation engines,” says Sonavane.
These self-serve applications rely heavily on advanced vector search to analyze and optimize community content and refine knowledge bases, ensuring efficient and relevant responses. For customers requiring further assistance, Sprinklr equips support agents with powerful search capabilities, enabling them to quickly access similar cases and draw from past interactions, enhancing the quality and speed of customer support.
The Need for a Vector Database
To support various AI-driven applications, Sprinklr needed an efficient vector database. “The key challenge was to provide the highest quality and fastest search capabilities for retrieval tasks across the board,” explains Sonavane.
Last year, Sprinklr undertook a comprehensive evaluation of its existing search infrastructure. The goals were to identify current capability gaps, benchmark performance for speed and cost, and explore opportunities to improve the developer experience through enhanced scalability and stronger data privacy controls. It became clear that an advanced vector database was essential to meet these needs, and Qdrant emerged as the ideal solution.
Why Qdrant?
After evaluating several options of vector DBs, including Pinecone, Weaviate, and ElasticSearch, Sprinklr chose Qdrant for its:
Developer-Friendly Documentation: “Qdrant’s clear documentation enabled our team to integrate it quickly into our workflows,” notes Sonavane.
High Customizability: Qdrant provided Sprinklr with essential flexibility through high-level abstractions that allowed for extensive customizations. The diverse teams at Sprinklr, working on various GenAI applications, needed a solution that could adapt to different workloads. “The ability to fine-tune configurations at the collection level was crucial for our varied AI applications,” says Sonavane. Qdrant met this need by offering:
- Configuration for high-speed search that fine-tunes settings for optimal performance.
- Quantized vectors for high-dimensional data workloads
- Memory map for efficient search optimizing memory usage.
Speed and Cost Efficiency: Qdrant provided the best combination of speed and cost, making it the most viable solution for Sprinklr’s needs. “We needed a solution that wouldn’t just meet our performance requirements but also keep costs in check, and Qdrant delivered on both fronts,” says Sonavane.
Enhanced Monitoring: Qdrant’s monitoring tools further boosted system efficiency, allowing Sprinklr to maintain high performance across their platforms.
Implementation and Qdrant’s Performance
Sprinklr’s transition to Qdrant was carefully managed, starting with 10% of their workloads before gradually scaling up. The transition was seamless, thanks in part to Qdrant’s configurable Web UI, which allowed Sprinklr to fully utilize its capabilities within the existing infrastructure.
“Qdrant’s ability to index multiple vectors simultaneously and retrieve and re-rank with precision brought significant improvements to our workflow,” Sonavane remarks. This feature reduced the need for repeated retrieval processes, significantly improving efficiency. Additionally, Qdrant’s quantization and memory mapping features enabled Sprinklr to reduce RAM usage, leading to substantial cost savings.
Qdrant now plays a key supportive role in enhancing Sprinklr’s vector search capabilities within its AI-driven applications, which is designed to be cloud- and LLM-agnostic. The platform supports various AI-driven tasks, from retrieval and re-ranking to serving advanced customer experiences. “Retrieval is the foundation of all our AI tasks, and Qdrant’s resilience and speed have made it an integral part of our system,” Sonavane emphasizes. Sprinklr operates Qdrant as a managed service on AWS, ensuring scalability, reliability, and ease of use.
Key Outcomes with Qdrant
After rigorous internal evaluation, Sprinklr achieved the following results with Qdrant:
- 30% Cost Reduction: Internal benchmarking showed Qdrant reduced Sprinklr’s retrieval infrastructure costs by 30%.
- Improved Developer Efficiency: Qdrant’s user-friendly environment made it easier to maintain instances, enhancing overall efficiency.
The Sprinklr team conducted a thorough internal benchmark on applications requiring vector search across 10k to over 1M vectors with varying dimensions of vectors depending on the use case. The key results from these benchmarks include:
- Superior Write Performance: Qdrant’s write performance excelled in Sprinklr’s benchmark tests, with incremental indexing time for 100k to 1M vectors being less than 10% of Elasticsearch’s, making it highly efficient for handling updates and append queries in high-ingestion use cases.
- Low Latency for Real-Time Applications: In Sprinklr’s benchmark, Qdrant delivered a P99 latency of 20ms for searches on 1 million vectors, making it ideal for real-time use cases like live chat, where Elasticsearch and Milvus both exceeded 100ms.
- High Throughput for Heavy Query Loads: In Sprinklr’s benchmark, Qdrant handled up to 250 requests per second (RPS) under similar configurations, significantly outperforming Elasticsearch’s 100 RPS, making it ideal for environments with heavy query loads.
“Qdrant is a very fast and high quality retrieval system,” Sonavane points out.
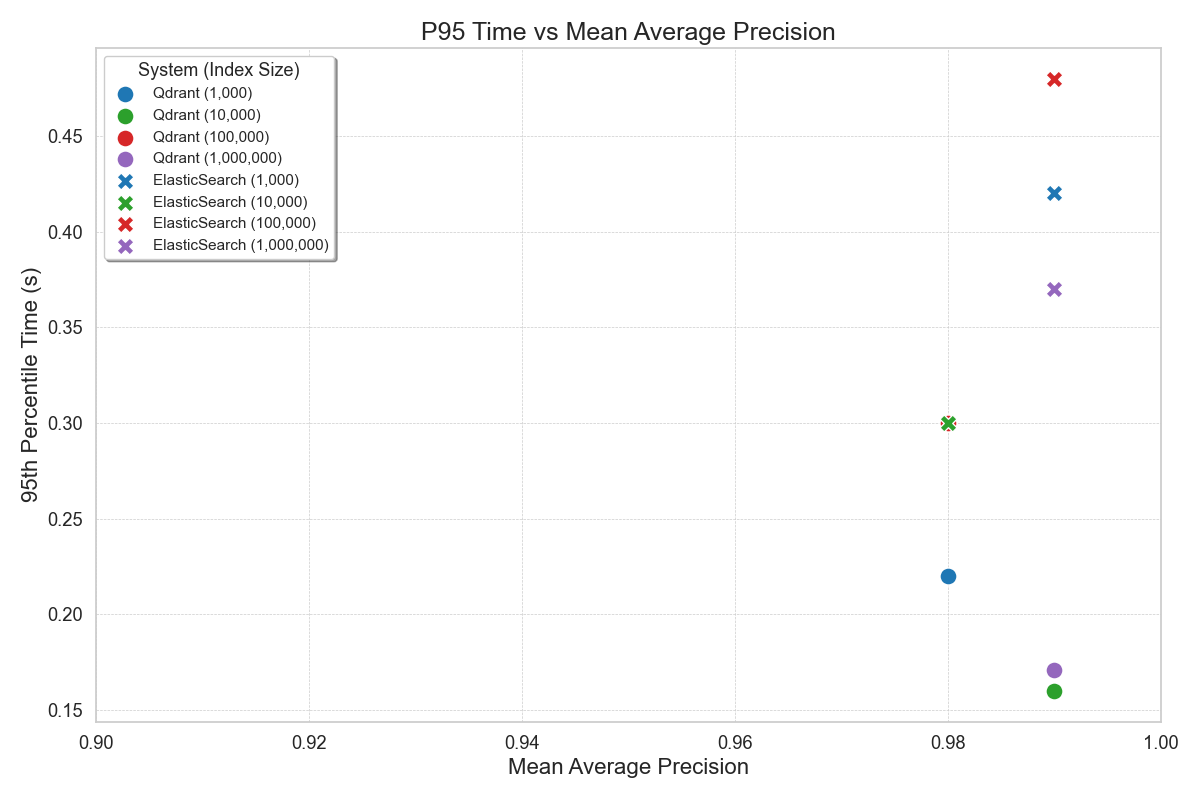
Figure: P95 Query Time vs Mean Average Precision Benchmark Across Varying Index Sizes
Outlook
Looking ahead, the Applied AI team at Sprinklr is focused on developing Sprinklr Digital Twin technology for companies, organizations, and employees, aiming to seamlessly integrate AI agents with human workers in business processes. Sprinklr Digital Twins are powered by a process engine that incorporates personas, skills, tasks, and activities, designed to optimize operational efficiency.
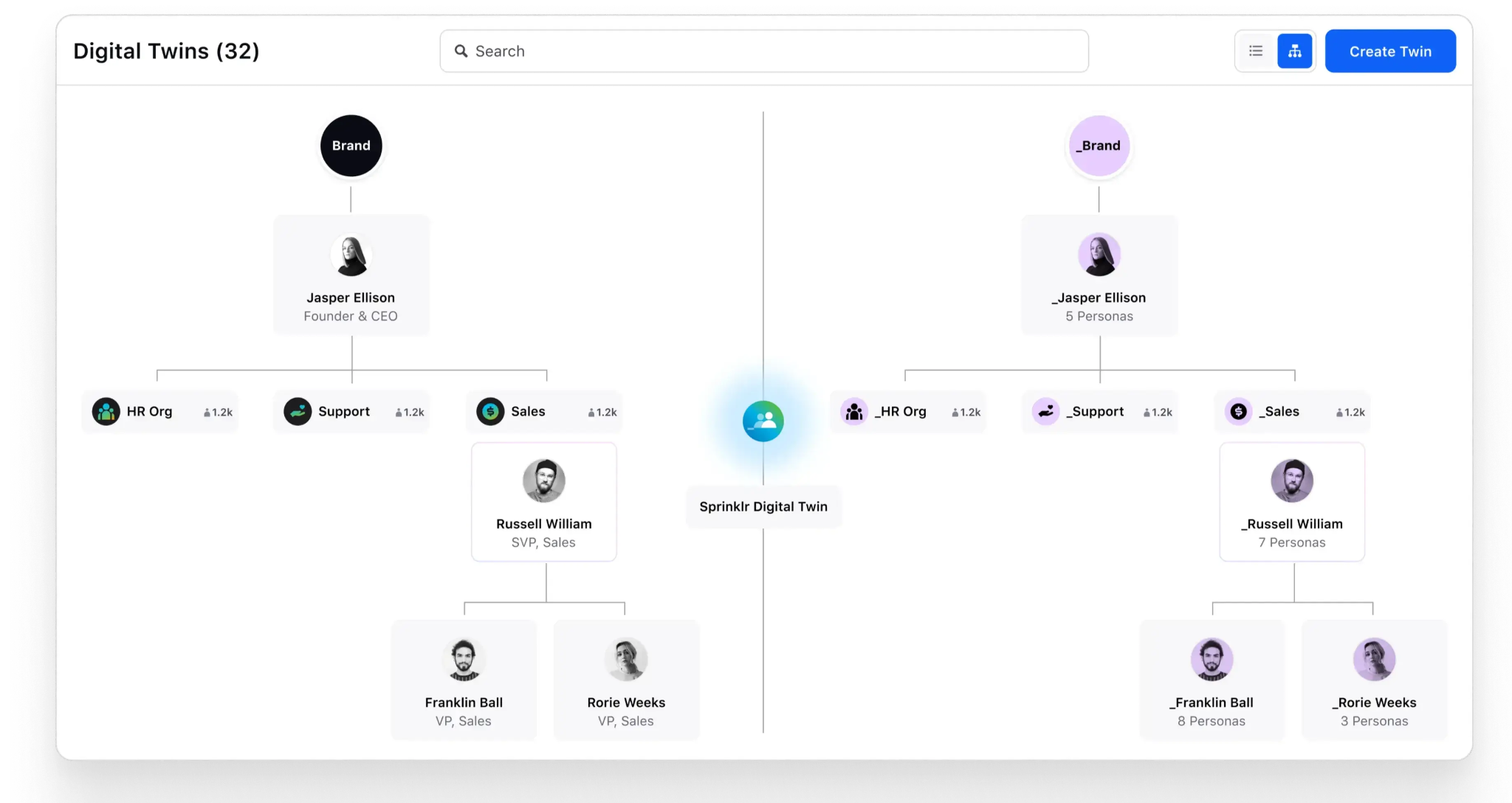
Figure: Sprinklr Digital Twin
Vector search will play a crucial role, as each AI agent will have its own knowledge base, skill set, and tool set, enabling precise and autonomous task execution. The integration of Qdrant further enhances the system’s ability to manage and utilize large volumes of data effectively.
Benchmarking Conclusion
Configuration Details:
- We benchmarked applications requiring search on different sizes ranging from 10k to 1M+ vectors, with varying dimensions of vectors depending on the usage. Our infrastructure mainly consisted of Elasticsearch and in-memory Faiss vector search.
Key Observations:
- Indexing Speed: Qdrant indexes vectors rapidly, making it suitable for applications that require quick data ingestion. Among the alternatives tried, milvus was on par with qdrant in terms of indexing time for a given precision. The latest versions of Elasticsearch offer much improvement compared to previous versions, though not as efficient as Qdrant.
- Write Performance: For some of our use cases, update queries and append queries were significantly higher. For ES, an increase in the number of points had a severe impact on total upload time. For 100k to 1M vector index qdrant incremental indexing time was less than 10% of Elasticsearch.
- Low Latency: Tail latencies are very critical for real-time applications such as live chat, requiring low P95 and P99 latencies. For a workload requiring search on 1 million vectors, qdrant provided inference latency of 20ms P99 whereas ES and Milvus were more than 100ms.
- High Throughput: Qdrant handles a high number of requests per second, making it ideal for environments with heavy query loads. For similar configurations, Qdrant provided a throughput of 250 RPS whereas ES was around 100 RPS.
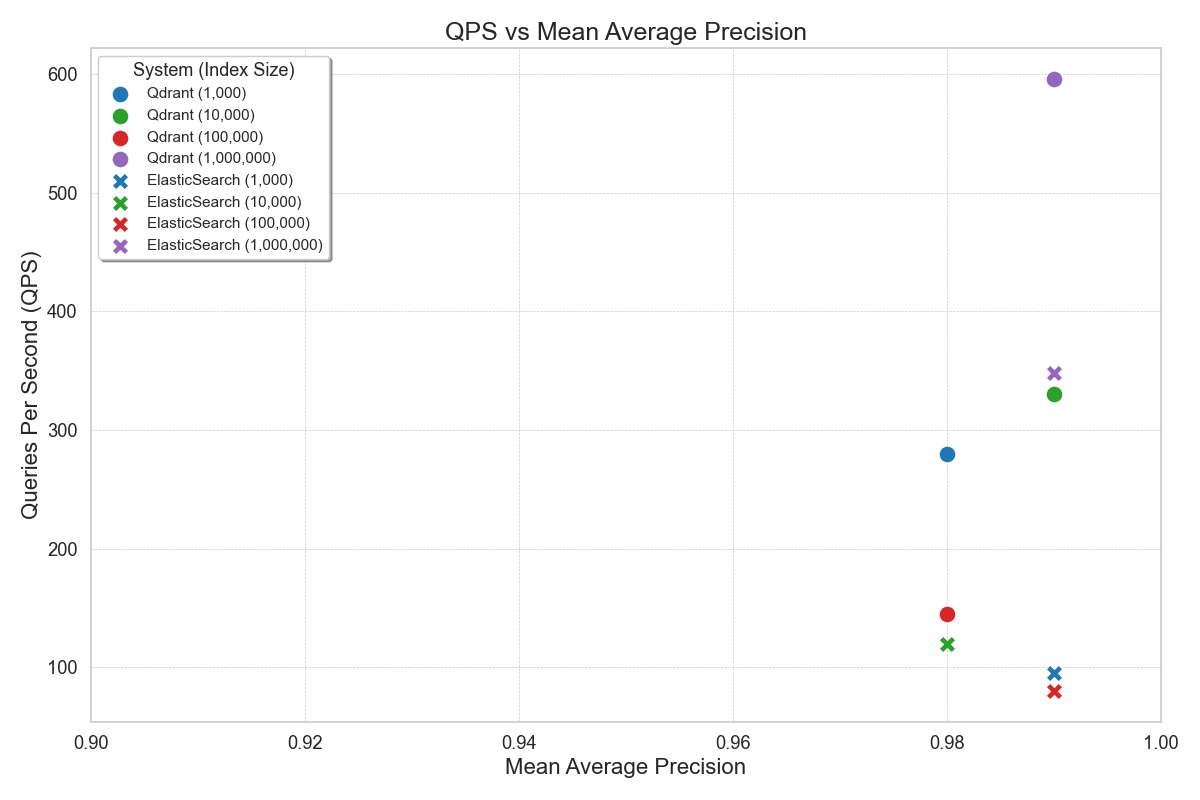
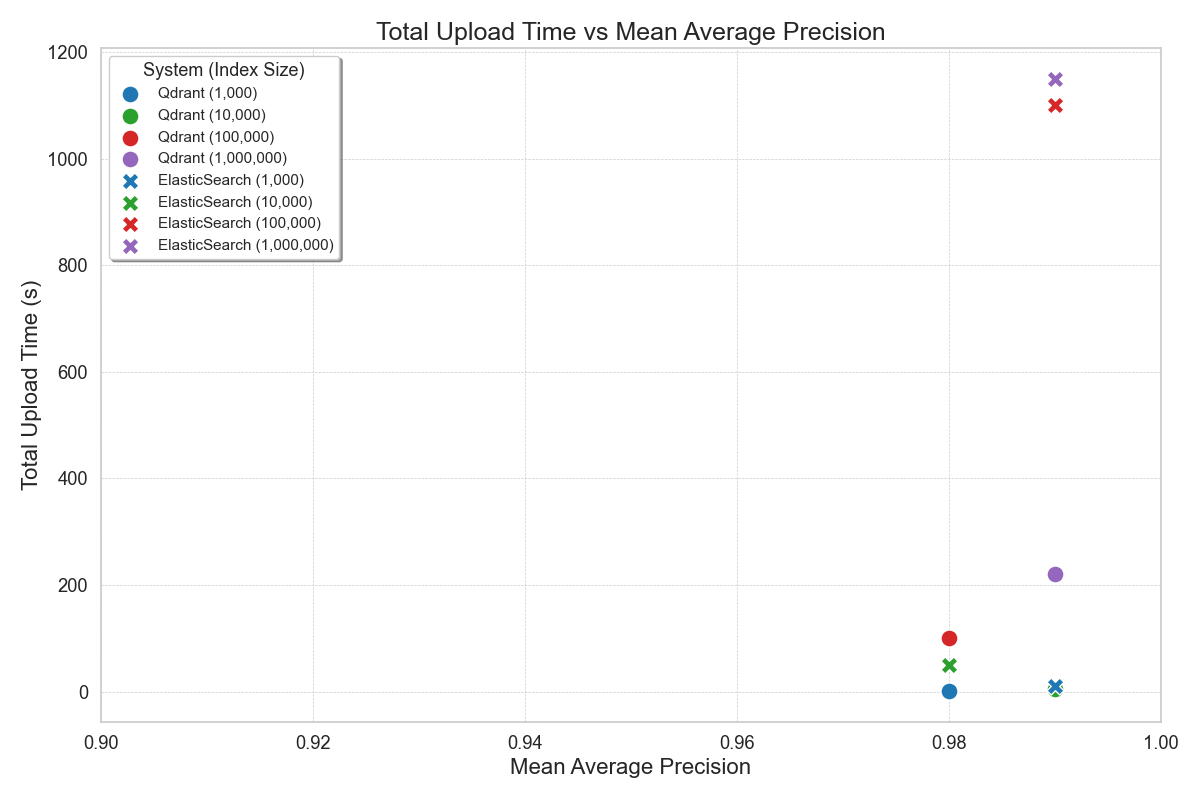
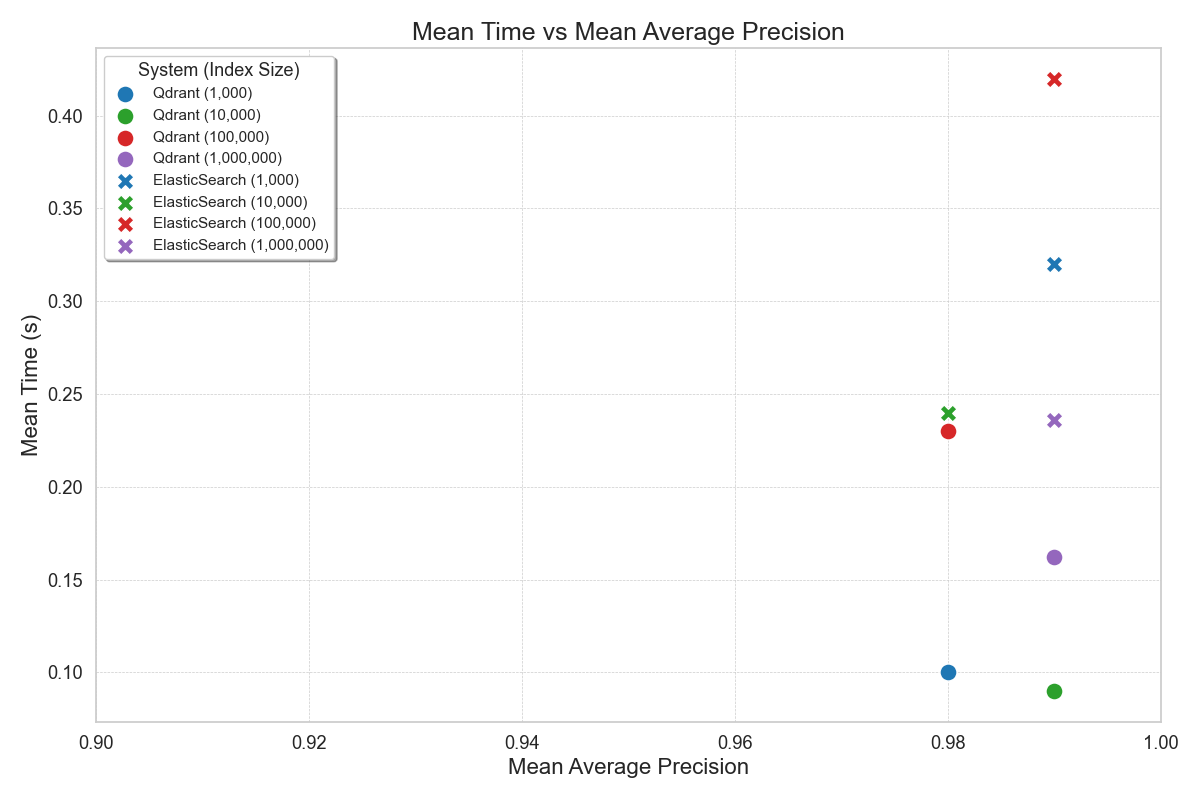
data = [
{'system': 'Qdrant', 'index_size': '1,000', 'MAP': 0.98, 'P95 Time': 0.22, 'Mean Time': 0.1, 'QPS': 280,
'Upload Time': 1},
{'system': 'Qdrant', 'index_size': '10,000', 'MAP': 0.99, 'P95 Time': 0.16, 'Mean Time': 0.09, 'QPS': 330,
'Upload Time': 5},
{'system': 'Qdrant', 'index_size': '100,000', 'MAP': 0.98, 'P95 Time': 0.3, 'Mean Time': 0.23, 'QPS': 145,
'Upload Time': 100},
{'system': 'Qdrant', 'index_size': '1,000,000', 'MAP': 0.99, 'P95 Time': 0.171, 'Mean Time': 0.162, 'QPS': 596,
'Upload Time': 220},
{'system': 'ElasticSearch', 'index_size': '1,000', 'MAP': 0.99, 'P95 Time': 0.42, 'Mean Time': 0.32, 'QPS': 95,
'Upload Time': 10},
{'system': 'ElasticSearch', 'index_size': '10,000', 'MAP': 0.98, 'P95 Time': 0.3, 'Mean Time': 0.24, 'QPS': 120,
'Upload Time': 50},
{'system': 'ElasticSearch', 'index_size': '100,000', 'MAP': 0.99, 'P95 Time': 0.48, 'Mean Time': 0.42, 'QPS': 80,
'Upload Time': 1100},
{'system': 'ElasticSearch', 'index_size': '1,000,000', 'MAP': 0.99, 'P95 Time': 0.37, 'Mean Time': 0.236,
'QPS': 348, 'Upload Time': 1150}
]
